当前位置:网站首页>BasicVSR_PlusPlus-master测试视频、图片
BasicVSR_PlusPlus-master测试视频、图片
2022-07-06 15:00:00 【cv-daily】
代码:https://github.com/ckkelvinchan/BasicVSR_PlusPlus
BasicVSR_PlusPlus-master测试图片和是视频总是报out of memory,显存不够,但是又需要测试,修改代码。
修改restoration_video_demo.py
# Copyright (c) OpenMMLab. All rights reserved.
import argparse
import os
import cv2
import mmcv
import numpy as np
import torch
from mmedit.apis import init_model, restoration_video_inference
from mmedit.core import tensor2img
from mmedit.utils import modify_args
import time
VIDEO_EXTENSIONS = ('.mp4', '.mov')
def parse_args():
modify_args()
parser = argparse.ArgumentParser(description='Restoration demo')
parser.add_argument('config', help='test config file path')
parser.add_argument('checkpoint', help='checkpoint file')
parser.add_argument('input_dir', help='directory of the input video')
parser.add_argument('output_dir', help='directory of the output video')
parser.add_argument(
'--start-idx',
type=int,
default=0,
help='index corresponds to the first frame of the sequence')
parser.add_argument(
'--filename-tmpl',
default='{:08d}.png',
help='template of the file names')
parser.add_argument(
'--window-size',
type=int,
default=0,
help='window size if sliding-window framework is used')
parser.add_argument(
'--max-seq-len',
type=int,
default=None,
help='maximum sequence length if recurrent framework is used')
parser.add_argument('--device', type=int, default=0, help='CUDA device id')
args = parser.parse_args()
return args
def main():
""" Demo for video restoration models. Note that we accept video as input/output, when 'input_dir'/'output_dir' is set to the path to the video. But using videos introduces video compression, which lowers the visual quality. If you want actual quality, please save them as separate images (.png). """
args = parse_args()
model = init_model(
args.config, args.checkpoint, device=torch.device('cuda', args.device))
for i in range(10000):
start_idx=i
# time.sleep(500)
output = restoration_video_inference(model, args.input_dir,
args.window_size, start_idx,
args.filename_tmpl, args.max_seq_len)
torch.cuda.empty_cache()
time.sleep(10)
file_extension = os.path.splitext(args.output_dir)[1]
if file_extension in VIDEO_EXTENSIONS: # save as video
h, w = output.shape[-2:]
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(args.output_dir, fourcc, 25, (w, h))
for i in range(0, output.size(1)):
img = tensor2img(output[:, i, :, :, :])
video_writer.write(img.astype(np.uint8))
cv2.destroyAllWindows()
video_writer.release()
else:
for i in range(args.start_idx, args.start_idx + output.size(1)):
output_i = output[:, i - args.start_idx, :, :, :]
output_i = tensor2img(output_i)
print(args.filename_tmpl.format(start_idx))
# save_path_i = f'{args.output_dir}/{args.filename_tmpl.format(i)}'
save_path_i = f'{
args.output_dir}/{
args.filename_tmpl.format(start_idx)}'
mmcv.imwrite(output_i, save_path_i)
if __name__ == '__main__':
main()
修改restoration_video_inference.py
# Copyright (c) OpenMMLab. All rights reserved.
import glob
import os.path as osp
import re
from functools import reduce
import mmcv
import numpy as np
import torch
from mmedit.datasets.pipelines import Compose
VIDEO_EXTENSIONS = ('.mp4', '.mov')
def pad_sequence(data, window_size):
padding = window_size // 2
data = torch.cat([
data[:, 1 + padding:1 + 2 * padding].flip(1), data,
data[:, -1 - 2 * padding:-1 - padding].flip(1)
],
dim=1)
return data
def restoration_video_inference(model,
img_dir,
window_size,
start_idx,
filename_tmpl,
max_seq_len=None,
):
"""Inference image with the model. Args: model (nn.Module): The loaded model. img_dir (str): Directory of the input video. window_size (int): The window size used in sliding-window framework. This value should be set according to the settings of the network. A value smaller than 0 means using recurrent framework. start_idx (int): The index corresponds to the first frame in the sequence. filename_tmpl (str): Template for file name. max_seq_len (int | None): The maximum sequence length that the model processes. If the sequence length is larger than this number, the sequence is split into multiple segments. If it is None, the entire sequence is processed at once. Returns: Tensor: The predicted restoration result. """
device = next(model.parameters()).device # model device
# build the data pipeline
if model.cfg.get('demo_pipeline', None):
test_pipeline = model.cfg.demo_pipeline
elif model.cfg.get('test_pipeline', None):
test_pipeline = model.cfg.test_pipeline
else:
test_pipeline = model.cfg.val_pipeline
print(img_dir)
# check if the input is a video
file_extension = osp.splitext(img_dir)[1]
if file_extension in VIDEO_EXTENSIONS:
video_reader = mmcv.VideoReader(img_dir)
# load the images
data = dict(lq=[], lq_path=None, key=img_dir)
for frame in video_reader:
data['lq'].append(np.flip(frame, axis=2))
# remove the data loading pipeline
tmp_pipeline = []
for pipeline in test_pipeline:
if pipeline['type'] not in [
'GenerateSegmentIndices', 'LoadImageFromFileList'
]:
tmp_pipeline.append(pipeline)
test_pipeline = tmp_pipeline
else:
# the first element in the pipeline must be 'GenerateSegmentIndices'
if test_pipeline[0]['type'] != 'GenerateSegmentIndices':
raise TypeError('The first element in the pipeline must be '
f'"GenerateSegmentIndices", but got '
f'"{
test_pipeline[0]["type"]}".')
# specify start_idx and filename_tmpl
print('start_idx', start_idx)
print('filename_tmpl', filename_tmpl)
test_pipeline[0]['start_idx'] = start_idx
test_pipeline[0]['filename_tmpl'] = filename_tmpl
# prepare data
# sequence_length = len(glob.glob(osp.join(img_dir, '*')))
sequence_length = 1
img_dir_split = re.split(r'[\\/]', img_dir)
print(img_dir)
key = img_dir_split[-1]
lq_folder = reduce(osp.join, img_dir_split[:-1])
print(lq_folder)
data = dict(
lq_path=lq_folder,
gt_path='',
key=key,
sequence_length=sequence_length)
# compose the pipeline
test_pipeline = Compose(test_pipeline)
data = test_pipeline(data)
print("data_lq",data['lq'].shape)
data = data['lq'].unsqueeze(0) # in cpu
data = data.unsqueeze(0) # in cpu
print("data",data.shape)
# forward the model
with torch.no_grad():
if window_size > 0: # sliding window framework
data = pad_sequence(data, window_size)
result = []
for i in range(0, data.size(1) - 2 * (window_size // 2)):
data_i = data[:, i:i + window_size].to(device)
result.append(model(lq=data_i, test_mode=True)['output'].cpu())
result = torch.stack(result, dim=1)
else: # recurrent framework
if max_seq_len is None:
result = model(
lq=data.to(device), test_mode=True)['output'].cpu()
else:
result = []
for i in range(0, data.size(1), max_seq_len):
result.append(
model(
lq=data[:, i:i + max_seq_len].to(device),
test_mode=True)['output'].cpu())
result = torch.cat(result, dim=1)
return result
边栏推荐
- 基于 QEMUv8 搭建 OP-TEE 开发环境
- Heavyweight news | softing fg-200 has obtained China 3C explosion-proof certification to provide safety assurance for customers' on-site testing
- Daily question 1: force deduction: 225: realize stack with queue
- 自制J-Flash烧录工具——Qt调用jlinkARM.dll方式
- Assembly and Interface Technology Experiment 6 - ADDA conversion experiment, AD acquisition system in interrupt mode
- 柔性数组到底如何使用呢?
- PVL EDI 项目案例
- The nearest common ancestor of binary (search) tree ●●
- MySQL数据库基本操作-DML
- labelimg的安装与使用
猜你喜欢

【数字IC手撕代码】Verilog无毛刺时钟切换电路|题目|原理|设计|仿真
Barcodex (ActiveX print control) v5.3.0.80 free version
Unity3d minigame-unity-webgl-transform插件转换微信小游戏报错To use dlopen, you need to use Emscripten‘s...问题
![[leetcode daily clock in] 1020 Number of enclaves](/img/2d/3d12f20c8c73fb28044c01be633c99.jpg)
[leetcode daily clock in] 1020 Number of enclaves
PVL EDI 项目案例

Web APIs DOM 时间对象
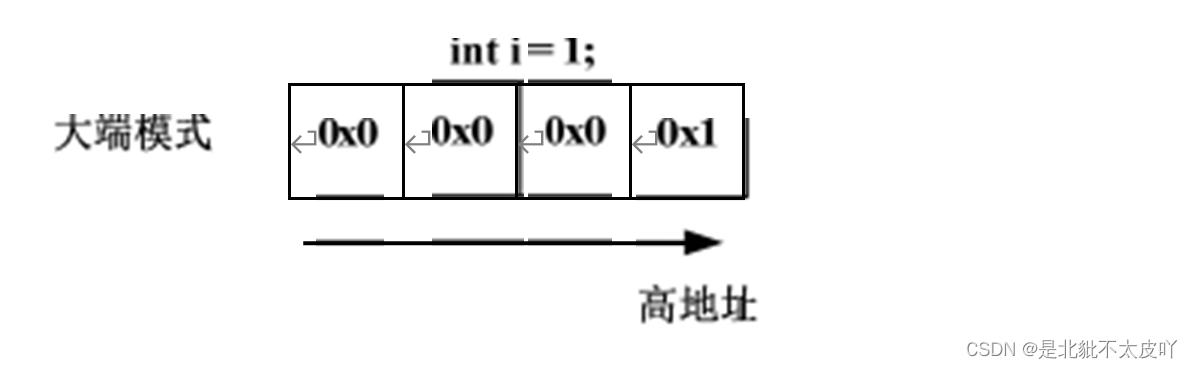
如何用程序确认当前系统的存储模式?
硬件开发笔记(十): 硬件开发基本流程,制作一个USB转RS232的模块(九):创建CH340G/MAX232封装库sop-16并关联原理图元器件
Memorabilia of domestic database in June 2022 - ink Sky Wheel
Management background --2 Classification list
随机推荐
空结构体多大?
新手程序员该不该背代码?
The SQL response is slow. What are your troubleshooting ideas?
变量与“零值”的比较
硬件開發筆記(十): 硬件開發基本流程,制作一個USB轉RS232的模塊(九):創建CH340G/MAX232封裝庫sop-16並關聯原理圖元器件
MySQL----初识MySQL
【数字IC手撕代码】Verilog无毛刺时钟切换电路|题目|原理|设计|仿真
在IPv6中 链路本地地址的优势
Build op-tee development environment based on qemuv8
枚举与#define 宏的区别
基于 QEMUv8 搭建 OP-TEE 开发环境
OpenCV VideoCapture. Get() parameter details
PVL EDI 项目案例
(18) LCD1602 experiment
Insert sort and Hill sort
RESNET rs: Google takes the lead in tuning RESNET, and its performance comprehensively surpasses efficientnet series | 2021 arXiv
i.mx6ull搭建boa服务器详解及其中遇到的一些问题
GD32F4XX串口接收中断和闲时中断配置
SQL server generates auto increment sequence number
将MySQL的表数据纯净方式导出