Hello everyone , I'm a dialogue .
Friends who understand graph neural network are interested in deep GNN The problem of over smoothing in must be familiar , As the number of network layers increases , Instead, the effect of the model drops sharply , It hurts . recall , Common solutions to smoothing include DropEdge、 There are also methods based on residuals Normalization etc. , But the effect is not satisfactory .
In today's KDD2022 See an interesting article , It doesn't stop at GNN Over smoothing in , But from another new perspective to think about the sudden decline of deep network effect —— Related problems of feature dimension . The so-called feature dimension overcorrelation , seeing the name of a thing one thinks of its function , It refers to the high correlation between the feature dimensions we have learned , It means high redundancy and less information encoded by the learned dimension , Thus damaging the effect of downstream tasks . In this paper, , The author not only proves the importance of the problems related to the feature dimension from theory and practice , Also propose a plan DeCorr, Based on Show feature dimensions And Maximum mutual information There are two ways to implement decorrelation tasks .
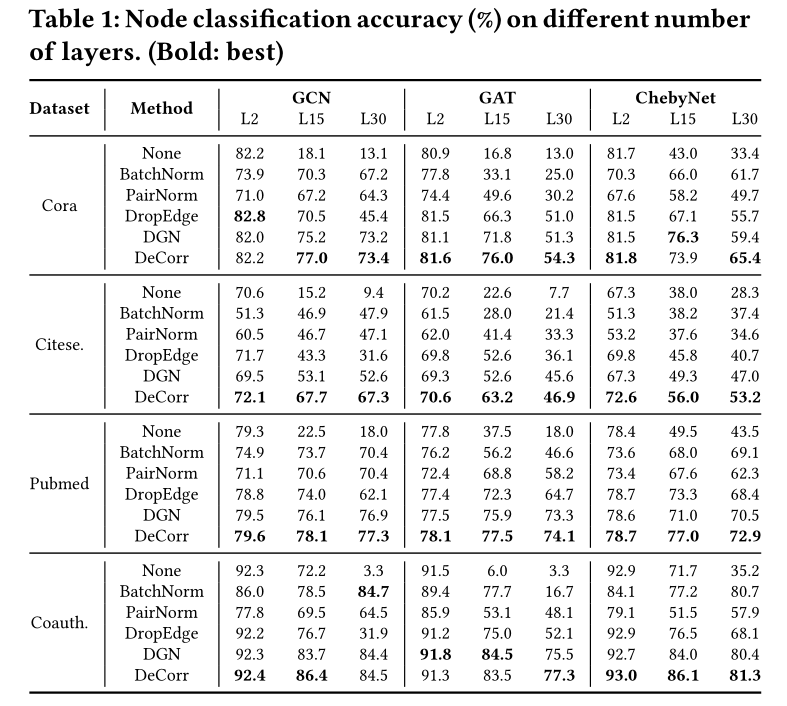
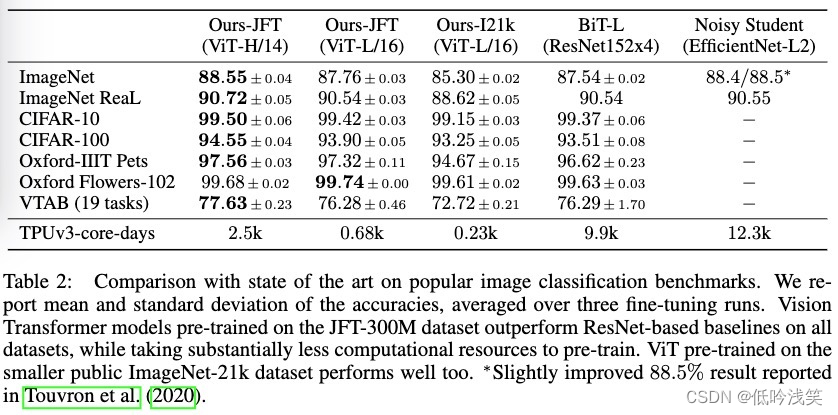
As can be seen from the table , The proposed scheme is for the same number of model layers , In most cases, the best performance can be achieved , And significantly slow down the performance degradation . for example , stay Cora Data set ,DeCorr Separately 15 layer GCN and 30 layer GCN Improved 58.9% and 60.3%.
Now let's take you to appreciate the wonders of this algorithm ~
Paper title :Feature Overcorrelation in Deep Graph Neural Networks: A New Perspective
Thesis link :https://doi.org/10.1145/3534678.3539445
Code link :https://github.com/ChandlerBang/DeCorr
One 、DeCorr The core idea

This paper is written by IBM And Michigan State University KDD2022****. In detail DeCorr Before , We need to explore the relationship between over smoothing and over Correlation , In order to better design the model .
In order to evaluate the specific degree of overcorrelation and smoothness , We use Corr and SMV As an evaluation indicator , The specific formula is :
We need to be clear : Overcorrelation and oversmooth are neither the same nor independent . Over smoothing refers to the similarity between node representations , Measured by node smoothness , Excessive correlation is measured by dimensional Correlation , The two are essentially different .Figure 6 It can be seen that , stay Pubmed and CoauthorCS On , With Corr An increase in value ,SMV It hasn't changed much .
On the other hand , They are highly correlated .
Both over correlation and over smoothing make the amount of representation coding information learned less , Damage downstream mission performance ;
Both cases are caused by GNN Multiple propagation in the model causes , In extreme cases, there will also be related problems if it is too smooth .
The article puts forward DeCorr The purpose is to solve the deep GNN Related problems in , Let's look at the details of the proposed method .
Two 、 Algorithm details
Method 1: Explicit feature dimension decorrelation : Minimize the correlation between dimensions . For the sake of simplicity , This paper uses covariance to replace Pearson correlation coefficient . Given a set of characteristic dimensions , Our goal is to minimize the loss function :
Minimizing the first item will reduce the covariance between different feature dimensions , When the first value is 0 when , There will be no correlation between dimensions . By minimizing the second , Set the norm of each dimension ( After subtracting the average ) push to 1, Then we rewrite the above formula as :
Note here , Because the time complexity of the gradient is , In real application scenarios , There are many nodes in the graph , It is not extensible . So , We use Monte Carlo sampling nodes to estimate the equal probability nodes of covariance . such , The time complexity of gradient calculation is reduced to , Increases linearly with the size of the graph .
Combined with decorrelation losses , The final loss function is :
By minimizing the loss function , We can explicitly force the representation after each layer to reduce Correlation , So as to alleviate the related problems .
Method 2: Maximizing mutual information : Maximize mutual information between input and presentation , So that the features are more independent . The motivation for adopting mutual information comes from ICA, Its principle is to learn expressions with low dimensional relevance , At the same time, maximize the relationship between input and representation MI. Due to deep GNN There is less encoded information in the representation ,MMI It can ensure that even if the model is stacked with many layers , The representation of learning can also retain some information from input .
MI The formula of the maximization process is :
Because in the context of Neural Networks , Estimate variables and MI Very difficult , Here is a very nice Methods —— Effectively estimate the mutual information of high-dimensional continuous data through samples (MINE). The specific local law is , We estimate the lower bound of mutual information by training the classifier to distinguish the sample pairs from the joint distribution and . therefore , Our training goal is :
The classifier is modeled as :
in application , We start from each batch From the joint distribution sampling to estimate the first term of the objective function , And then in batch In order to generate “ Negative pair ” To estimate the second .
To reduce losses , Apply only at each level to speed up the training process :
The final complete model loss function is :
And ordinary GNN The model compares , The additional complexity of the proposed model is negligible ; The additional time complexity is . The specific derivation process is detailed in the paper .
3、 ... and 、 experimental result
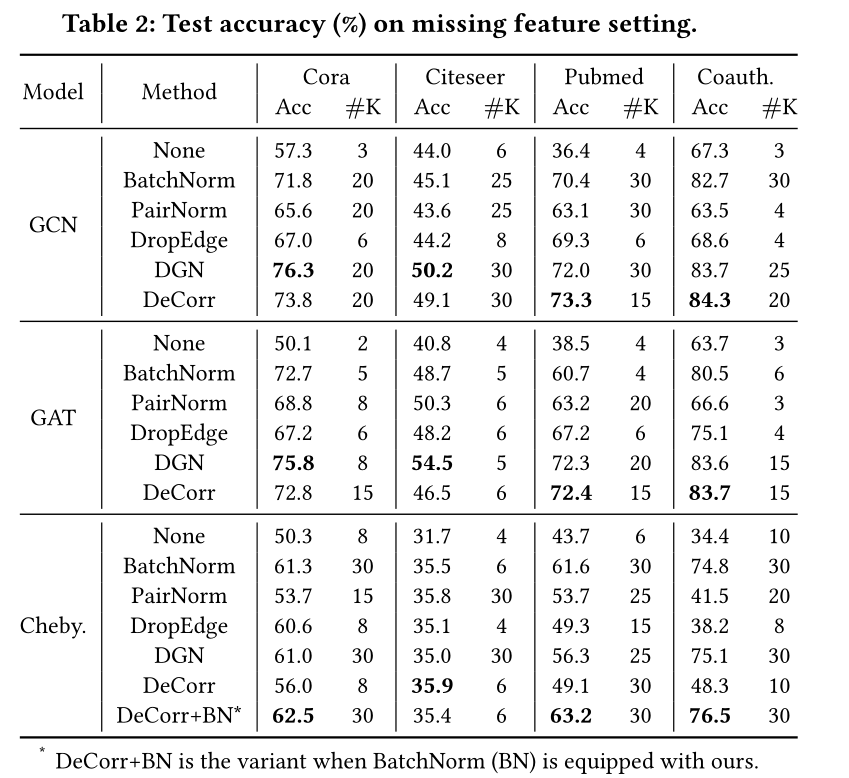
As shown in the figure , In the case of deleting the node characteristics in the test set and the verification set ( In this case, it is generally deep GNN The effect of is better than that of shallow layer ),Table 2 List 12 In this case ,DeCorr stay 8 In these cases, the best performance is achieved , Significantly better than shallow GNN. for example , stay Pubmed On dataset ,DeCorr stay GCN、GAT and ChebyNet We have achieved 36.9%、33.9% and 19.5% Improvement .
To explore DeCorr Reasons for performance improvement , The paper draws the Corr、SMV And the accuracy variation diagram , Proved the deep GNN The importance of planting relevant problems .
Combined with other deep learning methods, the experimental results are as follows :
Four 、 summary
The paper aims at the deep GNN The network is a problem of declining effect , A new problem besides over smoothing is considered —— Have been relevant . The paper has analyzed the importance of related issues , Explored the reasons behind , And designed a general framework DeCorr To improve the relevant phenomenon . It can be seen that ,DeCorr In the depth of improvement GNN Good performance , Besides , It also has potential in other application scenarios .
About me
I'm a dialogue , Tsinghua computer master ,BAT Algorithm engineer . Welcome to my WeChat official account. : Dialogue algorithm house , Daily sharing of programming experience and technical dry goods , Help you avoid detours ! You can also add my wechat , Lead resources and enter the communication group .


![[Chongqing Guangdong education] Information Literacy of Sichuan Normal University: a new engine for efficiency improvement and lifelong learning reference materials](/img/a5/94bdea3a871db5305ef54e3b304beb.jpg)