当前位置:网站首页>AdaViT——自适应选择计算结构的动态网络
AdaViT——自适应选择计算结构的动态网络
2022-07-06 14:46:00 【Law-Yao】
Paper地址:https://arxiv.org/abs/2111.15668
GitHub链接:GitHub - MengLcool/AdaViT: Official implementation of AdaViT
Methods
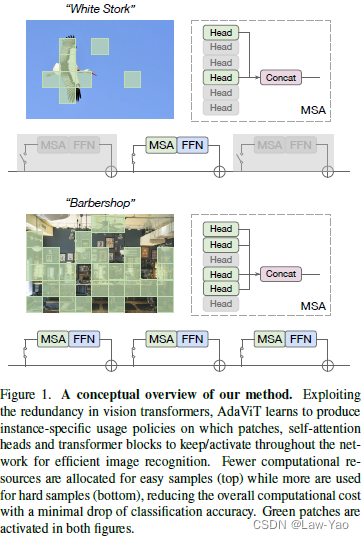
ViT基于其自身结构的特点或优势,具备较好的抽象语义表达或特征表征能力:
- 通过Attention计算,实现全局相关性信息编码;
- 通过Multi-head Attention,进一步实现不同子表征空间的特征抽象与融合;
- 通过深层次Transformer layer的堆叠,更进一步实现特征抽象;
然而,针对不同难易程度的样本,ViT实际计算所需的Patch数量、Attention head数目或网络层数可以存在区别,因此可构造样本驱动形式的条件计算(Sample-driven conditional computation)。

AdaViT通过设计动态网络结构,可根据输入样本的难易程度、自适应选择最佳的计算结构,包括Patch selection、Attention head selection以及Block selection,具体方法描述如下:
- Decision network:每个Transformer layer都会设置一个决策网络(由三个线性层构成),决策网络的输入为当前Transformer layer的输入特征,其输出为结构参数,分别用以实现Patch selection、Attention head selection和Block selection。结构参数进一步通过Gumbel-softmax采样,生成Binary mask:
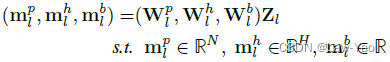
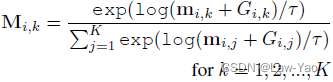
- Patch selection:除Class token之外,其余Token会执行自适应选择(Keep the most informative tokens):
![]()
- Head selection:针对复杂场景或嘈杂背景,通常需要更好的子空间特征表达与多Head信息融合,以表达信息多样性;但对于简单样本,无需较复杂的多样性表达。Head selection有两种实现形式,一是将Mask为0的Head输出替换为全一张量(Partial deactivation),二是直接消除相应的Attention Head(Full deactivation):
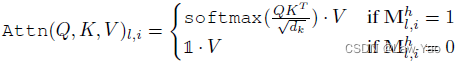
![]()
实际结果表明,Full deactivation能够节省更多计算量,但对识别精度的影响会更大。
- Block selection:主要包括MSA与FFN的条件选择,以实现Depth维度的结构压缩(对于简单样本,无需深层次的重复信息编码):
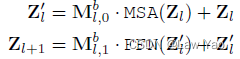
- Objective function:首先是任务相关的Loss,例如分类任务的CE loss;其次是约束结构参数的平滑项(Gamma参数表示目标计算预算,用来约束计算成本):
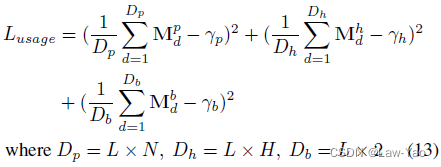
则总的优化目标可表示为:
![]()
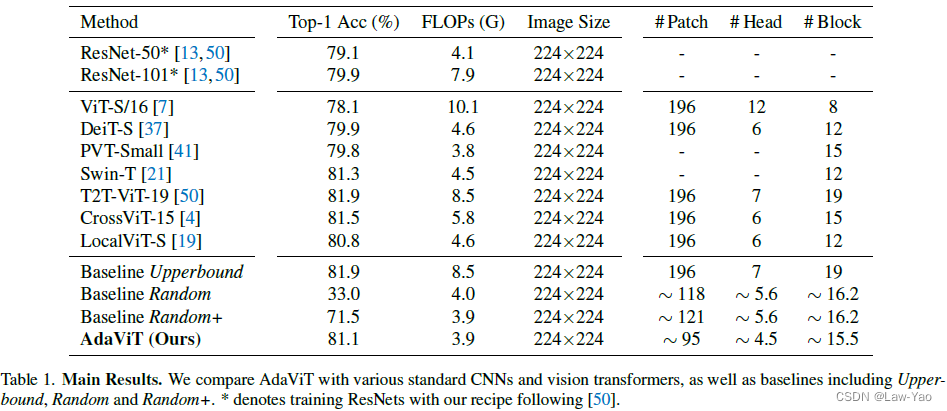
实验结果
实验对比了不同网络结构与AdaViT的计算效率/识别精度,等等;具体参考论文实验部分。


有关Transformer模型压缩与优化加速的更多讨论,参考如下文章:
边栏推荐
- HDR image reconstruction from a single exposure using deep CNNs阅读札记
- C#实现水晶报表绑定数据并实现打印4-条形码
- GNN, please deepen your network layer~
- (18) LCD1602 experiment
- Installation and use of labelimg
- Inno Setup 打包及签名指南
- Classic sql50 questions
- Management background --2 Classification list
- 网络基础入门理解
- [Digital IC hand tearing code] Verilog burr free clock switching circuit | topic | principle | design | simulation
猜你喜欢
CCNA-思科网络 EIGRP协议
Build op-tee development environment based on qemuv8
Assembly and interface technology experiment 5-8259 interrupt experiment

二分图判定

C#实现水晶报表绑定数据并实现打印4-条形码

【数字IC手撕代码】Verilog无毛刺时钟切换电路|题目|原理|设计|仿真
3DMax指定面贴图

(十八)LCD1602实验

Common sense: what is "preservation" in insurance?

Should novice programmers memorize code?
随机推荐
基於 QEMUv8 搭建 OP-TEE 開發環境
网络基础入门理解
数据处理技巧(7):MATLAB 读取数字字符串混杂的文本文件txt中的数据
volatile关键字
【sdx62】WCN685X将bdwlan.bin和bdwlan.txt相互转化操作方法
PVL EDI project case
Maximum product of three numbers in question 628 of Li Kou
NetXpert XG2帮您解决“布线安装与维护”难题
2500 common Chinese characters + 130 common Chinese and English characters
Daily question 1: force deduction: 225: realize stack with queue
RESNET rs: Google takes the lead in tuning RESNET, and its performance comprehensively surpasses efficientnet series | 2021 arXiv
C # réalise la liaison des données du rapport Crystal et l'impression du Code à barres 4
做接口测试都测什么?有哪些通用测试点?
The SQL response is slow. What are your troubleshooting ideas?
将MySQL的表数据纯净方式导出
[leetcode daily clock in] 1020 Number of enclaves
0 basic learning C language - interrupt
AI 企业多云存储架构实践 | 深势科技分享
Memorabilia of domestic database in June 2022 - ink Sky Wheel
3DMAX assign face map