当前位置:网站首页>Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR2022 oral)
Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR2022 oral)
2022-07-06 22:37:00 【Rainylt】
paper: https://arxiv.org/pdf/2203.15332.pdf
One sentence summary : Solve the problem that the dominant mode is trained too fast during multimodal training, resulting in insufficient training of auxiliary mode
Cross entropy loss function :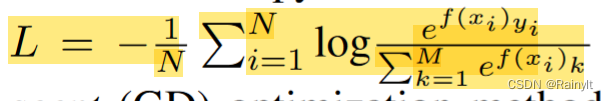
among ,f(x) by 
Decoupling :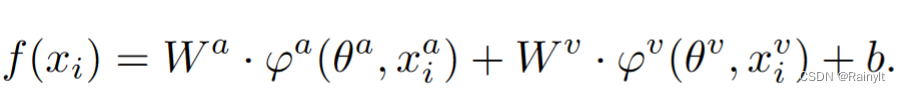
among ,a Express audio Modality ,v Express visual Modality ,f(x) by softmax The first two modes are jointly output logits. In this task a Is the dominant mode , namely about gt Category ,a Modal output logits Bigger
With W a W^a Wa For example ,L Yes W a W^a Wa Derivation :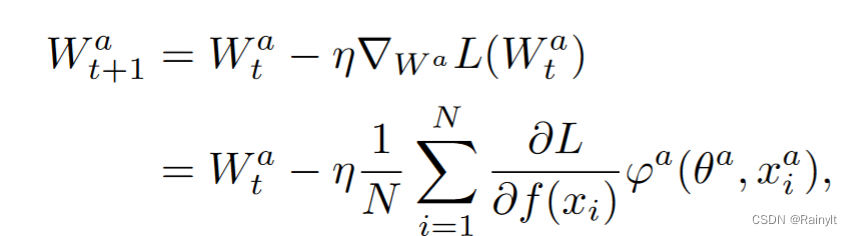
You can see , According to the chain derivation rule , φ a \varphi^a φa Is with the a Modal dependent output , ∂ L ∂ f ( x i ) \frac{\partial{L}}{\partial{f(x_i)}} ∂f(xi)∂L The value of is the same for both modes , Therefore, the impact on Different modes Of Gradient difference Is the latter part , That is to say φ \varphi φ Value . Due to the generally dominant mode output logits Higher , namely φ \varphi φ and W W W It's worth more , Therefore, the gradient of reverse transmission is also larger , Convergence is also faster .
Therefore, the dominant mode may appear. Train first ,loss Lower , Auxiliary mode has not been well trained . Specifically, why can't the auxiliary mode be trained well , To be explored .
For this article , in order to Deceleration dominates modal training , So when we find the gradient, we add Attenuation coefficient , Reduce the gradient of dominant mode backpropagation , It is equivalent to reducing the learning rate of the dominant mode alone :
Use two modes to output respectively logits Of softmax After score Ratio to determine
Make the ratio greater than 1 Of ( Dominant mode ) Set the attenuation factor k(0~1), The auxiliary mode is 1( unchanged )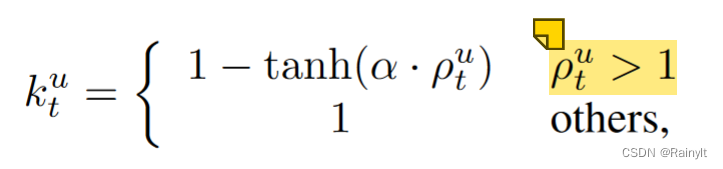
Multiply with the learning rate , Equivalent to reducing the learning rate 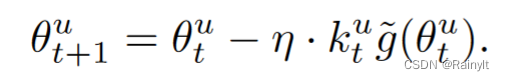
Besides , according to SGD Gradient back propagation process , The gradient can be pushed to the original gradient + Gaussian noise :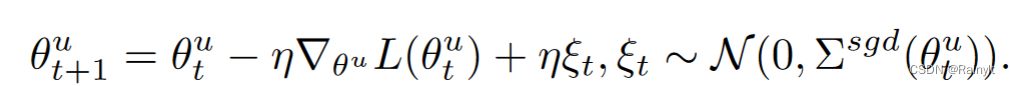
The higher the learning rate => The greater the covariance of Gaussian noise => The stronger the generalization ability . Reducing the learning rate here is equivalent to weakening the generalization ability of the dominant mode . The gradient after adding the attenuation coefficient , The variance is reduced to the original k^2 times :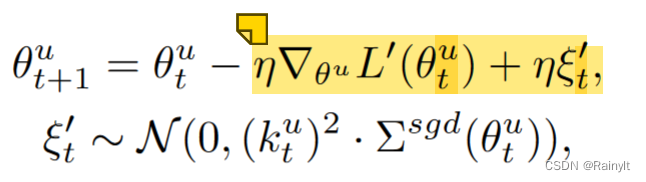
therefore , This paper artificially adds a Gaussian noise , variance =batch Variance of inner sample :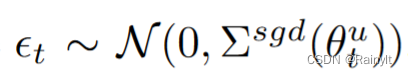
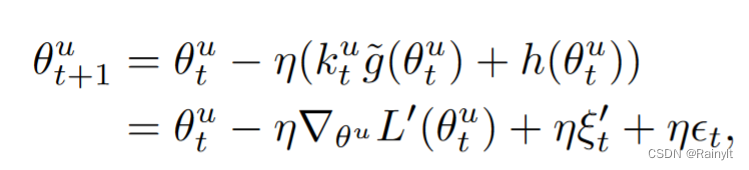
The covariance equivalent to noise is larger than before :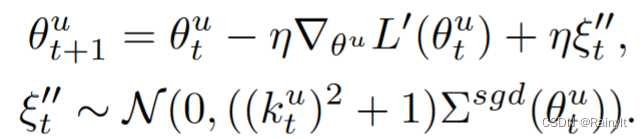
边栏推荐
猜你喜欢
自制J-Flash烧录工具——Qt调用jlinkARM.dll方式

That's why you can't understand recursion

金融人士必读书籍系列之六:权益投资(基于cfa考试内容大纲和框架)
config:invalid signature 解决办法和问题排查详解
手写ABA遇到的坑

(十八)LCD1602实验
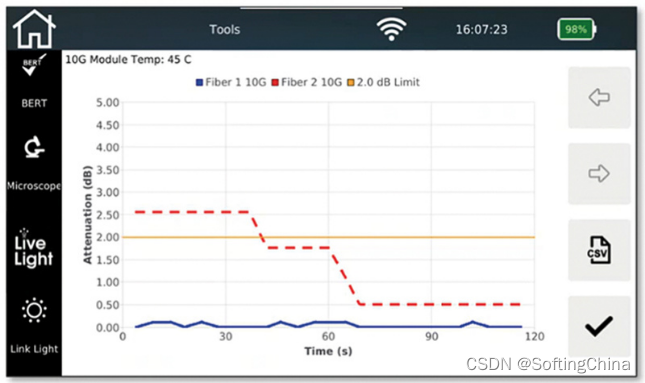
Netxpert xg2 helps you solve the problem of "Cabling installation and maintenance"
The SQL response is slow. What are your troubleshooting ideas?

MySQL ---- first acquaintance with MySQL
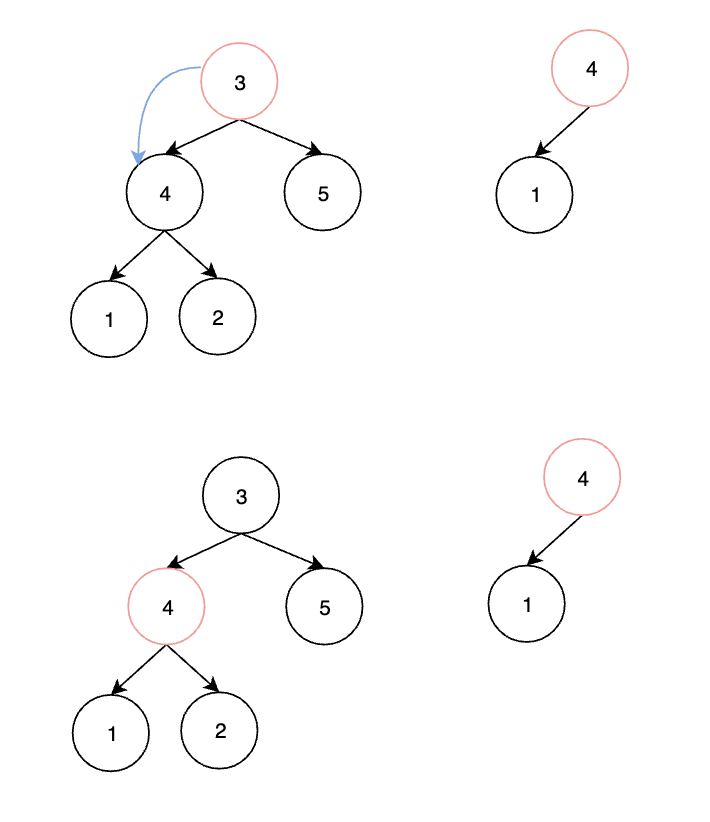
Leetcode exercise - Sword finger offer 26 Substructure of tree

随机推荐
Uniapp setting background image effect demo (sorting)
Adavit -- dynamic network with adaptive selection of computing structure
pytorch_YOLOX剪枝【附代码】
Heavyweight news | softing fg-200 has obtained China 3C explosion-proof certification to provide safety assurance for customers' on-site testing
POJ 1258 Agri-Net
Traversal of a tree in first order, middle order, and then order
Attack and defense world miscall
Advantages of link local address in IPv6
config:invalid signature 解决办法和问题排查详解
2022-07-05 stonedb的子查询处理解析耗时分析
The ceiling of MySQL tutorial. Collect it and take your time
动作捕捉用于蛇运动分析及蛇形机器人开发
go多样化定时任务通用实现与封装
Signed and unsigned keywords
AdaViT——自适应选择计算结构的动态网络
View
Crawler obtains real estate data
case 关键字后面的值有什么要求吗?
Financial professionals must read book series 6: equity investment (based on the outline and framework of the CFA exam)
LeetCode 练习——剑指 Offer 26. 树的子结构