当前位置:网站首页>ViT论文详解
ViT论文详解
2022-07-06 13:22:00 【低吟浅笑】
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
Billbill讲解:https://www.bilibili.com/video/BV1GB4y1X72R/?spm_id_from=333.788&vd_source=d2733c762a7b4f17d4f010131fbf1834
1.Introduction
基于自注意力的架构,尤其是 Transformers(Vaswani 等人,2017 年),已成为自然语言处理 (NLP) 的首选模型。主要方法是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行微调(Devlin 等人,2019)。由于Transformers 的计算效率和可扩展性,训练具有超过 100B 参数的前所未有的模型成为可能(Brown 等人,2020;Lepikhin 等人,2020)。随着模型和数据集的增长,仍然没有饱和性能的迹象。
但在计算机视觉领域,卷积仍占据主导地址。受NLP成功启发,多项工作尝试将类似CNN的架构与self-attention进行结合。其中一些完全取代了卷积,后一种模型虽然理论有效,但由于使用了专门的注意力模型,尚未在现代硬件加速器上有效地扩展,经典的ResNet仍为首选。
受NLP中的Transformer缩放成功的启发,尝试将标准的Transformer直接应用于图像,并尽尽可能减少修改。因此,我们将图像拆分为pathch,并提供这些patch的线性embedding作为Transformer的输入。Image patch的处理方式和NLP应用程序中的token(word)相同(一个句子有多少单词,一个图片有多少Patch)。我们以有监督的方式训练图像分类模型(nlp是用无监督来学习的)。
当没有强正则化的Transformer在中型数据集ImageNet上进行训练时,准确度比筒灯大小的ResNet低几个百分点。这是因为Transformer缺乏一些CNN固有的归纳 bias,例如平移不变形和局部性,因此在数据集不足的情况下无法很好地概括。
但是,如果模型在更大的数据集(14M-300M 图像)上训练,情况就会发生变化。我们发现大规模训练胜过归纳偏差。
2.Related Work
Self-attention简单地应用于图像需要每个像素地关注其他每个像素。由于像素数量的二次成本,不能扩展到实际输入大小。因为,为了在图像处理的上下文中应用Transformer,查询像素的局部领域中应用self-attention,对全局self-attention采用可扩展的近似值(稀疏注意力),以便适用于图像。扩展注意力的另一种方法是将其应用于不同大小的块(Weissenborn 等人,2019 年),在极端情况下仅沿单个轴应用(横轴、纵轴)(Ho 等人,2019 年;Wang 等人,2020a)。许多这些专门的注意力架构在计算机视觉任务上展示了有希望的结果,但需要复杂的工程才能在硬件加速器上有效实施。
与我们最相关的是 Cordonnier 等人的模型。 (2020),它从输入图像中提取大小为 2x2 的patch,并在顶部应用完全自注意力。该模型与 ViT 非常相似,但我们的工作进一步证明了大规模的预训练使 vanilla Transformer 可以与(甚至优于)最先进的 CNN 竞争。此外,Cordonnier 等人。 (2020) 使用 2 2 像素的小块大小,这使得该模型仅适用于小分辨率图像,而我们也处理中等分辨率图像。
另一个最近的相关模型是图像 GPT (iGPT) (Chen et al., 2020a),它在降低图像分辨率和色彩空间后将 Transformers 应用于图像像素。该模型作为生成模型以无监督方式进行训练,然后可以对生成的表示进行微调或线性探测以提高分类性能,在 ImageNet 上实现 72% 的最大准确度。
3.Method
在模型设计中,我们尽可能地遵循原始的 Transformer (Vaswani et al., 2017)。这种故意简单设置的一个优点是可扩展的NLP Transformer 架构及其高效的实现几乎可以开箱即用。
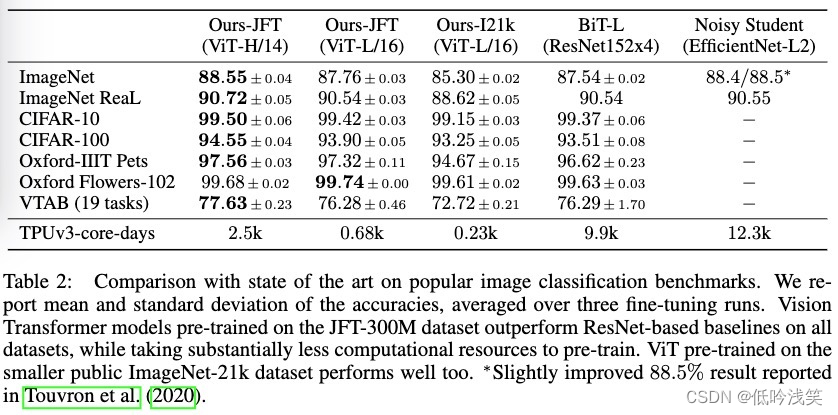
图 1:模型概述。我们将图像分割成固定大小的块,线性嵌入每个块,添加位置嵌入,并将生成的向量序列馈送到标准的 Transformer 编码器。为了执行分类,我们使用向序列添加额外可学习的“分类标记”的标准方法。 Transformer 编码器的插图受到 Vaswani 等人的启发。 (2017)
步骤:图--->分为多个patch--->将patch通过线性投影层---->添加Position Embedding---->Transformer Encoder-->MLP Head--->class
下面以224x224x3的输入,讲解该图。
输入X: 224x224x3 每个patch 的大小: 16x16 patch的数量 N = 224^2/16^2 = 196 每个patch转为1D Embedding:16x16x3=768
线性投影层 E: 768x768 (文章中维度D) 对于输入: 196x768 token: 1x768
通过线性投影层: [196x768] x [178x768] = [196,768] (矩阵乘法)
添加一个cls token,这个东西可以从其他196个embedding中学习分类特征:torch.cat([196,768],[1,768]) ==> [197,768]
添加位置编码:[197, 768] + [197, 768] ==> [197,768],求和 (2017年的Transformer证明+和concat效果一样)。
Multi-head attention。多头,e.g., 12个头,768/12 = 64,每个头是 197x64,拼接后是197x768。
MLP:一般维度放大,放大四倍 197x3012。后面再进行维度放缩,放缩回197x768。
Layer norm:区别于BN,在所有样本上,对CHW进行归一化操作。
3.1 Vision Transformer
标准的Transformer接收1D token作为输入。为了处理2D图像,将 变为一系列的扁平的2D patch ,其中。H和W是高度和宽度,C是通道,P每个patch 的分辨率。 是每个图像patch数,可作为Transformer的有效输入序列长度。Transformer 在其所有层中使用恒定的潜在向量大小 D,因此我们将 patch 展平并使用可训练的线性投影映射到 D 维(方程式 1)。我们将此投影的输出称为patch embedding。
与 BERT 的 [class] token类似,我们在embedding序列 (Z00= xclass) 中添加可学习的embedding,其在 Transformer 编码器 (Z0L ) 输出处的状态用作图像表示 y (方程 4)。在预训练和微调期间,分类头都附加到 Z0L 。分类头由 MLP 实现,在预训练时具有一个隐藏层,在微调时由单个线性层实现。
Position embedding 被添加到 patch embedding 中以保留位置信息。我们使用标准的可学习 1D position embedding,因为我们没有观察到使用更高级的 2D 感知位置嵌入带来的显着性能提升(附录 D.4)。生成的embedding vectors向量序列用作编码器的输入。
Transformer 编码器(Vaswani 等人,2017)由多头自注意力(MSA,见附录 A)和 MLP 块(等式 2、3)的交替层组成。在每个块之前应用 Layernorm (LN),在每个块之后应用残差连接 (Wang et al., 2019; Baevski & Auli, 2019)。
MLP 包含两个具有 GELU 非线性的层。
感知偏置。与CNN相比,Vision Transformer 的图像特征归纳偏差要少得多。在CNN中,局部性,二维领域结构和平移不变形被加到整个模型的每一层中。 在ViT中,只有MLP层是局部和平移不变的,而自注意力层是全局的,并在微调时调整不同分辨率图像的position embedding。除此之外,初始化时的position embedding不携带有关patch的2D位置信息,并且必须从头开始学习patch之间的所有空间关系。
Hybrid Architecture。混合架构。作为原始图像块的替代方案,输入序列可以由 CNN 的特征图形成(LeCun 等人,1989)。在这个混合模型中,patch embedding 投影 E(等式 1)应用于从 CNN 特征图中提取的补丁。作为一种特殊情况,patch 可以具有 1x1 的空间大小,这意味着输入序列是通过简单地将特征图的空间维度展平并投影到Transformer 维度来获得的。如上所述添加分类输入嵌入和位置嵌入。
3.2 Fine-tuning and higher resolution
通常,我们在大型数据集上预训练 ViT,并微调到(较小的)下游任务。为此,我们移除了预训练的预测头并附加了一个零初始化的 DxK 前馈层,其中 K 是下游类的数量。与预训练相比,以更高的分辨率进行微调通常是有益的(Touvron 等人,2019;Kolesnikov 等人,2020)。当提供更高分辨率的图像时,我们保持patch size相同,从而产生更大的有效序列长度。 Vision Transformer 可以处理任意序列长度(直至内存限制),但是,预训练的位置嵌入可能不再有意义。因此,我们根据它们在原始图像中的位置对预训练的位置嵌入进行 2D 插值。请注意,这种分辨率调整和补丁提取是将有关图像 2D 结构的归纳偏差手动注入视觉转换器的唯一点。
4.Experience
相比于其他方法,ViT性能更好,并且有着更小的训练时间。
灰色部分表示ResNet可以达到的效果,在小数据上,VIT的效果差于ResNet,在大数据集上,VIT优于ResNet。
图中展示了Transformer、ResNet、Hybrid三种模型,性能都在随着FLOPs增加而提高。暂未出现瓶颈。
对于相同FLOPs的模型,Transformer和混合模型优于ResNet。
混合模型可改善较小模型尺寸的纯Transformer,但相比于较大的型号没有优势。
4.5 Inspection Vision Transformer
Vision Transformer 的第一层将展平的patch线性投影到低维空间。图 7(左)显示了学习embedding fiters的主要组件。这些组件类似于合理的基函数,用于每个patch内精细结构的低维表示。
投影之后,将学习的位置嵌入添加到patch的表示中。图 7(中)显示该模型学习在position embedding的相似性中对图像内的距离进行编码,即更近的块往往具有更相似的位置嵌入。进一步,出现了行列结构;同一行/列中的补丁具有相似的嵌入。最后,对于较大的网格,有时会出现正弦结构(附录 D)。位置嵌入学习表示 2D 图像拓扑解释了为什么手工制作的 2D 感知嵌入变体不会产生改进(附录 D.4,因为Transformer已经从1D的位置编码中学习了相邻的特征表示)
Self-attention 允许 ViT 整合整个图像的信息,即使在最低层也是如此。我们调查网络在很大程度上利用了这种能力。具体来说,我们根据注意力权重计算图像空间中信息集成的平均距离(图 7,右)。这种“注意距离”类似于 CNN 中的感受野大小。一些参与低层网络的头也已经观察到了全局信息,这表明模型确实使用了全局集成信息的能力。其他注意力头在低层的注意力距离始终很小。这种高度局部化的注意力在 Transformer 之前应用 ResNet 的混合模型中不太明显(图 7,右),这表明它可能具有与 CNN 中的早期卷积层类似的功能。此外,注意力距离随着网络深度的增加而增加。在全球范围内,我们发现该模型关注与分类语义相关的图像区域。
5.Conclusion
我们已经探索了Transformer在图像识别中的直接应用。与在计算机视觉中使用自注意力的先前工作不同,除了初始patch提取步骤之外,我们不会将特定于图像的归纳偏差引入架构中。相反,我们将图像解释为一系列patch,并通过 NLP 中使用的标准 Transformer 编码器对其进行处理。这种简单但可扩展的策略在与大型数据集的预训练相结合时效果出奇地好。因此,Vision Transformer 在许多图像分类数据集上匹配或超过了现有技术,同时预训练成本相对较低。
边栏推荐
- 在Pi和Jetson nano上运行深度网络,程序被Killed
- 快讯:飞书玩家大会线上举行;微信支付推出“教培服务工具箱”
- numpy 下载安装
- HMS core machine learning service creates a new "sound" state of simultaneous interpreting translation, and AI makes international exchanges smoother
- 在最长的距离二叉树结点
- 2022菲尔兹奖揭晓!首位韩裔许埈珥上榜,四位80后得奖,乌克兰女数学家成史上唯二获奖女性
- Summary of cross partition scheme
- 20220211 failure - maximum amount of data supported by mongodb
- JS get array subscript through array content
- JS学习笔记-OO创建怀疑的对象
猜你喜欢

【滑动窗口】第九届蓝桥杯省赛B组:日志统计

Aiko ai Frontier promotion (7.6)
JPEG2000 matlab source code implementation
抖音將推獨立種草App“可頌”,字節忘不掉小紅書?
2017 8th Blue Bridge Cup group a provincial tournament

【力扣刷题】32. 最长有效括号
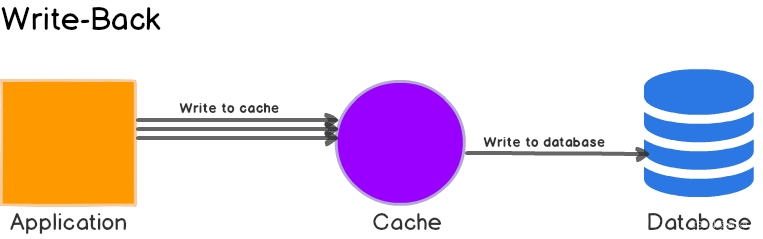
Caching strategies overview
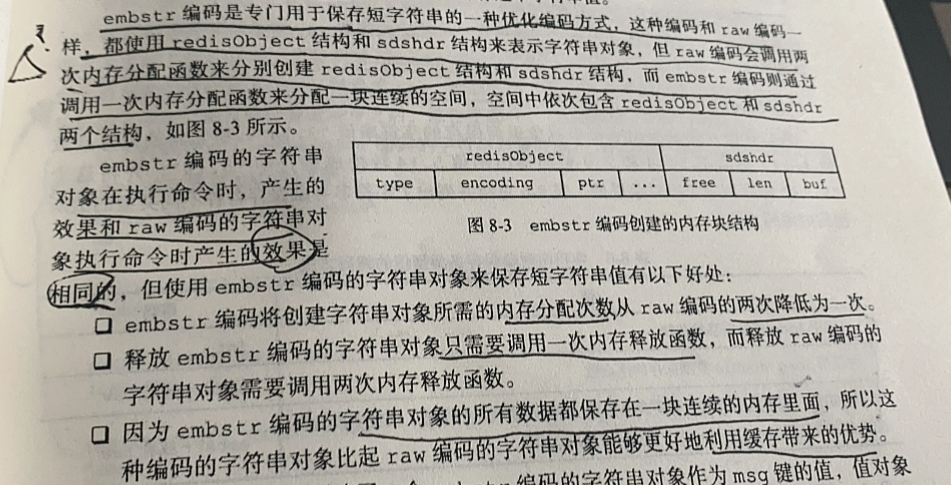
【Redis设计与实现】第一部分 :Redis数据结构和对象 总结
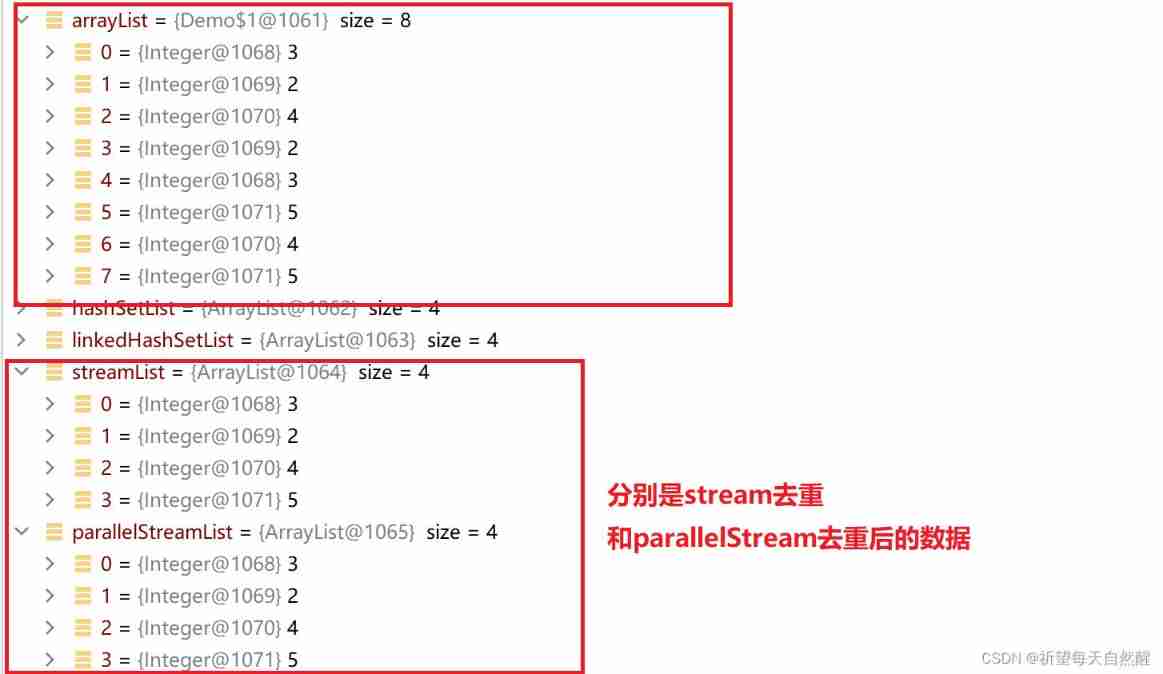
Four common ways and performance comparison of ArrayList de duplication (jmh performance analysis)
guava:Collections.unmodifiableXXX创建的collection并不immutable
随机推荐
分糖果
[Li Kou brushing questions] one dimensional dynamic planning record (53 change exchanges, 300 longest increasing subsequence, 53 largest subarray and)
Why does MySQL index fail? When do I use indexes?
首批入选!腾讯安全天御风控获信通院业务安全能力认证
Why do job hopping take more than promotion?
14 years Bachelor degree, transferred to software testing, salary 13.5k
代理和反向代理
guava: Multiset的使用
Dialogue with Jia Yangqing, vice president of Alibaba: pursuing a big model is not a bad thing
【力扣刷题】一维动态规划记录(53零钱兑换、300最长递增子序列、53最大子数组和)
Chris LATTNER, the father of llvm: why should we rebuild AI infrastructure software
Start the embedded room: system startup with limited resources
El table table - get the row and column you click & the sort of El table and sort change, El table column and sort method & clear sort clearsort
038. (2.7) less anxiety
KDD 2022 | realize unified conversational recommendation through knowledge enhanced prompt learning
基于深度学习的参考帧生成
C # use Oracle stored procedure to obtain result set instance
2022 fields Award Announced! The first Korean Xu Long'er was on the list, and four post-80s women won the prize. Ukrainian female mathematicians became the only two women to win the prize in history
Z function (extended KMP)
Word bag model and TF-IDF