当前位置:网站首页>pytorch_ Yolox pruning [with code]
pytorch_ Yolox pruning [with code]
2022-07-06 22:25:00 【Meat loving Peng】
Catalog
Fine tuning training after pruning
Conv And BN The fusion reasoning of layer accelerates
Environmental Science
pytorch 1.7
loguru 0.5.3
NVIDIA 1650 4G
intel i5-9th
torch-pruning 0.2.7
Installation package
pip install torch_pruning
Note: This project is in b standing up Lord Bubbliiiing Heyuan YOLOX The official code is integrated .
1. Added feature Visualization
2. It can be turned on during training EMA function
3. Network pruning ( Support s,m,l,x)
3.1 Support single convolution pruning
3.2 Support network layer pruning
4. Fine tuning training after pruning
5.Conv And BN The fusion reasoning of layer accelerates
6. preservation log Information
Dataset format : use voc Dataset format
feature Visualization
stay tools/Net_Vision.py Implement for visual code . You can import NV function , Realize channel visualization .
eg:
features = [out_features[f] for f in self.in_features]
[x2, x1, x0] = features # shape is (batch_size,channels,w,h)
NV(x2)
Network pruning
Reference paper :Pruning Filters for Efficient ConvNets
Import the pruning tool
import torch_pruning as tp
If you need to see yolov4 Of , You can see :YOLOv4 prune 【 The attached code 】_ Meat loving Peng's blog -CSDN Blog _yolov4 prune
Adopt channel pruning , Instead of weight pruning .
Before pruning, you need to pass tools/prunmodel.py save_whole_model(weights_path, num_classes) Function saves the weight and structure of the model .
weights_path: Weight path
num_classes: Own category quantity
model = YOLOX(num_classes, 's') # It needs to be modified according to the number of classes s finger yolox-s
Support the pruning of a convolution : call Conv_pruning(whole_model_weights):
pruning_idxs = strategy(v, amount=0.4) # 0.4 Is the pruning rate Modify as needed , The larger the number, the more you cut
For the pruning of a single convolution , Two local values need to be modified , The convolution layer here needs to be obtained by printing the model , Don't guess blindly :
if k == 'backbone.backbone.dark2.0.conv.weight'pruning_plan = DG.get_pruning_plan((model.backbone.backbone.dark2)[0].conv, tp.prune_conv, idxs=pruning_idxs)
Support network layer pruning : call layer_pruning(whole_model_weights):
included_layers = list((model.backbone.backbone.dark2.modules())) # Prune for a certain layer
Note: After successful pruning , It will print the parameter variation of the model ! If not printed , That means you cut it wrong , Check it out !
After pruning log The log file will be saved in logs Under the document
Fine tuning training after pruning
take train.py Medium pruned_train Set to True.
False For normal training , And then modify it yourself batch_size.
Pay attention to revision model_path and classes_path, Otherwise, it will report a mistake !
The size of network input before pruning must be consistent with that during fine tuning training and reasoning !
Train your own dataset
If you have Bubbliiiing up Code of master , You will soon be able to get started . The dataset uses VOC In the form of
VOCdevkit/ `-- VOC2007 |-- Annotations ( Deposit xml Label file ) |-- ImageSets | `-- Main `-- JPEGImages ( Store image )
stay model_data Create a new one in new_classes.txt, Write your own class inside . function voc_annotation.py, Will generate... In the current directory 2007_train.txt Document and 2007_val.txt file .( You can check whether it is successfully generated )
stay train.py in , take classes_path It is amended as follows model_data/new_classes.txt【 Wait for the prediction , Also needed in the yolo.py Modify here 】
Then modify other super parameters as needed to train , Training weights will be saved in logs In file ( Save weights by default , Without network structure )
forecast

Parameter description : The inputs of the following terminals are optional
--predict: Prediction model
--pruned: Turn on pruning prediction or training
--image: Image detection
--video: Start video detection
--video_path: Video path
--camid: camera id Default 0
--fps:FPS test
--dir_predict: Predict the image under a folder
--phi: You can choose s,m,l,x etc.
--input_shape: Network input size , Default 640
--confidence: Confidence threshold
--nms_iou:iou threshold
--num_classes: Number of categories , Default 80
--fuse: Whether the convolution layer and BN Layer fusion accelerates , Default False
The input terminal :
# Image prediction python demo.py --predict --image
# Video prediction python demo.py --predict --video --camdi 0
# fps test python demo.py --predict --fps
The default forecasts are yolox_s, If you want to specify another network , Input :( It is important to note that in yolo.py Modify the weight path , If it is your own data set , It needs to be revised classes_path)
# Use yolox_l forecast python demo.py --predict --image --phi l
Conv And BN The fusion reasoning of layer accelerates
Other commands can be used together , For example, using conv and bn Reasoning in the way of fusion
python demo.py --predict --image --fuse
Found by test FPS Promoted 3 frame /s about ( my GPU yes 1650)
Saving of log files
This project adopts loguru Tools capture logs , Some log records during detection and training will be automatically recorded , Save in logs Under the document , One log The maximum size of the file I set is 1 MB, If beyond this range , Will automatically generate a new .log file , You can modify this value by yourself , Or modify the log save time ( So as not to save too many logs ). If you don't want this feature , You can find the corresponding position and comment it out .
Here is just to help you build wheels , Implement some functions with as simple code as possible , You don't have to look at complex engineering code anymore , The final effect needs to be adjusted patiently , Take your time “ Alchemy ”!
The weight
link : Baidu SkyDrive Please enter the extraction code  https://pan.baidu.com/s/1Jbq8dCv893rZ7RkaANUZgQ Extraction code :yypn
https://pan.baidu.com/s/1Jbq8dCv893rZ7RkaANUZgQ Extraction code :yypn
Code ( If it helps , Excuse me star Chant ~):
 https://github.com/YINYIPENG-EN/Pruning_for_YOLOX
https://github.com/YINYIPENG-EN/Pruning_for_YOLOX边栏推荐
- Aardio - 利用customPlus库+plus构造一个多按钮组件
- Anaconda installs third-party packages
- 2500 common Chinese characters + 130 common Chinese and English characters
- Embedded common computing artifact excel, welcome to recommend skills to keep the document constantly updated and provide convenience for others
- Applet system update prompt, and force the applet to restart and use the new version
- 重磅新闻 | Softing FG-200获得中国3C防爆认证 为客户现场测试提供安全保障
- SQL Server生成自增序号
- A Mexican airliner bound for the United States was struck by lightning after taking off and then returned safely
- Inno Setup 打包及签名指南
- China 1,4-cyclohexanedimethanol (CHDM) industry research and investment decision-making report (2022 Edition)
猜你喜欢

【数字IC手撕代码】Verilog无毛刺时钟切换电路|题目|原理|设计|仿真

C#實現水晶報錶綁定數據並實現打印4-條形碼

Aardio - 利用customPlus库+plus构造一个多按钮组件
ZABBIX proxy server and ZABBIX SNMP monitoring
Netxpert xg2 helps you solve the problem of "Cabling installation and maintenance"
Memorabilia of domestic database in June 2022 - ink Sky Wheel
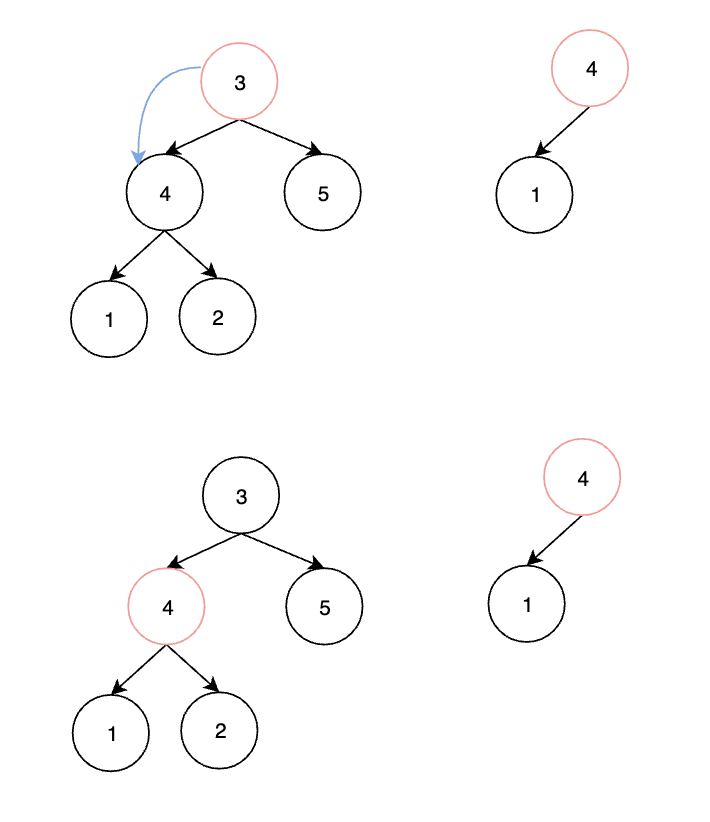
LeetCode 练习——剑指 Offer 26. 树的子结构
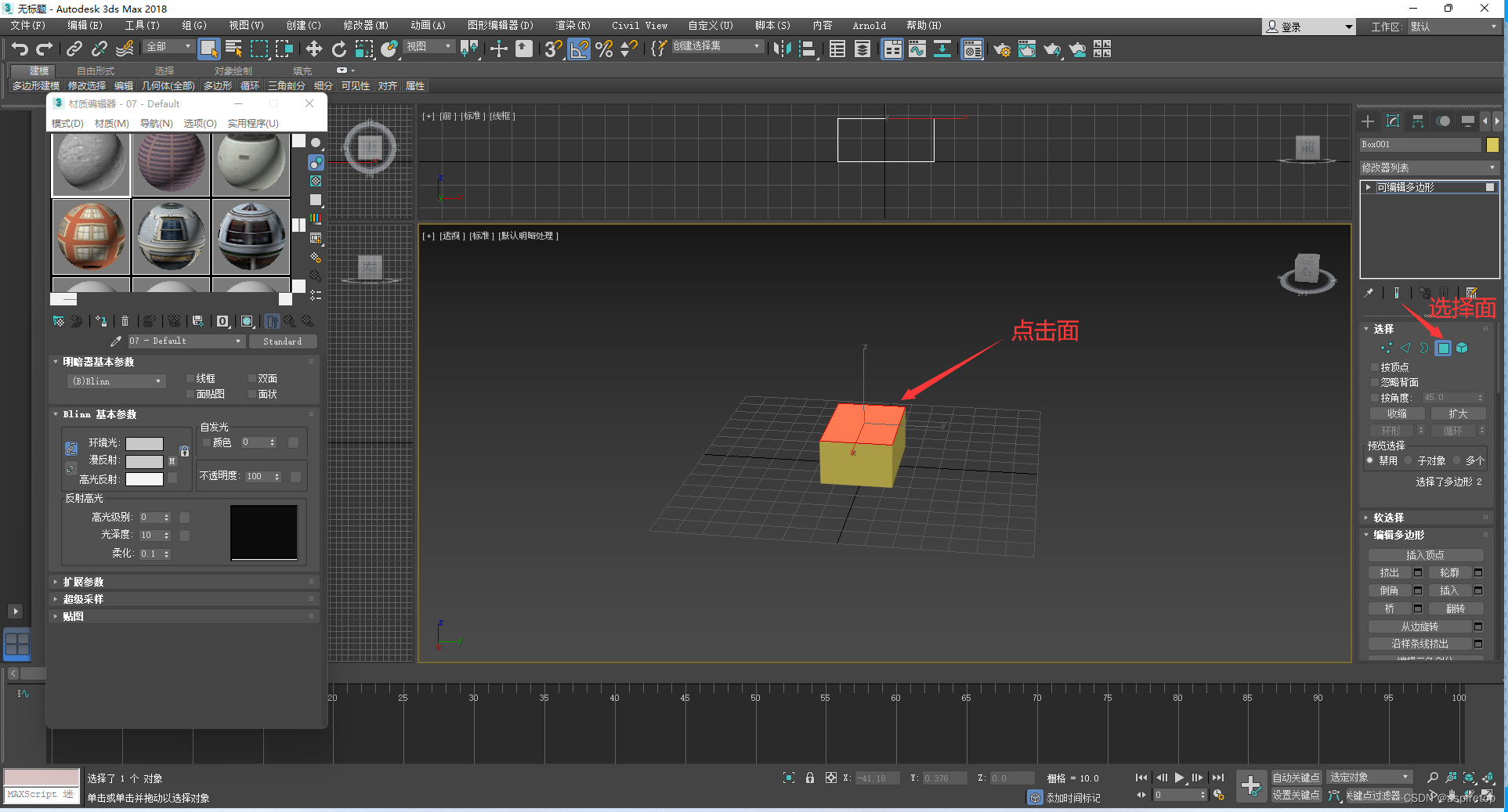
3DMAX assign face map
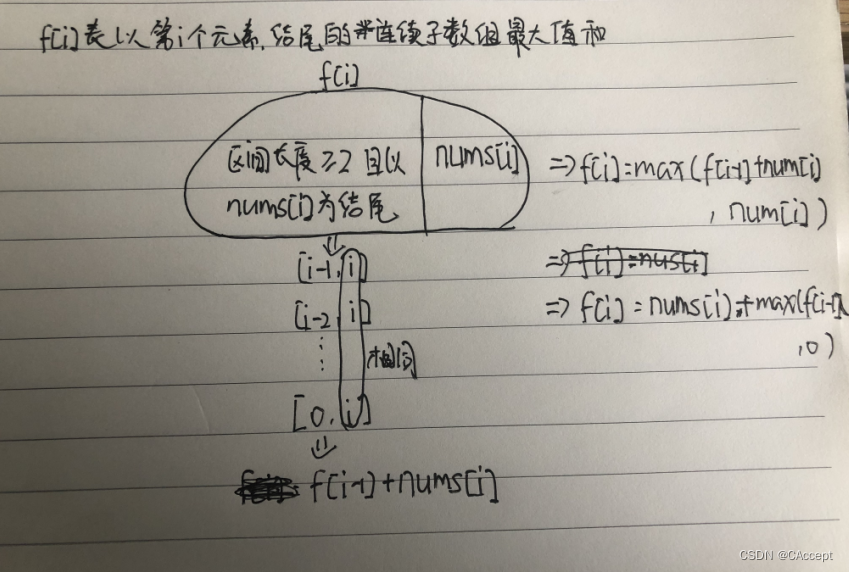
LeetCode刷题(十一)——顺序刷题51至55
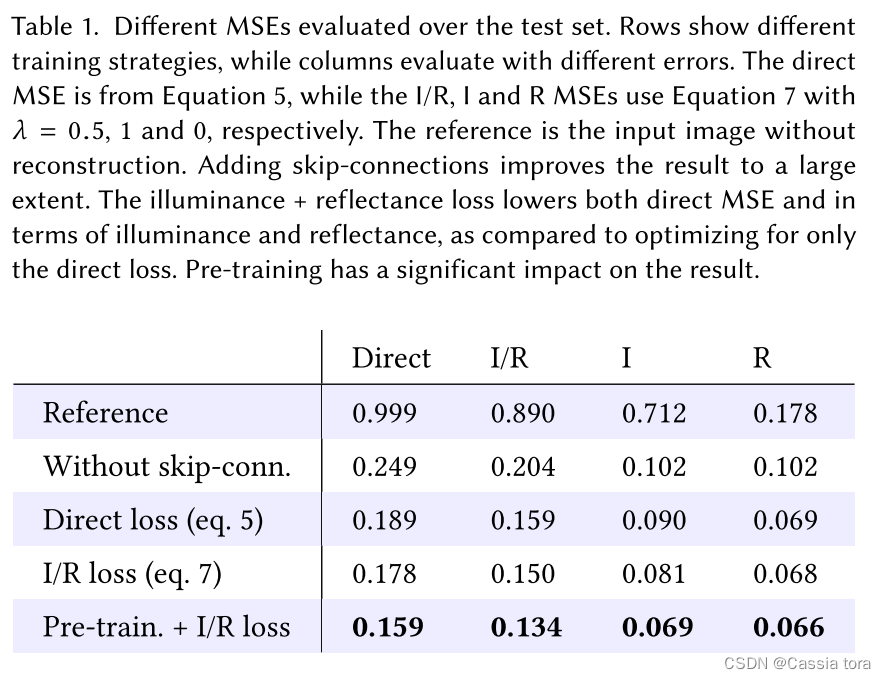
HDR image reconstruction from a single exposure using deep CNN reading notes
随机推荐
[sdx62] wcn685x will bdwlan Bin and bdwlan Txt mutual conversion operation method
Seata aggregates at, TCC, Saga and XA transaction modes to create a one-stop distributed transaction solution
每日一题:力扣:225:用队列实现栈
如何用程序确认当前系统的存储模式?
插入排序与希尔排序
HDR image reconstruction from a single exposure using deep CNNs阅读札记
case 关键字后面的值有什么要求吗?
GPS from getting started to giving up (12), Doppler constant speed
i.mx6ull搭建boa服务器详解及其中遇到的一些问题
Chapter 3: detailed explanation of class loading process (class life cycle)
3DMAX assign face map
C # realizes crystal report binding data and printing 4-bar code
GD32F4XX串口接收中断和闲时中断配置
Seata聚合 AT、TCC、SAGA 、 XA事务模式打造一站式的分布式事务解决方案
C#实现水晶报表绑定数据并实现打印4-条形码
网络基础入门理解
解决项目跨域问题
HDU 2008 digital statistics
Attack and defense world miscall
CCNA-思科网络 EIGRP协议