当前位置:网站首页>Aggregate function with key in spark
Aggregate function with key in spark
2022-07-06 21:43:00 【Big data Xiaochen】
RDD Every element of is 【 Key value pair 】 To call the following functions .
groupByKey
aggregateByKey
rdd = sc.parallelize([('a', 1), ('b', 1), ('a', 1), ('b', 1), ('a', 1)], 2)
When aggregating in the following partition , The initial value will participate in the calculation , When aggregating between partitions , The initial value will not participate in the calculation .

foldByKey
foldByKey By aggregateByKey Simplify
When aggregateByKey The logic of aggregation functions within and between partitions of is the same , It can be omitted as a , It becomes foldByKey.
reduceByKey
reduceByKey By foldByKey Simplify
When foldByKey When the initial value of is meaningless , You can omit it
边栏推荐
- PostgreSQL 安装gis插件 CREATE EXTENSION postgis_topology
- The relationship between root and coefficient of quadratic equation with one variable
- JS学习笔记-OO创建怀疑的对象
- Set up a time server
- Quick news: the flybook players' conference is held online; Wechat payment launched "education and training service toolbox"
- Yuan Xiaolin: safety is not only a standard, but also Volvo's unchanging belief and pursuit
- guava:Collections.unmodifiableXXX创建的collection并不immutable
- Replace Internet TV set-top box application through digital TV and broadband network
- From campus to Tencent work for a year of those stumbles!
- Seven original sins of embedded development
猜你喜欢
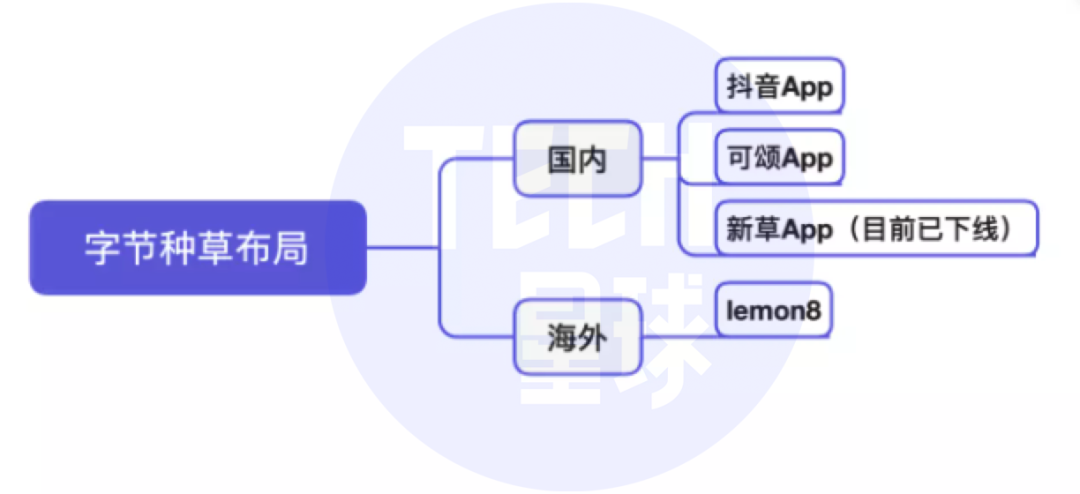
抖音将推独立种草App“可颂”,字节忘不掉小红书?
After working for 5 years, this experience is left when you reach P7. You have helped your friends get 10 offers
【Redis设计与实现】第一部分 :Redis数据结构和对象 总结
![Happy sound 2[sing.2]](/img/ca/1581e561c427cb5b9bd5ae2604b993.jpg)
Happy sound 2[sing.2]
Is this the feeling of being spoiled by bytes?
039. (2.8) thoughts in the ward

互联网快讯:吉利正式收购魅族;胰岛素集采在31省全面落地
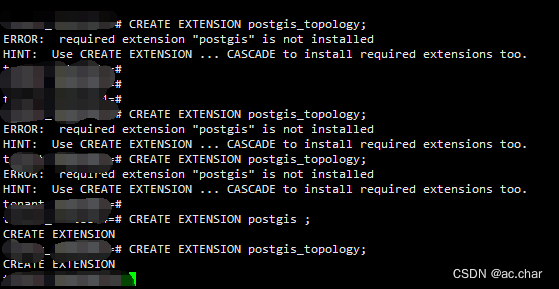
PostgreSQL 安装gis插件 CREATE EXTENSION postgis_topology
Set up a time server
![[sliding window] group B of the 9th Landbridge cup provincial tournament: log statistics](/img/2d/9a7e88fb774984d061538e3ad4a96b.png)
[sliding window] group B of the 9th Landbridge cup provincial tournament: log statistics
随机推荐
Chris LATTNER, the father of llvm: why should we rebuild AI infrastructure software
uni-app App端半屏连续扫码
跨分片方案 总结
C# 如何在dataGridView里设置两个列comboboxcolumn绑定级联事件的一个二级联动效果
Tiktok will push the independent grass planting app "praiseworthy". Can't bytes forget the little red book?
分糖果
快讯:飞书玩家大会线上举行;微信支付推出“教培服务工具箱”
Redistemplate common collection instructions opsforhash (IV)
50个常用的Numpy函数解释,参数和使用示例
document. Usage of write () - write text - modify style and position control
Web开发小妙招:巧用ThreadLocal规避层层传值
Why do job hopping take more than promotion?
Is this the feeling of being spoiled by bytes?
Reinforcement learning - learning notes 5 | alphago
guava:Collections.unmodifiableXXX创建的collection并不immutable
Thinking about agile development
mysql根据两个字段去重
PostgreSQL modifies the password of the database user
SQL:存储过程和触发器~笔记
3D face reconstruction: from basic knowledge to recognition / reconstruction methods!