当前位置:网站首页>[launched in the whole network] redis series 3: high availability of master-slave architecture
[launched in the whole network] redis series 3: high availability of master-slave architecture
2022-07-06 22:54:00 【Heapdump performance community】
1 、 Introduction to master-slave replication
Last one 《Redis series 2: Data persistence improves availability 》 in , We introduced Redis Data Persistence technology in , Include RDB snapshot and AOF journal . With these two sharp tools , We don't have to worry about machine downtime anymore , Data lost .
But persistence technology only solves Redis After service failure , The problem of fast data recovery . There is no fundamental improvement Redis The usability of , What we need is security Redis High availability , Reduce or even avoid Redis The possibility of service downtime .
Current implementation Redis There are three modes of high availability : A master-slave mode 、 Sentinel mode 、 Cluster pattern . These will be divided into three introductions later , Today, let's talk about the master-slave mode .
Redis The master-slave mode provided , By copying , Put... On the main server Redis A copy of the data is synchronously copied from Redis The server , It's very common ,MySQL That's what the master and slave do .
The master node Redis We call it master, From node's Redis We call it slave, Master-slave replication is one-way replication , Only from master to slave , You can't go from one to the other . There can be multiple slave nodes , such as 1 Lord 3 From even n from , Judge from the number of nodes according to the actual business needs .
2、 Master slave data consistency guarantee
To ensure the master server Redis Data and slave server Redis The consistency of the data of , In order to share the pressure of visiting , Load balancing , The application level generally adopts the mode of reading and writing separation .
- Read operations : Lord 、 It can be executed from the library , Generally, you are reading data from the Library , For real-time and accuracy 100% Some businesses with high requirements , You can read the main database after careful evaluation ;
- Write operations : Only write data on the main database , After writing, synchronize the write operation instructions to the slave Library .
Here's the picture :
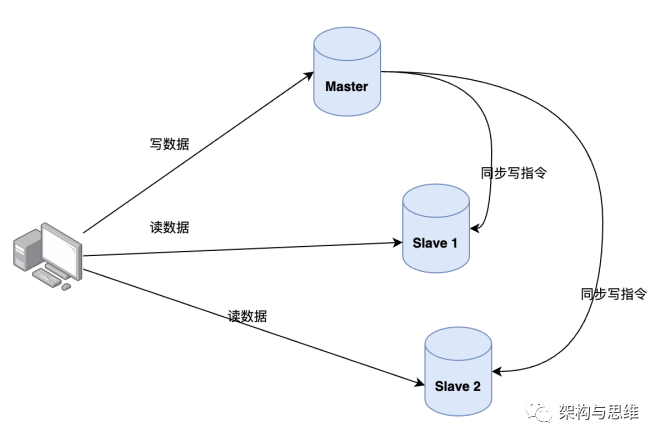
2.1 Why use the read-write separation mode ?
The use of read-write separation mode is similar to MySQL The original intention of separating reading and writing is the same . Because we have divided the master-slave database , And the data of the slave database is copied by the master database in one direction . If both master and slave libraries can execute write instructions , Then modify different replica data in high-frequency concurrency scenarios , The operation will be disordered , It is easy to cause data inconsistency among copies , This is the disadvantage of distributed mode . If you have to ensure strong consistency of data ,Redis Need to be locked , Or use queue order , This is bound to reduce Redis Performance of , Reduce service throughput , This is not high performance Redis What is acceptable .
2.2 Does master-slave copy have any other functions ?
Fault isolation and recovery : Whether the master node or the slave node goes down , Other nodes can still ensure the normal operation of the service , And you can manually switch between master and slave .
Read write isolation :Master Nodes provide write services ,Slave Nodes provide read services , Apportion flow pressure , Balance the load of traffic .
Provide high availability guarantee : Master-slave mode is the most basic version of high availability , It is also sentinel mode and cluster Preconditions for mode implementation .
3、 Build master-slave replication
The opening of master-slave replication , It is completely configured and initiated from the node , We don't need to do anything at the master node .
Can pass replicaof(Redis 5.0 Before using slaveof) Commands form the relationship between the master database and the slave database . Turn on master-slave replication at the slave node , Yes 3 Ways of planting :
explain :masterip: host IP,masterport: Host port number
3.1 Configuration file mode
Add to profile from server
replicaof <masterip> <masterport>3.2 Start command mode
redis-server Add... After the start command
--replicaof <masterip> <masterport>3.3 By using commands on the client
Start multiple Redis After the instance , Execute commands directly from the client :
replicaof <masterip> <masterport>Then Redis Instance becomes slave .
Suppose there is a main instance (192.168.0.1:6379)、 From the example A(192.168.0.2:6380) and From the example B (192.168.0.3:6381), Execute the following commands on the slave instance , Has become a Slave, The main instance becomes Master.
redis 5.0 Before slaveof 192.168.0.1 6379# redis 5.0 after replicaof 192.168.0.1 6379
4、 Master slave replication principle
After the master-slave library mode is turned on , The application level adopts read-write separation , All data write operations will only be performed on the main library , And the read operation will basically be carried out on the slave Library ( Under special circumstances, some read businesses are allowed to go to the main database ).
The master and slave will maintain the final consistency : After the data update of the main database , It will be synchronized to the slave library immediately , To ensure the consistency of the data of the master-slave database .
4.1 Synchronization steps of master-slave Library
How does the master-slave database synchronization complete ? One time transmission , Will the data be too large ? Delivery in batches , Will there be any problem with timeliness ? Will the data be lost in case of failure ? How to supplement the difference data generated in the middle after reconnection to ensure consistency ? With these questions, let's continue to analyze .
Based on the above problems, synchronization , There are three important scenarios :
Full replication after the primary and secondary libraries are configured for the first time
During the normal operation of master and slave , Quasi real time synchronization
The network between master and slave databases is disconnected and reconnected ,Append Incremental data + Quasi real time synchronization
4.1.1 The first full copy of the master-slave Library
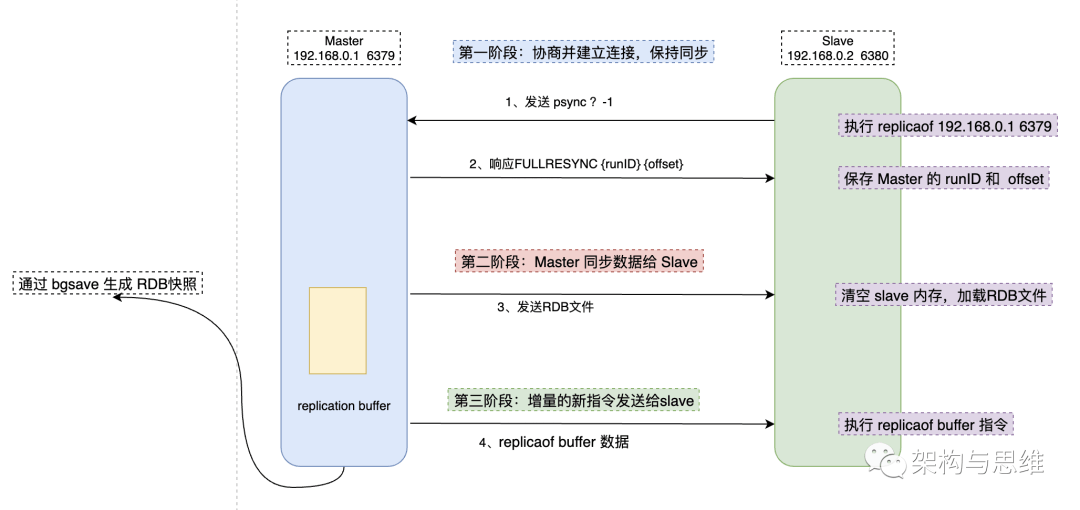
The first replication process of master-slave libraries can be roughly divided into 3 Stages : Preparation stage ( That is, establish connection preparation )、 The master database synchronizes data to the slave database stage 、 Send the incremental instruction during synchronization to the stage of slave Library .
Let's take a look at this complete flow chart , Have an understanding on the whole .
4.1.1.1 Establishing a connection
The main function of this stage is to establish the connection between master and slave , After the connection is established , Only in this way can we do full data synchronization . It mainly includes the following steps :
From the node's configuration file replicaof In the configuration item, the IP and port , Once the configuration is complete , The slave node knows which master node to connect with .
When the connection is successful , Open from library replicaof operation , Send... At the same time psync The instruction tells the main library , I'm ready to start syncing . The command contains the runID and Replication progress offset Two parameters .
- runID: Every Redis The instance will automatically generate a Unique identification ID, The first master-slave replication , I don't know the main library yet runID, So the parameter will be set to :?.
- offset: Because the first copy , There is no offset , So the default setting is -1, In this way, the default is from 1 Instructions begin to copy .
Master library received psync After the command, start the copy according to the parameters , Use FULLRESYNC Response command , Take two parameters at the same time : Main library runID And the current replication progress of the master library offset, Back to the slave Library .
After receiving a response from the library , Record these two parameters .
4.1.1.2 The master database synchronizes the data to the slave database
The second stage
master perform bgsave Command to generate RDB file , And send the file to the slave Library , Received from library RDB Save the file to disk , To empty the current Redis Data in the library , then RDB File data is loaded into memory .
At the same time, the main library is for each slave Open up a piece of replication buffer Buffer record , Used to record the generation of master database RDB The period after the document ( The write command generated during that time was not recorded RDB In file , But the main library will continue to receive new request instructions , The recording buffer is to ensure that data is not lost ) All write instructions generated .
4.1.1.3 Send a new write command to the slave library
The third stage
From the second stage, we can know , Generate RDB After the document , Subsequent operation instructions are not recorded , In order to ensure Redis Consistency of master-slave database data , The main library will be created in memory replication buffer , Record RDB All operation instructions after file generation .
And after receiving from the Library RDB Master data , First clear the current slave database data , Then complete data initialization . After the whole initialization , Continue from replication buffer Data sent from buffer , Avoid data fragmentation .
* The master data is synchronized to the slave database , The main library will not be blocked , It can normally handle any other operation , This is also Redis Prerequisites for ensuring high performance .
replication buffer The buffer is created in master On the main warehouse , The stored data is within the following three times master All write operations of data .
master perform bgsave production rdb Write operations during ;
master transmission rdb File to slave Write operations during ;
slave load rdb Write operations during file initialization to memory .
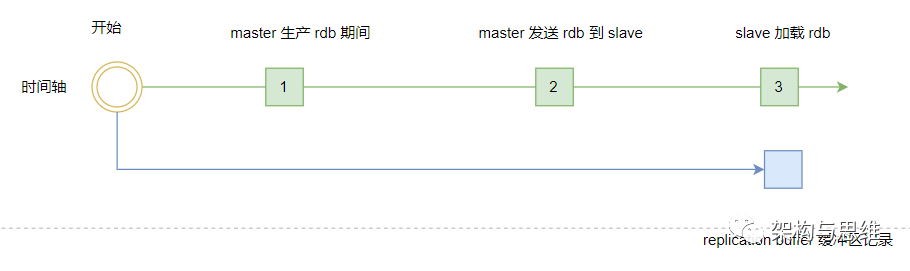
Three steps have been completed Redis Master slave full replication . What we need to pay attention to here is ,Redis Communication in , Whether it is between the master database and the slave database , Or data interaction with the client . In essence, it is through the allocation of memory buffer To carry out ,Master I will write the data to buffer in , Then send it out through the network , So as to complete data interaction .
RDB File as binary , Whether it is the disk during network transmission or writing IO, It's more efficient than AOF Much higher . alike , Data recovery from the library , It will be more efficient . So we will choose RDB Synchronize files instead of AOF Pattern .
4.1.2 Incremental replication
4.1.2.1 The synchronization mode after the master-slave network is disconnected
The high version of the Redis, After the network is disconnected or after recovering from the instance service failure , The master-slave database will continue to synchronize by incremental replication , Instead of full synchronization , This will greatly reduce the cost , Improve efficiency .
Incremental replication : It refers to the replication after network interruption or restart from the Library , Only write commands executed by the master node during the interrupt are sent to the slave node , More efficient than full replication .
repl_backlog_buffer
Incremental replication can be achieved after the master and slave libraries are reconnected . The key is repl_backlog_buffer buffer above .
because master The write instruction operation will be recorded in repl_backlog_buffer Buffer zone , And use master_repl_offset Record master Position offset written ,slave Then use slave_repl_offset Record the read offset .master When adding a write operation , The offset increases . After continuously executing synchronous write instructions from the library ,slave_repl_offset Will continue to increase . In general , These two offsets will remain synchronized , The following figure left .
But during network disconnection or library failure , Main instance Redis Generally, you will receive a new write operation command , But the execution is suspended from the instance , therefore master_repl_offset Will be greater than the slave_repl_offset. The following figure to the right .
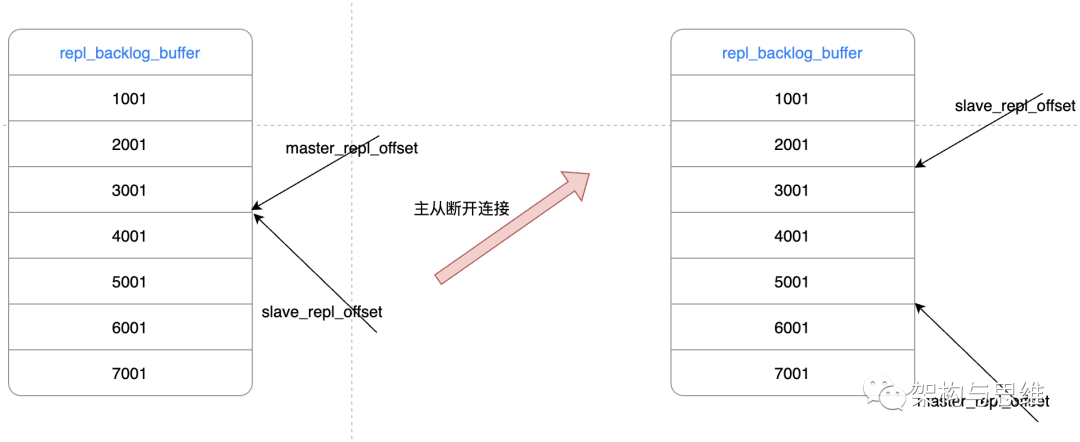
It should be noted that , repl_backlog_buffer It is not the seemingly infinite queue pattern shown in the figure , But a ring like array , If the array is full , It will cover the previous content from the beginning , Because the memory space given is limited .
After reconnecting between master and slave ,slave Will send psync Order to master, At the same time, I will put my own {runID,slave_repl_offset} Two parameters are sent to master.master Only need to master_repl_offset And slave_repl_offset You can synchronize the commands between them to the slave library . The process of incremental replication is similar to the following :
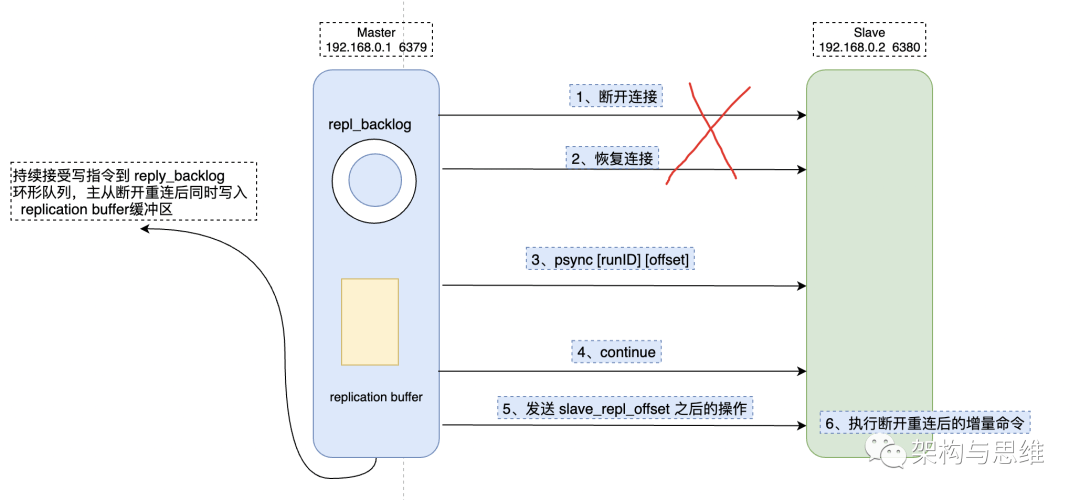
In the configuration repl_backlog_buffer When , All kinds of factors need to be taken into consideration , Too large will lead to a long incremental execution cycle , Not so good RDB Full coverage . Is too small , It's possible that it's not read from the library yet Master The new write operation of covers , That way, you can only perform full replication .
So we need to give a reasonable buffer Size. There are generally the following calculation formulas for reference :
repl_backlog_buffer_size = seconds * write_size_per_second
seconds: Under normal circumstances, disconnect from the Library , The average time to reconnect to the main database , Seconds per unit .
write_size_per_second: The average amount of write command data generated by the main library per second .
For example, the main server generates 0.5 MB Write instruction data , And disconnection to reconnection generally requires 30s, Then the size of the buffer is 0.5 * 30s = 15 MB.
But we usually keep a little buffer, such as reserve 0.5 times , That's it : 1.5 * 15 MB = 22.5 MB .
4.1.2.2 Command propagation based on long connections
The above work is to complete the complete replication , After full replication , The master and slave began to enter normal and orderly synchronization , What should I do ?
After the master and slave complete full replication , They need to stay connected . When the main library receives the operation instruction , Synchronize to the slave library through this connection , This process is called Command propagation based on long connections .
In order to ensure the effectiveness and stability of communication , The slave node uses the heartbeat mechanism to detect , dispatch orders :PING and REPLCONF ACK.
- Lord -> from :PING
Every specified time ( such as 1 minute , Configurable ), The master will send... To the slave PING command , Detect whether the slave node has timed out to judge the health of the slave node .
- from -> Lord :REPLCONF ACK
The stage of command execution propagation , The slave server defaults to once per second , Send commands to the main server , Send the copied offset .
REPLCONF ACK <replication_offset>
replication_offset The attribute of refers to the current replication offset from the instance server .
Send from instance REPLCONF ACK Command for main instance , It has the following functions :
Check whether the network path of the master-slave server is normal .
Aided implementation min-slaves Options , Use Redis Of min-slaves-to-write( Less than n From instance , Refuse to execute the write command ) and min-slaves-max-lag( The master-slave delay is greater than or equal to n seconds , Refuse to execute the write command ) Two options prevent the primary server from executing write commands without security .
Detection command lost , Sent... From node slave_replication_offset, The master node will compare master_replication_offset , If it's not consistent , It indicates that the slave node data is missing , The master node will run from repl_backlog_buffer Find and push missing data in buffer .
4.1.2.3 How to determine whether to perform full synchronization or partial synchronization ?
From the node can send psync The command requests the master node to synchronize data , The master node judges the current state of the slave node , See whether full replication or partial replication is used for synchronization . The core is psync Parameters of , We have already mentioned this before :
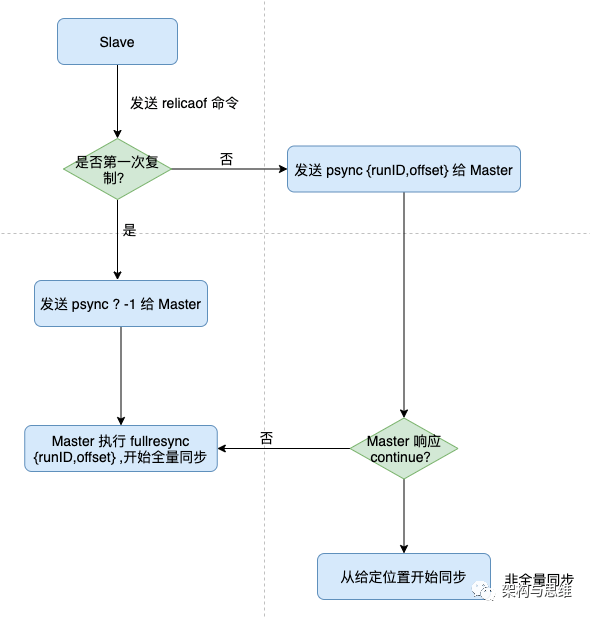
Now let's disassemble the next step :
1、 The slave node depends on its own state , send out psync Order to master:
- If it has never been executed from the instance replicaof , Send... From the node psync ? -1, Represents the total amount of , from -1 Start copying .
- If the slave node has been executed before replicaof, Then take the current instance and record runID and offset, Carry out orders psync <runID> <offset>, runID It's the master node runID,offset Copy offset .
2、 According to the received psync Command and current server status , Decide whether to perform full or partial replication :
- Compare the main 、 From node's runID Agreement , And send from the node slave_repl_offset And then the data is repl_backlog_buffer There are... In the buffer ( The queue is circular , It may be erased and rewritten ), Then reply CONTINUE, Represents partial replication in append mode .
- runID And sent from the node runID Different , Or sent from a node slave_repl_offset After that, the data is no longer in the primary node repl_backlog_buffer Buffer zone ( Because the queue is circular , So the waiting time is too long or there is disconnection , It may be erased and rewritten ), Then reply to the slave node FULLRESYNC <runid> <offset>, Means to make a full copy , At the same time, write down the main node runID and offset.
4.2 1 Lord n From the understanding of synchronization
From the above , We get the following two points :
- In the case of multiple slave libraries , Each slave will record its own slave_repl_offset, Their replication progress is also different .
- When reconnecting the primary database for recovery , From the library through psync The order will slave_repl_offset Inform the main warehouse , The master database judges the status of the slave database , To determine incremental replication , Or full copy .
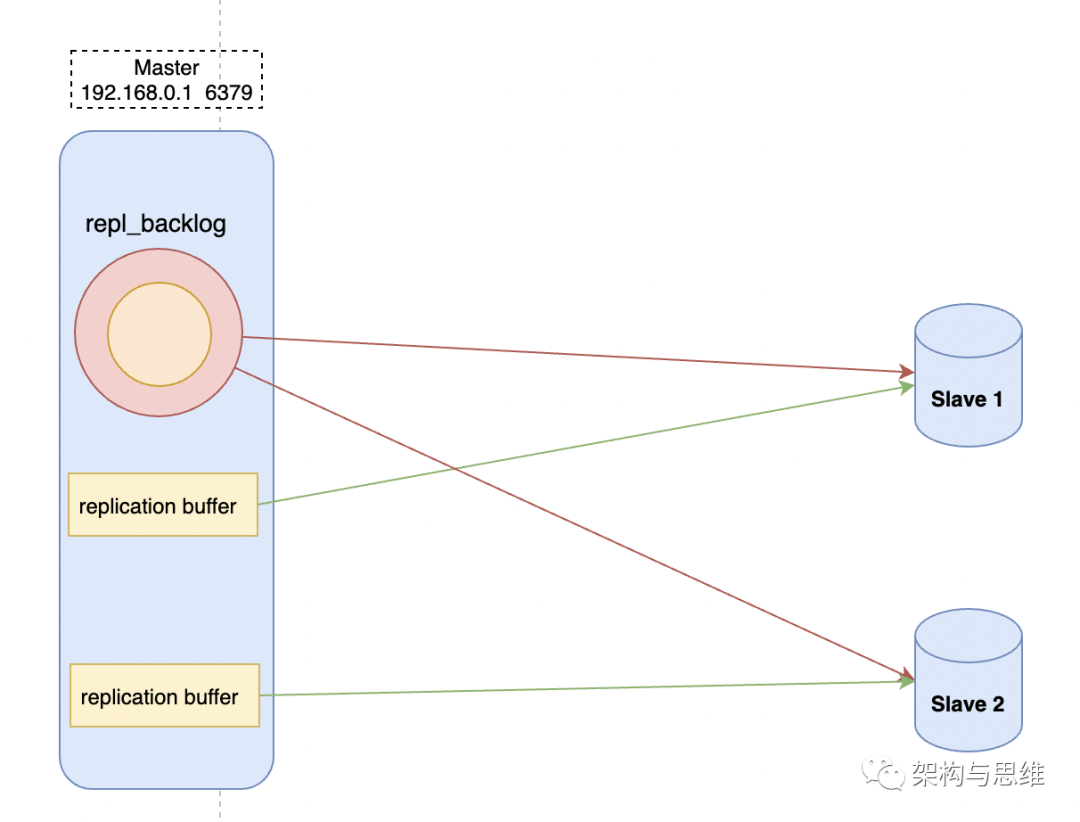
- replication buffer and repl_backlog Explanation
replication buffer It is the master-slave database in full replication , On the master library, it is used to connect the client with the slave library buffer, and repl_backlog_buffer Is to support incremental replication from the library , A dedicated block on the main library for persistent write operations buffer, All shared from the Library .
Master database and slave database will record their own replication progress respectively , therefore , When different slave libraries are recovering , You need to update your copy progress (slave_repl_offset) Send to master library , The main database can get data according to the offset and synchronize with it .
As shown in the figure :
5、 summary
- One of the functions of master-slave replication is to share the reading and writing pressure , Load balancing , The other is to ensure the continuous availability of services after some instances are down , therefore Redis Evolved master-slave architecture and read-write separation .
- The steps of master-slave replication include : The stage of establishing connection 、 The stage of data synchronization 、 Command propagation phase based on long connection .
- Data synchronization can be divided into full replication and partial replication , Full replication is generally the first full or long-term disconnection of the master-slave connection .
- In the command propagation phase, there are PING( Master to slave detection ) and REPLCONF ACK( From to the Lord ack The reply ) command , This mode of mutual heartbeat confirmation ensures the stability of data synchronization .
- The master-slave mode is a relatively low-level usability optimization , To achieve automatic failover , Abnormal warning , Gaobaohuo , More complex sentinel or cluster mode is also needed , We will have a special article to introduce this later .
See you here , If you are interested in what I write , Have any questions , Welcome to leave a message below , I will give you an answer for the first time , thank you !
边栏推荐
- dockermysql修改root账号密码并赋予权限
- OpenSSL: a full-featured toolkit for TLS and SSL protocols, and a general encryption library
- Improving Multimodal Accuracy Through Modality Pre-training and Attention
- Signed and unsigned keywords
- 【LeetCode】19、 删除链表的倒数第 N 个结点
- 企業不想換掉用了十年的老系統
- 【Unity】升级版·Excel数据解析,自动创建对应C#类,自动创建ScriptableObject生成类,自动序列化Asset文件
- Slide the uniapp to a certain height and fix an element to the top effect demo (organize)
- MySQL authentication bypass vulnerability (cve-2012-2122)
- Jafka source analysis processor
猜你喜欢
Export MySQL table data in pure mode
Rust knowledge mind map XMIND

European Bioinformatics Institute 2021 highlights report released: nearly 1million proteins have been predicted by alphafold
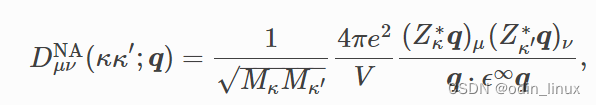
On the problems of born charge and non analytical correction in phonon and heat transport calculations

ICLR 2022 | pre training language model based on anti self attention mechanism

UE4 blueprint learning chapter (IV) -- process control forloop and whileloop
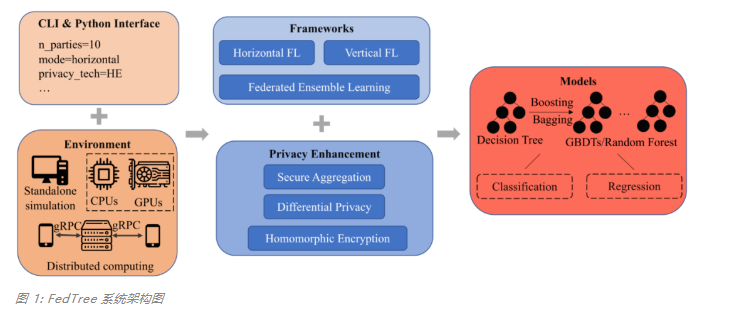
专为决策树打造,新加坡国立大学&清华大学联合提出快速安全的联邦学习新系统

On file uploading of network security
欧洲生物信息研究所2021亮点报告发布:采用AlphaFold已预测出近1百万个蛋白质
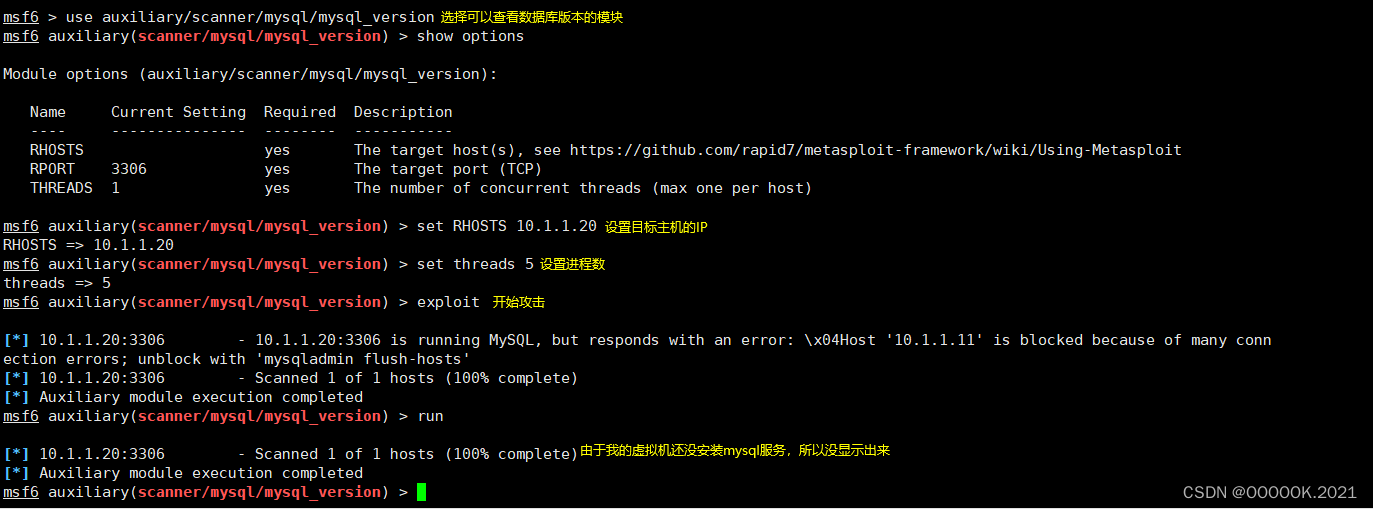
Mysql 身份认证绕过漏洞(CVE-2012-2122)
随机推荐
MySQL ---- first acquaintance with MySQL
如何实现文字动画效果
Introduction to network basics
OpenNMS分离数据库
OpenNMS separation database
MySQL教程的天花板,收藏好,慢慢看
Windows Auzre 微软的云计算产品的后台操作界面
The application of machine learning in software testing
Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR2022 oral)
QT signal and slot
机试刷题1
Bipartite graph determination
UE4蓝图学习篇(四)--流程控制ForLoop和WhileLoop
Volatile keyword
dockermysql修改root账号密码并赋予权限
The difference between enumeration and define macro
config:invalid signature 解决办法和问题排查详解
The ceiling of MySQL tutorial. Collect it and take your time
2022-07-05 stonedb sub query processing parsing time analysis
On the problems of born charge and non analytical correction in phonon and heat transport calculations