当前位置:网站首页>Markov decision process
Markov decision process
2022-07-07 00:26:00 【Evergreen AAS】
Plot task vs. Continuous mission
- Plot task (Episodic Tasks), All the tasks can be broken down into a series of plots , It can be seen as a limited step task .
- Continuous mission (Continuing Tasks), All tasks cannot be decomposed , It can be seen as an infinite step task .
Markov nature
Markov nature : When a stochastic process is in a given present state and all past states , The conditional probability distribution of its future state only depends on the current state .
Markov processes are Markov processes , That is, the conditional probability of the process is only related to the current state of the system , And it is independent of its past history or future state 、 uncorrelated .
Markov reward process
Markov reward process (Markov Reward Process,MRP) It is a Markov process with reward value , It can be represented by a quadruple
- S Is a finite set of States ;
- P Is the state transition matrix ,P_{ss^{‘}} = P[S_{t+1} = s^{‘}|S_t = s]
- R It's the reward function ;
- \gamma Is the discount factor (discount factor), among \gamma∈[0,1]
Reward function
stay t Reward value of the moment Gt :
G_t = R_{t+1} + \gamma R_{t+2} + ... = \sum_{k=0}^{\infty}\gamma^{k}R_{t+k+1}
Why Discount
About Return Why is it necessary to calculate \gamma Discount factor :
- The convenience of mathematical expression
- Avoid falling into an infinite cycle
- The long-term interest has certain uncertainty
- In Finance , Immediate return can gain more benefits than delayed return
- In line with the characteristics that human beings pay more attention to immediate interests
Value function
state s The long-term value function of is expressed as :
v(s)=E[Gt|St=s]
Bellman Equation for MRPs
\begin{align} v(s) &= E[G_t|S_t=s]\\ &= E[R_{t+1} + \gamma R_{t+2} + ... | S_t = s]\\ &= E[R_{t+1} + \gamma (R_{t+2} + \gamma R_{t+3} ... ) | S_t = s]\\ &= E[R_{t+1} + \gamma G_{t+1} | S_t = s]\\ &= E[R_{t+1} + \gamma v(s_{t+1}) | S_t = s] \end{align}
The following figure for MRP Of backup tree Sketch Map :
notes :backup tree The white circle in represents the state , The black dot corresponds to the action .
According to the above figure, we can further get :
v(s) = R_s + \gamma \sum_{s' \in S}P_{ss'}v(s')
Markov decision process
Markov decision process (Markov Decision Process,MDP) With decision MRP, It can be composed of a five tuple .
- S Is a finite set of States ;
- A For a limited set of actions ;
- P Is the state transition matrix ,P_{ss^{‘}}^{a} = P[S_{t+1} = s^{‘}|S_t = s,A_t=a]
- R It's the reward function ;
- \gamma Is the discount factor (discount factor), among \gamma∈[0,1] ]
We're talking about MDP Generally refers to limited ( discrete ) Markov decision process .
Strategy
Strategy (Policy) Is the action probability distribution in a given state , namely :
\pi(a|s) = P[A_t = a|S_t = a]
State value function & The optimal state value function
Given policy π Under the state of s State value function (State-Value Function) v_{\pi}(s)
v_{\pi}(s) = E_{\pi}[G_t|S_t = s]
state s The optimal state value function of (The Optimal State-Value Function)v~∗~(s)
v_{*}(s) = \max_{\pi}v_{\pi}(s)
Action value function & Optimal action value function
Given policy π, state s, Take action a Action value function (Action-Value Function)q~π~(s,a)
q_{\pi}(s, a) = E_{\pi}[G_t|S_t = s, A_t = a]
state s Take action a The optimal action value function of (The Optimal Action-Value Function)q∗(s,a):
q_{*}(s, a) = \max_{\pi}q_{\pi}(s, a)
The best strategy
If strategy π Better than strategy π′:
\pi \ge \pi^{'} \text{ if } v_{\pi}(s) \ge v_{\pi^{'}}(s), \forall{s}
The best strategy v∗ Satisfy :
- v∗≥π,∀π
- v~π∗~(s)=v~∗~(s)
- q~π∗~(s,a)=q~∗~(s,a)
How to find the best strategy ?
By maximizing q~∗~(s,a) To find the best strategy :
v_{*}(a|s) = \begin{cases} & 1 \text{ if } a=\arg\max_{a \in A}q_{*}(s,a)\\ & 0 \text{ otherwise } \end{cases}
about MDP Generally speaking, there is always a definite optimal strategy , And once we get q~∗~(s,a) , We can immediately find the optimal strategy .
Bellman Expectation Equation for MDPs
Let's first look at the state value function v^π^.
state s Corresponding backup tree As shown in the figure below :
According to the above figure :
v_{\pi}(s) = \sum_{a \in A}\pi(a|s)q_{\pi}(s, a) \qquad (1)
Let's look at the action value function q~π~(s,a)
state s, action a Corresponding backup tree As shown in the figure below :
So we can get :
q_{\pi}(s,a)=R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a v_{\pi}(s') \qquad (2)
Further subdivision backup tree Look again. v^π^ And q~π~(s,a) Corresponding representation .
Subdivision status ss Corresponding backup tree As shown in the figure below :
Will formula (2) Put in the formula (1) You can further get vπ(s)vπ(s) Behrman's expectation equation :
v_{\pi}(s) = \sum_{a \in A} \pi(a | s) \Bigl( R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a v_{\pi}(s') \Bigr) \qquad (3)
Subdivision status ss, action aa Corresponding backup tree As shown in the figure below :
Will formula (1) Put in the formula (2) You can get qπ(s,a) Behrman's expectation equation :
q_{\pi}(s,a)=R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a \Bigl(\sum_{a' \in A}\pi(a'|s')q_{\pi}(s', a') \Bigr) \qquad (4)
Bellman Optimality Equation for MDPs
Again, let's look at v~∗~(s):
The corresponding formula can be written :
v_{*}(s) = \max_{a}q_{*}(s, a) \qquad (5)
Look again. q~∗~(s,a):
The corresponding formula is :
q_{*}(s, a) = R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a v_{*}(s') \qquad (6)
Get the same routine v∗(s) Corresponding backup tree And Behrman optimal equation :
Behrman's optimal equation :
v_{*}(s) = \max_{a} \Bigl( R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a v_{*}(s') \Bigr) \qquad (7)
q∗(s,a) Corresponding backup tree And Behrman optimal equation :
The corresponding Behrman optimal equation :
R_s^a + \gamma \sum_{s'\in S}P_{ss'}^a\max_{a}q_{*}(s, a) \qquad (8)
Characteristics of Behrman optimal equation
- nonlinear (non-linear)
- Usually, there is no analytical solution (no closed form solution)
Solution of Behrman's optimal equation
- Value Iteration
- Policy Iteration
- Sarsa
- Q-Learning
MDPs Related expansion problems
Infinite MDPs/ continuity MDPsPartially observable MDPsReward In the form of no discount factor MDPs/ Average Reward Formal MDPs
边栏推荐
- [2022 the finest in the whole network] how to test the interface test generally? Process and steps of interface test
- Pdf document signature Guide
- 37页数字乡村振兴智慧农业整体规划建设方案
- Leecode brush question record sword finger offer 58 - ii Rotate string left
- Leecode brushes questions to record interview questions 17.16 massagist
- The programmer resigned and was sentenced to 10 months for deleting the code. Jingdong came home and said that it took 30000 to restore the database. Netizen: This is really a revenge
- 互动滑轨屏演示能为企业展厅带来什么
- Compilation of kickstart file
- 【2022全网最细】接口测试一般怎么测?接口测试的流程和步骤
- 2022年PMP项目管理考试敏捷知识点(9)
猜你喜欢
![[2022 the finest in the whole network] how to test the interface test generally? Process and steps of interface test](/img/8d/b59cf466031f36eb50d4d06aa5fbe4.jpg)
[2022 the finest in the whole network] how to test the interface test generally? Process and steps of interface test
2022/2/10 summary

37 pages Digital Village revitalization intelligent agriculture Comprehensive Planning and Construction Scheme
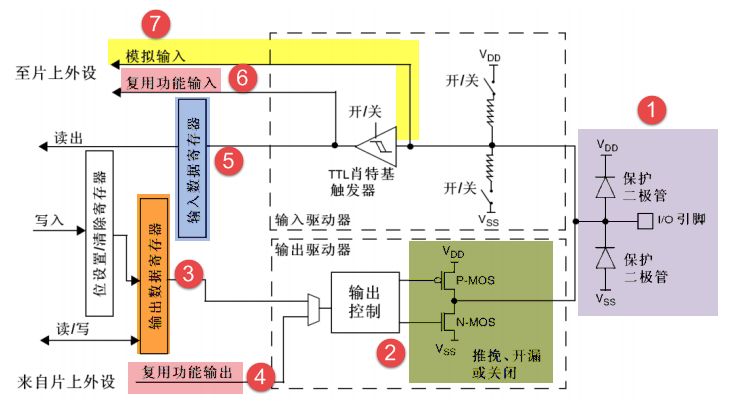
GPIO簡介

Testers, how to prepare test data
智能运维应用之道,告别企业数字化转型危机
DAY ONE
DAY TWO

1000字精选 —— 接口测试基础

DAY SIX
随机推荐
iMeta | 华南农大陈程杰/夏瑞等发布TBtools构造Circos图的简单方法
Liuyongxin report | microbiome data analysis and science communication (7:30 p.m.)
509 certificat basé sur Go
[2022 the finest in the whole network] how to test the interface test generally? Process and steps of interface test
Jenkins' user credentials plug-in installation
在Docker中分分钟拥有Oracle EMCC 13.5环境
Introduction to GPIO
48 page digital government smart government all in one solution
Three application characteristics of immersive projection in offline display
37頁數字鄉村振興智慧農業整體規劃建設方案
Testers, how to prepare test data
Use package FY in Oracle_ Recover_ Data. PCK to recover the table of truncate misoperation
The difference between redirectto and navigateto in uniapp
[boutique] Pinia Persistence Based on the plug-in Pinia plugin persist
AI超清修复出黄家驹眼里的光、LeCun大佬《深度学习》课程生还报告、绝美画作只需一行代码、AI最新论文 | ShowMeAI资讯日报 #07.06
陀螺仪的工作原理
After leaving a foreign company, I know what respect and compliance are
什么是响应式对象?响应式对象的创建过程?
2022/2/12 summary
Tourism Management System Based on jsp+servlet+mysql framework [source code + database + report]