当前位置:网站首页>使用MitmProxy离线缓存360度全景网页
使用MitmProxy离线缓存360度全景网页
2022-07-06 15:40:00 【小小明-代码实体】
博客主页:https://blog.csdn.net/as604049322
欢迎点赞 收藏 留言 欢迎讨论!
本文由 小小明-代码实体 原创,首发于 CSDN
昨天遇到一个问题:
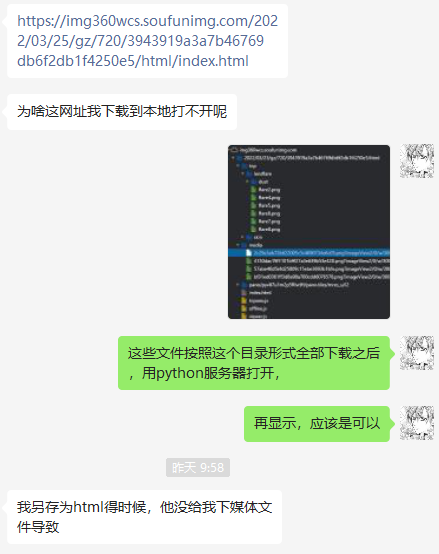
有些涉及动态加载的网页,有游览器自带的保存网页功能是无法保存全部资源的。
假如我们手工挨个文件去保存,未免也太多了:
超多的文件夹,一层一层的。
此时我为了实现离线缓存目标网页,想到了一个好方法,那就是通过支持python编程的代理,让每一个请求都根据URL保存对应的文件到本地。
MitmProxy的安装
比较推荐MitmProxy,安装方法在命令行中执行:
pip install mitmproxy
MitmProxy分为mitmproxy,mitmdump和mitmweb三个命令,其中mitmdump支持使用指定的python脚本处理每个请求(使用-s参数指定)。
安装后我们需要安装证书MitmProxy对应的证书,访问:http://mitm.it/
直接访问会显示:If you can see this, traffic is not passing through mitmproxy.
这里我们先执行mitmweb启动一个网页版的代理服务器:

我们给所使用的游览器,设置代理服务器的地址,以360安全游览器为例:
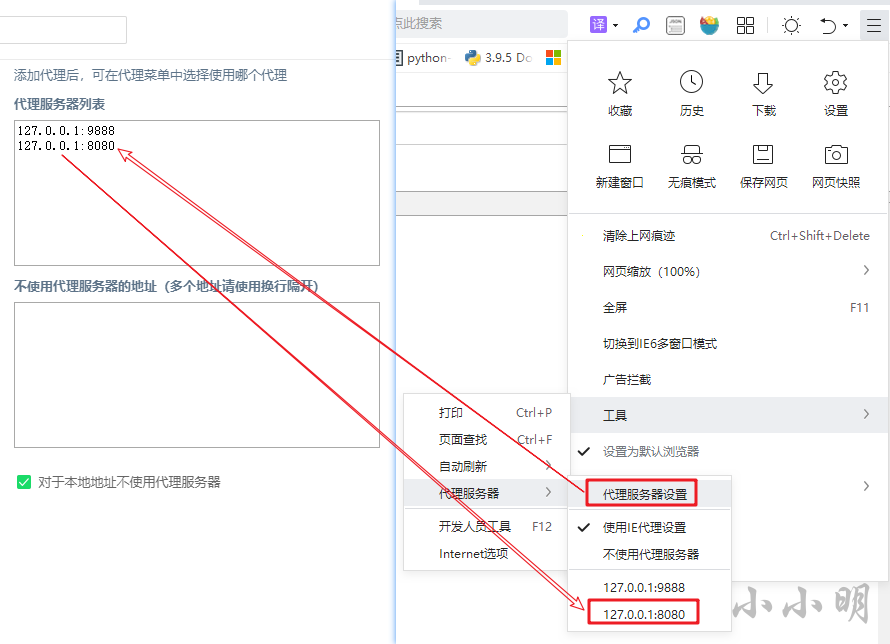
在设置并使用MitmProxy提供的代理服务器之后再次访问http://mitm.it/就可以下载并安装证书了:

下载后打开证书不断点击下一步即可安装完成。
此时访问百度,可以看到MitmProxy的证书验证信息:

编写mitmdump所需的脚本
mitmdump所支持的脚本的模板代码如下:
# 所有发出的请求数据包都会被这个方法所处理
def request(flow):
# 获取请求对象
request = flow.request
# 所有服务器响应的数据包都会被这个方法处理
def response(flow):
# 获取响应对象
response = flow.response
request和response对象与requests库中的对象几乎一致。
我们的需求是根据url保存文件,只需要处理响应即可,先尝试缓存百度首页:
import os
import re
dest_url = "https://www.baidu.com/"
def response(flow):
url = flow.request.url
response = flow.response
if response.status_code != 200 or not url.startswith(dest_url):
return
r_pos = url.rfind("?")
url = url if r_pos == -1 else url[:r_pos]
url = url if url[-1] != "/" else url+"index.html"
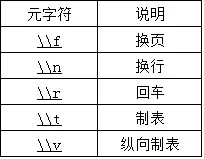
path = re.sub("[/\\\\:\\*\\?\\<\\>\\|\"\s]", "_", dest_url.strip("htps:/"))
file = path + "/" + url.replace(dest_url, "").strip("/")
r_pos = file.rfind("/")
if r_pos != -1:
path, file_name = file[:r_pos], file[r_pos+1:]
os.makedirs(path, exist_ok=True)
with open(file, "wb") as f:
f.write(response.content)
将上述脚本保存为dump.py然后使用如下命令启动代理(先关闭之前启动的mitmweb):
>mitmdump -s dump.py
Loading script dump.py
Proxy server listening at http://*:8080
刷新页面后已经顺利缓存了百度首页:
使用python自带的服务器测试运行并访问一下:
可以看到已经顺利访问了本地的百度。
离线缓存360全景网页
将上述脚本的dest_url修改为如下地址并保存:
dest_url = "https://img360wcs.soufunimg.com/2022/03/25/gz/720/3943919a3a7b46769db6f2db1f4250e5/html"
再次访问:https://img360wcs.soufunimg.com/2022/03/25/gz/720/3943919a3a7b46769db6f2db1f4250e5/html/index.html
如果发现保存的文件不够全,可以打开开发者工具,在网络选项卡勾选 禁用缓存 后,再次刷新网页:
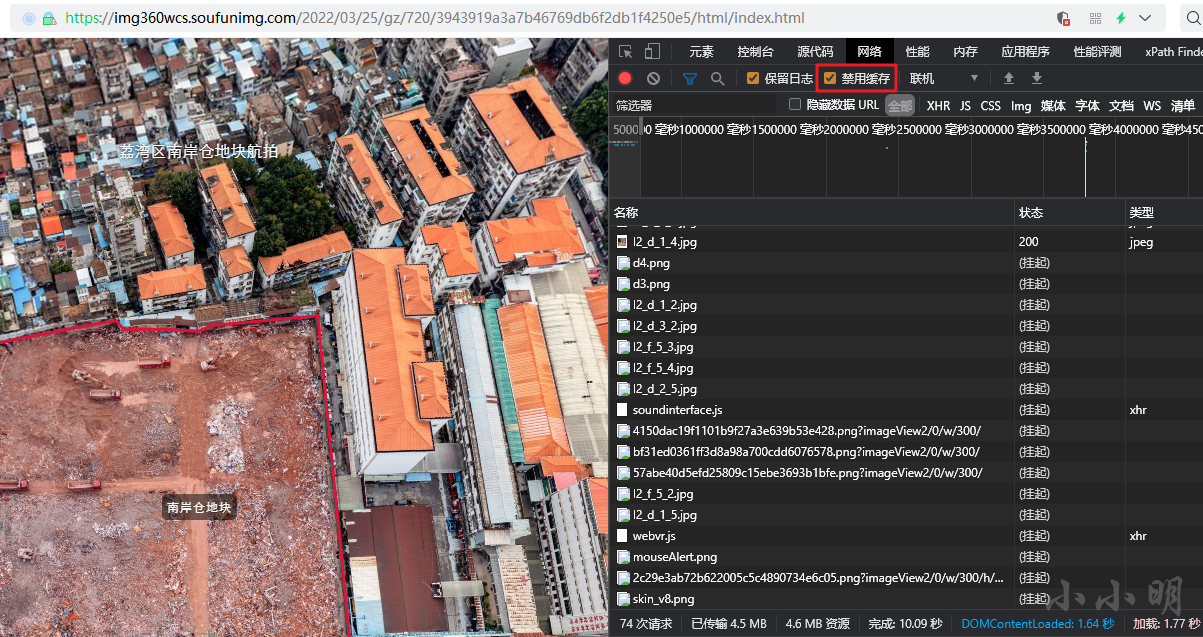
此时主体文件已经全部缓存:
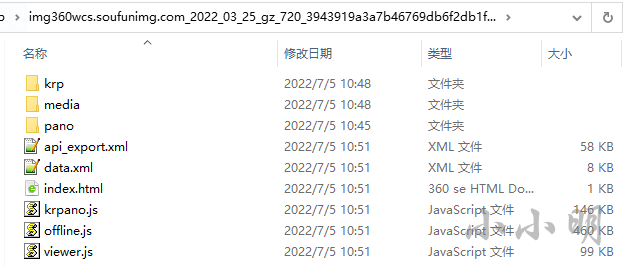
此时只要尽量多的在原始网页上游览各个方向,并放大缩小就可以尽量多缓存更多高清细节图片。
使用本地服务器启动测试已经顺利访问:
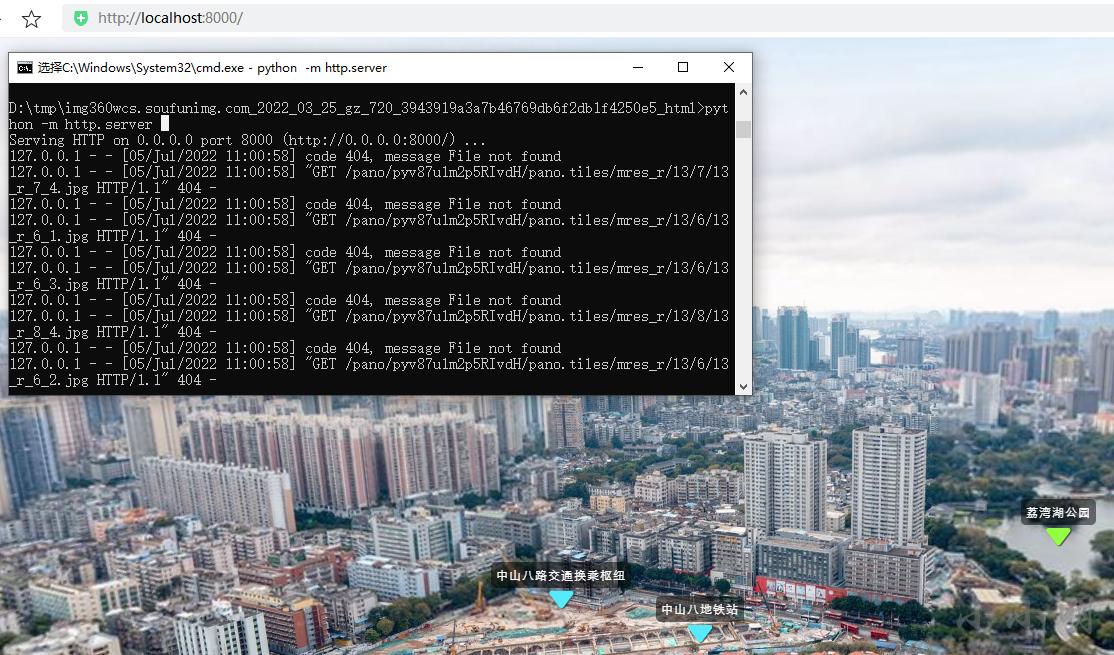
不过原始脚本只缓存响应码为200的普通文件,上述网站还会返回响应码为206的分片音乐文件,如果也需要缓存就稍微复杂一些,下面我们研究一下如何缓存音乐文件。
缓存206分片文件
经过一番研究,将上述代码修改为如下形式即可:
import os
import re
dest_url = "https://img360wcs.soufunimg.com/2022/03/25/gz/720/3943919a3a7b46769db6f2db1f4250e5/html"
def response(flow):
url = flow.request.url
response = flow.response
if response.status_code not in (200, 206) or not url.startswith(dest_url):
return
r_pos = url.rfind("?")
url = url if r_pos == -1 else url[:r_pos]
url = url if url[-1] != "/" else url+"index.html"
path = re.sub("[/\\\\:\\*\\?\\<\\>\\|\"\s]", "_", dest_url.strip("htps:/"))
file = path + "/" + url.replace(dest_url, "").strip("/")
r_pos = file.rfind("/")
if r_pos != -1:
path, file_name = file[:r_pos], file[r_pos+1:]
os.makedirs(path, exist_ok=True)
if response.status_code == 206:
s, e, length = map(int, re.fullmatch(
r"bytes (\d+)-(\d+)/(\d+)", response.headers['Content-Range']).groups())
if not os.path.exists(file):
with open(file, "wb") as f:
pass
with open(file, "rb+") as f:
f.seek(s)
f.write(response.content)
elif response.status_code == 200:
with open(file, "wb") as f:
f.write(response.content)
保存修改完的脚本,mitmdump可以自动重载:
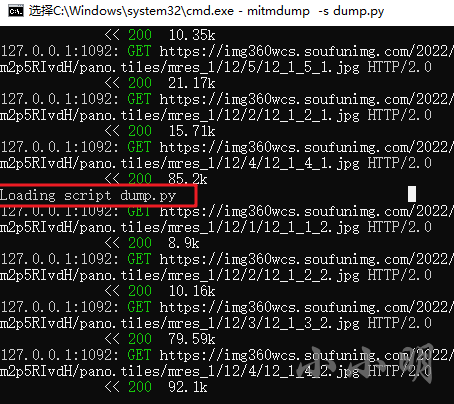
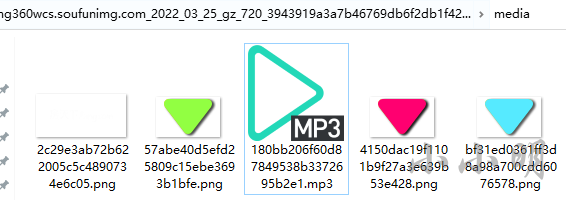
清理缓存并重新访问之后,音乐文件已经顺利下载:
总结
通过mitmdump我们已经顺利实现了对指定网站的缓存,以后想缓存其他网站到本地只需要修改dest_url的网址即可。
边栏推荐
猜你喜欢
dockermysql修改root账号密码并赋予权限

Hard core observation 545 50 years ago, Apollo 15 made a feather landing experiment on the moon
MySQL中正则表达式(REGEXP)使用详解
![[compilation principle] LR (0) analyzer half done](/img/ec/b13913b5d5c5a63980293f219639a4.png)
[compilation principle] LR (0) analyzer half done
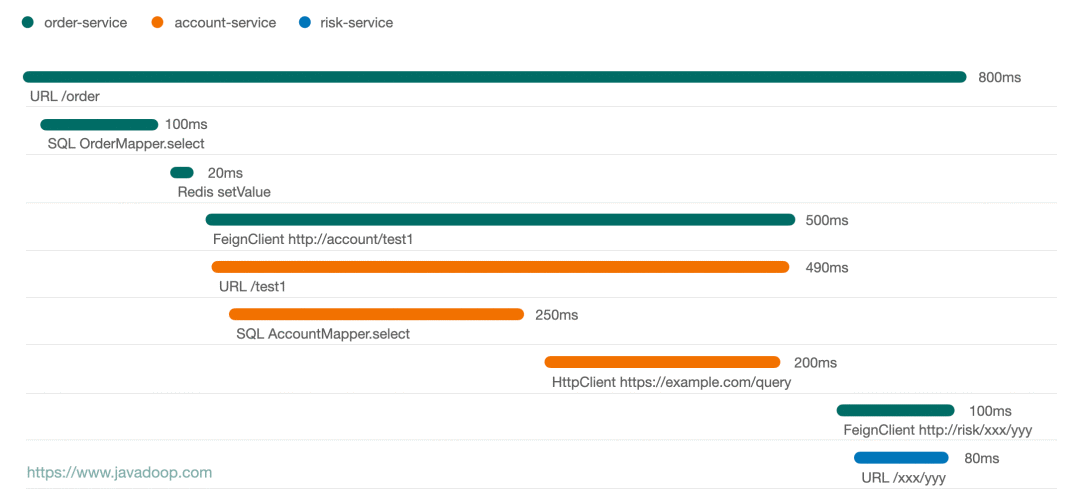
监控界的最强王者,没有之一!

同构+跨端,懂得小程序+kbone+finclip就够了!

企業不想換掉用了十年的老系統
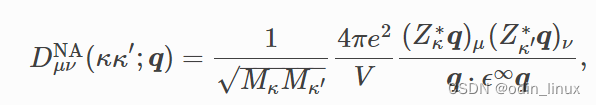
On the problems of born charge and non analytical correction in phonon and heat transport calculations
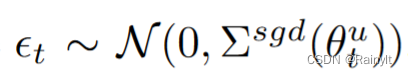
Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR2022 oral)
企业不想换掉用了十年的老系统

随机推荐
面试题:AOF重写机制,redis面试必问!!!
The difference between enumeration and define macro
OpenNMS separation database
Improving Multimodal Accuracy Through Modality Pre-training and Attention
CSDN 上传图片取消自动加水印的方法
What can be done for traffic safety?
Slide the uniapp to a certain height and fix an element to the top effect demo (organize)
Children's pajamas (Australia) as/nzs 1249:2014 handling process
MySQL authentication bypass vulnerability (cve-2012-2122)
On file uploading of network security
How to choose indoor LED display? These five considerations must be taken into account
CUDA exploration
(DART) usage supplement
Redis 持久化机制
OpenSSL:适用TLS与SSL协议的全功能工具包,通用加密库
COSCon'22 社区召集令来啦!Open the World,邀请所有社区一起拥抱开源,打开新世界~
POJ 1258 Agri-Net
[IELTS speaking] Anna's oral learning record part1
Project duplicate template
Redis persistence mechanism