当前位置:网站首页>剪映+json解析将视频中的声音转换成文本
剪映+json解析将视频中的声音转换成文本
2022-07-06 14:29:00 【fangye945a】
前言
有时候我们想将一段视频中的音频转换成文本,最简单最笨的方法就是通过人耳去听,然后通过打字打出来。但这种方法无疑是十分费劲的。机智的小伙伴肯定都知道我们可以借助语音识别工具来做这件事,但是比较现实的一点就是,很多识别软件不是要收费,就是识别准确率比较低。那么我们有什么办法可以既不花钱又准确的将视频中的音频转换成文本呢?
解决方法
有剪辑经验的小伙伴一定知道,剪映这款软件的字幕识别功能,其背后有字节跳动的语音识别技术支撑,对普通话的识别准确率是杠杠的。但是有一点是,他识别的字幕是分段的,要将它们一条条复制出来组成完整的文本,其工作量也不少。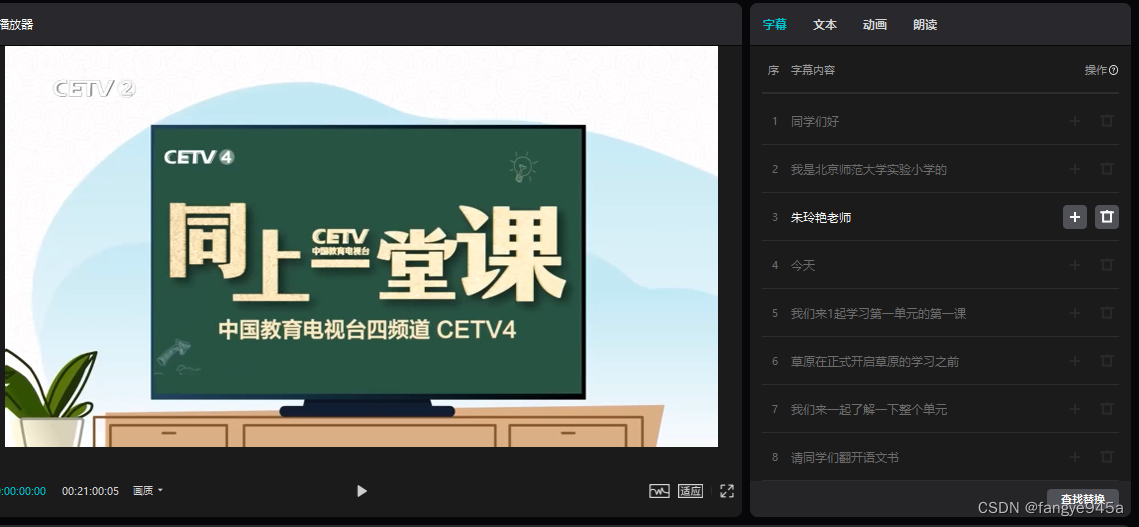
那么,下面介绍一个简单的办法:
具体操作步骤
- 1.下载windows版本的剪映
- 2.导入视频
- 3.识别字幕(导入视频后,点击文本->智能字幕->开始识别即可)
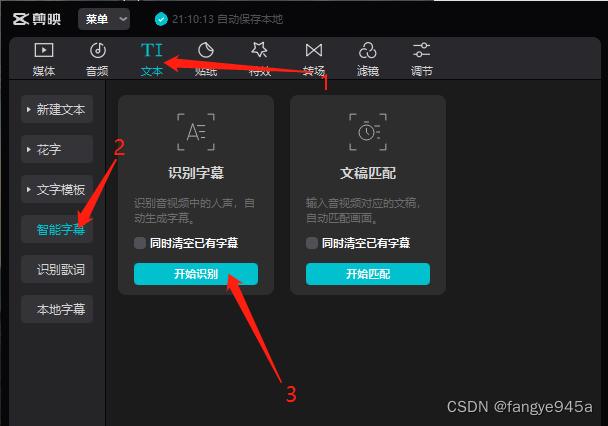
- 4.等待一段时间后(时间长短与视频文件大小有关),就会自动生成字幕了。
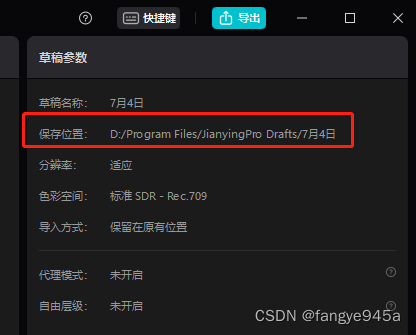
- 5.生成字幕后,关闭剪映,会自动保存为草稿。此时再打开剪映,右上角会出现草稿参数的方框,在方框中我们可以找到草稿保存的路径。
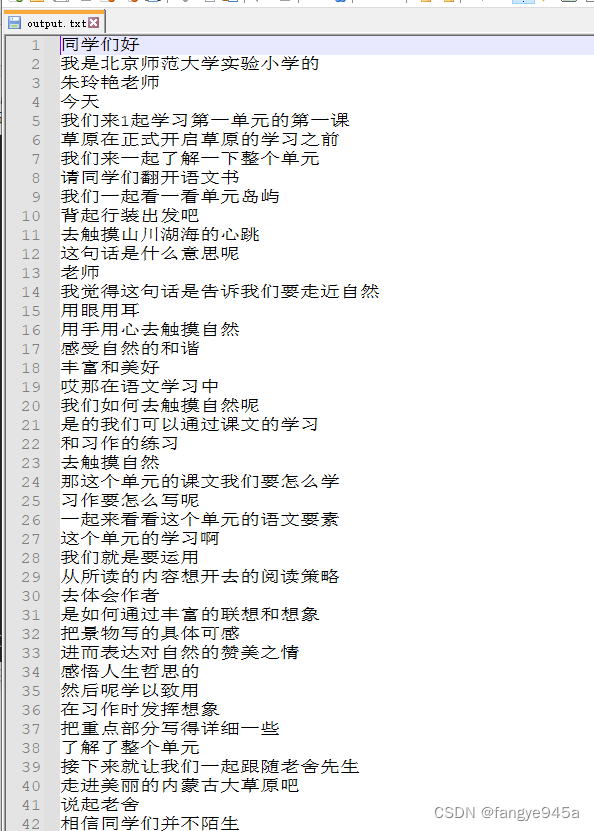
- 6.在windows资源管理器中打开保存位置,可以看到如下文件。
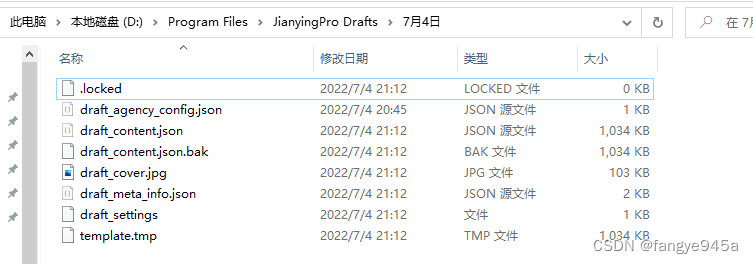
- 7.根据英文名称不难找出,draft_content.json 中就是我们草稿内容,刚刚生成的字幕文本也保存在这个json文件中。
- 8.既然是json文件,下一步自然就是json解析了,我们将字幕内容从这个文件中提取出来即可。
- 9.分析json文件,找出要解析的字段, 简化后的json结构如下:
{"materials":{"texts":[{"content":"<font id=\"\" path=\"D:/Program Files/JianyingPro/3.0.5.8542/Resources/Font/SystemFont/zh-hans.ttf\"><color=(1.000000, 1.000000, 1.000000, 1.000000)><size=5.000000>同学们好</size></color></font>"}]}}
而我们需要的字幕内容,被三个xml元素标签包裹。
- 10.我们先通过json解析获取到content字段的内容,然后通过字符串处理的方法剔除xml标签,获取最终文本字幕内容。
如下是我写的一个简单的python脚本,可以方便快捷的处理剪映这个包含字幕的json文件:
import json
if __name__ == '__main__':
with open("draft_content.json", "r", encoding='utf-8') as f:
json_str = f.read()
json_content = json.loads(json_str)
texts_data = json_content["materials"]["texts"]
for text_data in texts_data:
content = text_data["content"]
content = content[:-22]
result = content.split("><size=")[1].split(">")[1]
print(result)
- 11.直接将脚本与json文件放置在同一目录下,执行python脚本即可得到需要的字幕内容。
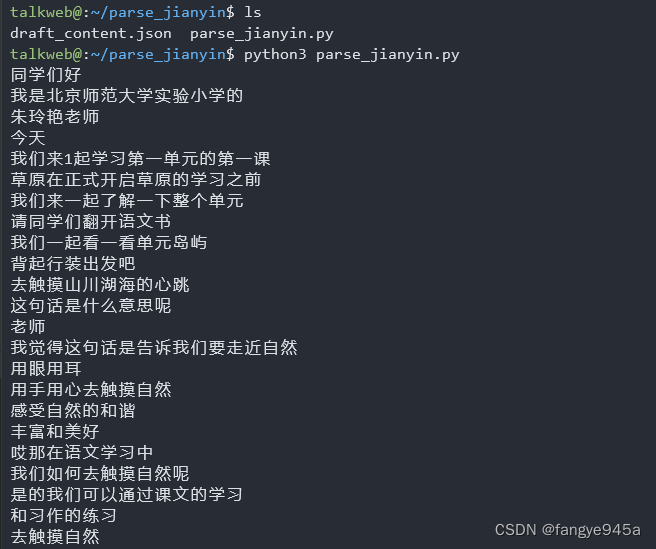
我们还可以通过重定向符号,直接将输出的内容生成文件
python3 parse_jianyin.py >> output.txt
边栏推荐
- 每日一题:力扣:225:用队列实现栈
- Data processing skills (7): MATLAB reads the data in the text file TXT with mixed digital strings
- Oracle-控制文件及日志文件的管理
- Assembly and Interface Technology Experiment 6 - ADDA conversion experiment, AD acquisition system in interrupt mode
- HDR image reconstruction from a single exposure using deep CNN reading notes
- GPS从入门到放弃(十九)、精密星历(sp3格式)
- 插入排序与希尔排序
- C # realizes crystal report binding data and printing 4-bar code
- Attack and defense world miscall
- GNN,请你的网络层数再深一点~
猜你喜欢
网络基础入门理解

2500个常用中文字符 + 130常用中英文字符

GPS从入门到放弃(十七) 、对流层延时
Notes de développement du matériel (10): flux de base du développement du matériel, fabrication d'un module USB à RS232 (9): création de la Bibliothèque d'emballage ch340g / max232 SOP - 16 et Associa
3DMax指定面贴图
RESNET rs: Google takes the lead in tuning RESNET, and its performance comprehensively surpasses efficientnet series | 2021 arXiv

Oracle control file and log file management

C#实现水晶报表绑定数据并实现打印4-条形码
数据处理技巧(7):MATLAB 读取数字字符串混杂的文本文件txt中的数据
Classic sql50 questions
随机推荐
GPS從入門到放弃(十三)、接收機自主完好性監測(RAIM)
MongoDB(三)——CRUD
2021 geometry deep learning master Michael Bronstein long article analysis
Attack and defense world miscall
Kohana database
[leetcode daily clock in] 1020 Number of enclaves
嵌入式常用计算神器EXCEL,欢迎各位推荐技巧,以保持文档持续更新,为其他人提供便利
[sciter]: encapsulate the notification bar component based on sciter
GPS from getting started to giving up (XVIII), multipath effect
GPS du début à l'abandon (XIII), surveillance autonome de l'intégrité du récepteur (raim)
Seata aggregates at, TCC, Saga and XA transaction modes to create a one-stop distributed transaction solution
GNN, please deepen your network layer~
Oracle control file and log file management
GPS从入门到放弃(十二)、 多普勒定速
Qt | UDP广播通信、简单使用案例
3DMAX assign face map
【sciter】: 基于 sciter 封装通知栏组件
Memorabilia of domestic database in June 2022 - ink Sky Wheel
2500个常用中文字符 + 130常用中英文字符
Common sense: what is "preservation" in insurance?