The paper reexamines ResNet Structure 、 Training methods and scaling strategies , Put forward a comprehensive performance beyond EfficientNet Of ResNet-RS series . From the experimental results, the performance improvement is very high , Worthy of reference
source : Xiaofei's algorithm Engineering Notes official account
The paper : Revisiting ResNets: Improved Training and Scaling Strategies

- Address of thesis :https://arxiv.org/abs/2103.07579
- Paper code :https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
Introduction
The accuracy of the visual model is determined by the structure 、 The training method and scaling strategy jointly decide , The experiments of new models usually use new training methods and super parameters , It cannot be directly compared with the old model results obtained by outdated training methods . So , The paper is intended to be in ResNet Verify the influence of different training methods and scaling strategies .
The main contributions of this paper are as follows :
- Without changing the model structure , The role of regularization method and its combination is verified by experiments , Get a regularization strategy that can improve performance .
- Put forward simple 、 Efficient scaling strategy :1) If the experimental configuration may have been fitted ( For example, the training cycle is long ), Zoom depth first , Otherwise, scale the width .2) Scale the input resolution more slowly .
- The above experimental results of regularization strategy and scaling strategy are applied to ResNet Put forward ResNet-RS, Performance surpasses EfficientNet.
- Use extra 130M False label picture pair ResNet-RS Conduct semi supervised pre training ,ImageNet The performance on the is up to 86.2%,TPU The training speed on is fast 4.7 times .
- Will be obtained through self-monitoring ResNet-RS Model , On different visual tasks fine-tuned, Performance is equal or better SimCLR and SimCLRv2.
- take 3D ResNet-RS Applied to video classification , Performance ratio baseline high 4.8%.
Characterizing Improvements on ImageNet
The improvement of the model can be roughly divided into four directions : Structural improvement 、 Training / The regular way 、 Scaling strategies and using additional training data .
Architecture
The study of new structures is the most concerned , The emergence of neural network search makes the structure research a step further . There are also some structures that break away from classical convolution Networks , Like joining self-attention Or other alternatives , Such as lambda layer .
Training and Regularization Methods
When the model needs to be trained for a longer time , The regular way ( Such as dropout、label smoothing、stochastic depth、dropblock) And data enhancement can effectively improve the generalization ability of the model , And a better learning rate adjustment method can also improve the final accuracy of the model . In order to make a fair comparison with the previous work , Some studies simply use non regular training settings , This obviously does not reflect the ultimate performance of the research .
Scaling Strategies
Improve the dimension of the model ( Width 、 Depth and resolution ) It is also an effective method to improve accuracy . Especially in natural language models , The scale of the model has a direct impact on the accuracy , It is also effective in visual models . With the increase of computing resources , The dimension of the model can be appropriately increased . In order to systematize this adaptation ,EfficentNet A hybrid scaling factor method is proposed , Used to balance network depth when scaling 、 The relationship between width and resolution , But the paper found that this method is not optimal .
Additional Training Data
Another effective way to improve performance is to use additional data sets for pre training . Pre trained models in large data sets , In the ImageNet Achieve good performance on . It should be noted that , It is not necessary to label the data set , Semi supervised training using pseudo tags , It can also achieve good performance .
Methodology

Architecture
On the structure ,ResNet-RS Only ResNet-D Add SENet Improvement , These improvements are often used in current models .
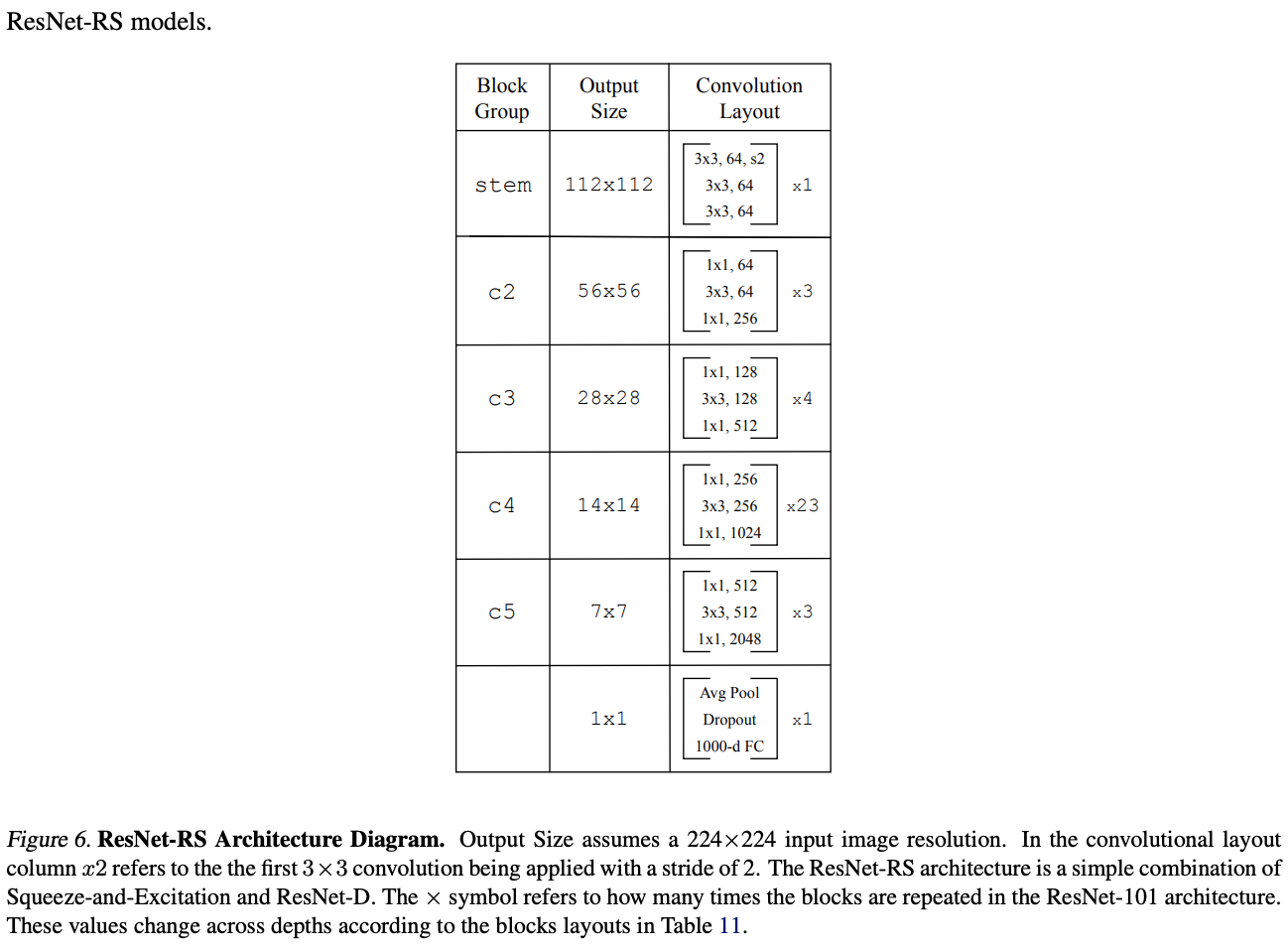
ResNet-D
For native ResNet Four improvements have been made :1) take stem Of \(7\times 7\) Convolution replaced by 3 individual \(3\times 3\) Convolution .2) Exchange the lower sampling module residual The first two of the path are convoluted stride To configure .3) Lower the... Of the sampling module skip In the path stride-2 \(1\times 1\) Convolution replaced by stride-2 \(2\times 2\) Average pooling and non-strided \(1\times 1\) Convolution .4) Get rid of stem Medium stride-2 \(3\times 3\) Maximum pool layer , Next bottleneck The first of \(3\times 3\) Down sampling in convolution .
Squeeze-and-Excitation
SE The weight of each channel obtained by the module through cross channel calculation , Then weight the channel . Set up ratio=0.25, At every bottleneck All of them join in .
Training Method
Study the current SOTA Regularization and data enhancement methods used in classification models , And semi supervised / Self supervised learning .
Matching the EfficientNet Setup
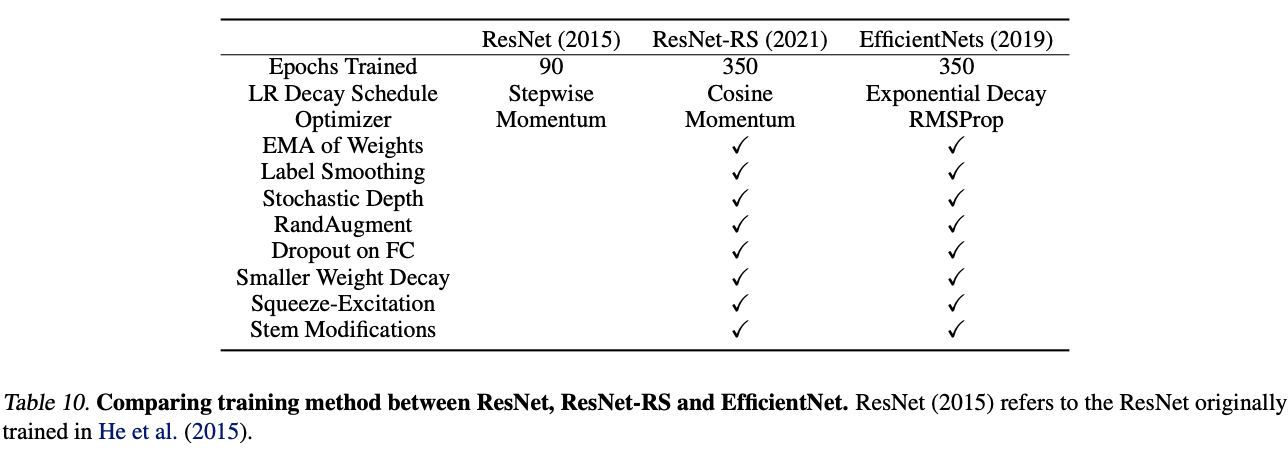
Training methods and EfficientNet similar , Co training 350 round , There are the following subtle differences :1) Use cosine Learning rate adjustment method .2) Use RandAugment Enhance data .EfficientNet First use AutoAugment Enhance data , Use RandAugment The results changed little .3) For simplicity , Use Momentum Optimizer instead of RMSProp Optimizer .
Regularization
Use weight decay,label smoothing,dropout and stochastic depth Regularize .
Data Augmentation
Use RandAugment Data enhancement as an additional regularizer , Use a series of random enhancement methods for each image .
Hyperparameter Tuning
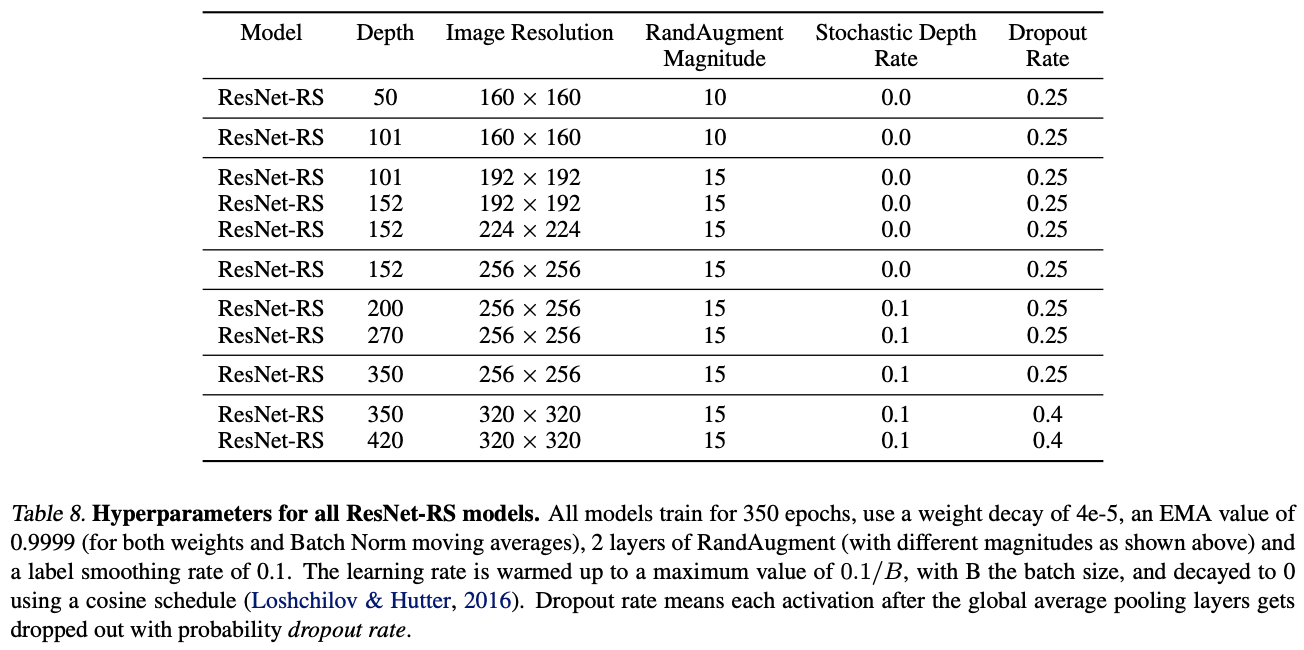
In order to quickly select hyperparameters suitable for different regularization methods and training methods , Use contains ImageNet Of 2%(1024 Slice extraction 20 Fragmentation ) Data structure minival-set, Original ImageNet Validation set as validation-set.
Improved Training Methods
Additive Study of Improvements
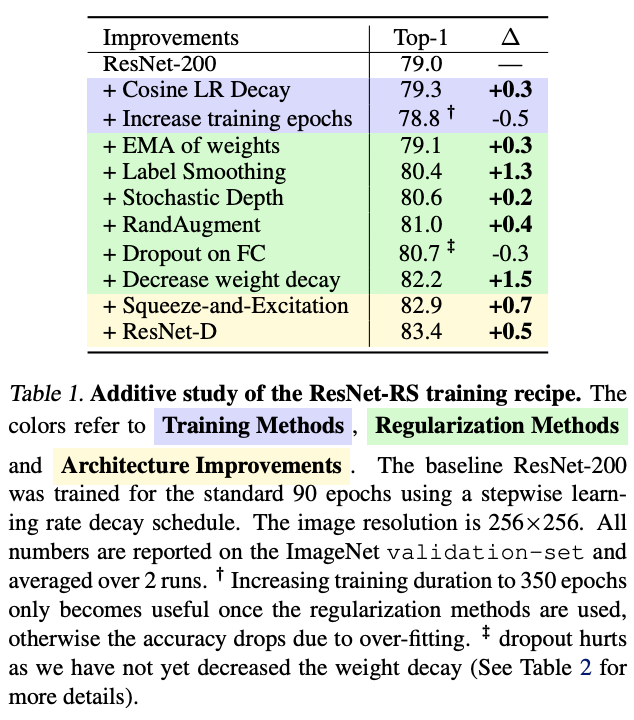
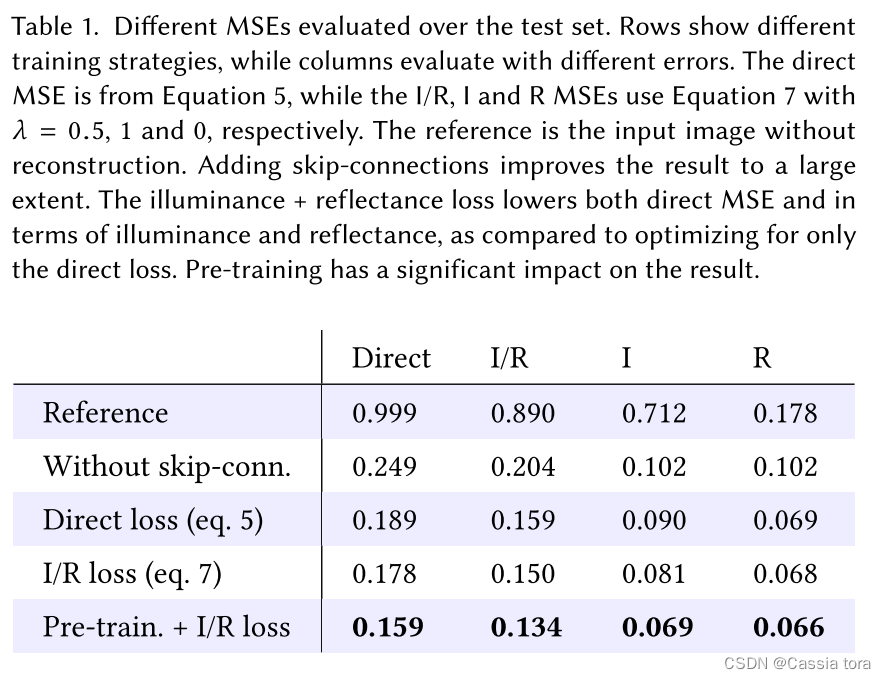
The paper discusses the training methods 、 Regularization method 、 Superposition experiments were carried out for structural optimization , Results such as table 2 Shown , The improvement brought by training methods and regularization methods accounts for about 3/4 The total accuracy of .
Importance of decreasing weight decay when combining regularization methods
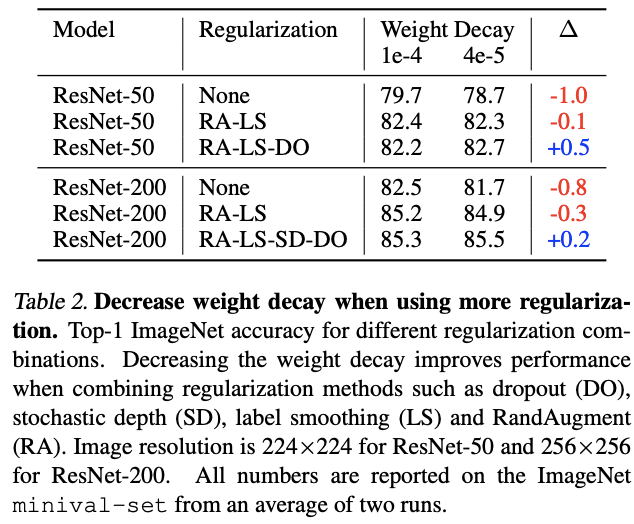
The paper is using RandAugment and label smoothing when , There is no change to the default weight decay Set up , Improved performance . But in addition to dropout or stochastic depth after , Performance has declined , Finally, by reducing weight decay To restore .weight decay For regularization parameters , When combined with other regularization processing , You need to reduce its value to avoid over regularization .
Improved Scaling Strategies
To explore the logic of model scaling , Preset width scale [0.25, 0.5, 1.0, 1.5, 2.0]、 Depth scale [26, 50, 101, 200, 300, 350, 400] And resolution [128, 160, 224, 320, 448], Combine different proportions to test the performance of the model . Each combination training 350 cycle , Training configuration and SOTA The models are the same , As the model size increases , Strengthen regularization accordingly .
The main findings are as follows :
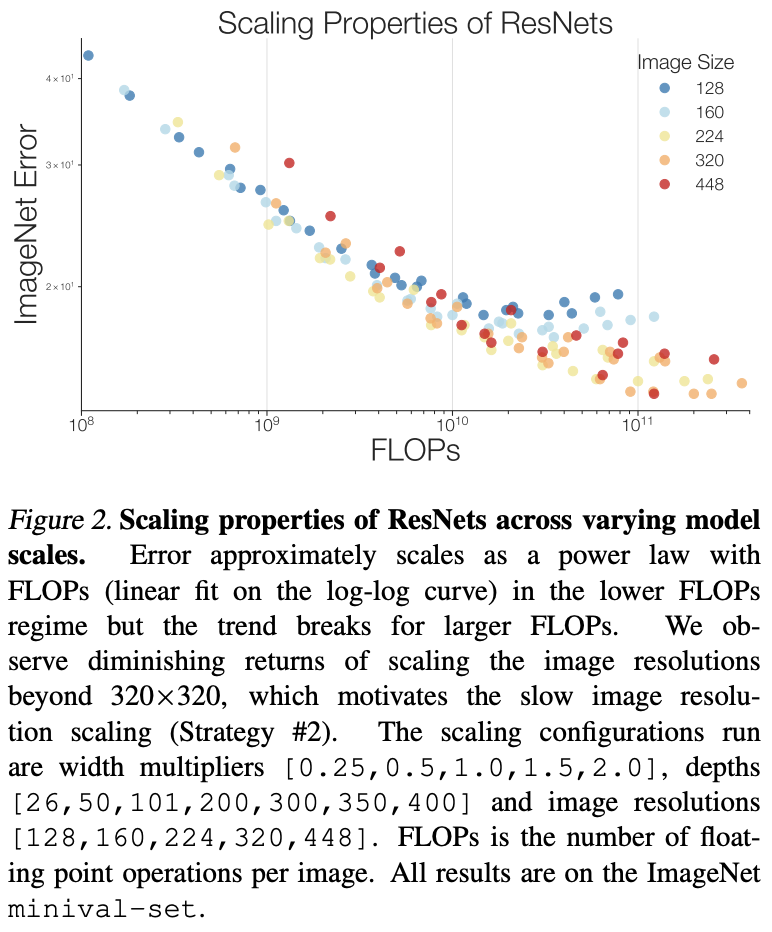
- FLOPs do not accurately predict performance in the bounded data regime. When the model is small , Model performance is positively related to model size , But when the model gets bigger , This relationship becomes less obvious , In turn, it is related to the scaling strategy . Scale the model to the same size using different scaling strategies , The bigger the model , The greater the difference in performance .
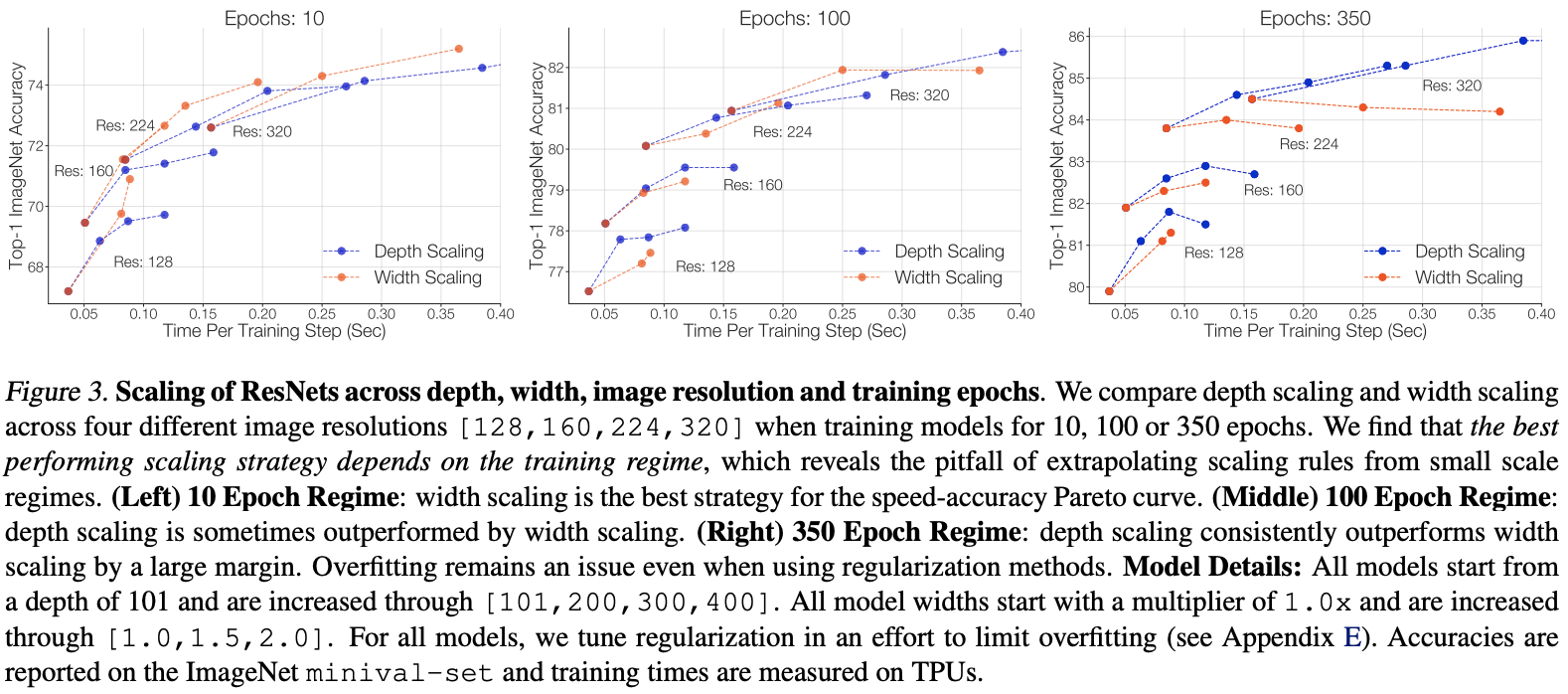
- The best performing scaling strategy depends on the training regime. Under different training cycles , The performance curves of different scaled versions vary greatly , Therefore, the best performance of the scaling strategy has a lot to do with the experimental settings .
Strategy #1 - Depth Scaling in Regimes Where Overfitting Can Occur
Depth scaling outperforms width scaling for longer epoch regimes. From the picture 3 You can see on the right , stay 350 Under the training configuration of the cycle , Depth scaling is more effective than width scaling at any input resolution . Width scaling is sub optimal for over fitting , Sometimes it even leads to performance loss , This may be due to the introduction of too many parameters in width scaling , Depth scaling introduces only a few parameters .
Width scaling outperforms depth scaling for shorter epoch regimes, From the picture 3 On the left you can see , stay 10 Under the training configuration of the cycle , Better width scaling . And from the graph 3 It can be seen that , stay 100 Under the training configuration of the cycle , With different input resolutions , The performance of depth scaling and width scaling varies .
Strategy #2 - Slow Image Resolution Scaling
From the picture 2 It can be seen that , The higher the input resolution , The less benefit it can bring , That is, the lower the cost performance . therefore , In the input resolution scaling , Papers take the lowest priority , So as to better compromise speed and accuracy .
Two Common Pitfalls in Designing Scaling Strategies
When analyzing the scaling strategy , The paper found two common wrong practices :
- Extrapolating scaling strategies from small-scale regimes, Study in a small experimental setup . Previous search strategies usually used small models or short training cycles for research , This scenario optimal scaling strategy may not be able to migrate to large models and long-term training . therefore , The paper does not recommend that you spend a lot of effort on scaling strategy experiments in this scenario .
- Extrapolating scaling strategies from a single and potentially sub-optimal initial architecture, Scaling from the suboptimal initial structure will affect the scaling result . such as EfficientNet The hybrid zoom fixes the amount of computation and resolution to search , However, the resolution is also a factor affecting the accuracy . therefore , The comprehensive width of the paper 、 Depth and resolution for scaling strategy research .
Summary of Improved Scaling Strategies
For new tasks , The paper suggests using a smaller training subset first , Complete cycle training test for configurations of different sizes , Find the scaling dimension that has a great impact on accuracy . For image classification , The scaling strategy mainly has the following two points :
- If the experimental configuration may have been fitted ( For example, the training cycle is long ), Zoom depth first , Otherwise, scale the width .
- Slowly scale the input resolution .
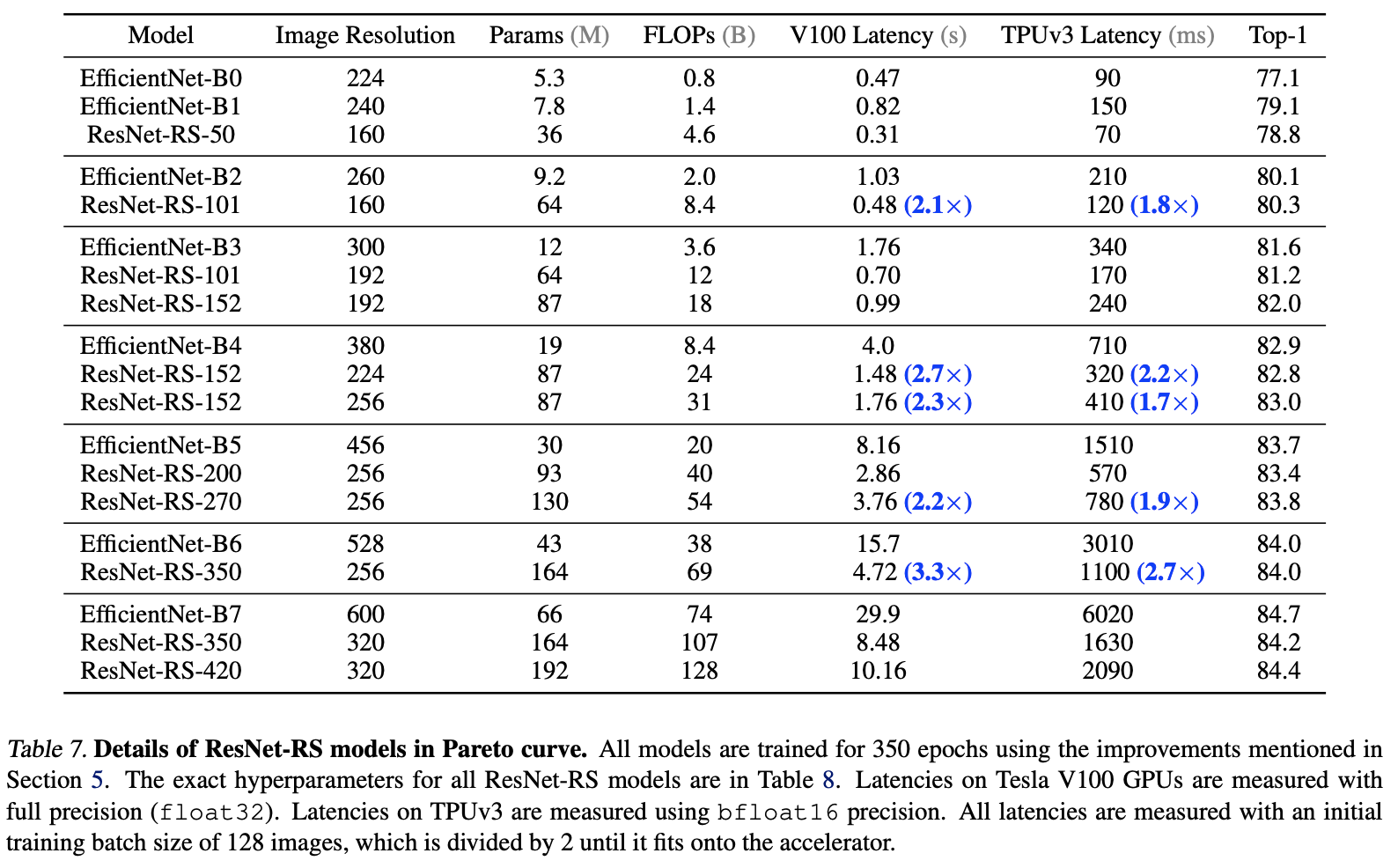
The paper finally got ResNet-RS The configuration of the series is shown in the table 7 Shown , Match in accuracy EfficientNet Under the premise of ,TPU The calculation speed on is fast 1.7~2.7 times . It should be noted that , although ResNet-RS The amount of calculation and the amount of parameters are generally higher than EfficientNet high , but ResNet-RS The actual computing speed and memory usage are better , It shows that the calculation amount and parameter amount cannot directly represent the speed and memory occupation .
Experiment
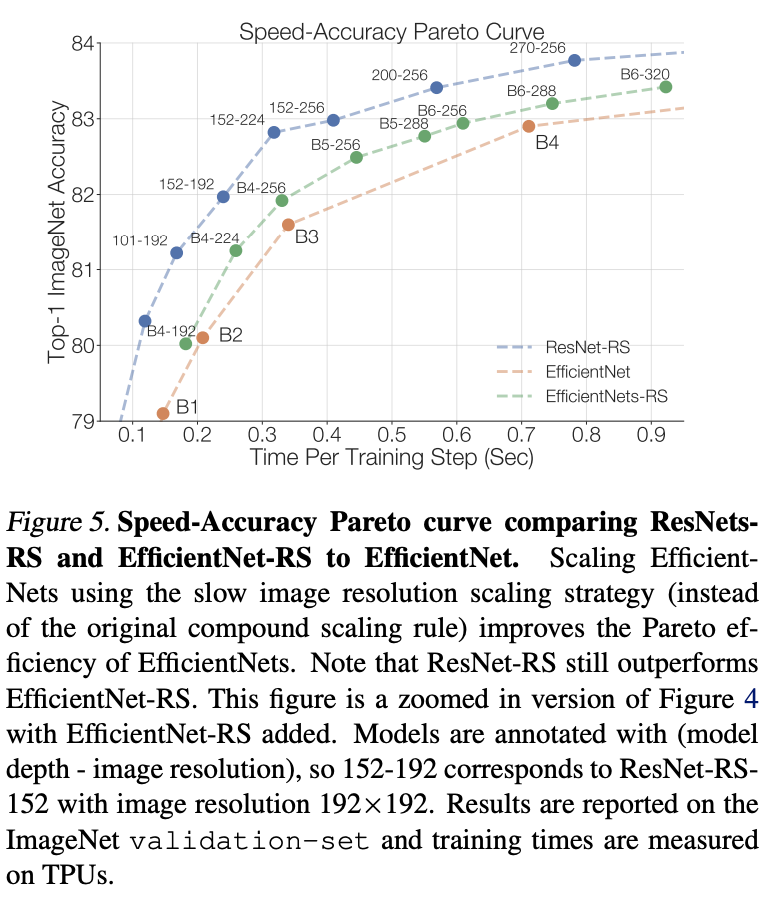
Yes EfficentNet Compare after optimization .
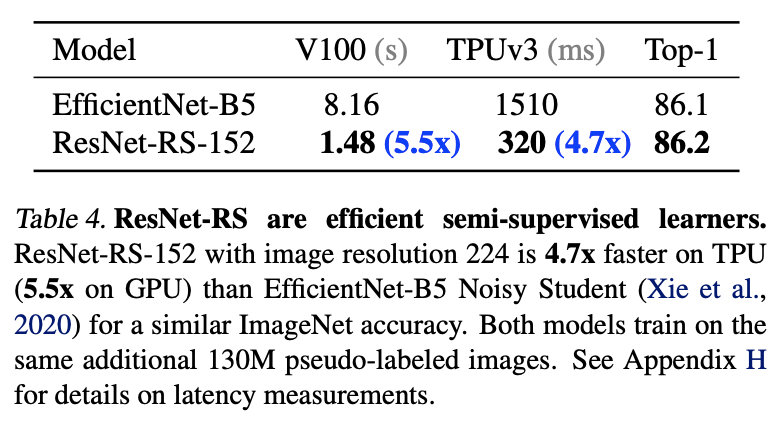
Semi supervised effect comparison .
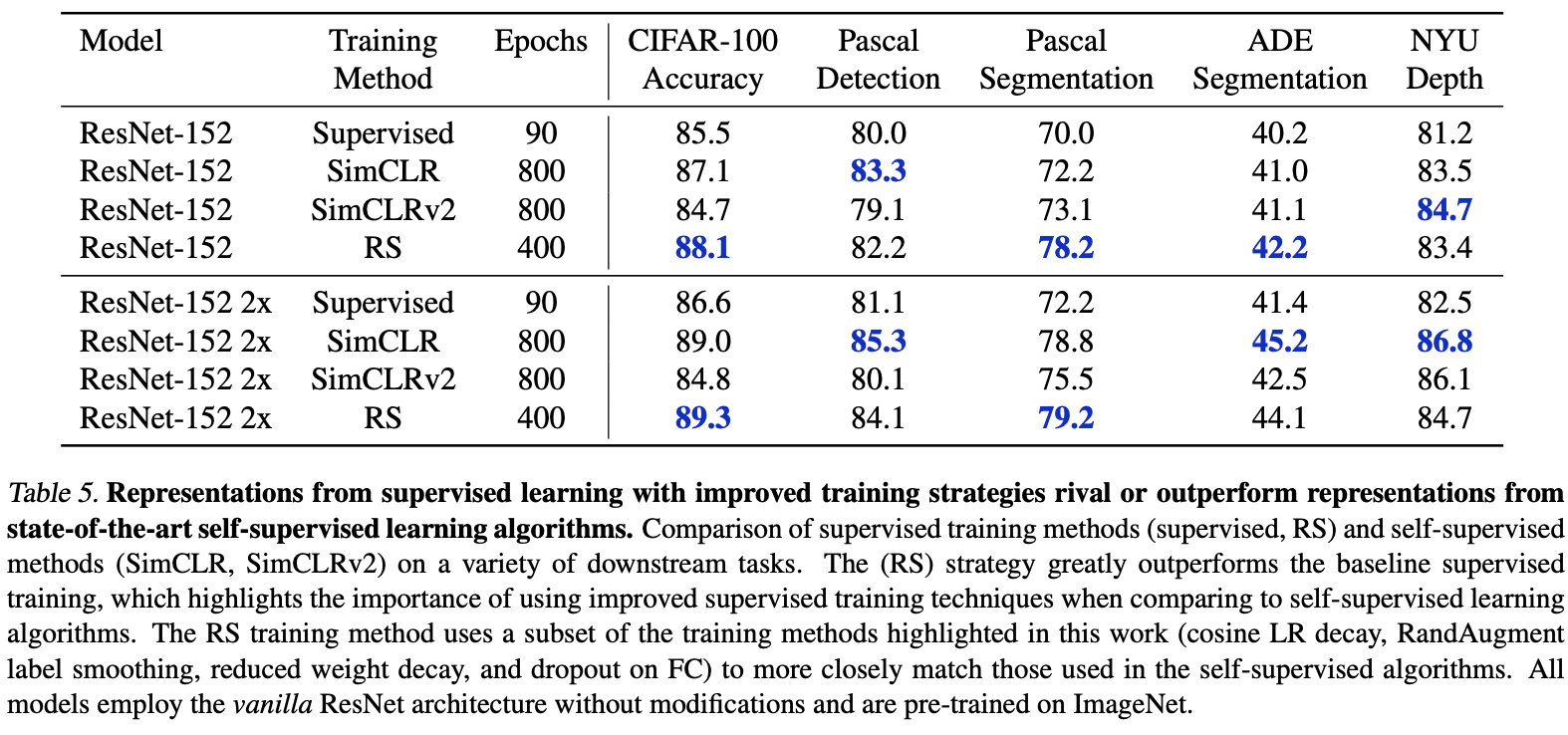
Comparison of the effect of self supervision on different tasks .
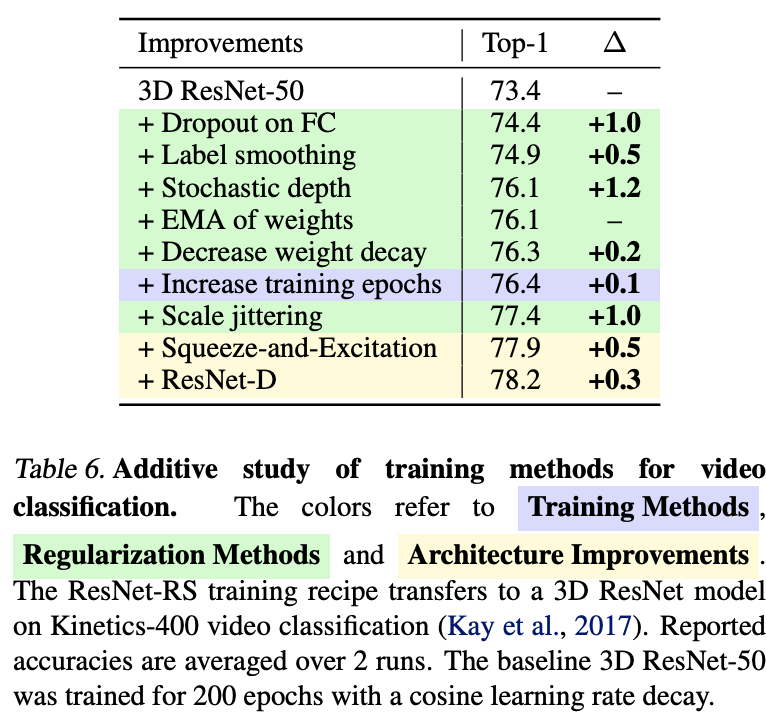
Comparative experiment of video classification .
Conclusion
The paper reexamines ResNet Structure 、 Training methods and scaling strategies , Put forward a comprehensive performance beyond EfficientNet Of ResNet-RS series . From the experimental results, the performance improvement is very high , Worthy of reference .
If this article helps you , Please give me a compliment or watch it ~
More on this WeChat official account 【 Xiaofei's algorithm Engineering Notes 】


![[Chongqing Guangdong education] Information Literacy of Sichuan Normal University: a new engine for efficiency improvement and lifelong learning reference materials](/img/a5/94bdea3a871db5305ef54e3b304beb.jpg)