当前位置:网站首页>Checkpoint of RDD in spark
Checkpoint of RDD in spark
2022-07-06 21:44:00 【Big data Xiaochen】

RDD Of checkpoint Mechanism , because cache、persist Supported persistent storage media memory and disk are easy 【 The loss of 】, and HDFS Yes 【 High availability 】、【 Fault tolerance 】 Characteristics of , So will RDD The data is stored in HDFS On .
therefore checkpoint It also has the function of persistence , There's more 【 Safe and reliable 】 The function of .
Usage mode
First step :【sc.setCheckpointDir("hdfs://node1:8020/output/ckp/6_checkpoint")】 // Appoint HDFS The catalog of
The second step :【rdd.checkpoint()】// Frequently used later RDD、 Or very important RDD
Case study
Directly on the basis of the previous case , With a little modification , First specify HDFS The catalog of , then persist or cache Replace with checkpoint.
# -*- coding:utf-8 -*-
# Desc:This is Code Desc
import os
import json
import re
import time
from pyspark import SparkConf, SparkContext, StorageLevel
os.environ['SPARK_HOME'] = '/export/server/spark'
PYSPARK_PYTHON = "/root/anaconda3/bin/python3.8"
# When multiple versions exist , Failure to specify is likely to result in an error
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
#1- establish SparkContext Context object
conf=SparkConf().setAppName("2_rdd_from_external").setMaster("local[*]")
sc=SparkContext(conf=conf)
sc.setCheckpointDir("hdfs://node1:8020/output/ckp/6_checkpoint")
#2 Read the file
rdd=sc.textFile("file:///export/pyworkspace/pyspark_sz26/pyspark-sparkcore-3.1.2/data/apache.log")
#3 Wash and extract ip,\\s+ Represents general white space characters , such as tab key , Space , Line break ,\r\t
rdd2=rdd.map(lambda line : re.split('\\s+',line)[0])
# Yes rdd2 checkpoint Persist to HDFS
rdd2.checkpoint()
pv = rdd2.count()
#4 Calculation pv, Print
pv=rdd2.count()
print('pv=',pv)
#5 Calculation uv, Print
uv=rdd2.distinct().count()
print('uv=',uv)
time.sleep(600)
sc.stop()
result :
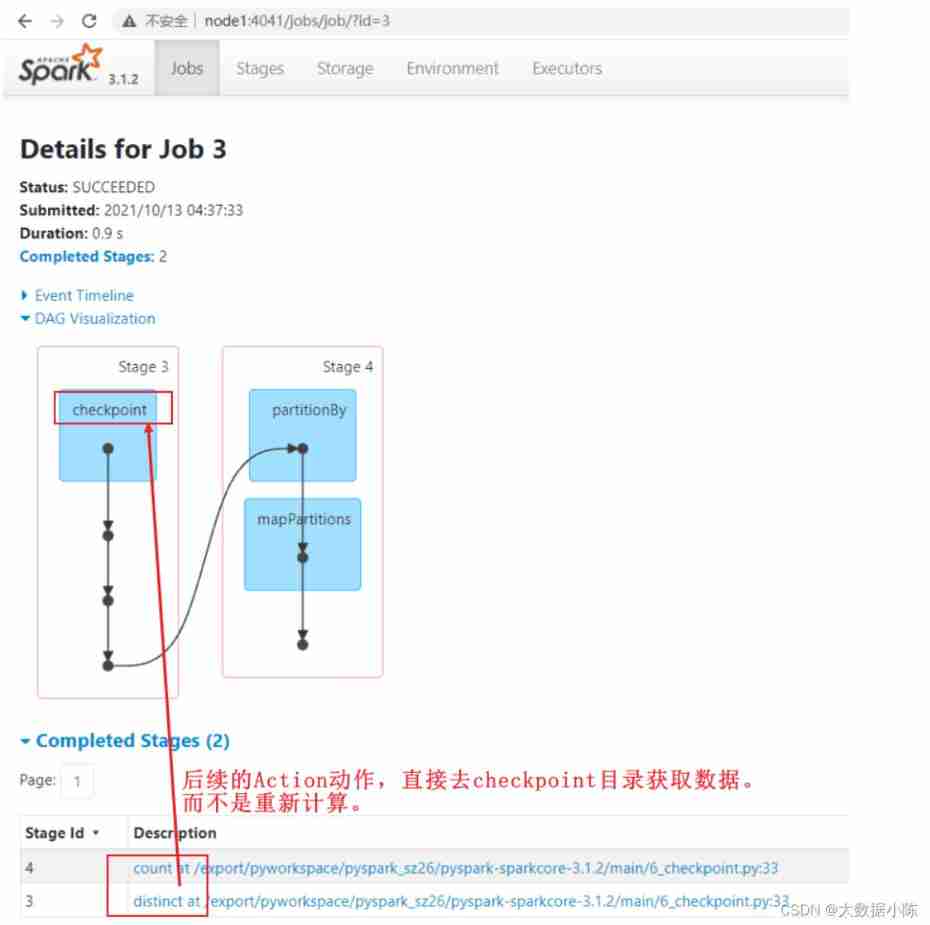
Persistence and Checkpoint The difference between
Location difference :persist or cache Will RDD The data is stored in 【 Memory 】、【 disk 】、【 Out of heap memory 】 in , however checkpoint Mechanism will RDD Data saved in 【HDFS】 On .
Life cycle : When Application completion of enforcement , Or call 【unpersist】, that persist or cache The data will be automatically cleared . however checkpoint Contents of the catalog 【 Can't 】 Automatic removal of , It needs to be cleared manually .
Consanguinity :persist or cache【 Meeting 】 Retain RDD By blood , If the data of a partition is lost , Then we can use 【 Dependent on kinship 】 Recalculate . however HDFS【 no need 】 Retain dependencies , Because even if the data of a partition is lost or damaged , Then it can also be used directly and conveniently HDFS In addition to 【2】 Copies .
边栏推荐
- Redistemplate common collection instructions opsforhash (IV)
- Technology sharing | packet capturing analysis TCP protocol
- Yyds dry inventory run kubeedge official example_ Counter demo counter
- 中国白酒的5场大战
- The underlying implementation of string
- The underlying implementation of string
- From campus to Tencent work for a year of those stumbles!
- Description of web function test
- SDL2来源分析7:演出(SDL_RenderPresent())
- Enhance network security of kubernetes with cilium
猜你喜欢
JPEG2000 matlab source code implementation

Is it profitable to host an Olympic Games?

【力扣刷题】一维动态规划记录(53零钱兑换、300最长递增子序列、53最大子数组和)
Numpy download and installation

Digital transformation takes the lead to resume production and work, and online and offline full integration rebuilds business logic
![[Digital IC manual tearing code] Verilog automatic beverage machine | topic | principle | design | simulation](/img/75/c0656c4890795bd65874b4f2b16462.jpg)
[Digital IC manual tearing code] Verilog automatic beverage machine | topic | principle | design | simulation

Microsoft technology empowerment position - February course Preview
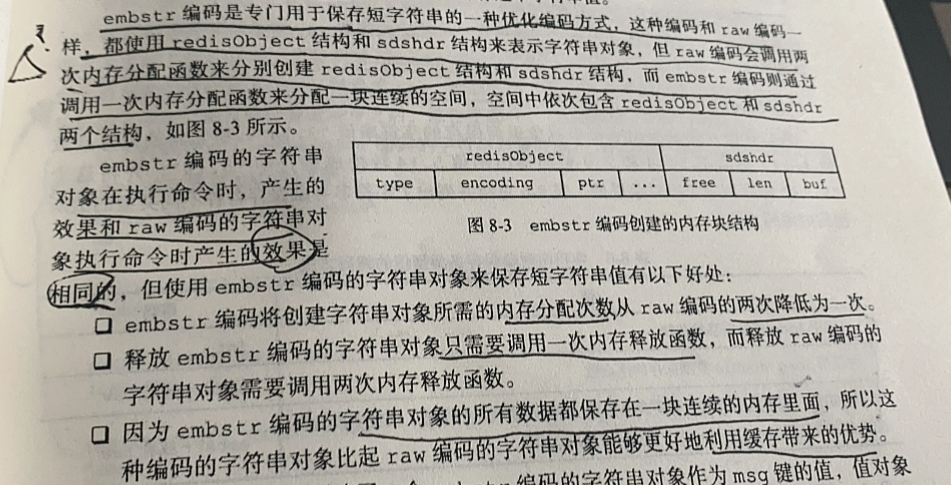
【Redis设计与实现】第一部分 :Redis数据结构和对象 总结

It's not my boast. You haven't used this fairy idea plug-in!
爬虫实战(五):爬豆瓣top250
随机推荐
The underlying implementation of string
Yuan Xiaolin: safety is not only a standard, but also Volvo's unchanging belief and pursuit
抖音将推独立种草App“可颂”,字节忘不掉小红书?
JS learning notes OO create suspicious objects
Tips for web development: skillfully use ThreadLocal to avoid layer by layer value transmission
50个常用的Numpy函数解释,参数和使用示例
One line by line explanation of the source code of anchor free series network yolox (a total of ten articles, you can change the network at will after reading it, if you won't complain to me)
Reinforcement learning - learning notes 5 | alphago
[Li Kou brushing questions] one dimensional dynamic planning record (53 change exchanges, 300 longest increasing subsequence, 53 largest subarray and)
Redistemplate common collection instructions opsforhash (IV)
Divide candy
NPM run dev start project error document is not defined
guava:Collections. The collection created by unmodifiablexxx is not immutable
麦趣尔砸了小众奶招牌
The role of applicationmaster in spark on Yan's cluster mode
袁小林:安全不只是标准,更是沃尔沃不变的信仰和追求
一行代码可以做些什么?
Summary of cross partition scheme
C how to set two columns comboboxcolumn in DataGridView to bind a secondary linkage effect of cascading events
Four common ways and performance comparison of ArrayList de duplication (jmh performance analysis)