当前位置:网站首页>DR-Net: dual-rotation network with feature map enhancement for medical image segmentation
DR-Net: dual-rotation network with feature map enhancement for medical image segmentation
2022-07-06 22:46:00 【Never_ Jiao】
DR-Net: dual-rotation network with feature map enhancement for medical image segmentation
Journal Publishing : Complex&Intelligent System( Categories: : Computer science 2 District
Time of publication : 2022 year
Abstract
In order to obtain more semantic information with small samples for medical image segmentation , This paper presents a simple and efficient double rotation network (DR-Net), It can enhance the quality of local and global feature maps . DR-Net The key steps of the algorithm are as follows ( Pictured 1 Shown ). First , Divide the number of channels on each floor into four equal parts . then , Different rotation strategies are used to obtain the rotation feature map of each sub image in multiple directions . then , Use multi-scale volume product and hole convolution to learn the local and global features of the feature graph . Last , Use residual strategy and integration strategy to fuse the generated feature map . Experimental results show that , Compared with the most advanced methods ,DR-Net The method can be found in CHAOS and BraTS Get higher segmentation accuracy on the dataset .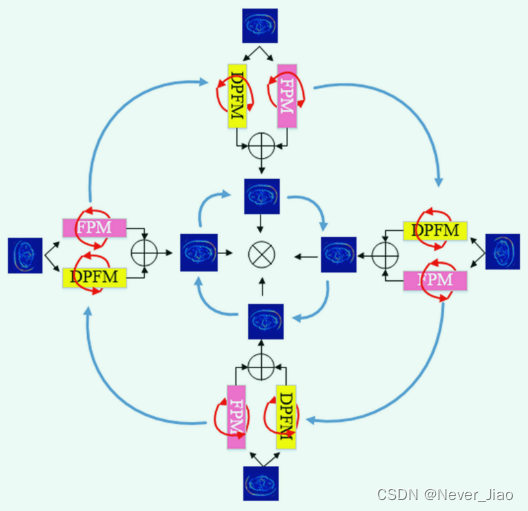
Fig.1 DR-Net Outer rotation and inner rotation of . The red line represents internal rotation , The blue line represents external rotation . The blue square indicates that the same feature map is used , Where the number indicates the direction of rotation . The green square represents the rotation characteristic graph , Use FPM and DPFM Get local semantic features and global semantic features ( A minus sign indicates reverse rotation )
Keywords: Dual-rotation convolution, Feature fusion, Medical segmentation, Deep learning
Introduction
Computer vision is widely used in medical tasks : Semantic segmentation of medical images [1-3]、 Medical image classification [4-6]、 Bioengineering recognition [7-9]、 Three dimensional reconstruction [10-12] etc. . Although deep learning is due to the complex structure of medical images 、 The pathological tissue is similar to the surrounding normal tissue 、 Small data sample size and other reasons , It has achieved great success in the field of Medicine , But it is difficult to obtain deeper semantic information . In order to further enhance the ability of the model to learn medical image features , Researchers have constructed various model strategies to mine deep features and obtain deep semantic information . Ni et al [3] A global context attention module is proposed to obtain the context semantic information of medical images , And integrate SEPP Multiscale receptive field information generated by the model , So as to provide more learning information for segmentation tasks . The model achieves good segmentation results on three public data sets and one local data set ; In order to better understand the intensity of lesions in medical images 、 Location 、 Subtle differences in shape and size ,Chen wait forsomeone [13] A new convolutional neural network structure is constructed , be known as DRINet. The network is integrated by dense network blocks [14]、 Residual network block and initial network block [15] Multiple feature maps generated , And get all kinds of semantic information . Last , It turns out that DRINet In three challenging applications, it is better than UNet; Alom et al [16] take U-Net [17] Improved to recursive U-Net And the residuals U-Net The joint model of . The model realizes the feature fusion of deep features and shallow features through residual blocks , adopt loop The module realizes the accumulation of residual volume layer semantic information . The algorithm obtains the best segmentation results on three data sets : Retinal image 、 Skin cancer segmentation and lung lesion segmentation ; Gu et al [18] A context encoder network is proposed (CE-Net). This network uses ResNet [19] To achieve feature extraction , And use dense convolution blocks and multi-layer pooled blocks [20] To get richer image context semantic information . 5 The results of data sets prove the feasibility of the model ( chart 1).
The above results show that , Different model strategies can obtain different semantic information to generate different feature maps ( for example , Shallow characteristic map 、 Deep feature map 、 Local characteristic graph and global characteristic graph ). The above strategy can only generate oneortwo characteristic graphs , Not comprehensive enough , Unable to obtain semantic information of medical images . Although the feature map generated by the fusion of multiple strategies can obtain more semantic information , But the total number of parameters will also increase , The computational complexity of the algorithm is greatly increased . Besides , The fusion of feature maps of each strategy is only established between the deep feature maps of each strategy , It makes it impossible to obtain other semantic information in the process of shallow to deep feature mining ; And the generated feature map is not rich enough .
The emergence of group convolution makes researchers without increasing network parameters , You can get richer semantic information . Xie wait forsomeone [21] Proposed ResNeXt Algorithm , Transform high-dimensional feature maps into multiple low-dimensional feature maps , Then the depth feature is obtained by learning the low dimensional feature map . The advantage of converting high-dimensional feature map to low-dimensional feature map is that it can reduce the number of parameter calculations . Their algorithm is ImageNet-1 k Good results have been achieved on the dataset , It is proved that group convolution has good feature learning ability . Romero et al [22] An attention strategy based on group convolution is introduced , The constructed attention group convolution can enhance the feature map . These findings , Group convolution can improve the feature learning ability of the network . In previous work , Researchers increase the number of training samples by preprocessing the images [23, 24], Thus, the test accuracy of the data set is improved .
In order to obtain richer semantic information without increasing algorithm complexity and reducing data preprocessing , This paper presents a faithful deep learning algorithm : Double rotating network (DR-Net).
The main contributions of this paper are as follows :
1、 We divide the feature map generated by the previous layer into four equal channel parts according to the total number of channels . Then according to different rotation angles ( The rotation angles are 0°、90°、180°、270°) Rotate each part , Realize the internal rotation of traditional convolution . then , Different local semantic information is obtained from the rotated feature map through convolution kernels of different sizes , So as to generate a deeper local feature map . ad locum , We call these characteristic graphs partial characteristic graphs (PFM).
2、 We also divide the feature map generated by the previous layer into four parts with equal number of channels according to the total number of channels . And then , We also rotated each part in four directions . Different from the previous method, the feature mining method is that we use hole convolution to obtain different perception domains by setting different extension values , So as to obtain more global semantic information . The convolution kernel size of all our extended convolutions is set to 3. ad locum , We call these characteristic graphs extended partial characteristic graphs (DPFM).
3、 In order to further obtain richer semantic information , We've fused PFM and DPFM Features in the same direction of rotation ( Add strategy through feature graph ), In the end in DR-Net Each layer of the algorithm obtains 16 Group richer feature map ( These feature maps form an outer rotation ).
4、 In order to obtain the fusion feature map of shallow feature map and deep feature map , At the same time, get more semantic information , Get the shallow feature map of the previous sub module . We use the transfer invariance of maximum pooling to compress the characteristic graph . Last , Use the rotation angle 、 Three strategies, multi-scale convolution and different expansion steps, generate semantic information to describe shallow features 、 Deep feature semantic information 、 Feature graph of local feature semantic information and global feature semantic information .
The main contents of the rest of this paper are summarized as follows . The second section mainly introduces the background and significance of this algorithm . The third section introduces DR-Net The overall flow of the algorithm and the functions of each module . In the fourth part , We have verified through relevant experiments DR-Net Performance of the algorithm . In part five , We give a summary of this paper and further research objectives .
Related work
Characteristic graphs are defined by their widths 、 Definition of height and number of channels . In recent years , Researchers use the number of channels as a benchmark to enhance the relationship between feature maps . for example , Xie et al [21] Et al. Used group convolution ,Chollet [25] Use separable convolution ,You et al. [26] It is proposed to use partial characteristic graph . Although the names of these methods are different , But they are all based on addressing the number of channels , To improve the quality of the feature map or reduce the number of parameter calculations . Next , We will analyze the advantages and disadvantages of the above three strategies in detail .
Group convolution (GC)
The principle of group convolution is to use a 1×1 Convolution kernel from the original characteristic graph (256 Channels ) Number of compressed features in , Generate 32 Group 4 New characteristic diagram of channels . The channel compression strategy has also been verified in previous work [27-30]. The purpose of this method is to reduce the redundant information of the depth feature map , Reduce the number of parameter calculations . And then , The convolution kernel is 3 To mine the previous 32 Group characteristic map , The computational complexity of features is reduced . then , The compressed characteristic graph is 1 Convolution recovery (4 The characteristic graph of the channel is restored to the original number of channels 256 Characteristic graph ). Last , The characteristic graph is fused through the aggregation residual exchange strategy . Then by Gao Et al Res2NeXt The Internet [31] The efficiency of group convolution is also proved .
Deep separable convolution (DSC)
The principle of deep separable convolution is to divide the original feature map into N Sub channels , adopt N Feature mining with convolution kernel , Generate intermediate feature map . By splicing the middle feature map , Restore the number of feature maps with the original number of feature channels . And then , The stitched middle feature map passes 1×1 Convolution compression characteristic graph , At the same time build N individual 1×1 Convolution recovery characteristic graph .
Multidirectional integrated convolution (MDIC)( Multidirectional integration convolution )
The core idea of the algorithm is to divide the original feature map into four groups of sub feature maps , Flip each sub feature map in different directions , Feature map is extracted after multi-scale feature inversion . The algorithm obtains a variety of semantic information through the above strategy to enhance the feature map . result , Even with a small number of fitters , You can also get more accurate segmentation results . Final ,520 The total number of parameters of 10000 is much smaller than that of other models .
Our strategy
Our proposed model passed PFM Get all kinds of local semantic information , At the same time through DPFM Get all kinds of global semantic information . The semantic information obtained is richer than the above algorithm . For depth characteristic map and shallow characteristic map , This paper introduces a new residual strategy . This strategy compresses and extends the characteristic graph . The semantic information of the upper feature map is fused in the encoder . The decoder not only obtains the characteristic diagram of the corresponding encoder , The characteristic diagram of the upper decoder is also obtained . The whole sub module gets richer semantic information .
Based on previous studies ,DRNet The main purpose of the algorithm is to reduce the number of parameter calculations and enhance the features . Next , We use tables 1 Directly compare the number of parameters of each group of convolution modules and the type of characteristic graph obtained . “Shallow” It represents the shallow characteristic map ,“Deep” Represents the depth characteristic map ,“Local” Represents a local feature map ,“Global” Represents the global feature graph ,“C” Represents traditional convolution .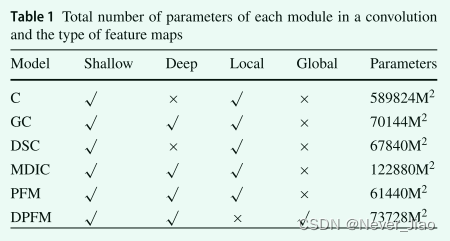
All blocks are implemented on convolution . “M” Represents the size of the feature map . The size of convolution kernel is uniformly set to 3, Input and output fitter The size of is set to 256. From the table 1 It can be seen that , What we proposed PFM The total number of parameters of the module is the lowest . DPFM The number of parameters of the module is the same as GC Module and DSC Module similarity . because PFM and DPFM The addition strategy of , The calculation times of all parameters in this part are the least .
Methodology
In this section , We will introduce our proposal in detail in four sections DR-Net Algorithm . The next section introduces the framework of the whole model , The next section introduces PFM and DPFM The details of the , The next section introduces encoder and decoder Different strategies used in , The next section introduces DR-Net Environment detail algorithm ( chart 2).
DR-Net
chart 1 Shows our proposed DRNet The overall structure of the algorithm . DR-Net The algorithm consists of two inner rotation convolutions from the second layer encoder sub module to the penultimate layer decoder sub module ( Traditional convolution and void convolution ) form . Give Way 
Through multi-directional and multi-scale feature mining 32 Group (32 How did it come from ,4 A direction , Every direction 4 Group ,n from 1 To 4,PFM Yes 16 Group ,DPFM Yes 16 Group , altogether 32 Group ) New feature map , And use this 32 A new set of characteristic graphs is formed 16 Group ( In the same direction and scale PFM and DPFM For a group ) Deep feature map containing global semantic information and local language information . here ,n Represent different parts (n What does it mean to represent different parts ),d Represents the rotation angle ,k Represents the size of the convolution kernel ,D Represents expansion value . The purpose is to reduce the number of feature maps , At the same time, strengthen the feature map . In the encoder section , In order to further improve the feature map Y(x) The quality of the , Current sub module layer H(x) The generated feature map and the multi rotation direction feature map generated by the previous sub module Md(x) It is a feature fused by residual operation .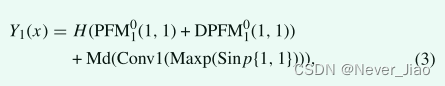
among Conv1 Indicates that the size of the convolution kernel is equal to 1,Maxp Indicates maximum pooling ,Sinp{1,1} Represents the input and direction of the first set of features of the previous layer feature graph .
In the decoder , The feature map generated by the sub module of the current layer F(x) Not only the corresponding characteristic diagram of the encoder is obtained Y(x) The prior information of , It also integrates the feature map generated by the previous sub module . Through the above two feature fusion strategies of encoder and decoder , The feature map of each layer contains more semantic information of medical images , Finally through softmax Function to complete multi classification tasks .
PFMs and DPFMs
Partial feature maps(PFMs)
In this internal rotation , We divided four groups according to the total number of channels PFM, And rotate each group in different directions PFM. Even if the same convolution kernel is used , We can also get semantic information of feature graphs in different directions [26]. In order to further obtain more semantic information , In this part , We introduced PFMs Multiscale convolution in , And you end up with 16 Group feature graph with different semantic information . Through the above multi-directional and multi-scale convolution , Get a large number of rich local characteristic graphs . Although we divide the total number of channels into groups PFM To reduce the number of parameter calculations , But in order to further reduce the number of parameter calculations , We compress the feature graph . The specific calculation of the total number of local features and the parameters of the feature map are as follows :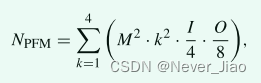
among NPFM Represents the total number of parameters ,M Represents the scale of the feature map ,k Represents the size of the convolution kernel ,I Represents the total number of channels of the input characteristic graph ,O Represents the total number of channels of the output characteristic graph ( Enter the total number of channels of the characteristic graph divided by 4, Because of the division 4 Group , Then divide the total number of channels of the output characteristic graph by 8, What is it for? ?).
Dilated partial feature maps (DPFMs)
DPFM The module is structurally similar to PFM Module similarity . The difference is that we use void convolution instead of traditional convolution . The purpose is to obtain different receptive fields through different expansion coefficients , Finally get more global semantic information . We use different extended convolution structures in the last two sub modules of the encoder and the first two sub modules of the decoder . The purpose is to reduce the size of the feature map , A more valuable characteristic graph is obtained by convolution of double-layer holes . The structure of two groups of different hole convolution modules is shown in the figure 3 Shown . The total number of calculations with global characteristic graph parameters is as follows :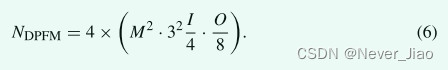
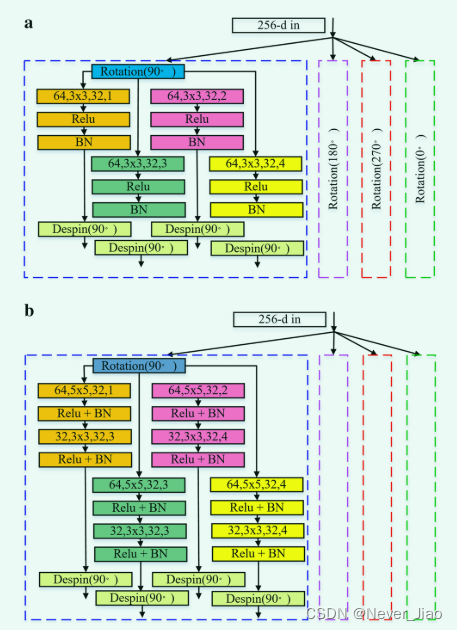
Fig.3 DPFM Network structure of different sub modules . a DPFM The structure of the first two floors , b DPFM The structure of the last two layers . The dotted line represents DPFM Different directions in the module , But the network structure is the same . ( Each dimension in the convolution represents the following : Enter the number of feature maps 、 The size of the convolution kernel 、 The number of output feature graphs 、 The scale of expansion )
Encoder and decoder
DR-Net The encoder and decoder of are composed of 5 The sub modules are composed of . In order to further fully obtain the feature map of different semantic information , We combine the second and fifth sub modules in the encoder and the first and fourth sub modules in the decoder , Make up the PFM and DPFM Strategy . And U-Net Pattern [17, 32, 33] Different , In the encoder section , Mining only the features of the current layer . Besides , The decoder part only contains the prior characteristic diagram of the corresponding encoder . Besides , And MC-Net[20] The difference between network models is , The semantic information of the encoder is increased by constructing multiple scales , Get more information by fusing semantic information of different scales . What we proposed DR-Net Not only use multi-directional and multi-scale strategies to obtain more feature maps . In the encoder section , The method also integrates PFM The local feature map generated by the module and DPFM Global feature map generated by the module , Expand the experience of each feature point . The input feature graph utilizes the feature invariance of the maximum pooling layer , Introduce the semantic information of more upper level sub modules into the current layer . In the decoder part , On the current upper level , We not only introduce the characteristic graph of the encoder output of the corresponding layer , Also refer to the characteristic diagram of the upper input of the decoder , Thus, more semantic information can be obtained . The different structural models of encoder and decoder are shown in Figure 4 Shown .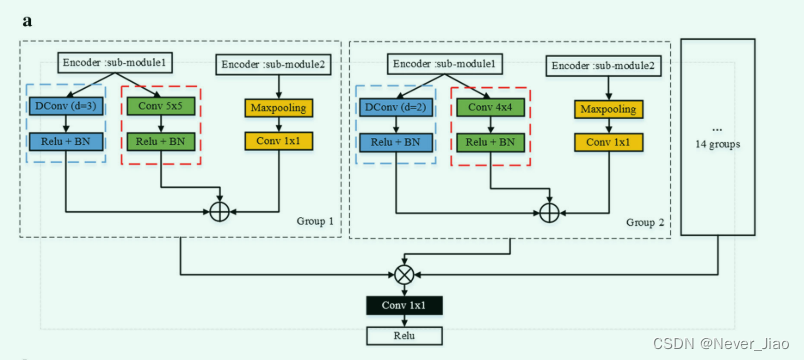
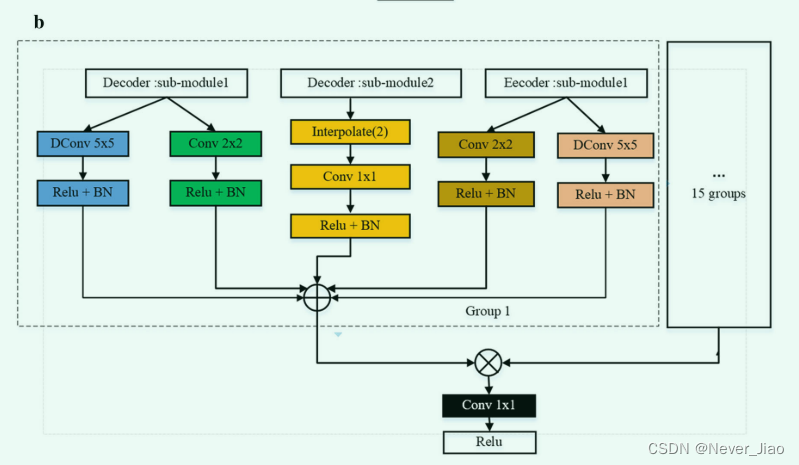
Fig.4 DR-Net Model diagram of encoder and decoder . a The model structure of the second to fifth sub modules of the encoder , and b The model structure of the first to fourth sub modules of the decoder . here ,“submodule 1” Represents the structure diagram of the current layer sub module ,“submodule 2” The structure diagram of the upper sub module ,⊕ Represent the residual operation of multi class feature graph ,⊗ Indicates fusion 16 Group residual characteristic diagram ,“interpolate” It means that linear strategy is used to enlarge the size of the feature map 2 times ,d Represents the expansion coefficient of hole convolution
Pictured 3 Shown , We divide the feature map generated by the previous layer into 4 Group , Equal number of channels . chart 4a in , The network structure of blue dotted line realizes different scales PFM, The network structure of red dotted line realizes different scales DPFM, other 14 The network structure is the same as that of the first group and the second group . therefore , We go in different directions 、 Convolution kernels of different scales , From the feature map of the upper layer 16 Set up a new feature map . The picture above 4a Show , In the encoder section , We calculate the residual between the characteristic graph generated by the current layer convolution and the extended convolution and the characteristic graph generated by the previous layer . chart 4b The biggest difference between the display encoder and the decoder is that we introduce the prior information of the encoder . Through the above feature fusion ,DR-Net Each sub module of the model can obtain more abundant characteristic graphs .
Implementation details
All our experiments are in 3 Group Tesla V100 (16 GB) GPU On . These two datasets only adjust the size of medical images , And keep the length width ratio as 256 and 256. Besides , No image preprocessing . The optimization function we choose is Adam, The learning rate is 0.001,beta The range is 0.9-0.999, The loss function is the cross entropy loss , During the whole training process, all the comparison models are iterated 300 Time . Each group of our experiments runs 5 Time , Select the group with the highest comprehensive evaluation .
Experiments
Data sets
In this paper , We are working on two multi classification datasets CHAOS and BraTS The proposed model is verified on DR-Net.CHAOS Data sets [34]: The data set is composed of 4 Foreground classes ( The liver 、 Left kidney 、 Right kidney and spleen ) And a background class . The size of all medical images is 256×256. We chose 647 With a real label MRI Image validation . The ratio of the number of samples in the training set to the number of samples in the test set is 3:2. The evaluation criteria of this data set come from You Articles of others . [26].
BraTS Data sets [35, 36]: The data set is composed of 3 Foreground classes ( edema 、 Non reinforced solid and reinforced core ) And a background class . The proportion of all its medical images is 240×240, So we add zero to every medical image . We are 285 In the group of cases, the two sample images with the largest lesion area in each case were selected . Besides , We also take the sample as 3:2 The proportion is divided into training set and verification set . The evaluation criteria of this data set come from Bakas wait forsomeone [35] The article .WT Including all three tumor structures ,ET Including except for “ edema ” All tumor structures except ,TC Only those unique to advanced cases “ Enhance the core ” structure .
Comparison with the state-of-the-art models
In this section , We compared the classical medical segmentation models U-Net, And compares some algorithms that have achieved good results in the field of medical image segmentation recently , for example CE-Net [18]、DenseASPP [37] and MS-Dual [38]. What this article puts forward DR-Net The performance of the model is verified by comparing its results with those of other models ( surface 2、 surface 3).
Each model is CHAOS Experimental results on data sets show that , although Liver for CE-Net The result is better than our method 1%, But in Kidney L Class , Our method is higher than the second method CE-Net good 1.38% A little bit . stay Kidney R In category , Our method is higher than the second method MSDual good 2.12%. In spleen , Our method is higher than the second CE-Net good 1.86%. Besides , On the other three comprehensive indicators , Our method achieves higher accuracy , It proves the feasibility of our method .
In order to further evaluate the generalization ability of our proposed method , We are BraTS Each model is further validated on the dataset . Our approach is at all WT Better than other models in value , It shows that our model has better generalization ability in multi classification . Dice+ The results of the three values of clearly show ,DR-Net The algorithm is far better than other algorithms . In each test TC The value clearly indicates , Our proposed model is better than the second algorithm in each test 4.28%、5.38% and 0.1%, This further proves that DR-Net Better at learning advanced cases . The experimental results on the above two data sets clearly show that the method proposed in this paper is effective . We are in the picture 5 The segmentation results of each model are visualized in .
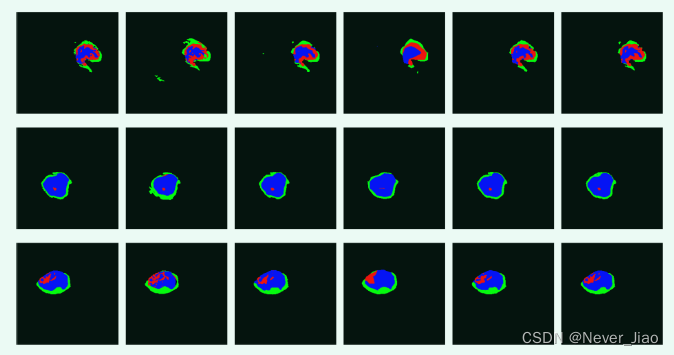
Fig.5 Each model is CHAOS Data sets ( The first 1-4 That's ok ) and BraTS 2018 Data sets ( The first 5-8 That's ok ) Split results on .a ground truth b U-Net c CE-Net. d dense-ASPP e MS-Dual f DR-Net
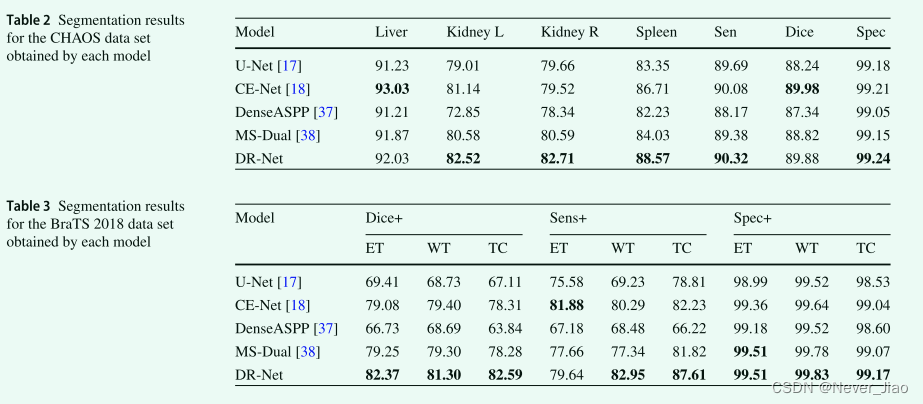
chart 5 It shows the segmentation results of each model on different data sets . The first group 、 The segmentation results of the fourth and sixth groups show ,DR-Net The algorithm has better segmentation effect on background classes , Thus, less noise is generated . The segmentation results of other groups also show that ,DR-Net It also has good prediction ability in edge segmentation and small shape . This further proves that our proposed method can obtain a deep feature map containing more semantic information by strengthening multiple feature maps . Even in the case of small data sets and a small number of feature maps , This method can also learn more meaningful depth features .
Comparison of the total number of parameters in the two data sets
The total number of parameters directly affects the learning efficiency of the model , The number of characteristic graphs directly affects the total number of parameters . In this paper , Our proposed method reduces the feature map at the same time , It still achieved good results on most indicators in the two data sets . surface 4 The total number of parameters of each model is listed in detail .
surface 4 Show , In the five groups of models compared , Our approach is CHAOS Only 2,700,581 Parameters , stay BraTS Only 2,704,156 Parameters , Far less than other models . Besides , The model inputs data in a single (CHAOS Data sets ) And multiple input data (BraTS Data sets ) There is no difference in the total number of parameters on .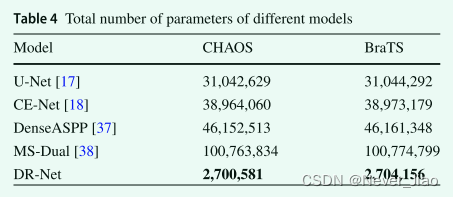
The impact of different strategies on the experiment
In order to further analyze the feasibility of each strategy proposed in our method , We have verified each strategy . here ,“1” Contains only PFM modular ,“2” Contains only DPFM modular ,“3” It only contains the prior semantic information of the previous layer ,“4” A priori semantic information decoder sub module containing only symmetric encoding sub module . To verify semantic information ,“5” Medium PFM and DPFM There is no rotation strategy . For the sake of strategy “1” And strategy “2” Feature fusion strategy is used in , We will strategy “1” Change to two groups DPFM modular , The strategy “2” Change to two groups PFM modular . We go through the picture 6 The line graph in describes the learning process of each model .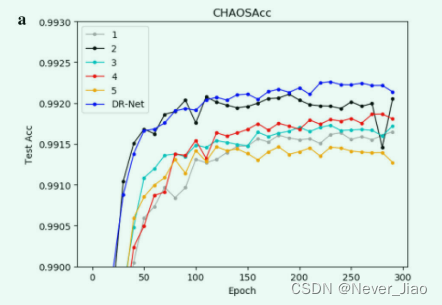
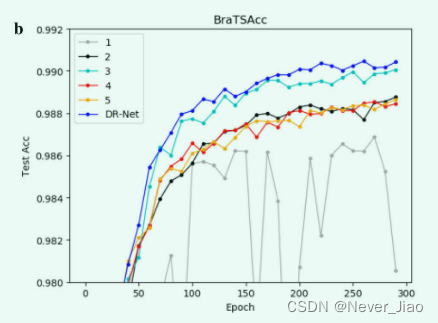
Fig.6 The learning process of each strategy on different data sets .a CHAOS Data sets . b BraTS Data sets
chart 6 The experimental results show that , Each strategy plays an active role in learning the semantic information of medical images . PFM The structure of is right CHAOS Data sets have less impact . The reason may be that the distribution of various organs is not centralized , The global characteristics have a great influence . stay BraTS Data set ,PFM Greater impact , There's a lot of volatility . The reason may be that the focus of the data set is relatively concentrated , Local features become particularly important . Our method has the best experimental effect after fusing various feature maps , The feasibility of our proposed algorithm is proved .
Application of our proposed module in othermodels
For further proof PFM and DPFM In our proposal DR-Net Feasibility in the model , We will PFM Module introduces U-Net. We have improved the total number of parameters and the learning results , And compare the results with original U-Net The results are compared . The results are as follows 5 Shown . ↑ The higher the value of , The better the performance of the model .
We use it PFM Module replaces the original convolution , Except for the first convolution . stay CHAOS Experimental results on data sets show that , My improved UNet Of mAverage Than traditional U-Net mAverage high 3.38%, And in the BraTS Experimental results on data sets show that , My improved U-Net Of mAverage Than traditional U-Net high 3.58% Conventional U-Net. The results of the above algorithm clearly illustrate the feasibility of our proposed strategy . The total number of parameters is also greatly reduced .

The influence of rotation angle and different convolution strategies on DR-Net algorithm
In order to further verify that the rotation strategy and different convolution strategies can be used at the same time to obtain more semantic information , In this section , We use specific experimental results to analyze the importance of each strategy on two data sets . DR-Net(0°) Indicates that the feature map is not rotated at all ,DR-Net(90°) Represents the rotation of the feature map 90°,DR-Net(180°) Represents the rotation of the feature graph multiplied by 180°,DR-Net (270°) Indicates that the feature map is rotated 270°,DR-Net(a) Indicates that only traditional convolution is used for feature learning ,DR-Net(b) Indicates that only the inflated convolution feature learning amount is used . The specific results of the two data sets are shown in table 6 Shown .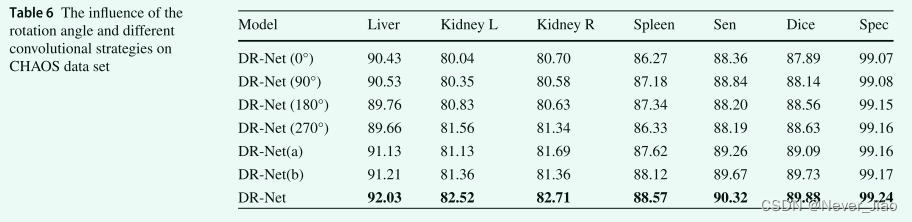
In the table 6 in , We find that the rotation strategy is right CHAOS Data sets have a greater impact than convolution strategies . Different rotation strategies obtain different features , Thus, the learning points of each class are different . When the feature map rotates 90° when ,Liver Get the highest value 90.53%; When the feature map rotates 180° when ,Spleen The accuracy of 87.34%; When the feature map rotates 270° when ,Kidney L The accuracy of 81.56%; And when there is no rotation feature graph , The results are relatively balanced . When using DR-Net Of 4 Two types of rotation , To obtain the CHAOS The best prediction results of various types in the data set . In the table 7 in , In multimodal BraTS On dataset , We find that both rotation strategy and convolution strategy play a positive role . If in DR-Net Only traditional convolution is used in the algorithm , The result of the learned feature is lower than that when only using hole convolution , This shows that hole convolution is more important to obtain global features in multimodal tasks . surface 6 And table 7 indicate , When DR-Net When the algorithm uses rotation strategy and multiple convolution strategies at the same time , The best prediction result is obtained , It is further proved that DR-Net The rationality of the algorithm .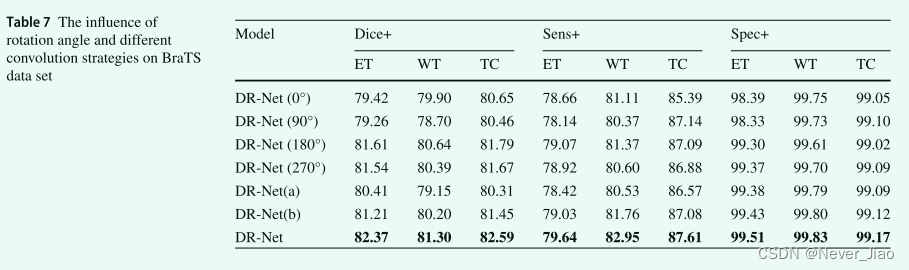
Conclusion
This paper presents a double rotation network , Fully learn and integrate global features 、 Local features 、 Shallow features and deep features , Mining more semantic information . Besides , In order to further integrate more semantic information in encoder and decoder , We rotate the characteristic graph 、 Three strategies of multi-scale and different expansion steps further strengthen the characteristic map . We fuse the original feature map of the previous sub module through the latter sub module , Provide more semantic information for encoder ; Besides , In order to make the decoder get more semantic information , We compress and expand the features . Graph realizes the fusion of various types of feature graphs . Last , The method proposed in this paper has achieved good segmentation results on two multi class medical image datasets .
边栏推荐
猜你喜欢




随机推荐
That's why you can't understand recursion
Comparison between variable and "zero value"
Sword finger offer question brushing record 1
树的先序中序后序遍历
Gd32f4xx serial port receive interrupt and idle interrupt configuration
空结构体多大?
signed、unsigned关键字
Export MySQL table data in pure mode
On the problems of born charge and non analytical correction in phonon and heat transport calculations
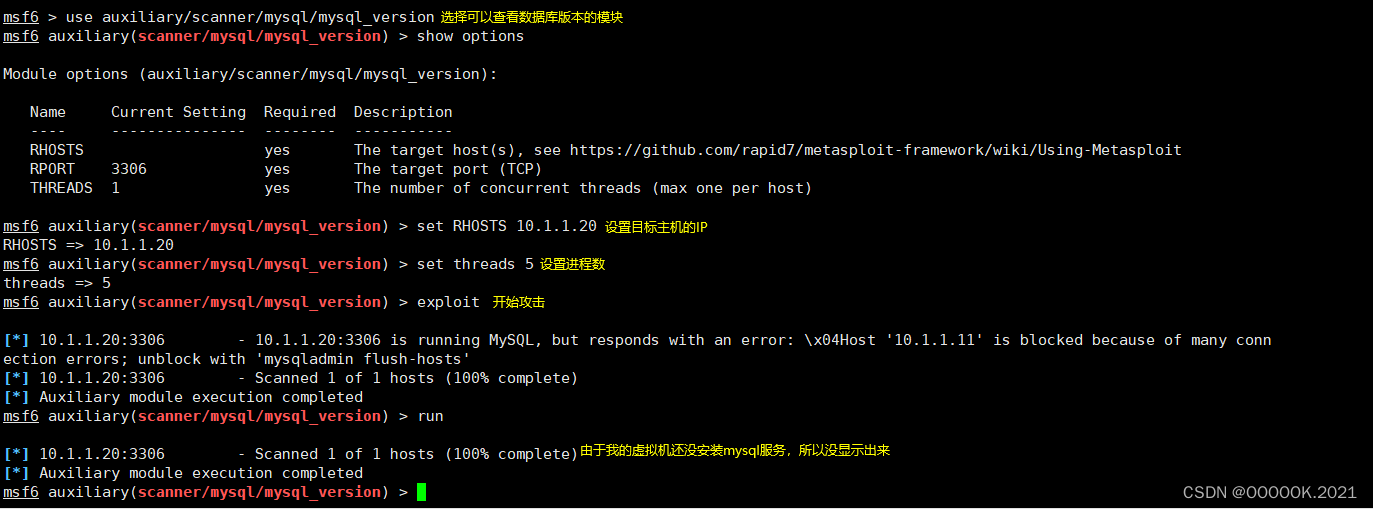
Plafond du tutoriel MySQL, bien collecté, regardez lentement
UE4蓝图学习篇(四)--流程控制ForLoop和WhileLoop
How to confirm the storage mode of the current system by program?
Aardio - 封装库时批量处理属性与回调函数的方法
Is there any requirement for the value after the case keyword?
金融人士必读书籍系列之六:权益投资(基于cfa考试内容大纲和框架)
服务器的系统怎么选者
【无标题】
Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR2022 oral)
Volatile keyword
第十九章 使用工作队列管理器(二)