当前位置:网站首页>Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR2022 oral)
Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR2022 oral)
2022-07-06 14:53:00 【Rainylt】
paper: https://arxiv.org/pdf/2203.15332.pdf
一句话总结:解决多模态训练时主导模态训得太快导致辅助模态没训充分的问题
交叉熵损失函数: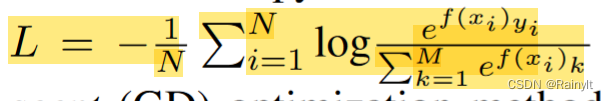
其中,f(x)为
解耦一下: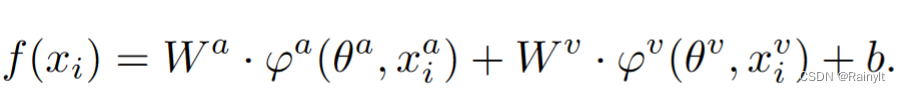
其中,a表示audio模态,v表示visual模态,f(x)为softmax前的两个模态联合输出的logits。在这个任务中a为主导模态,即对于gt类别,a模态输出的logits更大
以 W a W^a Wa为例,L对 W a W^a Wa求导: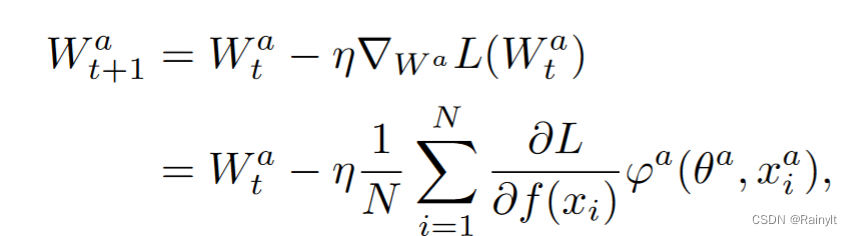
可以看到,根据链式求导法则, φ a \varphi^a φa是与a模态相关的输出, ∂ L ∂ f ( x i ) \frac{\partial{L}}{\partial{f(x_i)}} ∂f(xi)∂L的值对于两个模态都相同,因此影响对不同模态的梯度差异的就是后面这部分,也就是 φ \varphi φ的值。由于一般主导模态输出的logits较高,即 φ \varphi φ和 W W W的值较大,因此反传时的梯度也更大,收敛也更快。
因此可能会出现主导模态先训好了,loss降得比较低了,辅助模态还没训好的问题。具体为啥辅助模态不能接着训好,有待探究。
对于本文,为了减速主导模态训练,因此在求梯度时加个衰减系数,减少主导模态反传的梯度,相当于单独减小主导模态的学习率:
用两个模态各自输出logits的softmax后的score比值来确定
将比值大于1的(主导模态)设置衰减系数k(0~1),辅助模态为1(不变)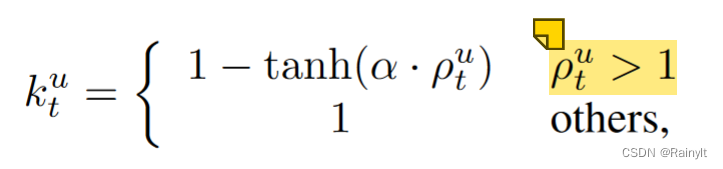
与学习率相乘,相当于减小学习率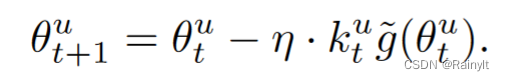
此外,根据SGD的梯度反传过程,梯度可以推到为原梯度+高斯噪声: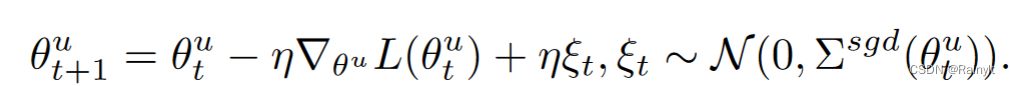
学习率越大=>高斯噪声协方差越大=>泛化能力越强。这里减小学习率相当于削弱了主导模态的泛化能力。加了衰减系数后的梯度,方差缩小为原来的k^2倍: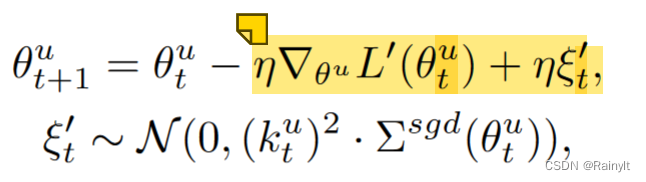
因此,本文人为增加一个高斯噪声,方差=batch内样本的方差: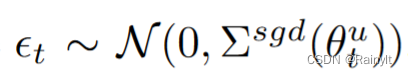
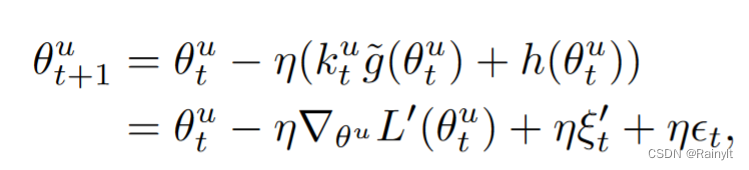
相当于噪声的协方差相比以前还变大了: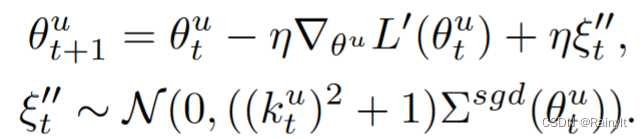
边栏推荐
- The nearest common ancestor of binary (search) tree ●●
- Daily question 1: force deduction: 225: realize stack with queue
- CCNA-思科网络 EIGRP协议
- config:invalid signature 解决办法和问题排查详解
- RESNET rs: Google takes the lead in tuning RESNET, and its performance comprehensively surpasses efficientnet series | 2021 arXiv
- NetXpert XG2帮您解决“布线安装与维护”难题
- C# 三种方式实现Socket数据接收
- Assembly and Interface Technology Experiment 6 - ADDA conversion experiment, AD acquisition system in interrupt mode
- 二分图判定
- 枚举与#define 宏的区别
猜你喜欢

C # realizes crystal report binding data and printing 4-bar code
Management background --5, sub classification
Hardware development notes (10): basic process of hardware development, making a USB to RS232 module (9): create ch340g/max232 package library sop-16 and associate principle primitive devices
2022年6月国产数据库大事记-墨天轮

Aardio - 利用customPlus库+plus构造一个多按钮组件
![[线性代数] 1.3 n阶行列式](/img/6e/54f3a994fc4c2c10c1036bee6715e8.gif)
[线性代数] 1.3 n阶行列式

NPDP认证|产品经理如何跨职能/跨团队沟通?

重磅新闻 | Softing FG-200获得中国3C防爆认证 为客户现场测试提供安全保障

CocosCreator+TypeScripts自己写一个对象池
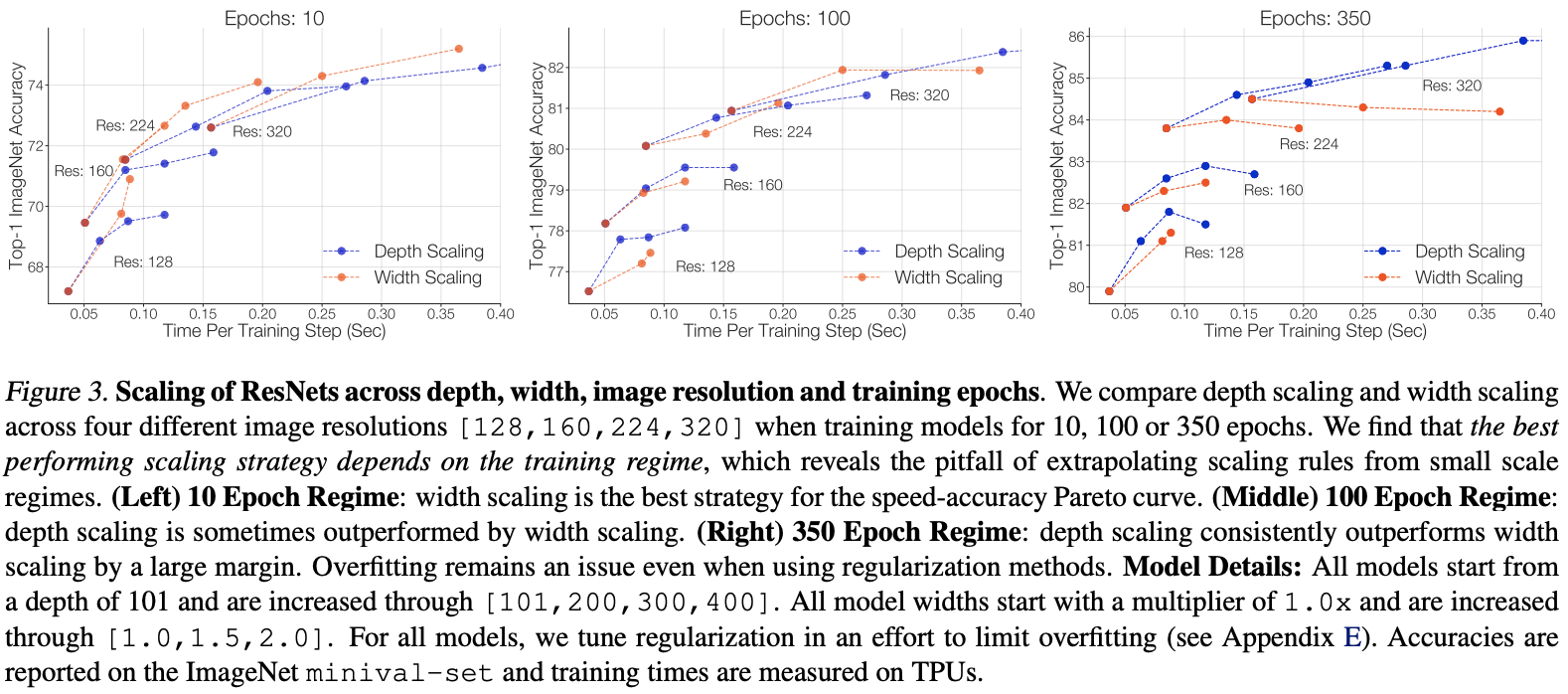
ResNet-RS:谷歌领衔调优ResNet,性能全面超越EfficientNet系列 | 2021 arxiv
随机推荐
HDR image reconstruction from a single exposure using deep CNNs阅读札记
Attack and defense world ditf Misc
解决项目跨域问题
中国固态氧化物燃料电池技术进展与发展前景报告(2022版)
Clip +json parsing converts the sound in the video into text
Notes de développement du matériel (10): flux de base du développement du matériel, fabrication d'un module USB à RS232 (9): création de la Bibliothèque d'emballage ch340g / max232 SOP - 16 et Associa
二分图判定
i.mx6ull搭建boa服务器详解及其中遇到的一些问题
墨西哥一架飞往美国的客机起飞后遭雷击 随后安全返航
2022-07-04 mysql的高性能数据库引擎stonedb在centos7.9编译及运行
Web APIs DOM 时间对象
Management background --1 Create classification
柔性数组到底如何使用呢?
剪映+json解析将视频中的声音转换成文本
硬件开发笔记(十): 硬件开发基本流程,制作一个USB转RS232的模块(九):创建CH340G/MAX232封装库sop-16并关联原理图元器件
手写ABA遇到的坑
How do I write Flask's excellent debug log message to a file in production?
case 关键字后面的值有什么要求吗?
剑指offer刷题记录1
如何用程序确认当前系统的存储模式?