当前位置:网站首页>20220211 failure - maximum amount of data supported by mongodb
20220211 failure - maximum amount of data supported by mongodb
2022-07-06 21:06:00 【It migrant worker brother goldfish】
Deal with various needs and faults in daily work , In particular, fault response is particularly important .
If the fault is not handled in time , The loss caused , In my previous sentence : Every second is money .
Brother goldfish suddenly thought , Make a new column to record the faults encountered in daily work , I hope my sharing and summary can enlighten you .
Maybe it's fate , I was in my new unit yesterday ( Outsourcing to a large company ) First day of mobilization , Not familiar with various environments , They were taken up to follow up the faults encountered .
Fortunately, , Although I already have 11 I haven't worked in the front line of technology for months , But my technical skills have always been . Again reflected in the foundation , thinking , Experience is really important , Let me locate the problem and let relevant personnel communicate the subsequent solutions .

Fault description :
At midday , I went to... With the delivery manager XX courtyard 5 In the information center of the building , What we are dealing with is developers ( ji ao) Development and company support engineer , I learned the relevant information from everyone :
Application and use MongoDB 3.4, It used to be 3 Set up a cluster of machines + 1. Arbitration node , On Thursday, developers tried to take a node for single node test , Therefore, one node data has been deleted . But I took a snapshot on Thursday night ( Use XX cloud ), So there is a snapshot backup .
The current situation of the day :
1. One master one slave one arbitration node
2. Master and slave nodes cannot start at the same time
2. When starting the master node first , The node status is SECONDARY, Restart the slave node , The slave node cannot start , The process is shut down when an exception occurs directly .Test results :
Start the master node as a stand-alone , Can't read or write , When writing, the same exception occurs as the slave node mentioned above . Subsequently, delete some data of the master node , The master node is readable and writable .
Here are some related logs ( Because I just entered , So I didn't get any more information , Now you can only check the relevant logs on site )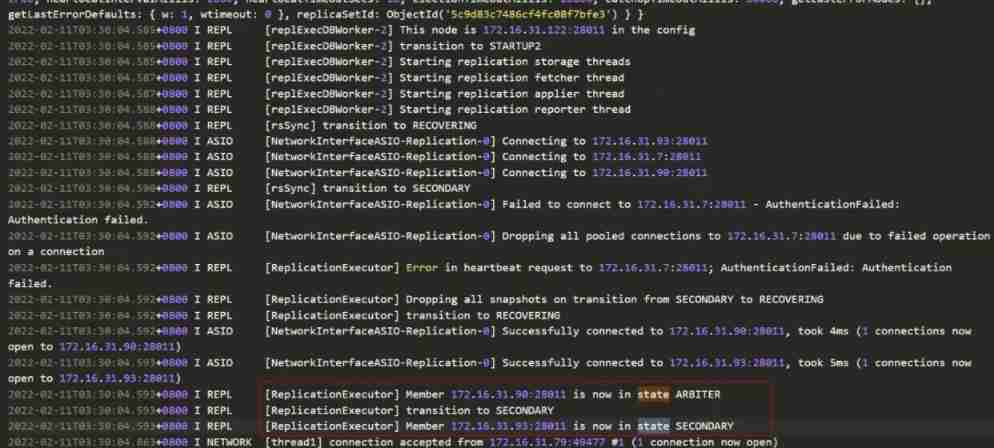
The primary node is always secondary The state of , So you can only read , Can't write , There are problems in the whole cluster .
Therefore, relevant uploading operations cannot be carried out in business ( Can't write ), However, various queries can be made .

Make complaints about it :
o((⊙﹏⊙))o Go to the scene , The discovery libraries are all running in windows server On , How painful it is to view logs ...
Field personnel are not familiar with their own application architecture , Ask whether the concurrency of applications is large ? I don't know. ( If concurrency is not great , Cluster wool )... So you need to know all kinds of things when you go to the scene , Time consuming ...
The above two points hinder the efficiency of troubleshooting ...*️*️*️
then , Why are all kinds of problems on the cluster still tangled on the scene , Why not take restoring business first as the guide ?*️*️*️
It also shows that there is no corresponding emergency plan . You can also think about how many things you need to improve in your future work .
Test and try :
Looking at them struggling with the cluster , I'm new here , I wanted to look around , But thinking about , Since I follow you , If they can't handle , It will only definitely work overtime ... You know, it's far away , this XX The academy is in Science City , I added Guangyuan Road in Baiyun District ... So I couldn't help making a noise :
“ First, it is oriented to restore business , Don't worry about the problems in the cluster , First restart the service with a single node , Resume business . According to your feedback , Using concurrency is not big , Single node is ok , Recover first .”
It is suggested that the developer find a single node with data , Let him modify different ports to start the database .
After starting , There was a phenomenon of speaking on Thursday night , Delete some data of the node , Nodes are readable and writable .
Let development test phenomena , After deleting some files , Indeed, you can upload files , But when uploading large files , You can't continue uploading , It will cause the database to collapse , Restart the library can only read , Writing again will collapse .
From the log , There is no effective error reporting information at all .(win It's painful to read the log ... Why don't linux,low Is it like this ?)
See this phenomenon , I'm by the side , I suggest you test it again .
At this time, I will record the approximate capacity , Look at the size of the file he deleted , Then compare the uploaded capacity .
During the test , Just upload the size , No more than the deleted capacity can be uploaded , exceed , It just broke down . And the disk capacity is enough .
See here , A sudden inspiration , Is there any limitation ?
This is the time , Look up your notes and find online articles immediately .

Fault analysis :
Check your notes , There is a passage :
Limit
MongoDB Generally applicable to 64 Bit operating system ,32 Bit systems can only address 4GB Memory , It means that the data set contains metadata and stores up to 4GB,Mongodb You can't store additional data , Strongly recommended 32 Bit system uses Mongodb You can test it yourself , The production environment is used everywhere 64 Bit operating system .
The maximum document size helps ensure that a single document does not use too much RAM Or occupy too much bandwidth in the transmission process . To store documents larger than the maximum size ,MongoDB Provides GridFS API.MongoDB Support BSON The nesting level of documents should not exceed 100.
Replica set
stay Mongodb3.0 Replica set members in support of 50 individual , That is to say, the replica set is supported 50 Nodes , Replica set data support for each node 32T, It is recommended that the data of each instance of the replica set should not exceed 4T, Large amount of data, backup and recovery time will be long .
coming , See the point ,“ It is recommended that the data of each instance of the replica set should not exceed 4T”, Then immediately let the corresponding development check ,3915G, At this time, I finally know the problem , No wonder some data can be rewritten after being deleted , Because it has reached the upper limit of others , So I can't write any more .
Check the website (https://docs.mongodb.com/v3.4/reference/limits/) Specific description :
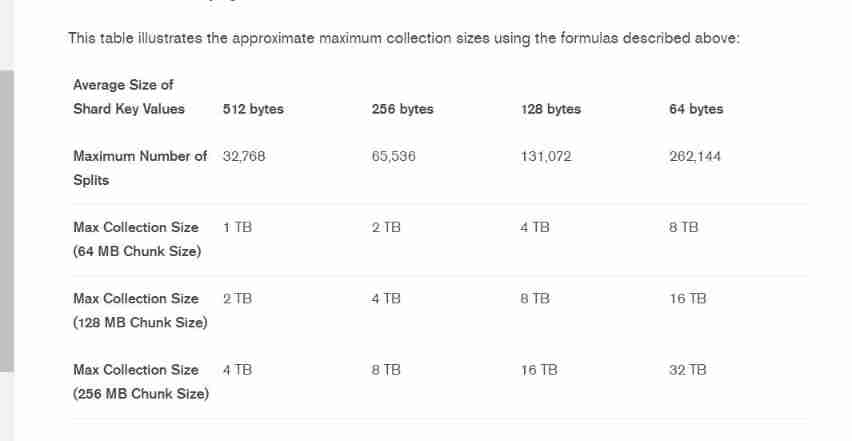
Storage limits
Slicing will use the default chunk The size is 64M, If our slice key ( Chip key )values The value is 512 byte , Sharding nodes support maximum 32768 individual , The maximum set size is 1TB.
The size of a chip key cannot exceed 512 byte .
If you don't make relevant settings , By default chunk The size is 64M Under the circumstances , Use 128 byte , The biggest is just 4TB The capacity of .
Don't think about it , Certainly not considering all kinds of , and , I can't use 64 Bytes are so small values value .
Therefore, it is inferred that the problem is caused by the fast reaching capacity limit of a single instance .

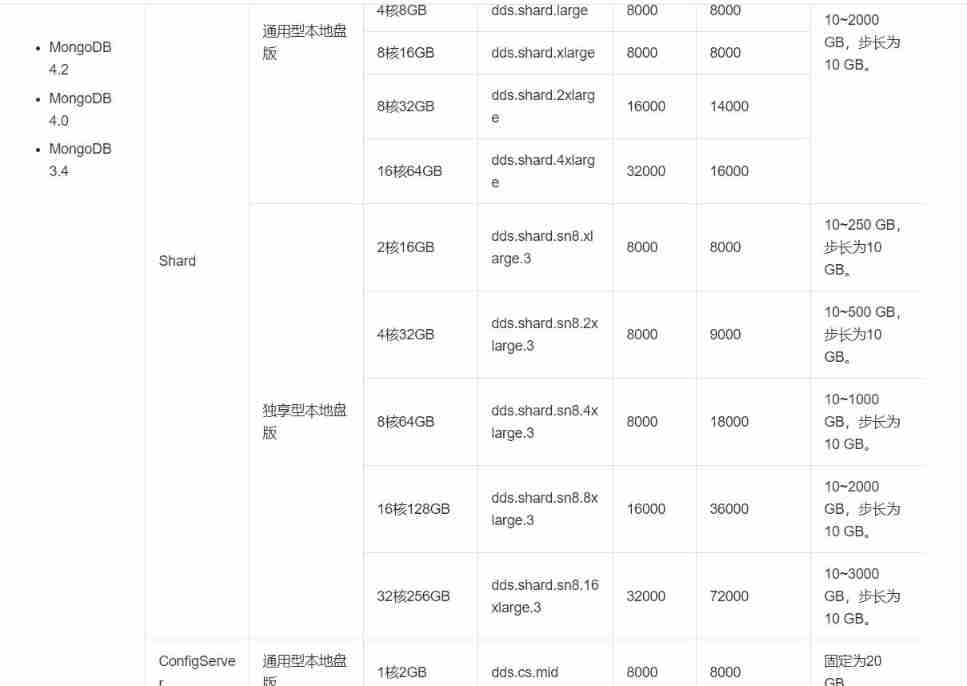
Use Alibaba cloud's MongoDB Specifications can also be seen :

Fault handling :
Do this , It's what I can do on my first day .
Then let the developer communicate with the operation and maintenance manager of the whole group to solve the subsequent problem .( I'm new here , The environment is completely unfamiliar )
The person in charge of the developer , Operations Manager , user , After discussion and communication , Back up the data first ( Yes 2 The data of nodes is , And there are snapshots , but zheng wu Snapshots of clouds once had pits , In my heart , There is still a physical backup conservative point , But the backup must be too long because there are too many small files , So for the time being ), Then count 2020 Years ago ( After statistics , Only 200 many G), Then delete the data , In order to solve the urgent problem .
This problem ultimately requires developers to deal with the corresponding logic .
When choosing a database , Also evaluate the characteristics of the database , In the past, the amount of data can meet , But I certainly didn't expect it to be close 2 The data volume in has exploded .
I also heard that the subsequent developers will carry out major rectification .
Then this matter will come to an end ...

summary
That's all 【 Brother goldfish 】 The trouble I encountered on my first day at work ( I haven't started to understand anything , Just ...). I hope it can be helpful to the little friends who see this article .
If this article 【 article 】 It helps you , I hope I can give 【 Brother goldfish 】 Point a praise , It's not easy to create , Compared with the official statement , I prefer to use 【 Easy to understand 】 To explain every point of knowledge with your writing , If there is a pair of 【 Operation and maintenance technology 】 Interested in , You are welcome to pay attention to ️️️ 【 Brother goldfish 】️️️, I will bring you great 【 Harvest and surprise 】!

边栏推荐
- 审稿人dis整个研究方向已经不仅仅是在审我的稿子了怎么办?
- ICML 2022 | Flowformer: 任务通用的线性复杂度Transformer
- 爱可可AI前沿推介(7.6)
- 2022菲尔兹奖揭晓!首位韩裔许埈珥上榜,四位80后得奖,乌克兰女数学家成史上唯二获奖女性
- 【论文解读】用于白内障分级/分类的机器学习技术
- PG基础篇--逻辑结构管理(事务)
- Variable star --- article module (1)
- (work record) March 11, 2020 to March 15, 2021
- 性能测试过程和计划
- 【深度学习】PyTorch 1.12发布,正式支持苹果M1芯片GPU加速,修复众多Bug
猜你喜欢

MLP (multilayer perceptron neural network) is a multilayer fully connected neural network model.

2022 fields Award Announced! The first Korean Xu Long'er was on the list, and four post-80s women won the prize. Ukrainian female mathematicians became the only two women to win the prize in history
![Mécanisme de fonctionnement et de mise à jour de [Widget Wechat]](/img/cf/58a62a7134ff5e9f8d2f91aa24c7ac.png)
Mécanisme de fonctionnement et de mise à jour de [Widget Wechat]

Aiko ai Frontier promotion (7.6)

Pinduoduo lost the lawsuit, and the case of bargain price difference of 0.9% was sentenced; Wechat internal test, the same mobile phone number can register two account functions; 2022 fields Awards an

Common English vocabulary that every programmer must master (recommended Collection)
Redis insert data garbled solution

【mysql】触发器
Opencv learning example code 3.2.3 image binarization

966 minimum path sum
随机推荐
R语言可视化两个以上的分类(类别)变量之间的关系、使用vcd包中的Mosaic函数创建马赛克图( Mosaic plots)、分别可视化两个、三个、四个分类变量的关系的马赛克图
Activiti global process monitors activitieventlistener to monitor different types of events, which is very convenient without configuring task monitoring in acitivit
Kubernetes learning summary (20) -- what is the relationship between kubernetes and microservices and containers?
[MySQL] basic use of cursor
Minimum cut edge set of undirected graph
2022 fields Award Announced! The first Korean Xu Long'er was on the list, and four post-80s women won the prize. Ukrainian female mathematicians became the only two women to win the prize in history
新型数据库、多维表格平台盘点 Notion、FlowUs、Airtable、SeaTable、维格表 Vika、飞书多维表格、黑帕云、织信 Informat、语雀
字符串的使用方法之startwith()-以XX开头、endsWith()-以XX结尾、trim()-删除两端空格
Reference frame generation based on deep learning
The mail command is used in combination with the pipeline command statement
愛可可AI前沿推介(7.6)
User defined current limiting annotation
2022菲尔兹奖揭晓!首位韩裔许埈珥上榜,四位80后得奖,乌克兰女数学家成史上唯二获奖女性
Solution to the 38th weekly match of acwing
自定义限流注解
Build your own application based on Google's open source tensorflow object detection API video object recognition system (IV)
Dynamically switch data sources
Web开发小妙招:巧用ThreadLocal规避层层传值
Entity alignment two of knowledge map
Summary of different configurations of PHP Xdebug 3 and xdebug2