当前位置:网站首页>Improving Multimodal Accuracy Through Modality Pre-training and Attention
Improving Multimodal Accuracy Through Modality Pre-training and Attention
2022-07-06 22:37:00 【Rainylt】
paper:
It is found that the convergence speed of different modes of the multimodal model is inconsistent , So they pre train separately , Reuse attention( Not self-attn) Get the weights of different modes , Multiply by the weight concat->FC->logits
First of all, let's talk about attention. No self-attention That kind of Q*K The mechanism of , It is Put the three modes directly feature concat after , too FC Get the weight :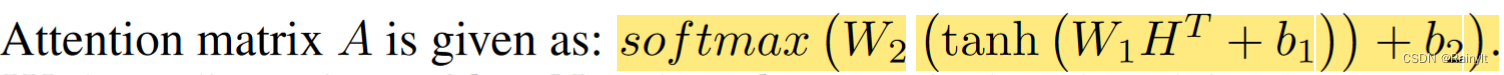
H There are three modes (v, a, t) Of feature,shape by (3,m). Output three modes The weight
According to the author's observation , Direct training of multimodal models , Of different modes Loss The descent speed is inconsistent ( Convergence rate ):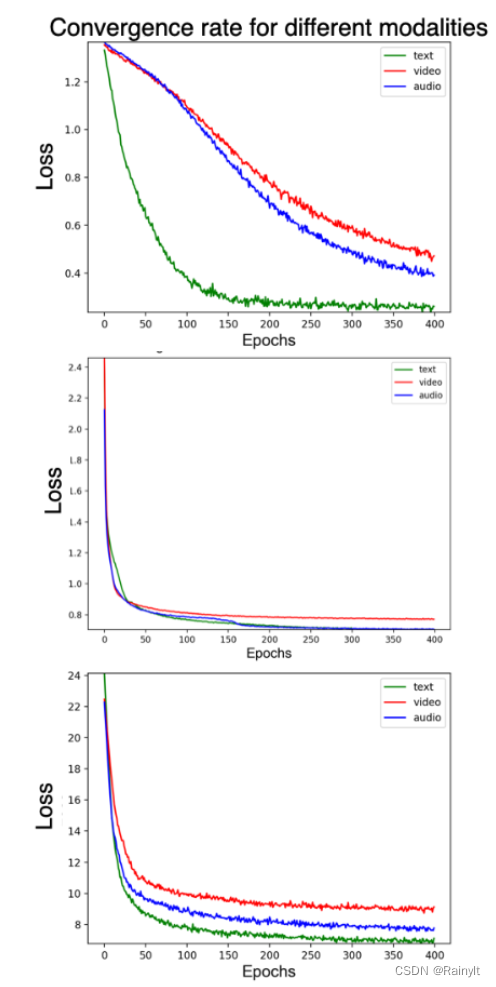
The three figures are different data sets , The second and third datasets are slightly better , The first data set is text Convergence too fast .
Look at the weights of different modes :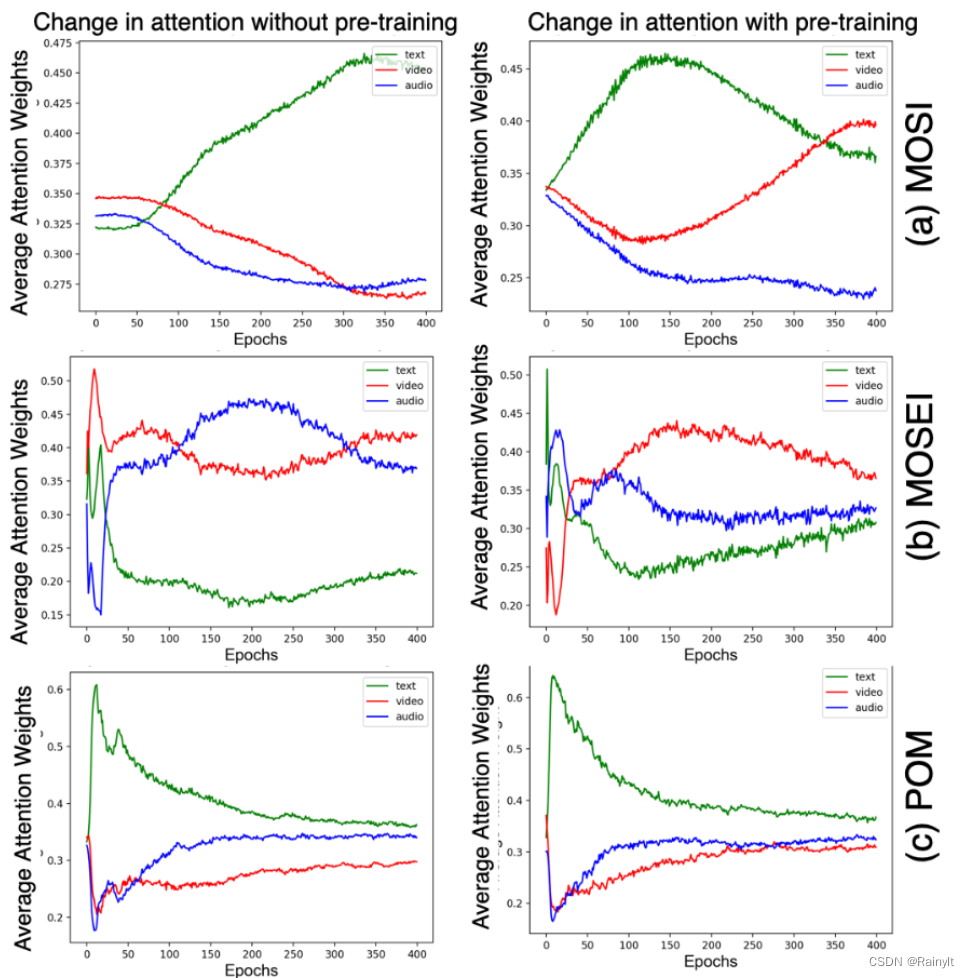
You can see that the first data set is before the pre training text Account for most of the weight , Maybe because it is more important , It may also be because of his feature Better quality . After pre training video Catch up , explain video Before it was just feature It's just not well trained .
Three modes , Who is more important is to As the case may be Of :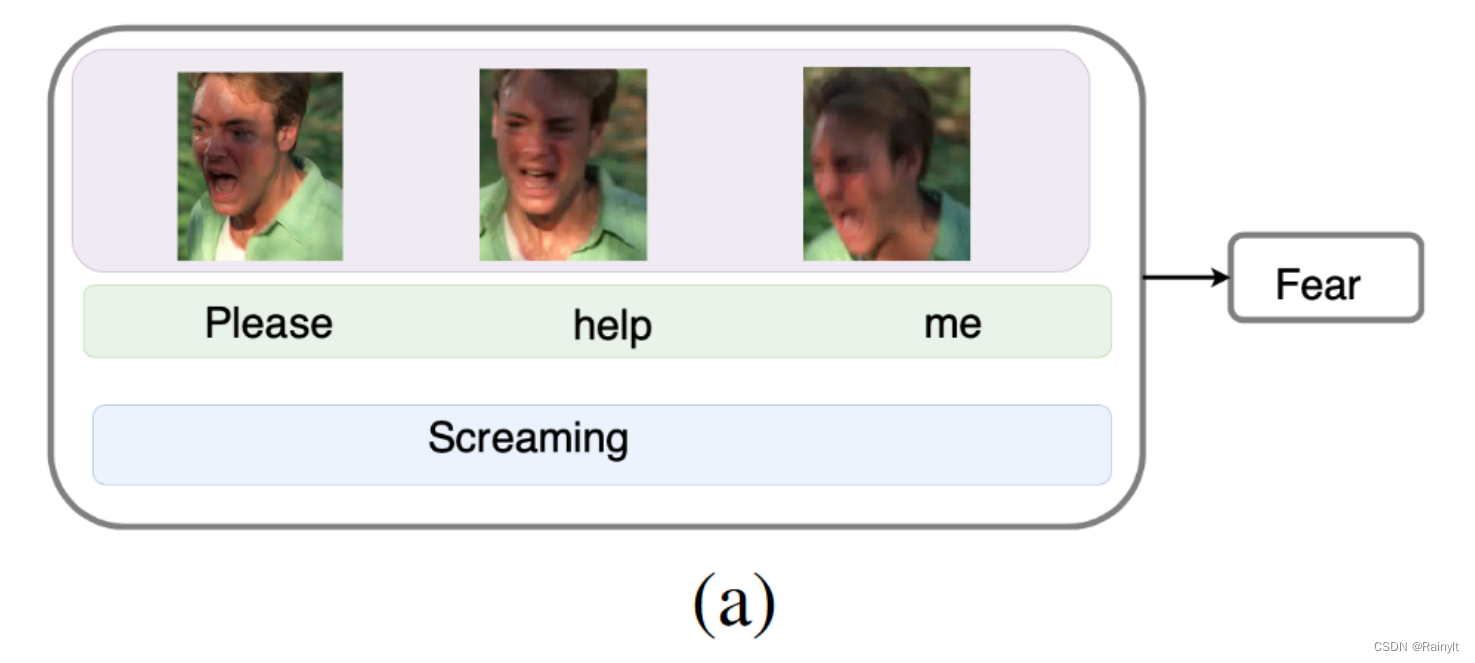
All three modes here can show fear 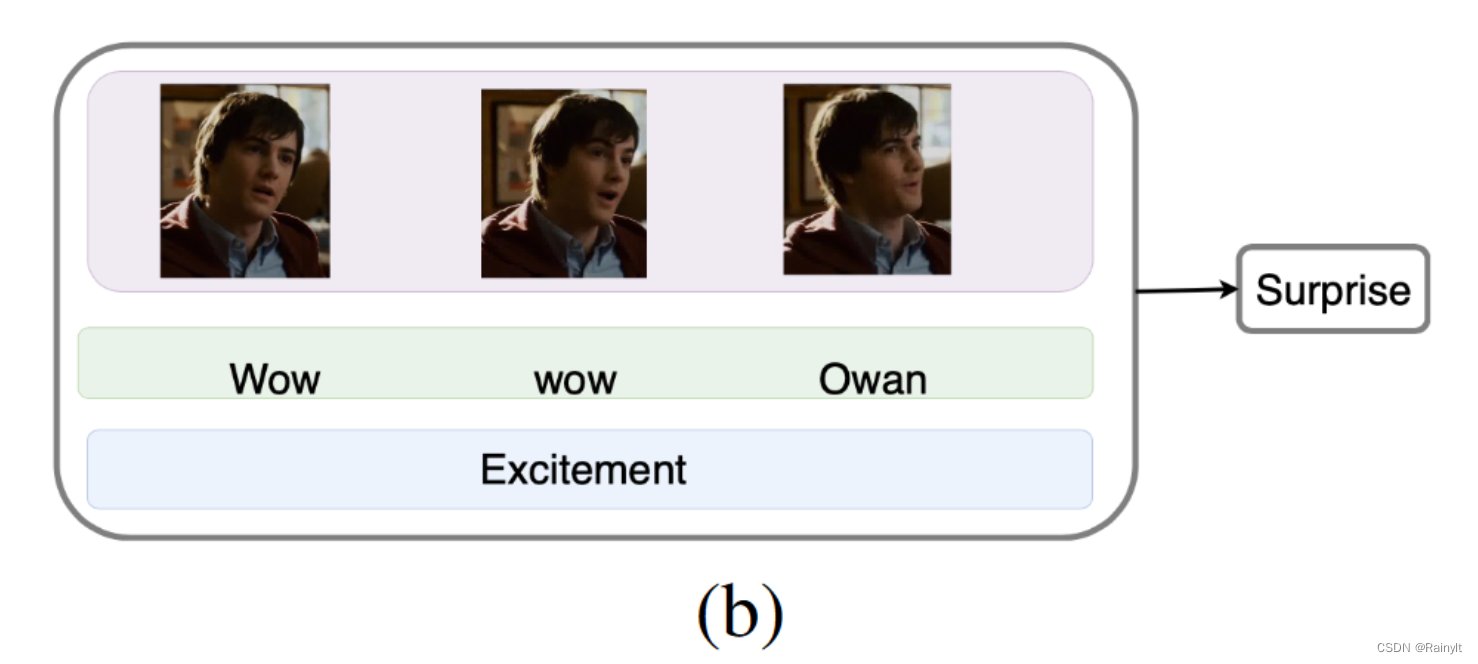
here text and audio Can show surprise , but img No way. , The expression is relatively flat ( It's hard to say )
This example is better , Although he is apologizing , But actually I was laughing , It should be a happy mood , So this should be audio Dominant
What this article puts forward attention Weight and these importance can correspond :
边栏推荐
猜你喜欢

0 basic learning C language - interrupt

NPDP认证|产品经理如何跨职能/跨团队沟通?
![[leetcode] 19. Delete the penultimate node of the linked list](/img/ab/25cb6d6538ad02d78f7d64b2a2df3f.png)
[leetcode] 19. Delete the penultimate node of the linked list

Daily question 1: force deduction: 225: realize stack with queue
【LeetCode】19、 删除链表的倒数第 N 个结点

0 basic learning C language - digital tube

Should novice programmers memorize code?
Attack and defense world miscall

CocosCreator+TypeScripts自己写一个对象池

(18) LCD1602 experiment
随机推荐
C# 三种方式实现Socket数据接收
signed、unsigned关键字
2022-07-05 use TPCC to conduct sub query test on stonedb
【无标题】
MySQL约束的分类、作用及用法
Classification, function and usage of MySQL constraints
Uniapp setting background image effect demo (sorting)
go多样化定时任务通用实现与封装
ThreadLocal详解
Spatial domain and frequency domain image compression of images
Attack and defense world miscall
POJ 1258 Agri-Net
在IPv6中 链路本地地址的优势
(18) LCD1602 experiment
How big is the empty structure?
Traversal of a tree in first order, middle order, and then order
枚举与#define 宏的区别
Aardio - 利用customPlus库+plus构造一个多按钮组件
leetcode:面试题 17.24. 子矩阵最大累加和(待研究)
pytorch_ Yolox pruning [with code]