当前位置:网站首页>Four common ways and performance comparison of ArrayList de duplication (jmh performance analysis)
Four common ways and performance comparison of ArrayList de duplication (jmh performance analysis)
2022-07-06 21:16:00 【I hope to wake up naturally every day】
List of articles
Here are four practical ArrayList The way to remove weight , At the same time, I will be practical Oracle Performance testing tools provided JMH(Java Microbenchmark Harness,Java Micro benchmark test suite ) Let's test the performance of these methods . Of course, the test here is carried out when the system performance is sufficient , See who can squeeze the performance of the machine better .
Of course , That uncommon way of weight removal is not involved here .
ArrayList Common methods of weight removal
ArrayList There are four common methods of weight removal , Namely HashSet duplicate removal 、LinkedHashSet duplicate removal 、stream Stream single thread de duplication 、stream Stream multithreading de duplication . The data structures involved here are reviewed first :
ArrayList( Order is not unique ):Object[], Thread unsafe , Insert delete slow ( Array move ), Quick query ( Random access ).
HashSet( Disorder is unique ): Hashtable , be based on HashMap Realization ,hashmap Of key Store its value . Thread unsafe .
LinkedHashSet( Orderly and unique ): Hashtable + Linked list ( The linked list stores the insertion order ), It is HashSet Subclass , There is only constructor inside . Thread unsafe .
HashSet & LinkedHashSet
// data
List<Integer> arrayList = new ArrayList<Integer>(){
{
add(3);add(2);add(4);add(2);add(3);add(5);add(4);add(5);}};
// HashSet duplicate removal
ArrayList<Integer> hashSetList = new ArrayList<>(new HashSet<>(arrayList));
// LinkedHashSet duplicate removal
ArrayList<Integer> linkedHashSetList = new ArrayList<>(new LinkedHashSet<>(arrayList));
Hit the breakpoint to check the data

stream & parallelStream
List<Integer> arrayList = new ArrayList<Integer>(){
{
add(3);add(2);add(4);add(2);add(3);add(5);add(4);add(5);}};
// stream duplicate removal
List<Integer> streamList = arrayList.stream().distinct().collect(Collectors.toList());
// parallelStream duplicate removal
List<Integer> parallelStreamList = arrayList.parallelStream().distinct().collect(Collectors.toList());
Set a breakpoint to view the data
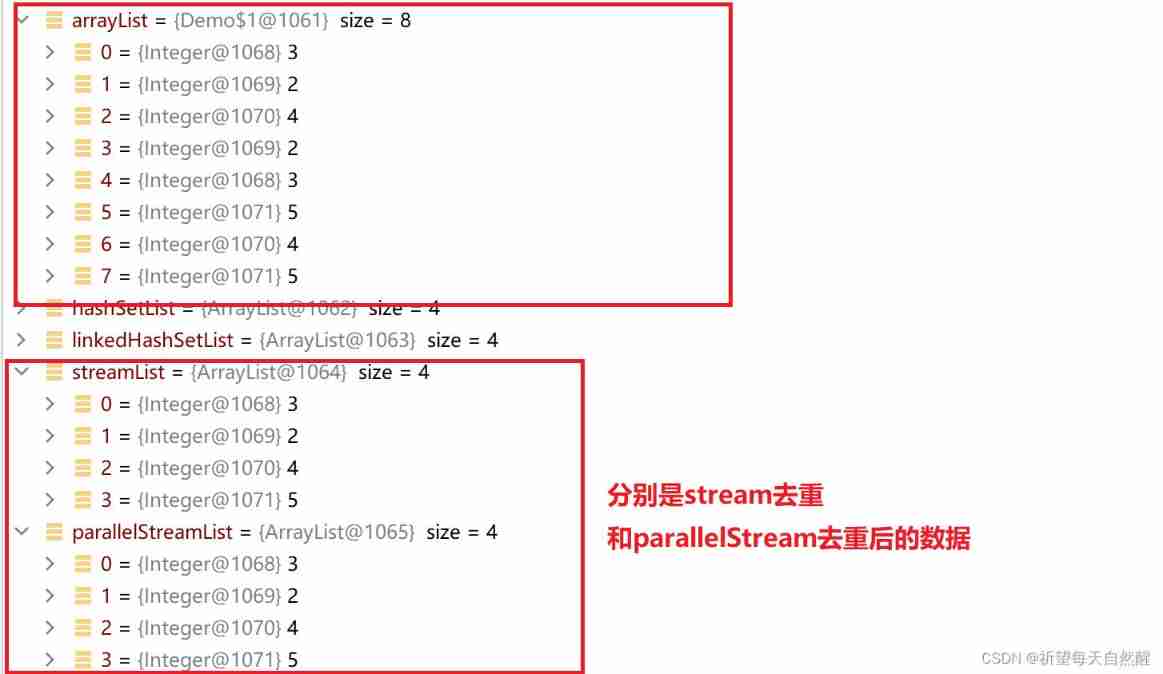
The above is the simple data De duplication operation method .
JMH Performance analysis
Use Oracle Official performance testing tools JMH(Java Microbenchmark Harness,JAVA Micro benchmark test suite ) Let's test this 4 Kind of The performance of the weight removal method .
First , Let's introduce JMH frame , stay pom.xml Add the following configuration to the file :
<!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-core -->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.23</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-generator-annprocess -->
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.23</version>
<scope>provided</scope>
</dependency>
I have written the version number , The latest version is recommended .
Now write the test code , as follows
@BenchmarkMode(Mode.AverageTime) // Test completion time
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@Warmup(iterations = 2, time = 1, timeUnit = TimeUnit.SECONDS) // preheating 2 round , Every time 1s
@Measurement(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)// test 5 round , Every time 1s
@Fork(1) // fork 1 Threads
@State(Scope.Thread) // One instance per test thread
public class ArrayListDistinctTest {
static List<Integer> arrayList = new ArrayList<Integer>(){
{
// altogether 2000000 Data
for (int i = 0; i < 1000000; i++) add(i);
for (int i = 0; i < 1000000; i++) add(i);
}};
public static void main(String[] args) throws RunnerException {
// Start benchmarking
Options opt = new OptionsBuilder()
.include(ArrayListDistinctTest.class.getSimpleName()) // Test class to import
.output("C:/Users/86177/Desktop/jmh-map.log") // Output test results file
.build();
new Runner(opt).run(); // Perform the test
}
@Benchmark
public void hashSet(){
new ArrayList<>(new HashSet<>(arrayList));
}
@Benchmark
public void linkedHashSet(){
new ArrayList<>(new LinkedHashSet<>(arrayList));
}
@Benchmark
public void stream(){
arrayList.stream().distinct().collect(Collectors.toList());
}
@Benchmark
public void parallelStream(){
arrayList.parallelStream().distinct().collect(Collectors.toList());
}
}
All have been added @Benchmark The annotated method will be tested , perform main The method can . And as the code shows , I tested a total of 2000000( Two million ) Data , Half is repeated . The test file has been printed to the desktop , I will post the performance comparison data here :
Benchmark Mode Cnt Score Error Units
ArrayListDistinctTest.hashSet avgt 5 37251270.300 ± 10458771.326 ns/op
ArrayListDistinctTest.linkedHashSet avgt 5 40382889.634 ± 11785155.916 ns/op
ArrayListDistinctTest.parallelStream avgt 5 157258934.286 ± 34670245.903 ns/op
ArrayListDistinctTest.stream avgt 5 38513055.914 ± 3839780.617 ns/op
among Units by ns/op It means execution completion time ( It's in nanoseconds ), and Score List as average execution time , ± Symbols indicate errors . It can be seen from the above results , Two Set It's similar in performance , And the execution speed is very fast , Next is stream .
notes : The above results are based on the test environment :JDK 1.8 / Win10 16GB (2021H) / Idea 2022.3
Conclusion
Except for the large amount of data above , I also tested into 1000 Small amount of data .HashSet and LinkedHashSet The performance of is still very satisfactory , And for stream In terms of performance, when the amount of data is relatively small Set high (parallelStream Performance is not as good as stream, Here is a simple analysis ). It is recommended to use HashSet and LinkedHashSet duplicate removal .
De duplication selection
Based on the above , Yes ArrayList During the weight removal operation , Recommended LinkedHashSet.
In the final analysis, the de duplication operation is based on the data of the set , You see Set Sets are not allowed to repeat , Of course, first choose it . Then let's take a look at the requirements , Such as HashSet Data disorder after de duplication ,LinkedHashSet After de duplication, the data is orderly, but the performance is not HashSet good .
Stream There are single threaded and multi-threaded flow operations for flow selection , The performance of multithreaded operation flow here is better than that of single thread operation , It is necessary to judge whether the current operation may have concurrency risks .
Be careful. : In the computer system , Multithreading is not necessarily better than multithreading , The reason why single threading may be better than multithreading is usually CPU Performance waste caused by switching operation threads , There will be a thread sleep and thread wake operation . For example, common Redis It is designed as a single thread .
边栏推荐
- 【OpenCV 例程200篇】220.对图像进行马赛克处理
- Pat 1078 hashing (25 points) ⼆ times ⽅ exploration method
- [interpretation of the paper] machine learning technology for Cataract Classification / classification
- 【力扣刷题】32. 最长有效括号
- [in depth learning] pytorch 1.12 was released, officially supporting Apple M1 chip GPU acceleration and repairing many bugs
- Le langage r visualise les relations entre plus de deux variables de classification (catégories), crée des plots Mosaiques en utilisant la fonction Mosaic dans le paquet VCD, et visualise les relation
- Torch Cookbook
- Swagger UI tutorial API document artifact
- In JS, string and array are converted to each other (I) -- the method of converting string into array
- Deployment of external server area and dual machine hot standby of firewall Foundation
猜你喜欢
HMS core machine learning service creates a new "sound" state of simultaneous interpreting translation, and AI makes international exchanges smoother

基于深度学习的参考帧生成

KDD 2022 | 通过知识增强的提示学习实现统一的对话式推荐
【mysql】游标的基本使用
OneNote in-depth evaluation: using resources, plug-ins, templates

【滑动窗口】第九届蓝桥杯省赛B组:日志统计

【力扣刷题】一维动态规划记录(53零钱兑换、300最长递增子序列、53最大子数组和)
2017 8th Blue Bridge Cup group a provincial tournament

3D face reconstruction: from basic knowledge to recognition / reconstruction methods!

Seven original sins of embedded development
随机推荐
通过数字电视通过宽带网络取代互联网电视机顶盒应用
Chris LATTNER, the father of llvm: why should we rebuild AI infrastructure software
R语言可视化两个以上的分类(类别)变量之间的关系、使用vcd包中的Mosaic函数创建马赛克图( Mosaic plots)、分别可视化两个、三个、四个分类变量的关系的马赛克图
@PathVariable
什么是RDB和AOF
966 minimum path sum
3D人脸重建:从基础知识到识别/重建方法!
愛可可AI前沿推介(7.6)
[redis design and implementation] part I: summary of redis data structure and objects
The difference between break and continue in the for loop -- break completely end the loop & continue terminate this loop
Yyds dry goods count re comb this of arrow function
js 根据汉字首字母排序(省份排序) 或 根据英文首字母排序——za排序 & az排序
JS操作dom元素(一)——获取DOM节点的六种方式
Why do job hopping take more than promotion?
The biggest pain point of traffic management - the resource utilization rate cannot go up
Proxy and reverse proxy
【mysql】游标的基本使用
In JS, string and array are converted to each other (II) -- the method of converting array into string
The most comprehensive new database in the whole network, multidimensional table platform inventory note, flowus, airtable, seatable, Vig table Vika, flying Book Multidimensional table, heipayun, Zhix
3D face reconstruction: from basic knowledge to recognition / reconstruction methods!