当前位置:网站首页>DR-Net: dual-rotation network with feature map enhancement for medical image segmentation
DR-Net: dual-rotation network with feature map enhancement for medical image segmentation
2022-07-06 15:32:00 【Never_Jiao】
DR-Net: dual-rotation network with feature map enhancement for medical image segmentation
发表期刊: Complex&Intelligent System(大类:计算机科学2区
发表时间: 2022年
Abstract
为了用小样本获得更多的语义信息用于医学图像分割,本文提出了一种简单高效的双旋转网络(DR-Net),可增强局部和全局特征图的质量。 DR-Net算法的关键步骤如下(如图1所示)。首先,将每层的通道数分成四等份。然后,使用不同的旋转策略来获得每个子图像在多个方向上的旋转特征图。然后,使用多尺度体积积和空洞卷积来学习特征图的局部和全局特征。最后,使用残差策略和集成策略来融合生成的特征图。实验结果表明,与最先进的方法相比,DR-Net 方法可以在 CHAOS 和 BraTS 数据集上获得更高的分割精度。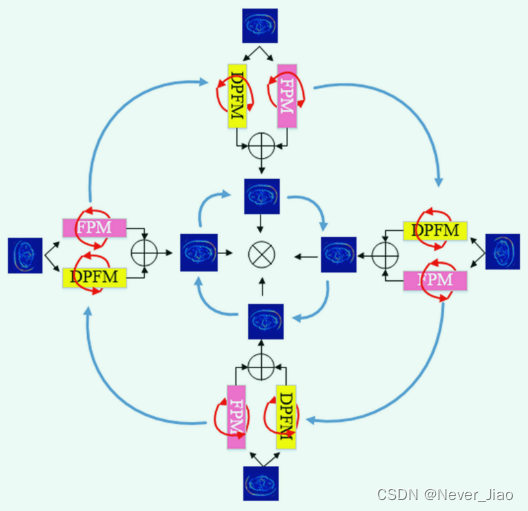
Fig.1 DR-Net的外旋转和内旋转。红线代表内旋,蓝线代表外旋。蓝色方块表示使用相同的特征图,其中数字表示旋转方向。绿色方块表示旋转特征图,使用FPM和DPFM得到局部语义特征和全局语义特征(负号表示反向旋转)
Keywords: Dual-rotation convolution, Feature fusion, Medical segmentation, Deep learning
Introduction
计算机视觉广泛应用于医学任务:医学图像语义分割 [1-3]、医学图像分类 [4-6]、生物工程识别 [7-9]、三维重建 [10-12] 等。虽然深度学习由于医学图像结构复杂、病理组织与周围正常组织相似、数据样本量少等原因,在医学领域取得了巨大成功,但难以获得更深层次的语义信息。为了进一步增强模型学习医学图像特征的能力,研究人员构建了各种模型策略来挖掘深度特征并获取深度语义信息。倪等人 [3] 提出了一个全局上下文注意模块来获取医学图像的上下文语义信息,并整合 SEPP 模型生成的多尺度感受野信息,从而为分割任务提供更多的学习信息。该模型在三个公共数据集和一个本地数据集上取得了良好的分割效果;为了更好地了解医学图像中病变的强度、位置、形状和大小的细微差异,Chen 等人[13] 构建了一种新的卷积神经网络结构,名为 DRINet。该网络集成了由密集网络块[14]、残差网络块和初始网络块[15]生成的多个特征图,并获取各种语义信息。最后,结果表明 DRINet 在三个具有挑战性的应用中优于 UNet;阿洛姆等人[16] 将 U-Net [17] 改进为递归 U-Net 和残差 U-Net 的联合模型。该模型通过残差块实现深特征和浅特征的特征融合,通过loop模块实现残差卷积层语义信息的积累。该算法在三个数据集上获得了最好的分割结果:视网膜图像、皮肤癌分割和肺病灶分割;顾等人[18] 提出了一种上下文编码器网络(CE-Net)。该网络使用 ResNet [19] 来实现特征提取,并使用密集卷积块和多层池化块 [20] 来获得更丰富的图像上下文语义信息。 5个数据集的结果证明了模型的可行性(图1)。
上述研究结果表明,不同的模型策略可以获得不同的语义信息来生成不同的特征图(例如,浅层特征图、深层特征图、局部特征图和全局特征图)。上述策略只能生成一两个特征图,不够全面,无法获得医学图像的语义信息。虽然通过多种策略融合后生成的特征图可以获得更多的语义信息,但参数的总数也会增加,大大提高了算法的计算复杂度。此外,每个策略的特征图的融合只建立在每个策略的深层特征图之间,使得从浅到深的特征挖掘过程中无法获取其他语义信息;并且生成的特征图不够丰富。
组卷积的出现让研究人员在不增加网络参数的情况下,可以获得更丰富的语义信息。 Xie等人 [21]提出的ResNeXt算法,将高维特征图转换为多个低维特征图,然后通过学习低维特征图获得深度特征。将高维特征图转换为低维特征图的好处是可以减少参数计算的次数。他们的算法在 ImageNet-1 k 数据集上取得了很好的效果,从而证明了组卷积具有很好的特征学习能力。罗梅罗等人[22]引入了基于组卷积的注意力策略,构建的注意力组卷积可以增强特征图。上述研究发现,组卷积可以提高网络的特征学习能力。在之前的工作中,研究人员通过对图像进行预处理来增加训练样本的数量[23, 24],从而提高了对数据集的测试精度。
为了在不增加算法复杂度和减少数据预处理的情况下获得更丰富的语义信息,本文提出了一种忠实的深度学习算法:双旋转网络(DR-Net)。
本文的主要贡献如下:
1、我们根据通道总数将前一层生成的特征图分成四个相等的通道部分。然后根据不同的旋转角度(旋转角度分别为0°、90°、180°、270°)对各个部分进行旋转,实现传统卷积的内旋。然后,通过不同大小的卷积核从旋转后的特征图中获得不同的局部语义信息,从而生成更深的局部特征图。在这里,我们将这些特征图称为部分特征图(PFM)。
2、我们还根据通道总数将前一层生成的特征图分成四个通道数相等的部分。随后,我们还在四个方向上旋转了每个部分。与前一种方法不同的特征挖掘方法是我们使用空洞卷积通过设置不同的扩展值来获得不同的感受域,从而获得更多的全局语义信息。我们所有扩张卷积的卷积核大小都设置为 3。在这里,我们将这些特征图称为扩张部分特征图 (DPFM)。
3、为了进一步获得更丰富的语义信息,我们融合了 PFM 和 DPFM 在同一旋转方向上的特征(通过特征图添加策略),最终在 DR-Net 算法的每一层获得了 16 组更丰富的特征图(这些特征地图构成外旋转)。
4、为了获得浅层特征图和深层特征图的融合特征图,同时获得更多的语义信息,得到前一个子模块的浅层特征图。我们利用最大池化的传递不变性来压缩特征图。最后,利用旋转角度、多尺度卷积和不同膨胀步长三种策略生成描述浅层特征语义信息、深层特征语义信息、局部特征语义信息和全局特征语义信息的特征图。
本文其余部分的主要内容总结如下。第二节主要介绍本文算法的背景和意义。第三节详细介绍了DR-Net算法的整体流程以及各个模块的功能。在第四部分,我们通过相关实验验证了 DR-Net 算法的性能。在第五部分,我们给出了本文的总结和进一步的研究目标。
Related work
特征图由它们的宽度、高度和通道数定义。近年来,研究人员以通道数为基准来增强特征图之间的关系。例如,谢等人 [21]等人使用组卷积,Chollet [25] 使用可分离卷积,You et al. [26] 提出使用部分特征图。虽然这些方法的名称不同,但都是基于对通道数的寻址,以提高特征图的质量或减少参数计算的次数。接下来,我们将详细分析上述三组策略的优缺点。
Group convolution (GC)
组卷积的原理是使用一个 1×1 的卷积核从原始特征图(256 个通道)中压缩特征个数,生成 32 组 4 个通道的新特征图。通道压缩策略也在之前的工作中得到了验证[27-30]。该方法的目的是减少深度特征图的冗余信息,减少参数计算的次数。随后,通过卷积核为3的卷积来挖掘之前的32组特征图,降低了特征的计算复杂度。然后,压缩后的特征图通过卷积核为1的卷积恢复(4通道的特征图恢复为原始通道数为256的特征图)。最后,通过聚合残差交换策略融合特征图。随后由 Gao 等人提出的 Res2NeXt 网络[31]也证明了组卷积的效率。
Deep separable convolution (DSC)
深度可分离卷积的原理是将原始特征图划分为N个子通道,通过N个卷积核实现特征挖掘,生成中间特征图。通过拼接中间特征图,恢复具有原始特征通道数的特征图数量。随后,拼接的中间特征图通过1×1卷积压缩特征图,同时构建N个1×1卷积恢复特征图。
Multidirectional integrated convolution (MDIC)(多向集成卷积)
该算法的核心思想是将原始特征图分成四组子特征图,将每个子特征图向不同方向翻转,经过多尺度特征翻转后提取特征图。该算法通过上述策略获得多种语义信息来增强特征图。结果,即使使用少量的拟合器,也可以获得更高精度的分割结果。最终,520万的参数总数远小于其他模型。
Our strategy
我们提出的模型通过 PFM 获得各种局部语义信息,同时通过 DPFM 获得各种全局语义信息。获取的语义信息比上述算法更丰富。对于深度特征图和浅层特征图,本文引入了一种新的残差策略。该策略压缩和扩展特征图。上层特征图的语义信息在编码器中融合。解码器不仅获得相应编码器的特征图,还获得上层解码器的特征图。整个子模块获得更丰富的语义信息。
基于前人的研究,DRNet算法的主要目的是在减少参数计算次数的同时增强特征。接下来,我们使用表 1 直接比较每个组卷积模块的参数个数和得到的特征图类型。 “Shallow”表示浅层特征图,“Deep”表示深度特征图,“Local”表示局部特征图,“Global”表示全局特征图,“C”表示传统卷积。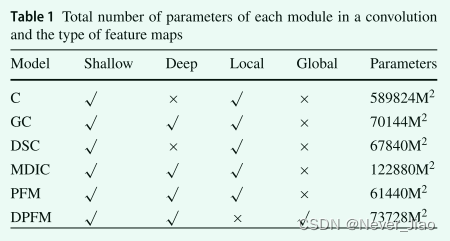
所有块都在卷积上实现。 “M”表示特征图的大小。卷积核的大小统一设置为 3,输入和输出 fitter 的大小设置为 256。从表 1 可以看出,我们提出的 PFM 模块的参数总数是最低的。 DPFM 模块的参数数量与 GC 模块和 DSC 模块相似。由于PFM和DPFM的相加策略,这部分所有参数的计算次数最少。
Methodology
在本节中,我们将通过四个小节详细介绍我们提出的 DR-Net 算法。下一节介绍整个模型的框架,下一节介绍PFM和DPFM的细节,下一节介绍encoder和decoder中使用的不同策略,下一节介绍DR-Net的环境细节算法(图 2)。
DR-Net
图 1 显示了我们提出的 DRNet 算法的整体结构。 DR-Net 算法由从第二层编码器子模块开始到倒数第二层解码器子模块结束的两个内旋转卷积(传统卷积和空洞卷积)组成。让
通过多方向多尺度特征挖掘生成32组(32怎么来的,4个方向,每个方向4组,n从1到4,PFM有16组,DPFM有16组,一共32组)新的特征图,并利用这32组新的特征图形成16组(同方向同尺度的PFM和DPFM为一组)包含全局语义信息和局部语言信息的深度特征图。这里,n代表不同的部分(n代表不同的部分是什么意思),d代表旋转角度,k代表卷积核的大小,D代表膨胀值。其目的是减少特征图的数量,同时实现对特征图的强化。在编码器部分,为了进一步提高特征图Y(x)的质量,当前子模块层H(x)生成的特征图和前一层子模块生成的多旋转方向特征图Md(x)是由残差操作融合的特征。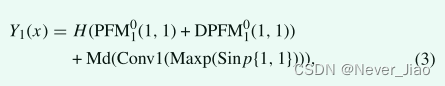
其中Conv1表示卷积核的大小等于1,Maxp表示最大池化,Sinp{1,1}表示上一层特征图的第一组特征的输入和方向。
在解码器中,当前层的子模块生成的特征图F(x)不仅获得了编码器对应的特征图Y(x)的先验信息,还融合了前一层子模块生成的特征图。通过编码器和解码器的上述两种特征融合策略,每一层的特征图包含更多的医学图像语义信息,最终通过softmax函数完成多分类任务。
PFMs and DPFMs
Partial feature maps(PFMs)
在这个内部旋转中,我们根据通道总数划分了四组 PFM,并在不同方向上旋转了每组 PFM。即使使用相同的卷积核,也可以获得不同方向的特征图语义信息[26]。为了进一步获取更多的语义信息,在这一部分中,我们引入了 PFMs 中的多尺度卷积,最终生成了 16 组具有不同语义信息的特征图。通过上述多方向多尺度卷积,得到大量丰富的局部特征图。虽然我们将通道总数划分为多组 PFM 以减少参数计算次数,但为了进一步减少参数计算次数,我们对特征图进行了特征图压缩。局部特征的具体计算总数特征图参数如下: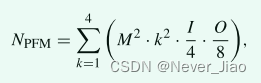
其中NPFM表示参数的总数,M表示特征图的尺度,k表示卷积核的大小,I表示输入特征图的总通道数,O表示输出特征图的总通道数(输入特征图的总通道数除以4,是因为划分了4组,那输出特征图的总通道数除以8,是为什么?)。
Dilated partial feature maps (DPFMs)
DPFM 模块在结构上与 PFM 模块相似。不同的是我们用空洞卷积代替了传统的卷积。目的是通过不同的扩展系数获得不同的感受野,最终获得更多的全局语义信息。我们在编码器的最后两组子模块和解码器的前两组子模块中使用不同的扩张卷积结构。目的是随着特征图规模的减小,通过双层空洞卷积得到更有价值的特征图。两组不同空洞卷积模块的结构如图3所示。具有全局特征图参数的计算总数如下: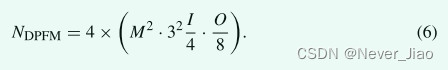
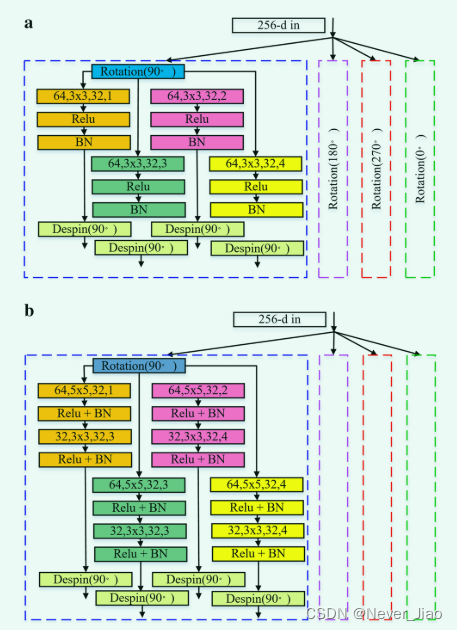
Fig.3 DPFM不同子模块的网络结构。 a DPFM 前两层的结构, b DPFM 后两层的结构。虚线代表DPFM模块中的不同方向,但网络结构是一样的。 (卷积中的每个维度代表如下:输入特征图的数量、卷积核的大小、输出特征图的数量、扩张的尺度)
Encoder and decoder
DR-Net的编码器和解码器由5个子模块组成。为了进一步充分获取不同语义信息的特征图,我们将编码器中的第二个子模块与第五个子模块以及解码器中的第一个子模块与第四个子模块结合起来,组成了 PFM 和 DPFM 策略。与 U-Net 模式 [17, 32, 33] 不同,在编码器部分,仅挖掘当前层的特征。此外,解码器部分仅包含相应编码器的先验特征图。此外,与MC-Net[20]等网络模型不同的是,编码器的语义信息是通过构建多个尺度来增加的,通过融合不同尺度的语义信息来获得更多的信息。我们提出的 DR-Net 不仅使用多方向和多尺度策略来获得更多的特征图。在编码器部分,该方法还整合了PFM模块生成的局部特征图和DPFM模块生成的全局特征图,扩展了每个特征点的体验。输入的特征图利用最大池化层的特征不变性,将更多上层子模块的语义信息引入当前层。在解码器部分,在当前的上一层,我们不仅引入了对应层编码器输出的特征图,还参考了解码器上层输入的特征图,从而可以获得更多的语义信息。编码器和解码器的不同结构模型如图4所示。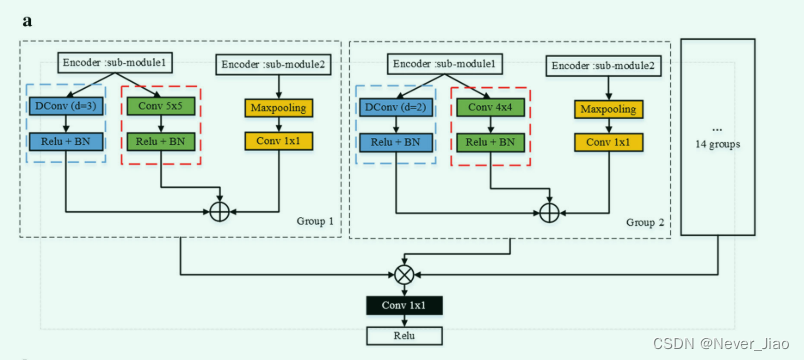
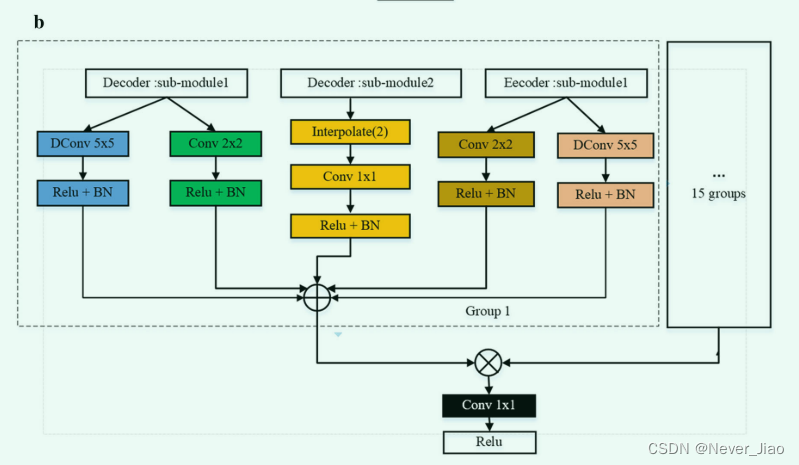
Fig.4 DR-Net 编码器和解码器的模型图。 a 编码器第二至第五子模块的模型结构,和 b 解码器第一至第四子模块的模型结构。这里,“submodule 1”表示当前层子模块的结构图,“submodule 2”表示上层子模块的结构图,⊕表示多类特征图的残差操作,⊗表示融合16组残差特征图,“interpolate”表示使用线性策略将特征图大小放大2倍,d表示空洞卷积的扩展系数
如图 3 所示,我们将前一层生成的特征图分成 4 组,通道数相等。图4a中,蓝色虚线的网络结构实现了不同尺度的PFM,红色虚线的网络结构实现了不同尺度的DPFM,其他14个网络结构与第一组和第二组相同。因此,我们通过不同方向、不同尺度的卷积核,从上一层特征图得到了16组新的特征图。上面的图 4a 显示,在编码器部分,我们计算了当前层卷积和扩张卷积生成的特征图与前一层生成的特征图之间的残差。图 4b 显示编码器和解码器最大的区别在于我们引入了编码器的先验信息。通过上述特征融合,DR-Net模型的各个子模块可以获得更丰富的特征图。
Implementation details
我们所有的实验都是在 3 组 Tesla V100 (16 GB) GPU 上进行的。这两个数据集仅调整了医学图像的大小,并将其长宽比例分别保留为256和256。此外,没有对图像进行预处理。我们选择的优化函数是Adam,学习率是0.001,beta的范围是0.9-0.999,损失函数是交叉熵损失,整个训练过程中所有的比较模型都迭代了300次。我们每组实验运行 5 次,选出综合评价最高的一组结果。
Experiments
Data sets
在本文中,我们在两个多分类数据集 CHAOS 和 BraTS 上验证了所提出的模型 DR-Net。CHAOS 数据集 [34]:该数据集由 4 个前景类(肝脏、左肾、右肾和脾脏)和一个背景类组成。其所有医学图像的尺寸为256×256。我们选择了 647 张带有真实标签的 MRI 图像进行验证。训练集样本数与测试集样本数之比为3:2。该数据集的评价标准来自You等人的文章。 [26]。
BraTS 数据集 [35, 36]:该数据集由 3 个前景类(水肿、非增强实心和增强核心)和一个背景类组成。它所有的医学图像的比例都是240×240,所以我们给每一个医学图像加零。我们在 285 组病例中选择了每个病例中病变面积最大的两张样本图像。此外,我们还将样本以 3:2 的比例分为训练集和验证集。该数据集的评价标准来自 Bakas 等人[35] 的文章。WT 包括所有三种肿瘤结构,ET 包括除“水肿”以外的所有肿瘤结构,TC 仅包含高级病例独有的“增强核心”结构。
Comparison with the state-of-the-art models
在本节中,我们比较了经典的医学分割模型 U-Net,并比较了一些最近在医学图像分割领域取得良好效果的算法,例如 CE-Net [18]、DenseASPP [37] 和 MS-Dual [38]。本文提出的 DR-Net 模型的性能通过将其结果与其他模型的结果进行比较来验证(表 2、表 3)。
每个模型在 CHAOS 数据集上的实验结果表明,虽然 Liver for CE-Net 的结果比我们的方法好 1%,但在 Kidney L 类中,我们的方法比第二高的方法CE-Net好 1.38% 个点。在Kidney R 类别中,我们的方法比第二高的方法 MSDual 好 2.12%。在脾脏类中,我们的方法比第二高的 CE-Net 好 1.86%。此外,在其他三个综合指标上,我们的方法获得了更高的准确率,证明了我们方法的可行性。
为了进一步评估我们提出的方法的泛化能力,我们在 BraTS 数据集上进一步验证了每个模型。我们的方法在所有 WT 值上都优于其他模型,表明我们的模型在多分类中具有更好的泛化能力。 Dice+ 的三个值的结果清楚地表明,DR-Net 算法远远优于其他算法。每次测试中的 TC 值清楚地表明,我们提出的模型在每次测试中都比第二名的算法好 4.28%、5.38% 和 0.1%,这进一步证明了 DR-Net 更擅长学习高级案例。在上述两个数据集上的实验结果清楚地表明了本文提出的方法是有效的。我们在图 5 中可视化了每个模型的分割结果。
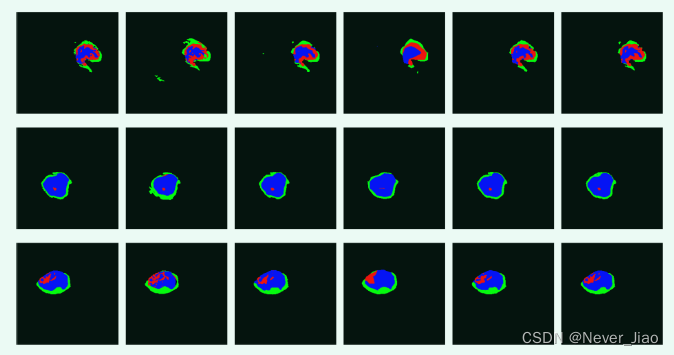
Fig.5 每个模型在 CHAOS 数据集(第 1-4 行)和 BraTS 2018 数据集(第 5-8 行)上的分割结果。a ground truth b U-Net c CE-Net。 d dense-ASPP e MS-Dual f DR-Net
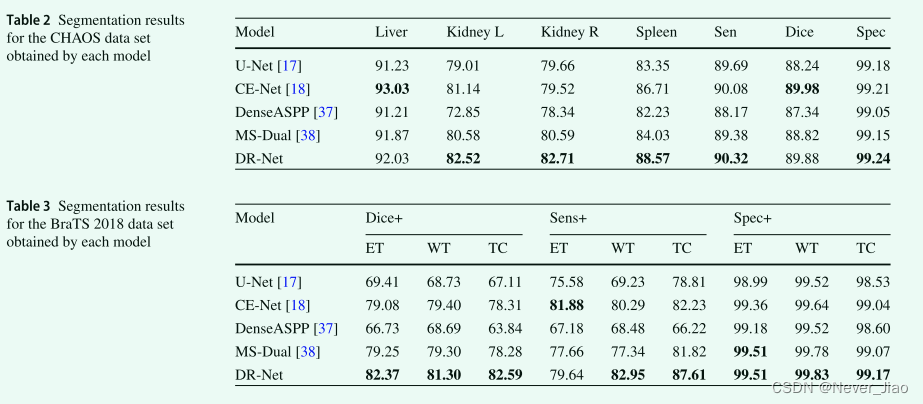
图 5 显示了每个模型在不同数据集上的分割结果。第一组、第四组和第六组的分割结果表明,DR-Net算法对背景类的分割效果更好,从而产生的噪声更少。其他组的分割结果也表明,DR-Net在边缘分割和小形状方面也有很好的预测能力。这进一步证明了我们提出的方法通过加强多个特征图获得了包含更多语义信息的深度特征图。即使在小数据集和特征图数量较少的情况下,这种方法也可以学习到更有意义的深度特征。
Comparison of the total number of parameters in the two data sets
参数的总数直接影响模型的学习效率,特征图的数量直接影响参数的总数。在本文中,我们提出的方法在减少特征图的同时,仍然在两个数据集上的大多数指标上取得了良好的效果。表 4 详细列出了每个模型的参数总数。
表 4 显示,在比较的五组模型中,我们的方法在 CHAOS 数据集上仅使用了 2,700,581 个参数,在 BraTS 数据集上仅使用了 2,704,156 个参数,远低于其他模型。此外,模型在单输入数据(CHAOS 数据集)和多输入数据(BraTS 数据集)上的参数总数没有差异。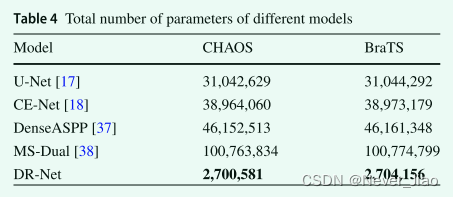
The impact of different strategies on the experiment
为了进一步分析我们方法中提出的每个策略的可行性,我们已经验证了每个策略。这里,“1”只包含PFM模块,“2”只包含DPFM模块,“3”只包含前一层的先验语义信息,“4”只包含对称编码子模块的先验语义信息解码器子模块。为了验证语义信息,“5”中的 PFM 和 DPFM 都没有使用轮换策略。为了在策略“1”和策略“2”中使用特征融合策略,我们将策略“1”更改为两组DPFM模块,将策略“2”更改为两组PFM模块。我们通过图6 中的折线图描述了每个模型的学习过程。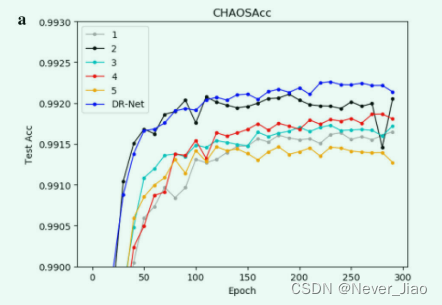
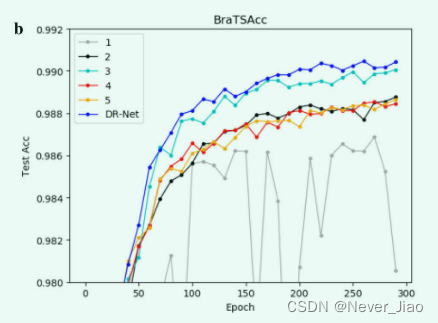
Fig.6 每个策略在不同数据集上的学习过程。a CHAOS数据集。 b BraTS 数据集
图 6 中的实验结果表明,每种策略在学习医学图像的语义信息方面都发挥着积极作用。 PFM 的结构对 CHAOS 数据集的影响较小。原因可能是各器官分布不集中,全局特征影响较大。在 BraTS 数据集中,PFM 影响较大,波动较大。原因可能是数据集的焦点比较集中,局部特征变得尤为重要。我们的方法融合各种特征图后的实验效果最好,证明了我们提出的算法的可行性。
Application of our proposed module in othermodels
为了进一步证明 PFM 和 DPFM 在我们提出的 DR-Net 模型中的可行性,我们将 PFM 模块引入了 U-Net。我们对参数总数和学习结果进行了改进,并将结果与原始 U-Net 的结果进行了比较。结果如下表5所示。 ↑的值越高,模型的性能越好。
我们用PFM模块代替了原来的卷积,除了第一层卷积。在 CHAOS 数据集上的实验结果表明,我改进后的 UNet 的 mAverage 比传统的 U-Net mAverage 高 3.38%,而在 BraTS 数据集上的实验结果表明,我改进后的 U-Net 的 mAverage 比传统的 U-Net 高 3.58%传统的U-Net。上述算法的结果清楚地说明了我们提出的策略的可行性。参数的总数也大大减少了。

The influence of rotation angle and different convolution strategies on DR-Net algorithm
为了进一步验证旋转策略和不同的卷积策略可以同时使用以获得更多的语义信息,在本节中,我们使用具体的实验结果来分析每种策略在两个数据集上的重要性。 DR-Net(0°)表示特征图完全不旋转,DR-Net(90°)表示特征图旋转90°,DR-Net(180°)表示特征图旋转乘以 180°,DR-Net (270°) 表示特征图旋转了 270°,DR-Net(a) 表示仅使用传统卷积进行特征学习,DR-Net(b) 表示仅使用了膨胀的卷积特征学习量。两个数据集的具体结果如表 6 所示。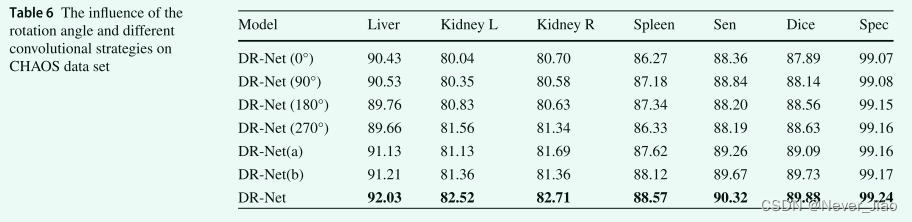
在表 6 中,我们发现旋转策略对 CHAOS 数据集的影响比卷积策略更大。不同的旋转策略获得不同的特征,从而导致每个类的学习点不同。当特征图旋转90°时,Liver获得最高值90.53%;当特征图旋转 180° 时,Spleen 的准确率达到 87.34%;当特征图旋转 270° 时,Kidney L 的准确率达到了 81.56%;并且在没有旋转特征图的情况下,各种结果相对平衡。当使用 DR-Net 的 4 种类型的旋转时,获得了 CHAOS 数据集中各种类型的最佳预测结果。在表 7 中,在多模态 BraTS 数据集上,我们发现旋转策略和卷积策略都发挥了积极作用。如果在DR-Net算法中只使用传统卷积,学习到的特征的结果比只使用空洞卷积时要低,这说明空洞卷积在多模态任务上获得的全局特征更为重要。表 6 和表 7 表明,当 DR-Net 算法同时使用旋转策略和多个卷积策略时,得到了最好的预测结果,进一步证明了 DR-Net 算法的合理性。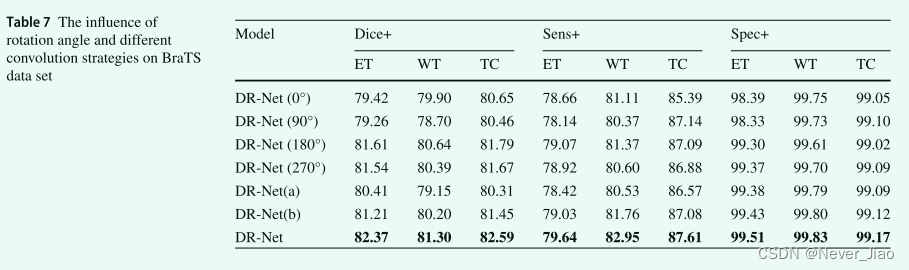
Conclusion
本文提出了一种双旋转网络,充分学习和融合全局特征、局部特征、浅层特征和深层特征,挖掘更多的语义信息。此外,为了在编码器和解码器中进一步整合更多的语义信息,我们通过特征图的旋转、多尺度和不同扩张步长三种策略进一步强化特征图。我们通过后一个子模块融合前一个子模块的原始特征图,为编码器提供更多的语义信息;此外,为了让解码器获得更多的语义信息,我们对特征进行了压缩和扩展。图实现了多种类型特征图的融合。最后,本文提出的方法在两个多类医学图像数据集上取得了良好的分割效果。
边栏推荐
猜你喜欢
剪映+json解析将视频中的声音转换成文本
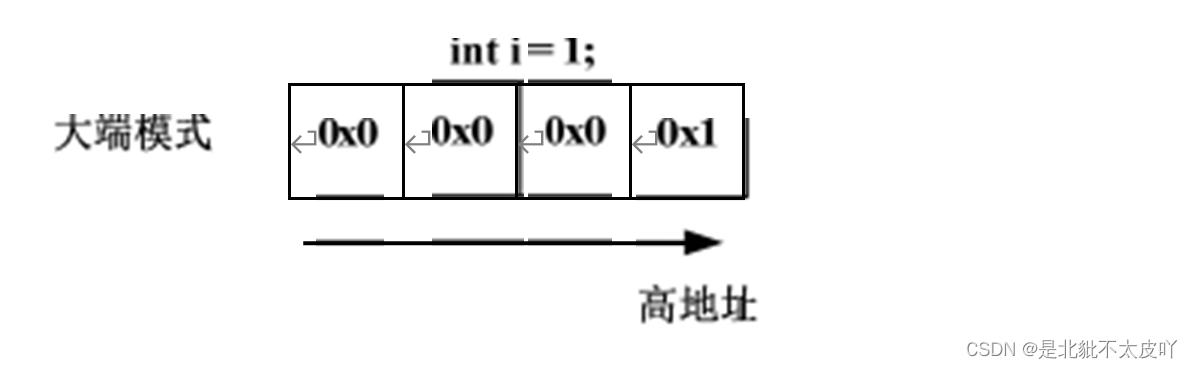
How to confirm the storage mode of the current system by program?
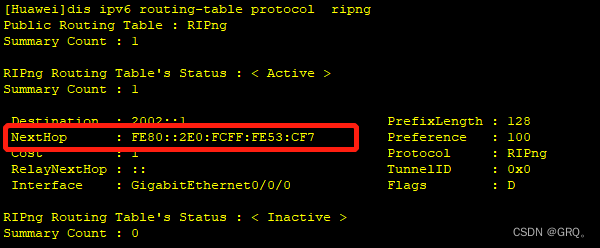
在IPv6中 链路本地地址的优势
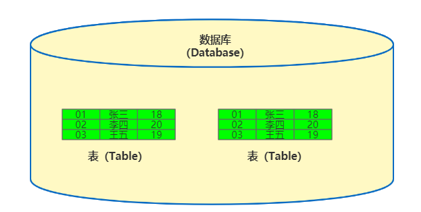
MySQL数据库基本操作-DML
Advantages of link local address in IPv6
![[leetcode] 19. Delete the penultimate node of the linked list](/img/ab/25cb6d6538ad02d78f7d64b2a2df3f.png)
[leetcode] 19. Delete the penultimate node of the linked list
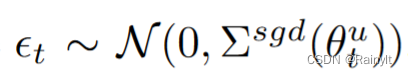
Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR2022 oral)
剑指offer刷题记录1

新手程序员该不该背代码?
视图(view)
随机推荐
Puppeteer连接已有Chrome浏览器
2022-07-05 stonedb sub query processing parsing time analysis
Adavit -- dynamic network with adaptive selection of computing structure
How to confirm the storage mode of the current system by program?
新手程序员该不该背代码?
使用云服务器搭建代理
Dealing with the crash of QT quick project in offscreen mode
BasicVSR_ Plusplus master test videos and pictures
【踩坑合辑】Attempting to deserialize object on CUDA device+buff/cache占用过高+pad_sequence
signed、unsigned关键字
Aardio - integrate variable values into a string of text through variable names
自定义 swap 函数
rust知识思维导图xmind
金融人士必读书籍系列之六:权益投资(基于cfa考试内容大纲和框架)
0 basic learning C language - interrupt
【雅思口语】安娜口语学习记录part1
(18) LCD1602 experiment
Aardio - 封装库时批量处理属性与回调函数的方法
0 basic learning C language - digital tube
Build op-tee development environment based on qemuv8