当前位置:网站首页>Persistence / caching of RDD in spark
Persistence / caching of RDD in spark
2022-07-06 21:44:00 【Big data Xiaochen】

Yes RDD In the process of conversion , If you want to treat someone in the middle RDD Multiple reuse , For example, yes. RDD Output multiple times , So by default, every time Action Will trigger a job, Every job Will load data from scratch and calculate , A waste of time . If the logical RDDN Data persistence to specific storage media, such as 【 Memory 】、【 disk 】、【 Out of heap memory 】, Then only calculate this once RDD, Improve program performance
RDD call cache/persist All are 【lazy 】 operator , Need one 【Action】 After operator trigger ,( Usually use count To trigger ).RDD Data will be persisted to memory or disk . Later operations , Will get data directly from memory or disk .
below 3 Both are only persistent to 【 Memory 】
rdd.persist()
rdd.cache()
rdd.persist(StorageLevel.MEMORY_ONLY)
More storage levels
rdd.persist(level : StorageLevel)
StorageLevel
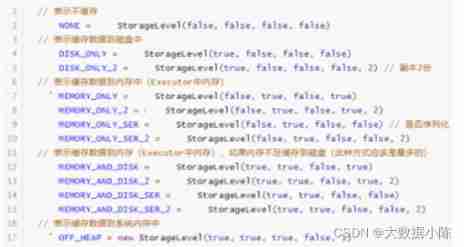
_ONLY: Just save the data to 【 Memory 】 or 【 disk 】
_2: Backup when data is persistent 【2】 Share
_SER: take RDD The elements of 【 serialize 】, Compress , Convenient network transmission .
MEMORY_AND_DISK_SER_2 : Put the data 【 serialize 】 Save to memory , If 【 Memory 】 Not enough , Continue to overflow 【 disk 】, And backup 2 Time .
Release cache / Persistence
When caching RDD When data is no longer used , Consider releasing resources
rdd.unpersit()
# -*- coding:utf-8 -*-
# Desc:This is Code Desc
import os
import json
import re
import time
from pyspark import SparkConf, SparkContext
os.environ['SPARK_HOME'] = '/export/server/spark'
PYSPARK_PYTHON = "/root/anaconda3/bin/python3.8"
# When multiple versions exist , Failure to specify is likely to result in an error
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
#1- establish SparkContext Context object
conf=SparkConf().setAppName("2_rdd_from_external").setMaster("local[*]")
sc=SparkContext(conf=conf)
#2 Read the file
rdd=sc.textFile("file:///export/pyworkspace/pyspark_sz26/pyspark-sparkcore-3.1.2/data/apache.log")
#3 Wash and extract ip,\\s+ Represents general white space characters , such as tab key , Space , Line break ,\r\t
rdd2=rdd.map(lambda line : re.split('\\s+',line)[0])
# Yes rdd2 Cache persistence
rdd2.cache()
pv = rdd2.count()
#4 Calculation pv, Print
pv=rdd2.count()
print('pv=',pv)
#5 Calculation uv, Print
uv=rdd2.distinct().count()
print('uv=',uv)
time.sleep(600)
sc.stop()
When to use cache/persist ?
When RDD By 【 many 】 Secondary multiplexing
When RDD The previous calculation process is very 【 Complex and expensive 】( Such as through 【JDBC】 Come to ), And it has been used many times .
边栏推荐
- JPEG2000-Matlab源码实现
- [Li Kou brush questions] 32 Longest valid bracket
- Reinforcement learning - learning notes 5 | alphago
- FZU 1686 龙之谜 重复覆盖
- Tiktok will push the independent grass planting app "praiseworthy". Can't bytes forget the little red book?
- Nodejs tutorial expressjs article quick start
- C# 如何在dataGridView里设置两个列comboboxcolumn绑定级联事件的一个二级联动效果
- guava:Collections. The collection created by unmodifiablexxx is not immutable
- Yyds dry inventory run kubeedge official example_ Counter demo counter
- ACdreamoj1110(多重背包)
猜你喜欢
![[interpretation of the paper] machine learning technology for Cataract Classification / classification](/img/0c/b76e59f092c1b534736132faa76de5.png)
[interpretation of the paper] machine learning technology for Cataract Classification / classification
Why does MySQL index fail? When do I use indexes?

袁小林:安全不只是标准,更是沃尔沃不变的信仰和追求
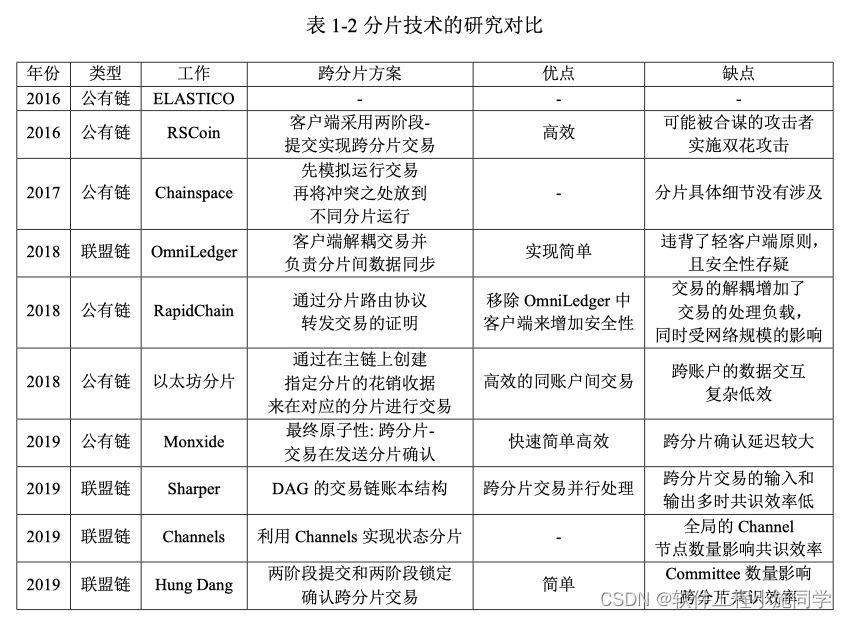
Summary of cross partition scheme
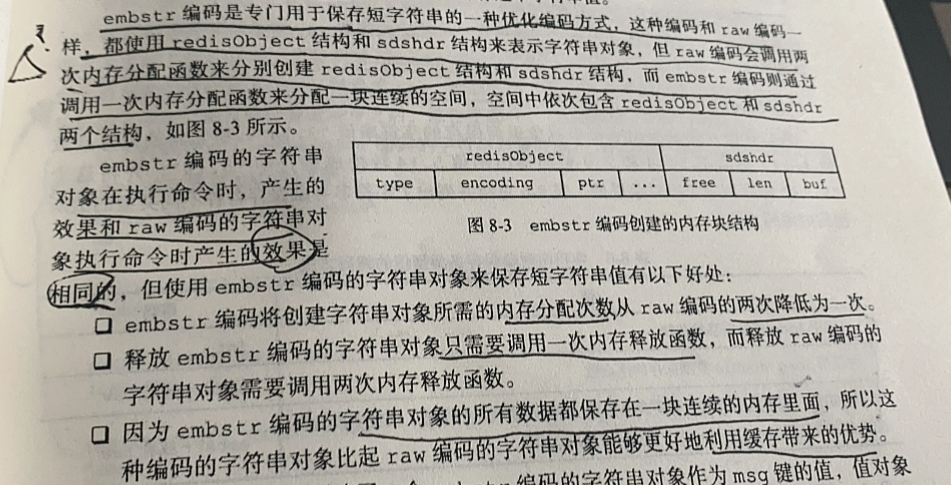
【Redis设计与实现】第一部分 :Redis数据结构和对象 总结
![[in depth learning] pytorch 1.12 was released, officially supporting Apple M1 chip GPU acceleration and repairing many bugs](/img/66/4d94ae24e99599891636013ed734c5.png)
[in depth learning] pytorch 1.12 was released, officially supporting Apple M1 chip GPU acceleration and repairing many bugs
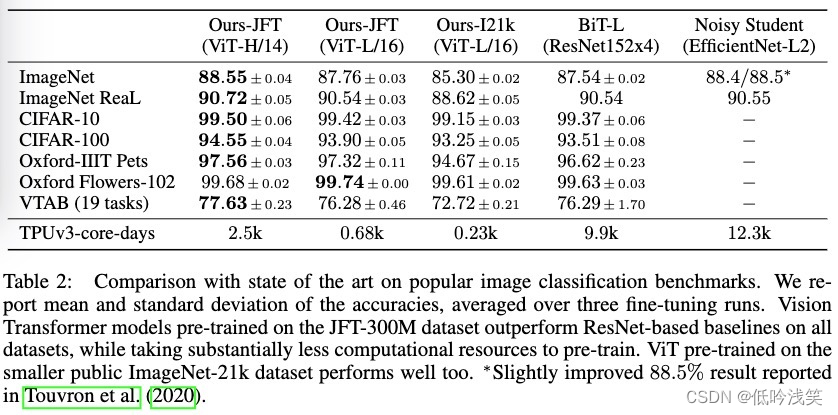
Vit paper details

互联网快讯:吉利正式收购魅族;胰岛素集采在31省全面落地
1292_ Implementation analysis of vtask resume() and xtask resume fromisr() in freeros
![Leetcode topic [array] -118 Yang Hui triangle](/img/77/d8a7085968cc443260b4c0910bd04b.jpg)
Leetcode topic [array] -118 Yang Hui triangle

随机推荐
Acdreamoj1110 (multiple backpacks)
[redis design and implementation] part I: summary of redis data structure and objects
爬虫实战(五):爬豆瓣top250
Redistemplate common collection instructions opsforhash (IV)
In JS, string and array are converted to each other (II) -- the method of converting array into string
通过数字电视通过宽带网络取代互联网电视机顶盒应用
First batch selected! Tencent security tianyufeng control has obtained the business security capability certification of the ICT Institute
分糖果
强化学习-学习笔记5 | AlphaGo
Uni app app half screen continuous code scanning
代理和反向代理
3D face reconstruction: from basic knowledge to recognition / reconstruction methods!
JPEG2000 matlab source code implementation
SQL:存储过程和触发器~笔记
What's the best way to get TFS to output each project to its own directory?
Guava: three ways to create immutablexxx objects
C语言:#if、#def和#ifndef综合应用
Is it profitable to host an Olympic Games?
@GetMapping、@PostMapping 和 @RequestMapping详细区别附实战代码(全)
Sdl2 source analysis 7: performance (sdl_renderpresent())