当前位置:网站首页>Unified Focal loss: Generalising Dice and cross entropy-based losses to handle class imbalanced medi
Unified Focal loss: Generalising Dice and cross entropy-based losses to handle class imbalanced medi
2022-07-06 15:32:00 【Never_Jiao】
Unified Focal loss: Generalising Dice and cross entropy-based losses to
handle class imbalanced medical image segmentation
发表期刊:Computerized Medical Imaging and Graphics’
发表时间:2022年
Abstract
自动分割方法是医学图像分析的重要进步。机器学习技术,尤其是深度神经网络,是大多数医学图像分割任务的最新技术。类别不平衡的问题对医学数据集提出了重大挑战,相对于背景,病变通常占据相当小的体积。深度学习算法训练中使用的损失函数在对类别不平衡的鲁棒性上有所不同,对模型收敛有直接影响。最常用的分割损失函数是基于交叉熵损失、Dice损失或两者的组合。我们提出了统一Focal损失,这是一个新的层次框架,它概括了Dice和基于交叉熵的损失来处理类不平衡。我们在五个公开可用的、类别不平衡的医学成像数据集上评估我们提出的损失函数:CVC-ClinicDB、用于血管提取的数字视网膜图像 (DRIVE)、2017 年乳腺超声 (BUS2017)、2020 年脑肿瘤分割 (BraTS20) 和 2019 年肾肿瘤分割(KiTs 19)。我们将我们的损失函数性能与六个 Dice 或基于交叉熵的损失函数进行比较,跨越 2D 二分类、3D 二分类和 3D 多类分割任务,证明我们提出的损失函数对类不平衡具有鲁棒性,并且始终优于其他损失函数。源代码位于:https://github.com/mlyg/unified-focal-loss。
Keywords: Loss function, Class imbalance, Machine learning, Convolutional neural networks, Medical image segmentation
Introduction
图像分割涉及根据区域像素特征将图像划分为有意义的区域,从中识别感兴趣的对象(Pal 和 Pal,1993)。这是计算机视觉中的一项基本任务,已广泛应用于人脸识别、自动驾驶以及医学图像处理。特别是,自动分割方法是医学图像分析的重要进步,能够在包括超声 (US)、计算机断层扫描 (CT) 和磁共振成像 (MRI) 在内的一系列成像模式中划分结构。
经典的图像分割方法包括直接区域检测方法(例如分割合并和区域增长算法(Rundo et al., 2016))、基于图的方法(Chen and Pan, 2018)、活动轮廓和水平设置模型(Khadidos 等人,2017 年)。后来的方法侧重于应用和调整传统的机器学习技术(Rundo 等人,2020b),例如支持向量机(SVM)(Wang 和 Summers,2012 年)、无监督聚类(Ren 等人,2019 年)和图谱基于分割(Wachinger 和 Gol Land,2014 年)。然而,近年来,深度学习取得了重大进展(Ker 等人,2018 年;Rueckert 和 Schnabel,2019 年;Castiglioni 等人,2021 年)。
图像分割中最著名的架构 U-Net (Ronneberger et al., 2015) 是将卷积神经网络 (CNN) 架构修改为编码器-解码器网络,类似于 SegNet (Badrinarayanan et al., 2015)。 , 2017),它支持端到端的特征提取和像素分类。自成立以来,已经提出了许多基于 U-Net 架构的变体(Y. Liu et al., 2020; L. Liu et al., 2020; Rundo et al., 2019a)——包括 3D U-Net( Cicek et al., 2016)、Attention U-Net (Schlemper et al., 2019) 和 V-Net (Mil letari et al., 2016)——以及集成到条件生成对抗网络中 (Kessler et al., 2020) ;Armanious 等人,2020 年)。
为了训练深度神经网络,反向传播根据损失函数定义的优化目标更新模型参数。交叉熵损失通常是分类问题中使用最广泛的损失函数(L. Liu et al., 2020; Y. Liu et al., 2020),并应用于 U-Net(Ronneberger et al., 2015) , 3D U-Net (Cicek et al., 2016) 和 SegNet (Badrinarayanan et al., 2017)。相比之下,Attention U-Net (Schlemper et al., 2019) 和 V-Net (Milletari et al., 2016) 利用 Dice loss,它基于评估分割性能的最常用指标,因此表示发送一种形式的直接损失最小化。从广义上讲,图像分割中使用的损失函数可以分为基于分布的损失(例如交叉熵损失)、基于区域的损失(例如 Dice 损失)、基于边界的损失(例如边界损失)(Kervadec 等al., 2019),以及最近的复合损失。复合损失结合了多个独立的损失函数,例如 Combo 损失,它是 Dice 和交叉熵损失的总和(Taghanaki 等人,2019)。
医学图像分割中的一个主要问题是处理类别不平衡,这是指前景和背景元素的分布不均。例如,自动器官分割通常涉及比扫描本身小一个数量级的器官大小,从而导致有利于背景元素的偏态分布(Roth et al., 2015)。这个问题在肿瘤学中更为普遍,其中肿瘤大小本身通常明显小于相关的起源器官。
塔哈纳基等人(2019)区分输入和输出不平衡,前者如前所述,后者指的是推理过程中产生的分类偏差。其中包括假阳性和假阴性,它们分别描述了错误归类为前景对象的背景像素和错误归类为背景的前景对象。两者在医学图像分割的背景下都特别重要;在图像引导干预的情况下,假阳性可能会导致更大的放射野或过度的手术切缘,反之,假阴性可能会导致放射输送不足或手术切除不完全。因此,设计一个可以优化以处理输入和输出不平衡的损失函数非常重要.
尽管它很重要,但仔细选择损失函数并不是普遍的做法,并且通常选择次优的损失函数会产生性能影响。为了告知损失函数的选择,进行大规模的损失函数比较很重要。在 CVC-EndoSceneStill(胃肠息肉分割)数据集上比较了七种损失函数,其中基于区域的损失表现最佳,反之,交叉熵损失表现最差(S´anchez-Peralta 等人,2020)。同样,使用 NBFS Skull-stripped 数据集 (Jadon, 2020)(脑 CT 分割)对 15 个损失函数进行比较,该数据集还引入了 log-cosh Dice 损失,得出的结论是 Focal Tversky 损失和 Tversky 损失,都是基于区域的损失,通常是最佳的(Jadon,2020)。迄今为止最全面的损失函数比较进一步支持了这一点,在四个数据集(肝脏、肝脏肿瘤、胰腺和多器官分割)中比较了 20 个损失函数,观察到基于复合损失的最佳性能,其中使用 DiceTopK 和 DiceFocal 损失观察到最一致的性能(Ma et al., 2021)。从这些研究中可以明显看出,与基于分布的损失相比,基于区域或复合损失的表现始终更好。然而,不太清楚的是选择基于区域或复合损失中的哪一个,上述之间没有达成一致。一个主要的混杂因素是数据集中的类别不平衡程度,NBFS Skull-stripping 数据集中的类别不平衡程度较低,而在(马等人,2021)CVC-EndoSceneStill 数据集中的类别不平衡程度适中。
在医学影像数据集中,那些涉及肿瘤分割的数据集与高度的类别不平衡有关。手动描绘肿瘤既耗时又依赖操作者。肿瘤描绘的自动方法旨在解决这些问题,以及公共数据集,例如针对乳腺肿瘤的 Breast Ultrasound 2017 (BUS2017) 数据集 (Yap et al., 2017)、针对肾脏肿瘤的肾脏肿瘤分割 19 (KiTS19) 数据集 ( Heller 等人,2019 年)和针对脑肿瘤的脑肿瘤分割 2020(BraTS20)(Menze 等人,2014 年)加快了实现这一目标的进程。事实上,最近在将 BraTS20 数据集转化为临床和科学实践方面取得了进展(Kofler 等人,2020 年)。
BUS2017 数据集的当前最先进的模型包含注意力门,通过使用来自门控信号的上下文信息来细化跳过连接,突出显示感兴趣的区域,这可能会在类别不平衡的情况下提供好处(Abraham 和 Khan,2019 )。除了注意力门之外,RDAU-NET 还结合了残差单元和扩张卷积来分别增强信息传递和增加感受野,并使用 Dice 损失进行训练(Zhuang et al., 2019)。多输入注意力 U-Net 将注意力门与深度监督相结合,并引入了 Focal Tversky 损失,这是一种基于区域的损失函数,旨在处理类不平衡(Abraham 和 Khan,2019)。
对于 BraTS20 数据集,一种流行的方法是使用多尺度架构,其中不同的感受野大小允许独立处理本地和全局上下文信息(Kamnitsas 等人,2017;Havaei 等人,2017)。 Kamnitsas 等人。 (2017)使用了一个两阶段的训练过程,包括对代表性不足的类进行初始上采样,然后是第二阶段,其中输出层在更具代表性的样本上进行重新训练。同样,Havaei 等人。 (2017)使用采样规则在补丁中心施加相等概率的前景或背景像素,并使用交叉熵损失进行优化。
对于 KiTS19 数据集,当前最先进的是“no-newNet”(nnU-Net)(Isensee 等人,2021,2018),这是一种自动配置的基于深度学习的分割方法,涉及集成2D、3D 和级联 3D U-Nets。该框架使用 Dice 和交叉熵损失进行了优化。最近,一种基于集成的方法获得了与 nnU-Net 相当的结果,并涉及通过使用 Dice 损失训练的 2D U-Nets 对肾器官和肾肿瘤分割进行初始独立处理,然后抑制肾肿瘤分割的假阳性预测使用经过训练的肾器官分割网络进行心理分析(Fatemeh 等人,2020 年)。当数据集大小较小时,使用 CNN 校正标签的基于主动学习的方法(也使用 Dice 损失进行训练)的结果显示出比 nnU-Net 更高的分割精度(Kim 等人,2020)。
很明显,对于所有三个数据集,类不平衡主要通过改变训练或输入数据采样过程来处理,很少通过调整损失函数来解决。然而,流行的方法——例如对代表性不足的类进行上采样——本质上与误报预测的增加有关,而且更复杂的、通常是多阶段的训练过程需要更多的计算资源。
最先进的解决方案通常使用未修改版本的 Dice 损失、交叉熵损失或两者的组合,即使使用可用的损失函数来处理类不平衡,例如 Focal Tversky 损失,也能持续提高尚未观察到的性能(Ma et al., 2021)。决定使用哪个损失函数很困难,因为不仅有大量损失函数可供选择,而且还不清楚每个损失函数如何相互关联。了解损失函数之间的关系是提供启发式方法以在类不平衡情况下告知损失函数选择的关键。
在本文中,我们提出以下贡献:
1、我们总结和扩展了先前研究提供的知识,这些研究比较了损失函数以解决类不平衡的上下文,通过使用具有不同程度的类不平衡的五个类不平衡数据集,包括 2D 二进制、3D 二进制和 3D 多类分割,跨越多个成像方式。
2、我们定义了 Dice 和基于交叉熵的损失函数的层次分类,并使用它来推导统一Focal损失,它概括了基于 Dice 和基于交叉熵的损失函数来处理类不平衡数据集。
3、我们提出的损失函数始终如一地提高了其他六个相关损失函数的分割质量,与更好的召回精度平衡相关,并且对类别不平衡具有鲁棒性。
论文组织如下。第 2 节总结了所使用的损失函数,包括提议的统一Focal损失。第 3 节描述了所选的医学成像数据集并定义了使用的分割评估指标。第 4 节介绍并讨论了实验结果。最后,第 5 节提供了结论性评论和未来方向。
Background
损失函数定义了优化问题,直接影响训练过程中的模型收敛。本文重点关注语义分割,这是图像分割的一个子领域,其中直接执行像素级分类,与需要额外对象检测阶段的实例分割形成对比。我们描述了七种损失函数,它们属于基于分布、基于区域或基于两者组合的复合损失。图 1 提供了这些类别中损失函数的图形概述,以及如何从统一Focal损失中推导出来。首先,介绍了基于分布的函数,然后是基于区域的损失函数,最后得出结论具有复合损失函数。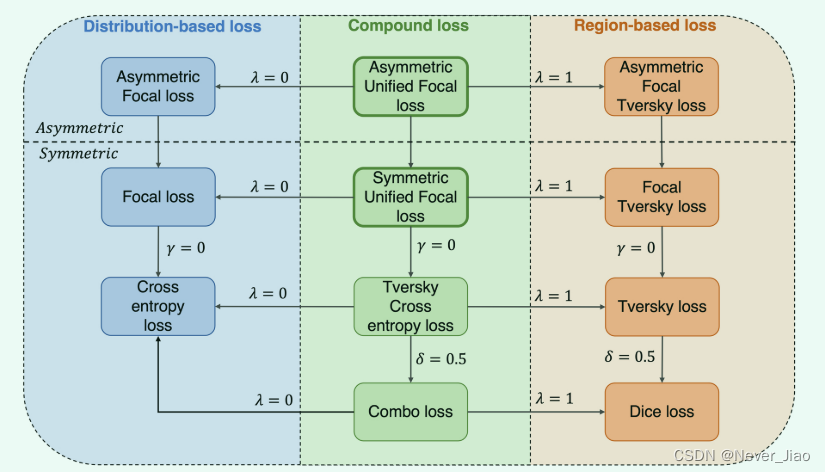
Fig.1 我们提出的框架统一了各种基于分布、基于区域和复合损失函数。箭头和相关的超参数值表示为前面的损失函数设置所需的超参数值,以便恢复得到的损失函数。
Cross entropy loss
交叉熵损失是深度学习中使用最广泛的损失函数之一。起源于信息论,交叉熵测量给定随机变量或事件集的两个概率分布之间的差异。作为一个损失函数,它表面上等同于负对数似然损失,对于二元分类,二元交叉熵损失 (LBCE) 定义如下: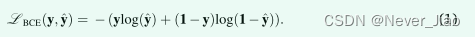
这里,y, ^y ∈ {0, 1} N,其中 ^y 指的是预测值,y 指的是 ground truth 标签。这可以扩展到多类问题,分类交叉熵损失(LCCE)计算为: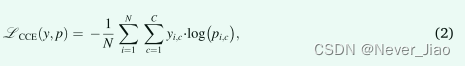
其中 yi,c 使用ground truth标签的 one-hot 编码方案,pi,c 是每个类的预测值矩阵,其中索引 c 和 i 分别迭代所有类和像素。交叉熵损失基于最小化像素级误差,在类不平衡的情况下,会导致损失中较大对象的过度表示,从而导致较小对象的分割质量较差。
Focal loss
使用标准交叉熵损失来解决类不平衡问题,方法是降低简单示例的贡献,从而能够学习更难的示例(Lin et al., 2017)。为了推导出 Focal 损失函数,我们首先简化方程1中的损失为: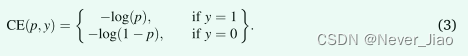
接下来,我们将预测ground truth class pt的概率定义为:
因此,二元交叉熵损失 (LBCE) 可以重写为:
Focal loss (LF) 为二元交叉熵损失添加了一个调制因子:
Focal loss由α和γ参数化,它们分别控制易于分类像素的类权重和降低加权程度(图2)。当 γ = 0 时,Focal loss 简化为二元交叉熵损失。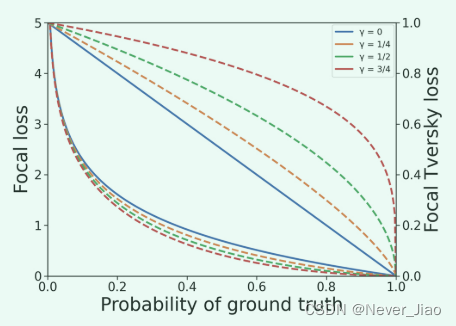
Fig.2 用统一Focal损失改变 γ 的影响。顶部和底部的曲线组分别与 Focal Tversky loss 和 Focal loss 有关。虚线表示具有修改的 Focal Tversky 损失和修改的 Focal 损失分量的不同 γ 值。
对于多类分割,我们定义分类 Focal loss(LCF):
其中 α 现在是类权重的向量,pt,c 是每个类的真实概率矩阵,LCCE 是等式2中定义的分类交叉熵损失。
Dice loss
Sørensen-Dice 指数在应用于布尔数据时称为 Dice 相似系数 (DSC),是评估分割准确度的最常用指标。我们可以根据真阳性 (TP)、假阳性 (FP) 和假阴性 (FN) 的每个体素分类来定义 DSC:
因此,Dice损失 (LDSC) 可以定义为:
Dice 损失的其他变体包括广义 Dice 损失(Crum 等人,2006;Sudre 等人,2017),其中类权重通过其体积的倒数进行校正,以及广义 Wasser stein Dice 损失(Fidon 等人., 2017),它将 Wasserstein 度量与 Dice 损失相结合,适用于处理分层数据,例如 BraTS20 数据集 (Menze et al., 2014)。
即使在最简单的公式中,Dice 损失在某种程度上也适用于处理类不平衡。然而,Dice 损失梯度本质上是不稳定的,最明显的是高度不平衡的数据,其中梯度计算涉及小分母(Wong 等人,2018;Bertels 等人,2019)。
Tversky loss
Tversky 指数 (Salehi et al., 2017) 与 DSC 密切相关,但可以通过将权重 α 和 β 分别分配给假阳性和假阴性来优化输出不平衡: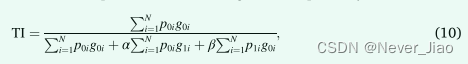
其中 p0i 是像素 i 属于前景类的概率,p1i 是像素属于背景类的概率。 g0i 为 1 表示前景,0 表示背景,相反 g1i 取值为 1 表示背景,0 表示前景。
使用 Tversky 索引,我们将 C 类的 Tversky 损失 (LT) 定义为:
当 Dice 损失函数应用于类不平衡问题时,生成的分割通常表现出高精度但召回分数低(Salehi 等人,2017)。为假阴性分配更大的权重可以提高召回率,并更好地平衡准确率和召回率。因此,β 通常设置为高于 α,最常见的是 β = 0.7 和 α = 0.3。
不对称相似性损失源自 Tversky 损失,但使用 Fβ 分数并将 α 替换为 1/1+β2 和 β 替换 β2 /1+β2,添加了 α 和 β 必须总和为 1 的约束(Hashemi et al., 2018 )。在实践中,选择 Tversky 损失的 α 和 β 值,使它们总和为 1,使两个损失函数在功能上等效。
Focal Tversky loss
受交叉熵损失的 Focal loss 适应的启发,Focal Tversky loss (Abraham and Khan, 2019) 通过应用一个focal参数来适应 Tversky 损失。
使用方程式10中的 TI 定义,如图 10 所示,Focal Tversky 损失定义(LFT)为:
其中 γ < 1 增加了对更难示例的关注程度。当 γ = 1 时,Focal Tversky 损失简化为 Tversky 损失。然而,与 Focal 损失相反,报告的最佳值是 γ = 4∕3,它增强而不是抑制简单示例的损失。实际上,在训练结束时,大多数示例被更自信地分类并且 Tversky 指数接近 1,增强该区域的损失会保持更高的损失,这可能会防止过早收敛到次优解决方案。
Combo loss
Combo 损失 (Taghanaki et al., 2019) 属于复合损失类,其中多个损失函数被统一最小化。组合损失 (Lcombo) 定义为方程8中 DSC 的加权和 和交叉熵损失(LmCE)的修改形式:
其中,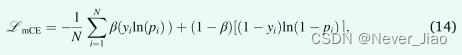
α ∈ [0,1] 控制 Dice 和交叉熵项对损失的相对贡献,β 控制分配给假阳性和阴性的相对权重。 β > 0.5 的值对假阴性预测的惩罚比对假阳性的惩罚更大。
令人困惑的是,“Dice和交叉熵损失”一词已被用来指代交叉熵损失和 DSC 的总和(Taghanaki 等人,2019;Isensee 等人,2018),以及交叉熵损失的总和熵损失和 Dice 损失,例如 DiceFocal 损失和 Dice 以及加权交叉熵损失 (Zhu et al., 2019b; Chen et al., 2019)。在这里,我们决定使用前一个定义,这与组合损失和 KiTS19 数据集的最新技术中使用的损失函数一致(Isensee 等人,2018 年)。
Hybrid Focal loss
Combo 损失 (Taghanaki et al., 2019) 和 DiceFocal 损失 (Zhu et al., 2019b) 是两个复合损失函数,它们继承了 Dice 和基于交叉熵的损失函数的好处。然而,在类别不平衡的情况下,两者都没有充分利用优势。 Combo 损失和 DiceFocal 损失在交叉熵分量损失中分别具有可调的 β 和 α 参数,对输出不平衡具有部分鲁棒性。但是,两者都缺乏 Dice 分量损失的等效项,其中正样本和负样本的权重相同。类似地,两种损失的 Dice 组件都不适用于处理输入不平衡,尽管 DiceFocal 损失更好地适应其在 Focal 损失组件中的focal参数。
为了克服这个问题,我们之前提出了混合focal损失函数,它结合了可调节参数来处理输出不平衡,以及用于处理输入不平衡的focal参数,用于 Dice 和基于交叉熵的分量损失(Yeung 等人,2021 )通过将 Dice 损失替换为 Focal Tversky 损失,并将交叉熵损失替换为 Focal 损失,混合focal损失 (LHF) 定义为:
其中 λ ∈ [0,1] 并确定两个分量损失函数的相对权重。
Unified Focal loss
Hybrid Focal loss 同时适应了 Dice 和基于交叉熵的损失来处理类不平衡。然而,在实践中使用混合Focal损失有两个主要问题。首先,有六个超参数需要调整:来自 Focal 损失的 α 和 γ,来自 Focal Tversky 损失的 α / β 和 γ,以及用于控制两个分量损失的相对权重的 λ。虽然这允许更大程度的灵活性,但这是以显著更大的超参数搜索空间为代价的。第二个问题是所有Focal损失函数共有的,其中Focal参数引入的增强或抑制效果应用于所有类,这可能会影响训练结束时的收敛。
Unified Focal loss 解决了这两个问题,通过将功能等效的超参数组合在一起并利用不对称性来分别集中在修改后的 Focal loss 和 Focal Tversky 损失分量中的focal参数的抑制和增强效果。
首先,我们将 Focal loss 中的 α 和 Tversky Index 中的 α 和 β 替换为共同的 δ 参数以控制输出不平衡,并重新公式化 γ 以同时实现 Focal loss 抑制和 Focal Tversky loss 增强,将这些命名为修改后的 Focal loss ( LmF) 和修正的 Focal Tversky 损失 (LmFT),分别为:
其中,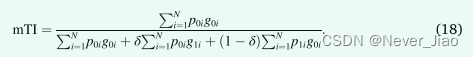
因此,Unified Focal loss (LsUF) 的对称变体定义为:
其中 λ ∈ [0,1] 并确定两个损失的相对权重。通过对功能等效的超参数进行分组,与 Hybrid Focal loss 相关的六个超参数减少到三个,其中 δ 控制正例和负例的相对权重,γ 控制背景类的抑制和稀有类的增强,最后是 λ确定两个分量损失的权重。
虽然 Focal loss 实现了对背景类的抑制,但由于将focal参数应用于所有类,因此稀有类贡献的损失也被抑制了。不对称通过为每个类分配不同的损失来使用focal参数进行选择性增强或抑制,这克服了稀有类的有害抑制和背景类的增强。修改后的非对称焦点损失 (LmaF) 移除了与稀有类 r 相关的损失分量的焦点参数,同时保留了对背景元素的抑制 (Li et al., 2019):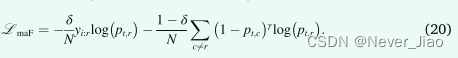
相比之下,对于修改后的 Focal Tversky 损失,我们删除了与背景相关的损失分量的焦点参数,保留了稀有类 r 的增强,并将修改后的非对称 Focal Tversky 损失(LmaFT)定义为: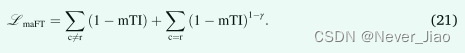
因此,Unified Focal loss (LaUF) 的不对称变体定义为:
与 Focal 损失相关的损失抑制问题通过与 Focal Tversky 损失的互补配对得到缓解,不对称性能够同时实现背景损失抑制和前景损失增强,类似于增加信噪比(图 2)。
通过结合先前损失函数的想法,Unified Focal loss将基于 Dice 和基于交叉熵的损失函数推广到单个框架中。事实上,可以证明到目前为止描述的所有基于 Dice 和交叉熵的损失函数都是Unified Focal loss的特例(图 1)。例如,通过设置 γ = 0 和 δ = 0.5,分别在 λ 设置为 0 和 1 时恢复 Dice 损失和交叉熵损失。通过明确损失函数之间的关系,Unified Focal loss 比单独尝试不同的损失函数更容易优化,而且它也更强大,因为它对输入和输出不平衡都具有鲁棒性。重要的是,鉴于 Dice 损失和交叉熵损失都是有效的操作,并且应用focal参数增加的时间复杂度可以忽略不计,Unified Focal loss预计不会显着增加其分量损失函数的训练时间。
在实践中,Unified Focal loss的优化可以进一步简化为单个超参数。鉴于focal参数对每个组件损失的不同影响,λ 的作用是部分冗余的,因此我们建议设置 λ = 0.5,它为每个组件损失分配相等的权重,并得到经验证据的支持(Taghanaki 等人, 2019)。此外,我们建议设置 δ = 0.6,以纠正 Dice 损失趋势,以产生高精度、低召回率且类别不平衡的分割。这在 Tversky 损失中小于 δ = 0.7,以解释基于交叉熵的分量的影响。这种将超参数搜索空间启发式减少到单个 γ 参数的做法使得Unified Focal loss既强大又易于优化。我们为补充材料中的Unified Focal loss提供了这些启发式方法背后的进一步经验证据。
Materials and methods
Dataset descriptions and evaluation metrics
我们为我们的实验选择了五类不平衡的医学成像数据集:CVC-ClinicDB、DRIVE、BUS2017、KiTS19 和 BraTS20。为了评估类别不平衡的程度,每张图像计算前景像素/体素的百分比,并在整个数据集上取平均值(表 1)。
CVC-ClinicDB dataset
结肠镜检查是结直肠癌的金标准筛查工具,但与显著的息肉漏诊率相关,这为利用计算机辅助系统支持临床医生减少漏诊的息肉数量提供了机会(Kim 等,2017)。我们使用 CVC-ClinicDB 数据集,该数据集由 612 帧组成,其中包含图像分辨率为 288 × 384 像素的息肉,由来自 13 名不同患者的 23 个视频序列生成,使用标准结肠镜检查和白光干预(Bernal 等,2015)。
DRIVE dataset
退行性视网膜疾病在眼底镜检查中显示出可用于帮助诊断的特征。特别是,视网膜血管异常,如迂曲度或新血管形成的变化为分期和治疗计划提供了重要线索。我们选择了 DRIVE 数据集 (Staal 等人,2004),它由 40 张从荷兰糖尿病视网膜病变筛查中获得的彩色眼底照片组成,使用分辨率为 768 × 584 的每个彩色平面 8 位拍摄。33 张照片显示没有糖尿病迹象视网膜病变,而 7 张照片显示轻度糖尿病视网膜病变的迹象。
BUS2017 dataset
最常用的乳腺癌评估筛查工具是数字乳房 X 线照相术。然而,致密的乳腺组织通常见于年轻患者,在乳房 X 线摄影中很难看到。一个重要的替代方法是超声成像,这是一种依赖操作者的程序,需要熟练的放射科医师,但与乳房 X 线照相术不同,它具有无辐射暴露的优点。 BUS2017 数据集 B 由 163 个 ul 超声图像和相关的ground truth分割组成,平均图像大小为 760 × 570 像素,从西班牙萨瓦德尔 Parc Taulí 公司的 UDIAT 诊断中心收集。 110 个图像是良性病变,包括 65 个未指明的囊肿、39 个纤维腺瘤和 6 个来自其他良性类型的病变。其他 53 幅图像描绘了癌性肿块,其中大部分是浸润性导管癌。
BraTS20 dataset
BraTS20 数据集是目前用于医学图像分割的最大的、公开可用且完全注释的数据集(Nazir 等人,2021 年),包括 494 份低级别胶质瘤或高级别胶质母细胞瘤患者的多模态扫描(Menze 等人, 2014;巴卡斯等人,2017、2018)。 BraTS20 数据集为以下 MRI 序列提供图像:T1 加权 (T1)、使用钆造影剂 (T1-CE) 增强的 T1 加权对比 (T1-CE)、T2 加权 (T2) 和流体衰减反向恢复 (FLAIR) 序列。图像被手动注释,与肿瘤相关的区域标记为:坏死和非增强肿瘤核心、瘤周水肿或钆增强肿瘤。在提供的 494 次扫描中,有 125 次扫描用于验证,参考分割掩码禁止公共访问,因此被排除在外。为了定义二元分割任务,我们进一步排除了 T1、T2 和 FLAIR 序列,以专注于使用 T1-CE 序列(Rundo 等人,2019b;Han 等人,2019)的钆增强肿瘤分割,这不仅似乎是最难分割的类别 (Henry et al., 2020),但也是与放射治疗最相关的临床类别 (Rundo et al., 2017, 2018)。我们进一步排除了另外 27 次扫描而不增强肿瘤区域,留下 342 次扫描,图像分辨率为 240 × 240 × 155 体素。
KiTs19 dataset
由于低密度组织的广泛存在以及 CT 上肿瘤的高度异质性外观,肾肿瘤分割是一项具有挑战性的任务(Linguraru 等人,2009;Rundo 等人,2020a)。为了评估我们的损失函数,我们选择了 KiTS19 数据集 (Heller et al., 2019),这是一个高度不平衡的多类分类问题。简而言之,该数据集由美国明尼苏达大学医学中心接受部分切除肿瘤和周围肾脏或完全切除包括肿瘤在内的肾脏的患者的 300 份动脉期腹部 CT 扫描组成。图像大小为轴向平面512×512像素,冠状平面平均216个切片。肾脏和肿瘤边界由两名学生手动划分,肾脏、肿瘤或背景的类标签分配给每个体素,从而产生语义分割任务(Heller 等人,2019)。提供了 210 次扫描及其相关的分割用于训练,其他 90 次扫描的分割掩码禁止公开访问以进行测试。因此,我们排除了没有分割掩码的 90 次扫描,并进一步排除了另外 6 次扫描(案例 15、23、37、68、125 和 133),因为担心地面真实质量(Heller 等人,2021),剩下 204 次扫描利用。
Evaluation metrics
为了评估分割准确性,我们使用四种常用的指标(Wang et al., 2020):DSC、Intersection over Union (IoU)、召回率和精度。 DSC 在方程式8中定义,IoU、召回率和精度同样根据每个像素/体素并根据等式23、24 和 25定义,分别为:
Implementation details
所有实验均使用带有 TensorFlow 后端的 Keras 进行编程,并在 NVIDIA P100 GPU 上运行。我们使用了带有卷积神经网络的医学图像分割 (MIScnn) 开源 Python 库(Müller 和 Kramer,2019 年)。
来自 CVC-ClinicDB、DRIVE 和 BUS2017 数据集的图像分别以匿名的 tiff、jpeg 和 png 文件格式提供。对于 KiTS19 和 BraTS20 数据集,图像和ground truth分割掩码均以匿名 NIfTI 文件格式提供。对于所有数据集,除了最初划分为 20 个训练图像和 20 个测试图像的 DRIVE 数据集,我们将每个数据集随机划分为 80% 的开发集和 20% 的测试集,进一步将开发集划分为 80% 的训练集和20% 的验证集。使用 z-Score将所有图像标准化为 [0,1]。我们利用“batchgenerators”库以 0.15 的概率应用即时数据增强,包括:缩放(0.85 − 1.25 × )、旋转(-15∘ 到 +15∘)、镜像(垂直和水平轴) , 弹性变形 (α ∈ [0,900] and σ ∈ [9.0, 13.0]) 和亮度 (0.5 − 2 × )
对于 2D 二进制分割,我们使用 CVC-ClinicDB、DRIVE 和 BUS2017 数据集并执行全图像分析,图像大小如表 1 所述。对于 3D 二进制分割,我们使用了 BraTS20 数据集。在这里,图像被预处理,头骨被剥离,图像被插值到相同的各向同性分辨率 1 mm3,我们使用大小为96 × 96×96体素的随机patch进行patch分析,以进行训练,并以48 × 48×48体素的patch重叠进行推断。对于 3D 多类分割,我们使用了 KiTS19 数据集。将 Hounsfield 单位 (HU) 裁剪为 [ − 79, …, 304] HU,体素间距重新采样为 3.22 × 1.62 × 1.62 mm3 (Müller and Kramer, 2019)。我们使用大小为 80 × 160 × 160 体素的随机补丁进行补丁分析,并使用 40 × 80 × 80 体素的补丁重叠进行推理。
对于 2D 分割任务,我们使用原始的 2D U-Net 架构 (Ronneberger et al., 2015),对于 3D 分割任务,我们使用 3D U-Net (Cicek et al., 2016)。模型参数使用 Xavier 初始化(Glorot 和 Bengio,2010)进行初始化,我们添加了实例归一化和最终的 softmax 激活层(Zhou 和 Yang,2019)。我们使用随机梯度下降优化器进行训练,批量大小为 2,初始学习率为 0.1。对于收敛标准,如果验证损失在 10 个 epoch 后没有改善,我们使用 ReduceLROnPlateau 将学习率降低 0.1,如果验证损失在 20 个 epoch 后没有改善,我们使用 EarlyStopping 回调终止训练。在每个 epoch 之后评估验证损失,选择验证损失最低的模型作为最终模型。
我们评估以下损失函数:交叉熵损失、focal损失、dice损失、Tversky损失、Focal Tversky损失、Comba损失以及Unified Focal损失的对称和非对称变体。我们使用原始研究中报告的每个损失函数的最佳超参数。具体来说,我们为 Focal 损失设置 α = 0.25 和 γ = 2(Lin 等人,2017),为 Tversky 损失设置 α = 0.3,β = 0.7(Salehi 等人,2017),α = 0.3,β = 0.7的Focal Tversky 损失和 γ = 4∕3(Abraham 和 Khan,2019),Combo 损失为 α = β = 0.5。对于Unified Focal Loss,我们设置 λ = 0.5, δ = 0.6,并对 2D 分割任务使用 γ ∈ [0.1, 0.9] 进行超参数调整,对于 3D 分割任务设置 γ = 0.5。
为了检验统计显着性,我们使用了 Wilcoxon 秩和检验。统计学上显着的差异定义为 p < 0.05。
Experimental results
在本节中,我们首先描述使用 CVC-ClinicDB、DRIVE 和 BUS2017 数据集的 2D 二进制分割的结果,然后使用 BraTS20 数据集进行 3D 二进制分割,最后使用 KiTS19 数据集进行 3D 多类分割。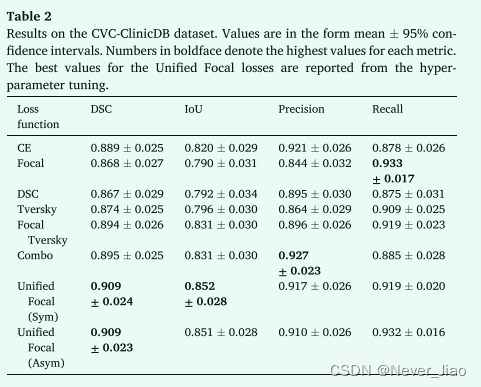
2D binary segmentation
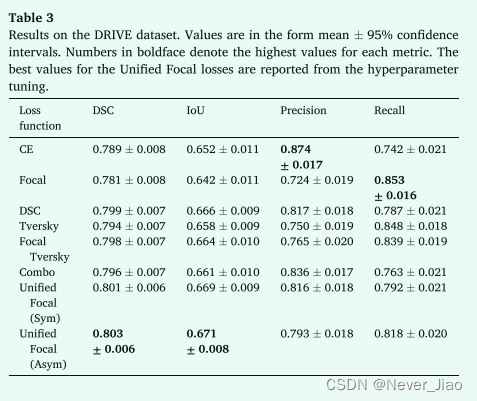
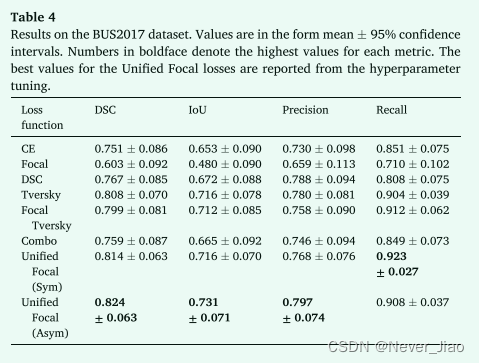
2D 二元分割实验的结果如表 2、3 和 4 所示。
在所有三个数据集中,Unified Focal loss的不对称变体始终观察到最佳性能,在 CVC-ClinicDB、DRIVE 和 BUS2017 数据集上分别实现了 0.909 ± 0.023、0.803 ± 0.006 和 0.824 ± 0.063 的 DSC。其次是Unified Focal loss的对称变体,它在 CVC-ClinicDB 数据集上获得了 0.852 ± 0.028 的最佳 IoU 得分,并且 DSC 得分与 DSC 为 0.909 ± 0.024、0.801 ± 0.006 和在 CVCClinicDB、DRIVE 和 BUS2017 数据集上为 0.814 ± 0.063。在这些数据集上,Unified Focal loss的两个变体之间没有观察到性能上的显着差异。一般来说,观察到基于交叉熵的损失函数的性能最差,Focal loss 在 CVCClinicDB (p = 0.04) 和 BUS2017 (p = 0.004) 数据集上的表现明显差于交叉熵损失,并且明显比三个数据集上Unified Focal loss的不对称变体(CVC-ClinicDB:p = 2×10-6,DRIVE:p = 110-4 和 BUS2017:p = 5×10-5)。在基于 Dice 的损失之间没有观察到显着差异。
为了评估 γ 超参数的性能稳定性,我们在图 3 中显示了 γ ∈ [0.1, 0.9] 的每个值的 DSC 性能。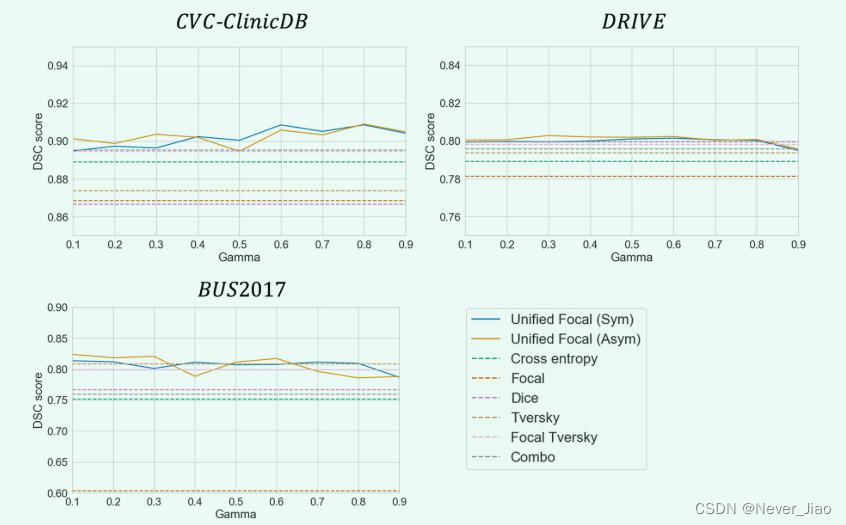
Fig.3 在每个数据集的 DSC 性能上使用Unified Focal loss评估 γ 的稳定性。实线代表Unified Focal loss的对称和不对称变体,作为参考,虚线代表其他损失函数的 DSC 性能。
对于对称和非对称变体,Unified Focal loss 在 γ ∈ [0.1, 0.9] 范围内表现出始终如一的强劲性能。这在 CVC-ClinicDB 数据集上最为明显,其中在整个超参数值范围内观察到与其他损失函数相比性能有所提高。最差的性能发生在 γ = 0.9 等高值时,而 γ = 0.5 等中等值则在跨数据集时提供了强大的性能优势。
为了进行定性比较,示例分割如图 4 所示。
使用不同损失函数生成的分割之间存在明显的视觉差异。与基于 Dice 的损失函数相比,基于交叉熵的损失函数的分割与更大比例的假阴性预测相关。最高质量的分割是由复合损失函数产生的,最好的分割是使用统一焦点损失产生的。这一点在 CVC-ClinicDB 示例中的统一焦点损失的非对称变体中尤为明显。
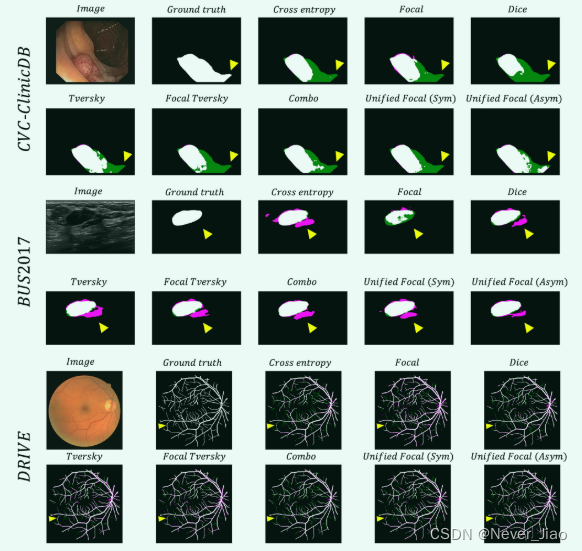
Fig.4 示例分割,用于三个数据集中的每一个的每个损失函数。提供图像和ground truth以供参考。假阳性以洋红色突出显示,假阴性以绿色突出显示。黄色箭头突出显示分割质量不同的示例区域。
3D binary segmentation
3D 二元分割实验的结果如表 5 所示。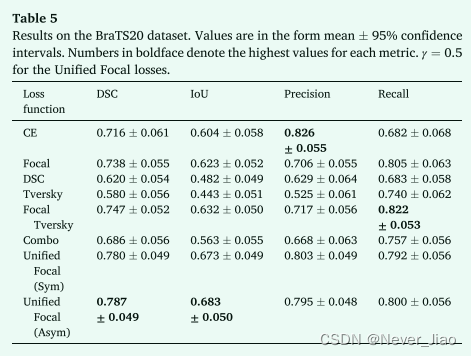
使用统一焦点损失观察到最佳性能,特别是不对称变体,DSC 为 0.787 ± 0.049,IoU 为 0.683 ± 0.050,精度为 0.795 ± 0.048,召回率为 0.800 ± 0.056。接下来是统一焦点损失的对称变体,两个损失函数之间没有显着差异。相比之下,与所有其他损失函数相比,非对称统一焦点损失显示出显着提高的性能(交叉熵损失:p = 0.02,焦点损失:p = 0.03,骰子损失:p = 6×10− 10,Tversky 损失:p = 5×10− 11,Focal Tversky loss: p = 0.02 and Combo loss: p = 1×10− 4)。
从示例分割中获取的轴向切片如图 5 所示。
从结果来看,该数据集存在明显的召回偏差,这反映在每个分割预测的假阳性预测比例上。复合损失函数显示出最佳的召回精度平衡,这可以从使用这些损失函数产生的分割中明显减少的假阳性预测中明显看出。
3D multiclass segmentation
3D 多类分割实验的结果如表 6 所示。
Unified Focal loss 达到最佳性能,对于肾脏和肾脏肿瘤分割,不对称变体的 DSC 分别为 0.943 ± 0.011 和 0.634 ± 0.079,而对称变体的 DSC 分别为 0.943 ± 0.013 和 0.614 ± 0.079。对于肾脏分割,与交叉熵损失 (p = 0.03)、Focal 损失 (p = 0.004)、Tversky 损失 (p = 0.001) 和 Focal Tversky 损失相比,Unified Focal loss 的不对称变体实现了显著改进的性能。 p = 0.03)。使用基于 Dice 的损失观察到肾脏分割的最差性能,Tversky 损失其次是 Focal Tversky 损失。相比之下,使用基于交叉熵的损失观察到肾肿瘤分割的最差性能,与交叉熵损失相比,使用 Dice 损失的 DSC 性能明显更好(p = 0.01)。对于肾肿瘤分割,与交叉熵损失(p = 6×10 - 5)、焦点损失(p = 1×10 - 4)、骰子损失(p < 0.05) 和 Tversky 损失 (p = 4×10 - 4)。
从示例分割中获取的轴向切片如图 5 所示。
虽然肾脏通常被很好地分割,损失函数之间只有细微的差异,但肿瘤分割的质量差异很大。具有基于交叉熵的损失函数的低肿瘤召回分数反映在分割中,其中肿瘤和肾脏之间的边界发生了转移,有利于肾脏预测。通过统一焦点损失观察到最高质量的分割,具有明显最准确的肿瘤轮廓。
Discussion and conclusions
在这项研究中,我们提出了一个新的分层框架来包含各种 Dice 和基于交叉熵的损失函数,并用它来推导Unified Focal loss,它概括了 Dice 和基于交叉熵的损失函数来处理类不平衡。我们在涉及 2D 二进制、3D 二进制和 3D 多类分割的五个类别不平衡数据集(CVC ClinicDB、DRIVE、BUS2017、BraTS20 和 KiTS19)上将Unified Focal loss与其他六个损失函数进行了比较。Unified Focal loss在五个数据集中始终获得最高的 DSC 和 IoU 分数,使用不对称度量变体观察到的性能略好于对称变体。我们证明了Unified Focal loss的优化可以简化为调整单个 γ 超参数,我们观察到它是稳定的,因此易于优化(图 3)。
使用不同损失函数的模型性能的显着差异凸显了损失函数选择在类不平衡图像分割任务中的重要性。最引人注目的是使用基于分布的损失函数在高度不平衡的 KiTS19 数据集上分割肾肿瘤类别的性能不佳(表 6)。鉴于在基于交叉熵的损失中占据更大区域的类的更大代表性,这种对类不平衡的敏感性是预期的。一般来说,基于 Dice 的损失函数和复合损失函数在类不平衡数据上表现更好,但一个值得注意的例外是 BraTS20 数据集,其中 Dice 损失和 Tversky 损失的表现明显低于其他损失函数。这可能反映了与 Dice 损失相关的不稳定梯度问题,从而导致次优收敛并导致性能不佳。复合损失函数(例如 Combo loss 和 Unified Focal loss)在数据集上始终表现良好,这得益于基于交叉熵的组件增加的梯度稳定性,以及基于 Dice 的组件对类别不平衡的鲁棒性。定性评估与性能指标相关,使用统一焦点损失观察到的最高质量分割(图 4-6)。正如预期的那样,在这些实验中使用的任何损失函数之间都没有观察到训练时间的差异。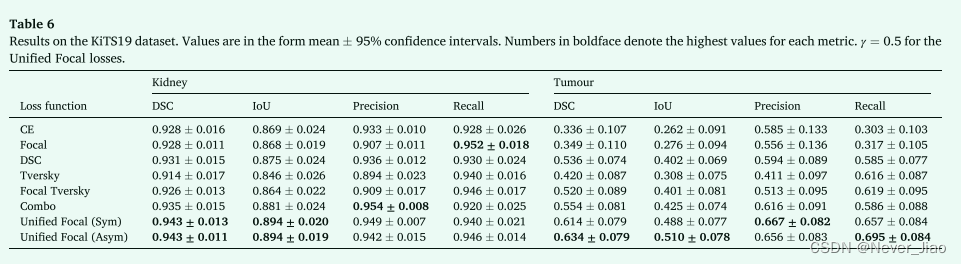
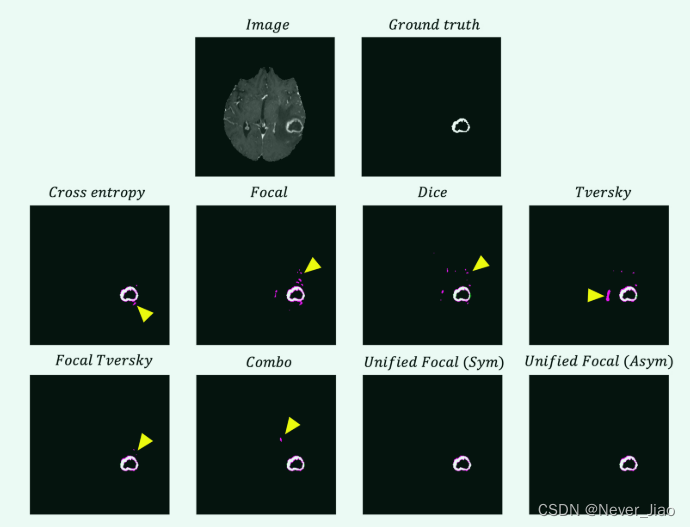
Fig.5 BraTS20 数据集的每个损失函数的示例分割的轴向切片。提供图像和ground truth 以供参考。假阳性以洋红色突出显示,假阴性以绿色突出显示。黄色箭头突出显示分割质量不同的示例区域。
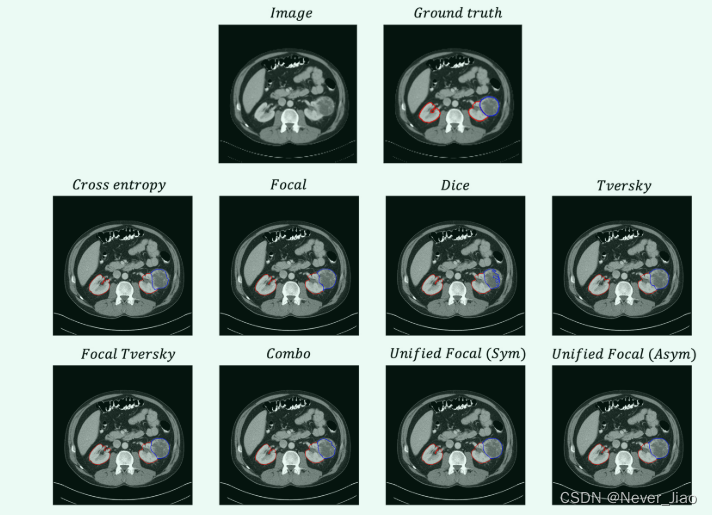
Fig.6 KiTS19 数据集的每个损失函数的示例分割的轴向切片。提供图像和ground truth以供参考。红色轮廓对应肾脏,蓝色轮廓对应肿瘤。
我们的研究存在一些局限性。首先,我们将我们的框架和比较限制为仅包括基于 Dice 和基于交叉熵的损失函数的最流行变体的一个子集。然而,需要注意的是,Unified Focal loss 还泛化了其他未包含的损失函数,例如 DiceFocal loss (Zhu et al., 2019b) 和 Asymmetricsimilarity loss (Hashemi et al., 2018)。未包括的一类主要损失函数是基于边界的损失函数(Kervadec 等人,2019;Zhu 等人,2019a),这是另一类损失函数,而是使用基于距离的指标来优化轮廓而不是分别比交叉熵和基于 Dice 的损失使用的分布或区域。其次,目前尚不清楚如何在多类分割任务中优化 γ 超参数。在我们的实验中,我们将肾脏和肾脏肿瘤都视为罕见类别,并指定 γ = 0.5。通过为每个类别分配不同的 γ 值可以观察到更好的性能,例如,KiTS19 数据集中的肾脏类别是肿瘤类别的四倍。但是,即使进行了这种简化,我们仍然使用统一焦点损失比其他损失函数获得了改进的性能。
最后,我们强调了未来研究的几个领域。为了告知类别不平衡分割的损失函数选择,重要的是比较更多数量和种类的损失函数,特别是来自其他损失函数类别和不同类别不平衡数据集的损失函数。我们使用原始的 U-Net 架构来简化并强调损失函数对性能的重要性,但评估性能增益是否可以推广到最先进的深度学习方法(例如 nnU- Net(Isensee 等人,2021 年)——以及这是否能够补充甚至替代替代方案,例如用于处理类不平衡的训练或基于抽样的方法。
边栏推荐
- [IELTS speaking] Anna's oral learning record part1
- SQL Server生成自增序号
- Leetcode: interview question 17.24 Maximum cumulative sum of submatrix (to be studied)
- leetcode:面试题 17.24. 子矩阵最大累加和(待研究)
- UDP编程
- 2014 Alibaba web pre intern project analysis (1)
- Jafka来源分析——Processor
- Unity3d minigame unity webgl transform plug-in converts wechat games to use dlopen, you need to use embedded 's problem
- 云原生技术--- 容器知识点
- 软考高级(信息系统项目管理师)高频考点:项目质量管理
猜你喜欢
【编译原理】做了一半的LR(0)分析器
C# 三种方式实现Socket数据接收

Web APIs DOM 时间对象

Heavyweight news | softing fg-200 has obtained China 3C explosion-proof certification to provide safety assurance for customers' on-site testing
Pit encountered by handwritten ABA
Improving Multimodal Accuracy Through Modality Pre-training and Attention
剑指offer刷题记录1
自制J-Flash烧录工具——Qt调用jlinkARM.dll方式

二分图判定
云原生技术--- 容器知识点
随机推荐
Should novice programmers memorize code?
UDP编程
网络基础入门理解
OpenSSL:适用TLS与SSL协议的全功能工具包,通用加密库
[leetcode] 19. Delete the penultimate node of the linked list
[linear algebra] determinant of order 1.3 n
Sizeof keyword
SQL server generates auto increment sequence number
How to use flexible arrays?
Aardio - integrate variable values into a string of text through variable names
Inno Setup 打包及签名指南
npm无法安装sharp
MySQL数据库基本操作-DML
ThreadLocal详解
Aardio - Method of batch processing attributes and callback functions when encapsulating Libraries
BasicVSR_PlusPlus-master测试视频、图片
2022-07-04 mysql的高性能数据库引擎stonedb在centos7.9编译及运行
Aardio - 利用customPlus库+plus构造一个多按钮组件
云原生技术--- 容器知识点
使用云服务器搭建代理