当前位置:网站首页>Use mitmproxy to cache 360 degree panoramic web pages offline
Use mitmproxy to cache 360 degree panoramic web pages offline
2022-07-06 23:11:00 【Xiaoming - code entity】
Blog home page :https://blog.csdn.net/as604049322
Welcome to thumb up Collection Leaving a message. Welcome to discuss !
This paper is written by Xiaoming - Code entities original , First appeared in CSDN
There was a problem yesterday :
Some involve dynamically loaded web pages , It is impossible to save all resources with the browser's own function of saving web pages .
If we save documents one by one by hand , There are too many :
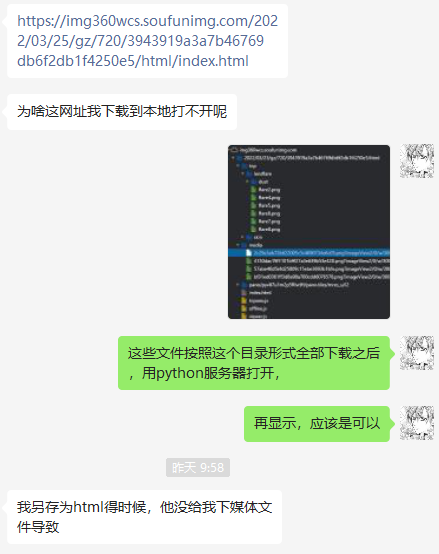
Too many folders , One layer at a time .
At this time, I want to cache the target web page offline , Thought of a good way , That is through support python Programmed agent , Let every request be based on URL Save the corresponding file locally .
MitmProxy Installation
Comparison recommendation MitmProxy, The installation method is executed in the command line :
pip install mitmproxy
MitmProxy It is divided into mitmproxy,mitmdump and mitmweb Three commands , among mitmdump Support the use of specified python The script handles each request ( Use -s Parameter assignment ).
After installation, we need the installation certificate MitmProxy Corresponding certificate , visit :http://mitm.it/
Direct access will show :If you can see this, traffic is not passing through mitmproxy.
Here we're going to do it first mitmweb Start a web proxy server :

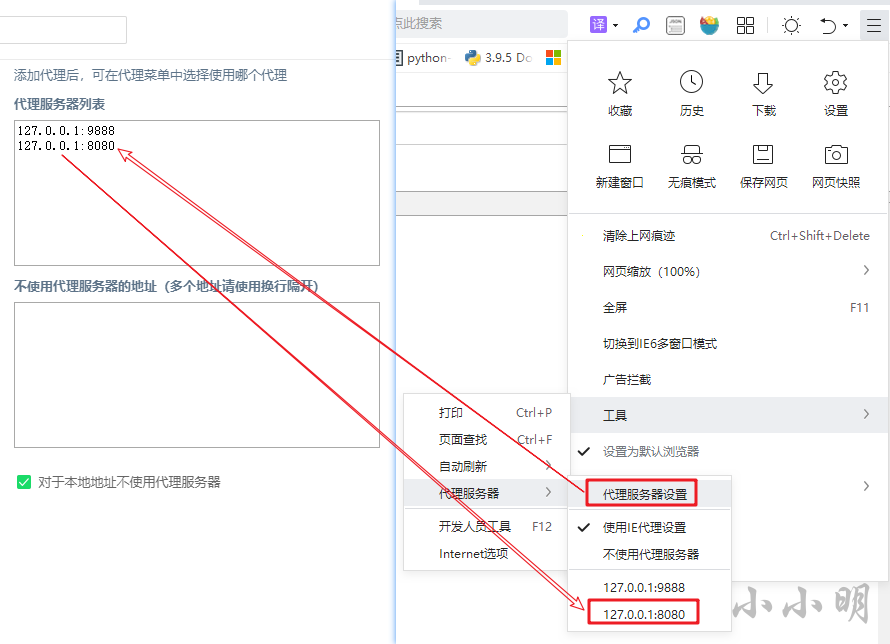
We give the tourist we use , Set the address of the proxy server , With 360 Take the safe tour as an example :
Set up and use MitmProxy Access again after the proxy server provided http://mitm.it/ You can download and install the certificate :

After downloading, open the certificate and click next to complete the installation .
Visit Baidu at this time , You can see MitmProxy Certificate validation information for :

To write mitmdump Required scripts
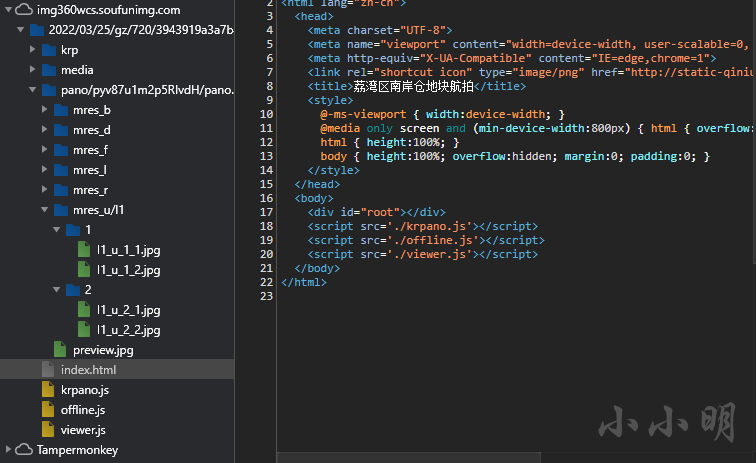
mitmdump The template code of the supported script is as follows :
# All sent request packets will be processed by this method
def request(flow):
# Get request object
request = flow.request
# All server response packets are processed by this method
def response(flow):
# Get the response object
response = flow.response
request and response Object and the requests The objects in the library are almost the same .
Our demand is based on url Save the file , Just process the response , Try caching Baidu homepage first :
import os
import re
dest_url = "https://www.baidu.com/"
def response(flow):
url = flow.request.url
response = flow.response
if response.status_code != 200 or not url.startswith(dest_url):
return
r_pos = url.rfind("?")
url = url if r_pos == -1 else url[:r_pos]
url = url if url[-1] != "/" else url+"index.html"
path = re.sub("[/\\\\:\\*\\?\\<\\>\\|\"\s]", "_", dest_url.strip("htps:/"))
file = path + "/" + url.replace(dest_url, "").strip("/")
r_pos = file.rfind("/")
if r_pos != -1:
path, file_name = file[:r_pos], file[r_pos+1:]
os.makedirs(path, exist_ok=True)
with open(file, "wb") as f:
f.write(response.content)
Save the above script as dump.py Then start the agent with the following command ( Close the previously started mitmweb):
>mitmdump -s dump.py
Loading script dump.py
Proxy server listening at http://*:8080
After refreshing the page, baidu home page has been successfully cached :
Use python Test the built-in server and visit :
You can see that you have successfully visited the local Baidu .
Offline caching 360 Panoramic web page
Put the dest_url Change to the following address and save :
dest_url = "https://img360wcs.soufunimg.com/2022/03/25/gz/720/3943919a3a7b46769db6f2db1f4250e5/html"
Revisit :https://img360wcs.soufunimg.com/2022/03/25/gz/720/3943919a3a7b46769db6f2db1f4250e5/html/index.html
If you find that the saved files are not complete , You can open developer tools , Check the network tab Disable caching after , Refresh the page again :
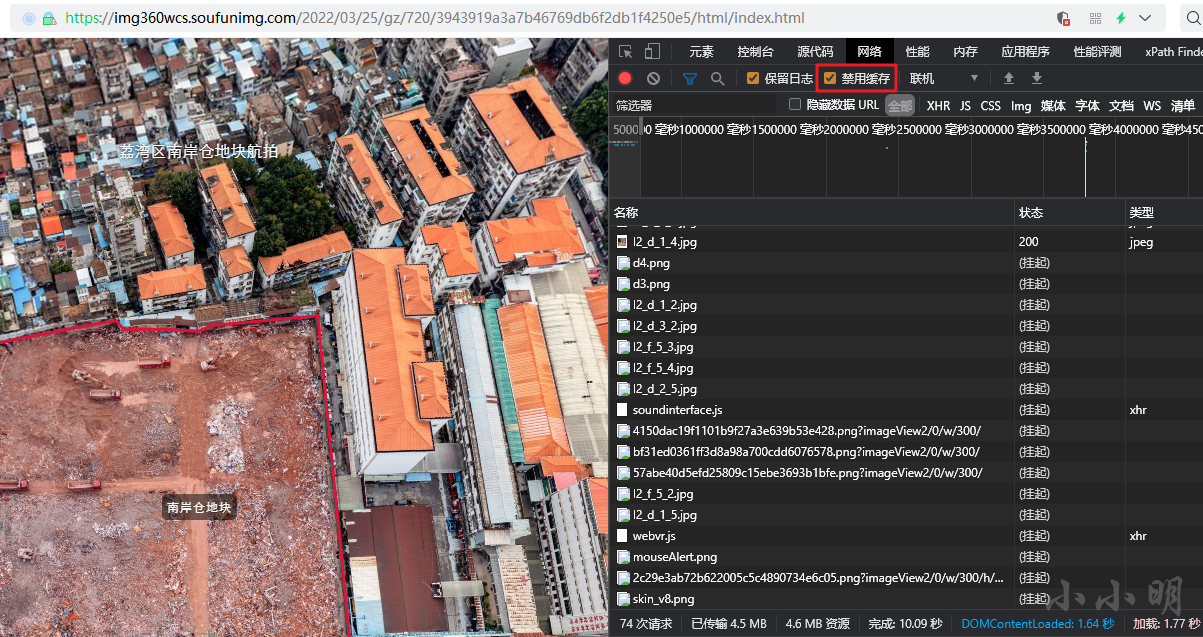
At this time, the main file has been cached :
At this time, just visit all directions on the original web page as much as possible , And zoom in and out to cache as many high-definition detail pictures as possible .
Using the local server to start the test has been successfully accessed :
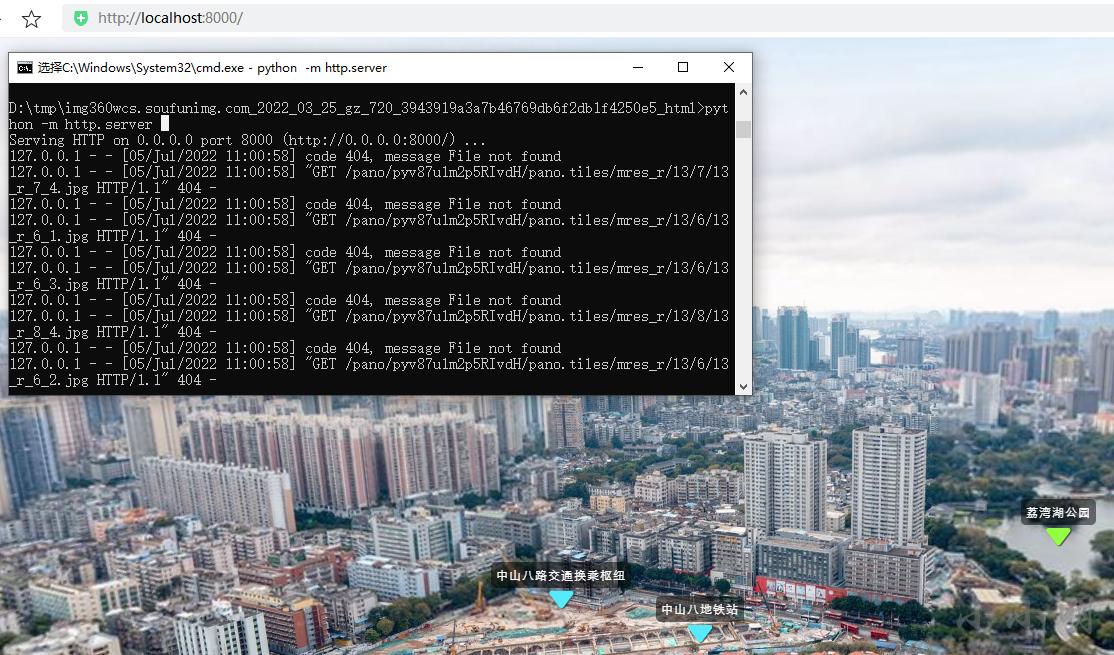
However, the original script only caches the response code as 200 The ordinary documents of , The above website will also return a response code of 206 Music files , If caching is also needed, it is a little more complicated , Now let's study how to cache music files .
cache 206 Split file
After some research , Modify the above code to the following form :
import os
import re
dest_url = "https://img360wcs.soufunimg.com/2022/03/25/gz/720/3943919a3a7b46769db6f2db1f4250e5/html"
def response(flow):
url = flow.request.url
response = flow.response
if response.status_code not in (200, 206) or not url.startswith(dest_url):
return
r_pos = url.rfind("?")
url = url if r_pos == -1 else url[:r_pos]
url = url if url[-1] != "/" else url+"index.html"
path = re.sub("[/\\\\:\\*\\?\\<\\>\\|\"\s]", "_", dest_url.strip("htps:/"))
file = path + "/" + url.replace(dest_url, "").strip("/")
r_pos = file.rfind("/")
if r_pos != -1:
path, file_name = file[:r_pos], file[r_pos+1:]
os.makedirs(path, exist_ok=True)
if response.status_code == 206:
s, e, length = map(int, re.fullmatch(
r"bytes (\d+)-(\d+)/(\d+)", response.headers['Content-Range']).groups())
if not os.path.exists(file):
with open(file, "wb") as f:
pass
with open(file, "rb+") as f:
f.seek(s)
f.write(response.content)
elif response.status_code == 200:
with open(file, "wb") as f:
f.write(response.content)
Save the modified script ,mitmdump It can be reloaded automatically :
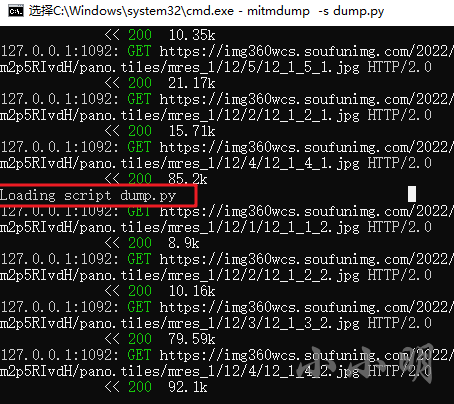
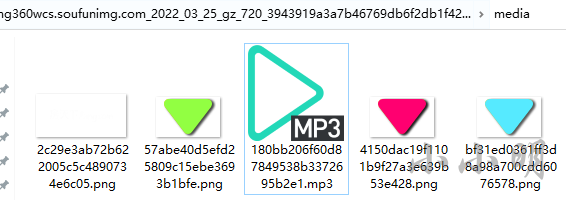
After cleaning up the cache and re accessing , The music files have been downloaded successfully :
summary
adopt mitmdump We have successfully implemented the caching of the designated website , If you want to cache other websites locally in the future, you only need to modify dest_url The website of .
边栏推荐
- Redis 持久化机制
- Redis persistence mechanism
- HDU 5077 NAND (violent tabulation)
- #DAYU200体验官# 首页aito视频&Canvas绘制仪表盘(ets)
- ACL 2022 | small sample ner of sequence annotation: dual tower Bert model integrating tag semantics
- DR-Net: dual-rotation network with feature map enhancement for medical image segmentation
- 「小程序容器技术」,是噱头还是新风口?
- mysql拆分字符串作为查询条件的示例代码
- Why are some people still poor and living at the bottom of society even though they have been working hard?
- 服务器的系统怎么选者
猜你喜欢
Flutter life cycle
dockermysql修改root账号密码并赋予权限

Enterprises do not want to replace the old system that has been used for ten years
docker中mysql开启日志的实现步骤
借助这个宝藏神器,我成为全栈了
Nftscan Developer Platform launches Pro API commercial services
CSDN 上传图片取消自动加水印的方法

On file uploading of network security
asp读取oracle数据库问题

What can be done for traffic safety?

随机推荐
Project duplicate template
mysql连接vscode成功了,但是报这个错
Dayu200 experience officer homepage AITO video & Canvas drawing dashboard (ETS)
European Bioinformatics Institute 2021 highlights report released: nearly 1million proteins have been predicted by alphafold
How to choose the server system
The difference between enumeration and define macro
「小程序容器技术」,是噱头还是新风口?
让 Rust 库更优美的几个建议!你学会了吗?
Enterprises do not want to replace the old system that has been used for ten years
[untitled]
Uniapp setting background image effect demo (sorting)
Aardio - Method of batch processing attributes and callback functions when encapsulating Libraries
基于PaddlePaddle平台(EasyDL)设计的人脸识别课堂考勤系统
C three ways to realize socket data reception
Improving Multimodal Accuracy Through Modality Pre-training and Attention
DockerMySQL无法被宿主机访问的问题解决
【全网首发】Redis系列3:高可用之主从架构的
COSCon'22 社区召集令来啦!Open the World,邀请所有社区一起拥抱开源,打开新世界~
Windows auzre background operation interface of Microsoft's cloud computing products
实现多彩线条摆出心形