当前位置:网站首页>Crawler obtains real estate data
Crawler obtains real estate data
2022-07-06 22:19:00 【sunpro518】
Crawl from the data released by the Bureau of Statistics , Take real estate data as an example , There are some problems , But it was finally solved , The execution time is 2022-2-11.
The basic idea is to use Python Of requests Library to grab . Analyze the web 1 Discovery is dynamic loading . Find the Internet content inside , yes jsquery Loaded ( I don't know how the great God found it , I just looked for it one by one , Just look for something slightly reliable by name ).
With Real estate investment Take the case of :
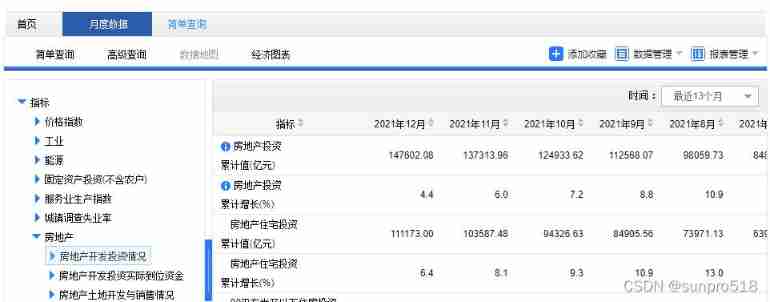
find out js Request for :
https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgyd&rowcode=zb&colcode=sj&wds=%5B%5D&dfwds=%5B%7B%22wdcode%22%3A%22zb%22%2C%22valuecode%22%3A%22A0601%22%7D%5D&k1=1644573450992&h=1
Using the browser, you can see that the request returns a json result . All the data we want are here .
According to this idea, you can basically write crawler code 1 了 !
The above reference blog is written in 2018 year ,2022 There are two problems when testing in :
- Dynamic code is required for the first visit
- The access address is not authenticated , Direct access will report an error 400.
For the first question , use cookie Of requests request 2 Access can solve .
cookie That is Request Headers Medium cookie, Notice what I measured copy value There are certain problems , Direct replication can . I don't know which detail I didn't notice .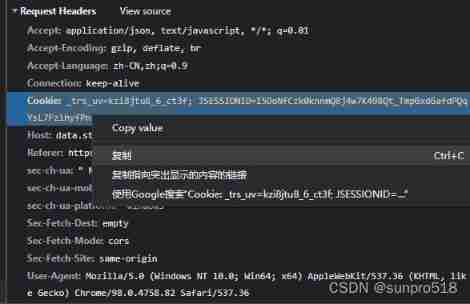
For the second question , Do not use ssl verification 34 The way , You can try to bypass this verification , But it will report InsecureRequestWarning, The solution to this problem is to suppress the warning 5.
Synthesize the above discussion , The implementation code is as follows :
# I use requests library
import requests
import time
# Used to obtain Time stamp
def gettime():
return int(round(time.time() * 1000))
# take query Pass in the parameter dictionary parameter
url = 'https://data.stats.gov.cn/easyquery.htm'
keyvalue = {
}
keyvalue['m'] = 'QueryData'
keyvalue['dbcode'] = 'hgnd'
keyvalue['rowcode'] = 'zb'
keyvalue['colcode'] = 'sj'
keyvalue['wds'] = '[]'
# keyvalue['dfwds'] = '[]'
# The one above is changed to the one below
keyvalue['dfwds'] = '[{"wdcode":"zb","valuecode":"A0301"}]'
keyvalue['k1'] = str(gettime())
# Find... From the web page cookie
cookie = '_trs_uv=kzi8jtu8_6_ct3f; JSESSIONID=I5DoNfCzk0knnmQ8j4w7K498Qt_TmpGxdGafdPQqYsL7FzlhyfPn!1909598655; u=6'
# Suppress the alarm caused by non verification
import urllib3
urllib3.disable_warnings()
headers = {
'Cookie':cookie,
'Host':'data.stats.gov.cn',
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac 05 X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
# Among them headers Contained in the cookie,param Is the request parameter dictionary ,varify That is, bypass authentication
r = requests.get(url,headers = headers,params=keyvalue,verify=False)
# Print status code
print(r.status_code)
# print(r.text)
# Print the results
print(r.text)
Some screenshots of the results are as follows :
The result has not been parsed , But this is used json Just decode it !
Python Crawl the relevant data of the National Bureau of Statistics ( original )︎︎
In reptile requests Advanced usage ( close cookie Make data requests )︎
Python The web crawler reports an error “SSL: CERTIFICATE_VERIFY_FAILED” Solutions for ︎
certificate verify failed:self signed certificate in certificate chain(_ssl.c:1076)︎
InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. terms of settlement ︎
边栏推荐
- GPS从入门到放弃(十五)、DCB差分码偏差
- CCNA Cisco network EIGRP protocol
- Solve project cross domain problems
- VIP case introduction and in-depth analysis of brokerage XX system node exceptions
- Seata聚合 AT、TCC、SAGA 、 XA事务模式打造一站式的分布式事务解决方案
- UNI-Admin基础框架怎么关闭创建超级管理员入口?
- Mysql相关术语
- Mongodb (III) - CRUD
- GPS from getting started to giving up (XX), antenna offset
- Qt | UDP广播通信、简单使用案例
猜你喜欢
The nearest common ancestor of binary (search) tree ●●
Notes de développement du matériel (10): flux de base du développement du matériel, fabrication d'un module USB à RS232 (9): création de la Bibliothèque d'emballage ch340g / max232 SOP - 16 et Associa
二叉(搜索)树的最近公共祖先 ●●

2020 Bioinformatics | GraphDTA: predicting drug target binding affinity with graph neural networks

GPS from entry to abandonment (XVII), tropospheric delay

Oracle control file and log file management
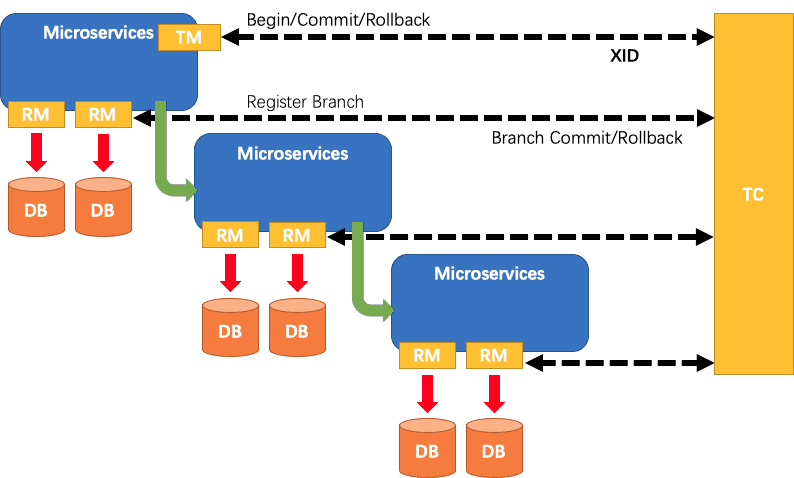
Seata聚合 AT、TCC、SAGA 、 XA事务模式打造一站式的分布式事务解决方案
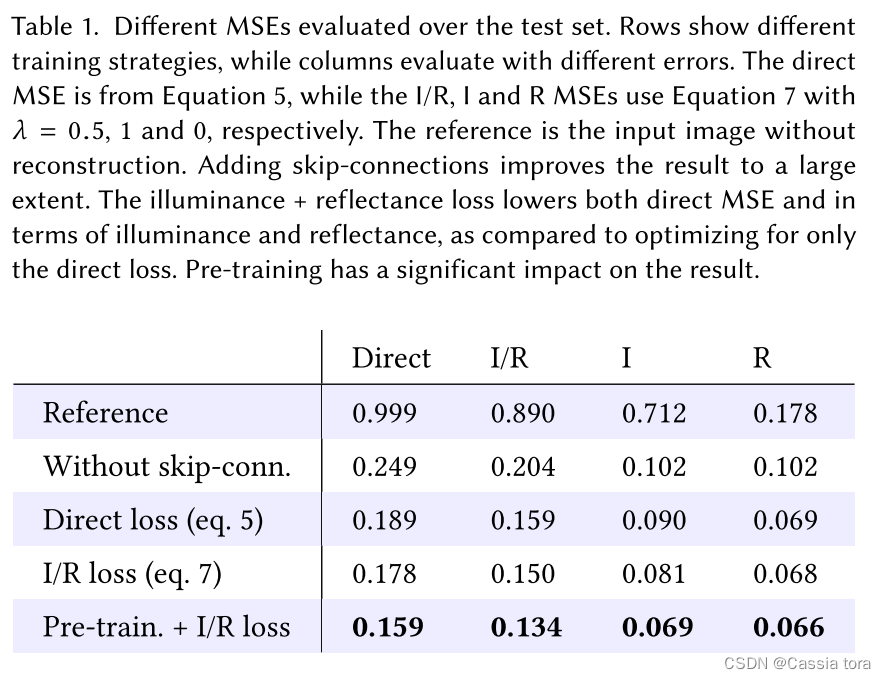
HDR image reconstruction from a single exposure using deep CNN reading notes

2500 common Chinese characters + 130 common Chinese and English characters
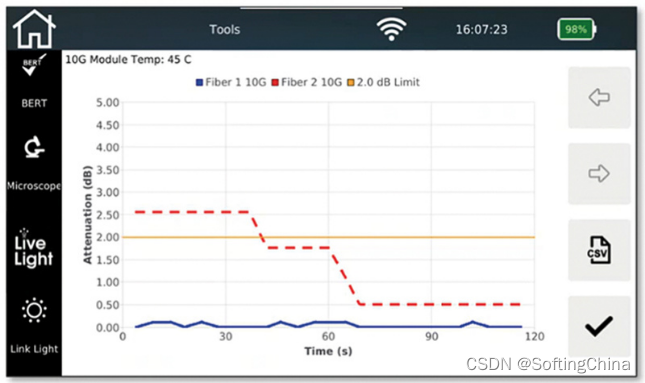
NetXpert XG2帮您解决“布线安装与维护”难题
随机推荐
Management background --2 Classification list
Insert sort and Hill sort
2500个常用中文字符 + 130常用中英文字符
What is the difference between animators and animators- What is the difference between an Animator and an Animation?
GPS从入门到放弃(十五)、DCB差分码偏差
微信红包封面小程序源码-后台独立版-带测评积分功能源码
C#实现水晶报表绑定数据并实现打印4-条形码
[sciter bug] multi line hiding
【数字IC手撕代码】Verilog无毛刺时钟切换电路|题目|原理|设计|仿真
QT | UDP broadcast communication, simple use case
GPS from entry to abandonment (XVII), tropospheric delay
Unity3d Learning Notes 6 - GPU instantiation (1)
2020 Bioinformatics | GraphDTA: predicting drug target binding affinity with graph neural networks
Notes de développement du matériel (10): flux de base du développement du matériel, fabrication d'un module USB à RS232 (9): création de la Bibliothèque d'emballage ch340g / max232 SOP - 16 et Associa
HDR image reconstruction from a single exposure using deep CNN reading notes
Intelligent online customer service system source code Gofly development log - 2 Develop command line applications
[sciter]: encapsulate the notification bar component based on sciter
第3章:类的加载过程(类的生命周期)详解
Some problems about the use of char[] array assignment through scanf..
[10:00 public class]: basis and practice of video quality evaluation