当前位置:网站首页>50 commonly used numpy function explanations, parameters and usage examples
50 commonly used numpy function explanations, parameters and usage examples
2022-07-06 21:33:00 【deephub】
Numpy yes python One of the most useful tools in . It can effectively handle large amounts of data . Use NumPy One of the biggest reasons is that it has many functions that deal with arrays . In this paper , Will introduce NumPy Some of the most important and useful functions in Data Science .
Create array
1、Array
It is used to create one-dimensional or multi-dimensional arrays
Dtype: The data type required to generate the array .
ndim: Specify the minimum number of dimensions of the generated array .
import numpy as np
np.array([1,2,3,4,5])
----------------
array([1, 2, 3, 4, 5, 6])
You can also use this function to pandas Of df and series To NumPy Array .
sex = pd.Series(['Male','Male','Female'])
np.array(sex)
------------------------
array(['Male', 'Male', 'Female'], dtype=object)
2、Linspace
Create an array of floating-point numbers with a specified interval .
start: Start number
end: end
Num: Number of samples to generate , The default is 50.
np.linspace(10,100,10)
--------------------------------
array([ 10., 20., 30., 40., 50., 60., 70., 80., 90., 100.])
3、Arange
Returns an integer with a certain step size within a given interval .
step: Numerical step size .
np.arange(5,10,2)
-----------------------
array([5, 7, 9])
4、Uniform
Generate random samples in the uniform distribution between the upper and lower limits .
np.random.uniform(5,10,size = 4)
------------
array([6.47445571, 5.60725873, 8.82192327, 7.47674099])
np.random.uniform(size = 5)
------------
array([0.83358092, 0.41776134, 0.72349553])
np.random.uniform(size = (2,3))
------------
array([[0.7032511 , 0.63212039, 0.6779683 ],
[0.81150812, 0.26845613, 0.99535264]])
5、Random.randint
Generate in a range n Random integer samples .
np.random.randint(5,10,10)
------------------------------
array([6, 8, 9, 9, 7, 6, 9, 8, 5, 9])
6、Random.random
Generate n Samples of random floating-point numbers .
np.random.random(3)
---------------------------
array([0.87656396, 0.24706716, 0.98950278])
7、Logspace
Generate evenly spaced numbers on a logarithmic scale .
Start: The starting value of the sequence .
End: The last value of the sequence .
endpoint: If True, The last sample will be included in the sequence .
base: base number . The default is 10.
np.logspace(0,10,5,base=2)
------------------
array([1.00000000e+00, 5.65685425e+00, 3.20000000e+01, 1.81019336e+02,1.02400000e+03])
8、zeroes
np.zeroes Will create a 0 Array of .
shape: The shape of the array .
Dtype: The data type required to generate the array .’ int ‘ Or default ’ float ’
np.zeros((2,3),dtype='int')
---------------
array([[0, 0, 0],
[0, 0, 0]])
np.zeros(5)
-----------------
array([0., 0., 0., 0., 0.])
9、ones
np.ones Function to create an all 1 Array of .
np.ones((3,4))
------------------
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
10、full
Create a single value n Dimension group .
fill_value: Fill value .
np.full((2,4),fill_value=2)
--------------
array([[2, 2, 2, 2],
[2, 2, 2, 2]])(2,4) : ꜱʜᴀᴘᴇ
11、Identity
Create an identity matrix with a specified dimension .
np.identity(4)
----------
array([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])#ᴅᴇꜰᴀᴜʟᴛ ᴅᴀᴛᴀ ᴛʏᴘᴇ ɪꜱ `ꜰʟᴏᴀᴛ`
Array operation
12、min
Returns the smallest value in the array .
axis: Axis for operation .
out: An array for storing output .
arr = np.array([1,1,2,3,3,4,5,6,6,2])
np.min(arr)
----------------
1
13、max
Returns the maximum value in the array .
np.max(arr)
------------------
6
14、unique
Returns an array sorted by all unique elements .
return_index: If True, Return the index of the array .
return_inverse: If True, Returns the subscript of a unique array .
return_counts: If True, Returns the number of occurrences of each unique element in the array .
axis: Axis to operate . By default , Arrays are considered flat .
np.unique(arr,return_counts=True)
---------------------
(
array([1, 2, 3, 4, 5, 6]), ## Unique elements
array([2, 2, 2, 1, 1, 2], dtype=int64) ## Count
)
15、mean
Returns the average number of arrays
np.mean(arr,dtype='int')
-------------------------------
3
16、medain
Returns the median of the array .
arr = np.array([[1,2,3],[5,8,4]])
np.median(arr)
-----------------------------
3.5
17、digitize
Returns the index of the container to which each value in the input array belongs .
bin: An array of containers .
right: Indicates whether the interval includes the right or left bin.
a = np.array([-0.9, 0.5, 0.9, 1, 1.2, 1.4, 3.6, 4.7, 5.3])
bins = np.array([0,1,2,3])
np.digitize(a,bins)
-------------------------------
array([0, 1, 1, 2, 2, 2, 4, 4, 4], dtype=int64)
Exp Value
x < 0 : 0
0 <= x <1 : 1
1 <= x <2 : 2
2 <= x <3 : 3
3 <=x : 4
Compares -0.9 to 0, here x < 0 so Put 0 in resulting array.
Compares 0.5 to 0, here 0 <= x <1 so Put 1.
Compares 5.4 to 4, here 3<=x so Put 4
18、reshape
It is NumPy One of the most commonly used functions in . It returns an array , It contains the same data with the new shape .
A = np.random.randint(15,size=(4,3))
A
----------------------
array([[ 8, 14, 1],
[ 8, 11, 4],
[ 9, 4, 1],
[13, 13, 11]])
A.reshape(3,4)
-----------------
array([[ 8, 14, 1, 8],
[11, 4, 9, 4],
[ 1, 13, 13, 11]])
A.reshape(-1)
-------------------
array([ 8, 14, 1, 8, 11, 4, 9, 4, 1, 13, 13, 11])
19、expand_dims
It is used to extend the dimension of the array .
arr = np.array([ 8, 14, 1, 8, 11, 4, 9, 4, 1, 13, 13, 11])
np.expand_dims(A,axis=0)
-------------------------
array([[ 8, 14, 1, 8, 11, 4, 9, 4, 1, 13, 13, 11]])
np.expand_dims(A,axis=1)
---------------------------
array([[ 8],
[14],
[ 1],
[ 8],
[11],
[ 4],
[ 9],
[ 4],
[ 1],
[13],
[13],
[11]])
20、squeeze
Reduce the dimension of the array by removing a single dimension .
arr = np.array([[ 8],[14],[ 1],[ 8],[11],[ 4],[ 9],[ 4],[ 1],[13],[13],[11]])
np.squeeze(arr)
---------------------------
array([ 8, 14, 1, 8, 11, 4, 9, 4, 1, 13, 13, 11])
21、count_nonzero
Calculates all non-zero elements and returns their counts .
a = np.array([0,0,1,1,1,0])
np.count_nonzero(a)
--------------------------
3
22、argwhere
Find and return all subscripts of non-zero elements .
a = np.array([0,0,1,1,1,0])
np.argwhere(a)
---------------------
array([[2],[3],[4]], dtype=int64)
23、argmax & argmin
argmax Return to the array Max Index of elements . It can be used to obtain the index of high probability prediction label in multi class image classification problems .
arr = np.array([[0.12,0.64,0.19,0.05]])
np.argmax(arr)
---------
1
argmin Will return in the array min Index of elements .
np.argmin(min)
------
3
24、sort
Sort the array .
kind: The sorting algorithm to use .{‘quicksort’, ‘mergesort’, ‘heapsort’, ‘stable’}
arr = np.array([2,3,1,7,4,5])
np.sort(arr)
----------------
array([1, 2, 3, 4, 5, 7])
25、abs
Return the absolute value of the element in the array . When the array contains negative numbers , It's very useful .
A = np.array([[1,-3,4],[-2,-4,3]])np.abs(A)
---------------
array([[1, 3, 4],
[2, 4, 3]])
26、round
Round the floating-point value to the specified number of decimal points .
decimals: The number of decimal points to keep .
a = np.random.random(size=(3,4))
a
-----
array([[0.81695699, 0.42564822, 0.65951417, 0.2731807 ],
[0.7017702 , 0.12535894, 0.06747666, 0.55733467],
[0.91464488, 0.26259026, 0.88966237, 0.59253923]])
np.round(a,decimals=0)
------------
array([[1., 0., 1., 1.],
[1., 1., 1., 1.],
[0., 1., 0., 1.]])
np.round(a,decimals=1)
-------------
array([[0.8, 0. , 0.6, 0.6],
[0.5, 0.7, 0.7, 0.8],
[0.3, 0.9, 0.5, 0.7]])
27、clip
It can keep the clipping value of the array within a range .
arr = np.array([0,1,-3,-4,5,6,7,2,3])
arr.clip(0,5)
-----------------
array([0, 1, 0, 0, 5, 5, 5, 2, 3])
arr.clip(0,3)
------------------
array([0, 1, 0, 0, 3, 3, 3, 2, 3])
arr.clip(3,5)
------------------
array([3, 3, 3, 3, 5, 5, 5, 3, 3])
Replace the values in the array
28、where
Return the array elements that meet the conditions .
condition: Matching conditions . If true Then return to x, otherwise y.
a = np.arange(12).reshape(4,3)
a
-------
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11]])
np.where(a>5) ## Get The Index
--------------------
(array([2, 2, 2, 3, 3, 3], dtype=int64),
array([0, 1, 2, 0, 1, 2], dtype=int64))
a[np.where(a>5)] ## Get Values
--------------------------
array([ 6, 7, 8, 9, 10, 11])
It can also be used to replace pandas df The elements in .
np.where(data[feature].isnull(), 1, 0)
29、put
Replace the specified element in the array with the given value .
a: Array
Ind: Index to be replaced .
V: Replacement value .
arr = np.array([1,2,3,4,5,6])
arr
--------
array([1, 2, 3, 4, 5, 6])
np.put(arr,[1,2],[6,7])
arr
--------
array([1, 6, 7, 4, 5, 6])
30、copyto
Copy the contents of one array into another .
dst: The goal is
src: source
arr1 = np.array([1,2,3])
arr2 = np.array([4,5,6])
print("Before arr1",arr1)
print("Before arr2",arr1)
np.copyto(arr1,arr2)
print("After arr1",arr1)
print("After arr2",arr2)
---------------------------
Before arr1 [1 2 3]
Before arr2 [4 5 6]
After arr1 [4 5 6]
After arr2 [4 5 6]
Set operations
31、 Find common elements
intersect1d The function returns all unique values in two arrays in a sorted manner .
Assume_unique: If true , Then assume that the input array is unique .
Return_indices: If it is true , Then return the index of the public element .
ar1 = np.array([1,2,3,4,5,6])
ar2 = np.array([3,4,5,8,9,1])
np.intersect1d(ar1,ar2)
---------------
array([1, 3, 4, 5])
np.intersect1d(ar1,ar2,return_indices=True)
---------------
(array([1, 3, 4, 5]), ## Common Elements
array([0, 2, 3, 4], dtype=int64),
array([5, 0, 1, 2], dtype=int64))
32、 Find different elements
np.setdiff1d The function returns arr1 In the arr2 All unique elements that do not exist in .
a = np.array([1, 7, 3, 2, 4, 1])
b = np.array([9, 2, 5, 6, 7, 8])
np.setdiff1d(a, b)
---------------------
array([1, 3, 4])
33、 Extract unique elements from two arrays
Setxor1d All unique values in the two arrays will be returned in order .
a = np.array([1, 2, 3, 4, 6])
b = np.array([1, 4, 9, 4, 36])
np.setxor1d(a,b)
--------------------
array([ 2, 3, 6, 9, 36])
34、 Merge
Union1d Function combines two arrays into one .
a = np.array([1, 2, 3, 4, 5])
b = np.array([1, 3, 5, 4, 36])
np.union1d(a,b)
-------------------
array([ 1, 2, 3, 4, 5, 36])
Array partition
35、 Horizontal segmentation
Hsplit The function divides the data horizontally into n An equal part .
A = np.array([[3,4,5,2],[6,7,2,6]])
np.hsplit(A,2) ## splits the data into two equal parts
---------------
[ array([[3, 4],[6, 7]]), array([[5, 2],[2, 6]]) ]
np.hsplit(A,4) ## splits the data into four equal parts
-----------------
[ array([[3],[6]]), array([[4],[7]]),
array([[5],[2]]), array([[2],[6]]) ]
36、 Vertical segmentation
Vsplit Divide the data vertically into n An equal part .
A = np.array([[3,4,5,2],[6,7,2,6]])
np.vsplit(A,2)
----------------
[ array([[3, 4, 5, 2]]), array([[6, 7, 2, 6]]) ]
Array overlay
37、 Horizontal superposition
hstack An array will be appended to the end of another array .
a = np.array([1,2,3,4,5])
b = np.array([1,4,9,16,25])
np.hstack((a,b))
---------------------
array([ 1, 2, 3, 4, 5, 1, 4, 9, 16, 25])
38、 Vertical overlay
vstack Stack one array on top of another .
np.vstack((a,b))
----------------------
array([[ 1, 2, 3, 4, 5],
[ 1, 4, 9, 16, 25]])
Array comparison
39、allclose
If two arrays have the same shape , be Allclose Function finds whether two arrays are equal or approximately equal according to the tolerance value .
a = np.array([0.25,0.4,0.6,0.32])
b = np.array([0.26,0.3,0.7,0.32])
tolerance = 0.1 ## Total Difference
np.allclose(a,b,tolerance)
---------
False
tolerance = 0.5
np.allclose(a,b,tolerance)
----------
True
40、equal
It compares each element of two arrays , If the elements match, it returns True.
np.equal(arr1,arr2)
-------------
array([ True, True, True, False, True, True])
Repeated array elements
repeat
It is used to repeat the elements in the array n Time .

A: Elements of repetition
Repeats: Number of repetitions .
np.repeat('2017',3)
---------------------
array(['2017', '2017', '2017'], dtype='<U4')
Let's look at a more practical example , We have a data set containing annual sales .
fruits = pd.DataFrame([
['Mango',40],
['Apple',90],
['Banana',130]
],columns=['Product','ContainerSales'])
fruits
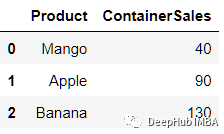
In the data set , Missing year column . We try to use numpy Add it .
fruits['year'] = np.repeat(2020,fruits.shape[0])
fruits
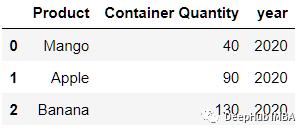
41、tile
By repeating A,rep Next, construct an array .
np.tile("Ram",5)
-------
array(['Ram', 'Ram', 'Ram', 'Ram', 'Ram'], dtype='<U3')
np.tile(3,(2,3))
-------
array([[3, 3, 3],
[3, 3, 3]])
Einstein's summation
42、einsum
This function is used to calculate multidimensional and linear algebraic operations on an array .
a = np.arange(1,10).reshape(3,3)
b = np.arange(21,30).reshape(3,3)
np.einsum('ii->i',a)
------------
array([1, 5, 9])
np.einsum('ji',a)
------------
array([[1, 4, 7],
[2, 5, 8],
[3, 6, 9]])
np.einsum('ij,jk',a,b)
------------
array([[150, 156, 162],
[366, 381, 396],
[582, 606, 630]])
p.einsum('ii',a)
----------
15
Statistical analysis
43、 Histogram
This is a Numpy Important statistical analysis function , The histogram value of a group of data can be calculated .
A = np.array([[3, 4, 5, 2],
[6, 7, 2, 6]])
np.histogram(A)
-------------------
(array([2, 0, 1, 0, 1, 0, 1, 0, 2, 1], dtype=int64),
array([2. , 2.5, 3. , 3.5, 4. , 4.5, 5. , 5.5, 6. , 6.5, 7. ]))
44、 Percentiles
Calculates the of data along a specified axis Q-T-T Percentiles .
a: Input .
q: The percentile to be calculated .
overwrite_input: If true, The input array is allowed to modify the intermediate calculation to save memory .
a = np.array([[2, 4, 6], [4, 8, 12]])
np.percentile(a, 50)
-----------
5.0
np.percentile(a, 10)
------------
3.0
arr = np.array([2,3,4,1,6,7])
np.percentile(a,5)
------------
2.5
45、 Standard deviation and variance
std and var yes NumPy Two functions of , Used to calculate the standard deviation and variance along the axis .
a = np.array([[2, 4, 6], [4, 8, 12]])
np.std(a,axis=1)
--------
array([1.63299316, 3.26598632])
np.std(a,axis=0) ## Column Wise
--------
array([1., 2., 3.])
np.var(a,axis=1)
-------------------
array([ 2.66666667, 10.66666667])
np.var(a,axis=0)
-------------------
array([1., 4., 9.])
Array printing
46、 Displays floating point numbers with two decimal values
np.set_printoptions(precision=2)
a = np.array([12.23456,32.34535])
print(a)
------------
array([12.23,32.34])
47、 Set the maximum value of the print array
np.set_printoptions(threshold=np.inf)
48、 Increase the number of elements in a row
np.set_printoptions(linewidth=100) ## The default is 75
Save and load data
49、 preservation
savetxt Used to save the contents of an array in a text file .
arr = np.linspace(10,100,500).reshape(25,20)
np.savetxt('array.txt',arr)
50、 load
Used to load arrays from text files , It takes the file name as a parameter .
np.loadtxt('array.txt')
That's all 50 individual numpy Common functions , I hope it helped you .
https://avoid.overfit.cn/post/f47bb7762ccb41189baff5fe6a10403a
author :Abhay Parashar
边栏推荐
- Is this the feeling of being spoiled by bytes?
- Nodejs教程之Expressjs一篇文章快速入门
- [redis design and implementation] part I: summary of redis data structure and objects
- Seven original sins of embedded development
- Data Lake (VIII): Iceberg data storage format
- Forward maximum matching method
- ICML 2022 | flowformer: task generic linear complexity transformer
- 技术分享 | 抓包分析 TCP 协议
- c语言char, wchar_t, char16_t, char32_t和字符集的关系
- @GetMapping、@PostMapping 和 @RequestMapping详细区别附实战代码(全)
猜你喜欢

3D人脸重建:从基础知识到识别/重建方法!

Yuan Xiaolin: safety is not only a standard, but also Volvo's unchanging belief and pursuit
Fastjson parses JSON strings (deserialized to list, map)
20220211 failure - maximum amount of data supported by mongodb

2022菲尔兹奖揭晓!首位韩裔许埈珥上榜,四位80后得奖,乌克兰女数学家成史上唯二获奖女性
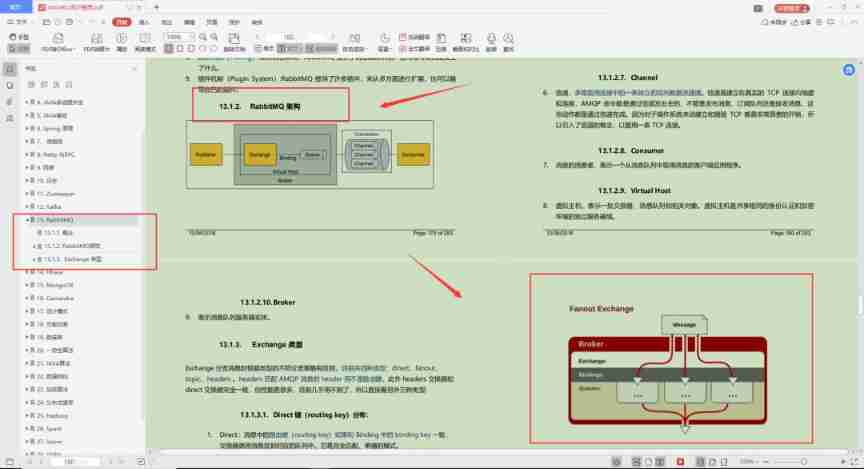
After working for 5 years, this experience is left when you reach P7. You have helped your friends get 10 offers
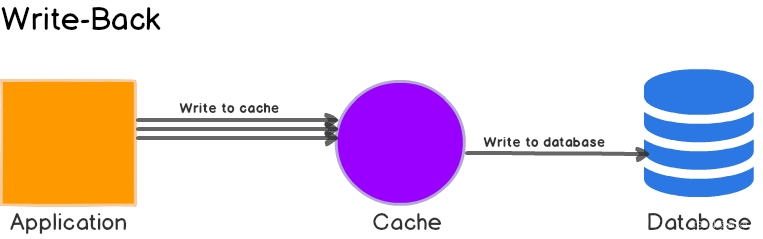
Caching strategies overview

Aike AI frontier promotion (7.6)
Aiko ai Frontier promotion (7.6)
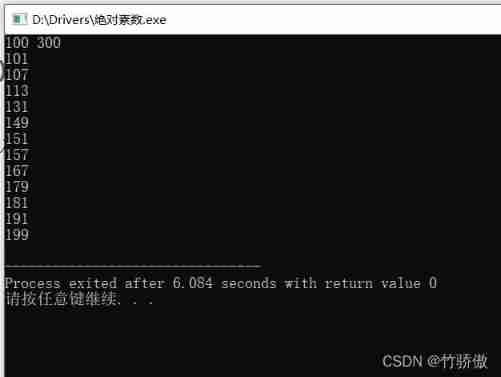
Absolute primes (C language)
随机推荐
string的底层实现
Torch Cookbook
红杉中国,刚刚募资90亿美元
【滑动窗口】第九届蓝桥杯省赛B组:日志统计
OneNote in-depth evaluation: using resources, plug-ins, templates
Technology sharing | packet capturing analysis TCP protocol
R语言做文本挖掘 Part4文本分类
【力扣刷题】32. 最长有效括号
How do I remove duplicates from the list- How to remove duplicates from a list?
3D人脸重建:从基础知识到识别/重建方法!
JS get array subscript through array content
js 根据汉字首字母排序(省份排序) 或 根据英文首字母排序——za排序 & az排序
Why does MySQL index fail? When do I use indexes?
字符串的使用方法之startwith()-以XX开头、endsWith()-以XX结尾、trim()-删除两端空格
快讯:飞书玩家大会线上举行;微信支付推出“教培服务工具箱”
How to implement common frameworks
抖音将推独立种草App“可颂”,字节忘不掉小红书?
This year, Jianzhi Tencent
3D face reconstruction: from basic knowledge to recognition / reconstruction methods!
In JS, string and array are converted to each other (I) -- the method of converting string into array