当前位置:网站首页>MIT 6.824 - raft Student Guide
MIT 6.824 - raft Student Guide
2022-07-06 23:59:00 【s09g】
Translated from MIT 6.824《Students' Guide to Raft》
For the past few months, I have been a Teaching Assistant for MIT’s 6.824 Distributed Systems class. The class has traditionally had a number of labs building on the Paxos consensus algorithm, but this year, we decided to make the move to Raft. Raft was “designed to be easy to understand”, and our hope was that the change might make the students’ lives easier.
In the past few months , I've always been at MIT 6.824 Teaching assistant of distributed system course . This course has been based on Paxos Experiments on consensus algorithm , But this year , We decided to switch to Raft.Raft yes " Designed to be easy to understand ", We hope this change will make students' lives easier .
This post, and the accompanying Instructors’ Guide to Raft post, chronicles our journey with Raft, and will hopefully be useful to implementers of the Raft protocol and students trying to get a better understanding of Raft’s internals. If you are looking for a Paxos vs Raft comparison, or for a more pedagogical analysis of Raft, you should go read the Instructors’ Guide. The bottom of this post contains a list of questions commonly asked by 6.824 students, as well as answers to those questions. If you run into an issue that is not listed in the main content of this post, check out the Q&A. The post is quite long, but all the points it makes are real problems that a lot of 6.824 students (and TAs) ran into. It is a worthwhile read.
This article , And what follows 《Raft Instructor's Guide 》, It records our use Raft History , I hope so Raft The implementers of the agreement and try to better understand Raft Internal students help . If you're looking for Paxos And Raft Comparison , Or want to be right Raft Conduct more teaching analysis , You should read 《 Instructor's Guide 》. The bottom of this article contains 6.824 A list of questions students often ask , And the answers to these questions . If the problems you encounter are not listed in the main content of this post , Please check the question and answer . This article is quite long , But all the points it raises are many 6.824 Student ( And teaching assistants ) The real problem . This is an article worth reading .
Background
Before we dive into Raft, some context may be useful. 6.824 used to have a set of Paxos-based labs that were built in Go; Go was chosen both because it is easy to learn for students, and because is pretty well-suited for writing concurrent, distributed applications (goroutines come in particularly handy). Over the course of four labs, students build a fault-tolerant, sharded key-value store. The first lab had them build a consensus-based log library, the second added a key value store on top of that, and the third sharded the key space among multiple fault-tolerant clusters, with a fault-tolerant shard master handling configuration changes. We also had a fourth lab in which the students had to handle the failure and recovery of machines, both with and without their disks intact. This lab was available as a default final project for students.
Before we go deep into Raft Before , Let's start with some useful background knowledge .6.824 Once there was a set of Paxos Based experiments , Yes, it is Go To build ; choice Go Because it is easy for students to learn , It is also suitable for writing concurrent distributed applications (goroutines Particularly convenient ). In the course of four experiments , The students built a fault-tolerant 、 Segmented key value storage . The first lab let them build a consensus based log base , The second laboratory adds a key value storage on this basis , The third lab stores the key value space in multiple fault-tolerant clusters , A fault-tolerant partition master station handles configuration changes . We have a fourth Laboratory , Students have to deal with the problem of machine failure and recovery , Including the condition that the disk is intact . This laboratory can be used as the default final project for students .
This year, we decided to rewrite all these labs using Raft. The first three labs were all the same, but the fourth lab was dropped as persistence and failure recovery is already built into Raft. This article will mainly discuss our experiences with the first lab, as it is the one most directly related to Raft, though I will also touch on building applications on top of Raft (as in the second lab).
This year, , We decided to use Raft Rewrite all these labs . The first three laboratories are the same , But the fourth laboratory was abandoned , Because persistence and failover are built into Raft in . This article will mainly discuss our experience in the first experiment , Because it is related to Raft The most directly related experiment , Although I will also involve in Raft Build applications on top of ( Like the second experiment ).
Raft, for those of you who are just getting to know it, is best described by the text on the protocol’s web site:
For those who just know Raft For people who , The text on the agreement website describes it best :
Raft is a consensus algorithm that is designed to be easy to understand. It’s equivalent to Paxos in fault-tolerance and performance. The difference is that it’s decomposed into relatively independent subproblems, and it cleanly addresses all major pieces needed for practical systems. We hope Raft will make consensus available to a wider audience, and that this wider audience will be able to develop a variety of higher quality consensus-based systems than are available today.Raft It's a consensus algorithm , Designed to be easy to understand . It is similar to Paxos Quite a . The difference is , It is decomposed into relatively independent subproblems , And it cleanly solves all the main parts required by the actual system . We hope Raft It can let more people understand the consensus , And these people will be able to develop consensus based systems of higher quality than now . |
|---|
Visualizations like this one give a good overview of the principal components of the protocol, and the paper gives good intuition for why the various pieces are needed. If you haven’t already read the extended Raft paper, you should go read that before continuing this article, as I will assume a decent familiarity with Raft.
Visualization like this , There is a good overview of the main components of the agreement , And the paper gives a good intuition about why these different parts are needed . If you haven't read the extended Raft The paper , You should read this article before continuing , Because I will assume that you are right Raft Have a certain degree of familiarity .
As with all distributed consensus protocols, the devil is very much in the details. In the steady state where there are no failures, Raft’s behavior is easy to understand, and can be explained in an intuitive manner. For example, it is simple to see from the visualizations that, assuming no failures, a leader will eventually be elected, and eventually all operations sent to the leader will be applied by the followers in the right order. However, when delayed messages, network partitions, and failed servers are introduced, each and every if, but, and and, become crucial. In particular, there are a number of bugs that we see repeated over and over again, simply due to misunderstandings or oversights when reading the paper. This problem is not unique to Raft, and is one that comes up in all complex distributed systems that provide correctness.
Like all distributed consensus protocols , The devil is in the details . In a stable state without failure ,Raft Your behavior is easy to understand , And it can be explained in an intuitive way . for example , From the visualization, we can simply see , Assume there is no fault , Finally, a leader will be elected , Finally, all operations sent to the leader will be applied by the follower in the correct order . However , When delaying information 、 When network partitions and failed servers are introduced , every last if、but、and, All become crucial . especially , We see some bug Recurring , Just because of misunderstanding or negligence when reading the paper . The problem is not Raft Unique , It is a problem that occurs in all complex distributed systems that provide correctness .
Implementing Raft
The ultimate guide to Raft is in Figure 2 of the Raft paper. This figure specifies the behavior of every RPC exchanged between Raft servers, gives various invariants that servers must maintain, and specifies when certain actions should occur. We will be talking about Figure 2 a lot in the rest of this article. It needs to be followed to the letter.
Raft The final guide for is Raft The picture of the paper 2 in . The figure stipulates Raft Every exchange between servers RPC act , It gives various invariance that the server must keep , It also stipulates when certain actions should occur . In the rest of this article , We will often discuss graphs 2. It needs to be strictly observed .
Figure 2 defines what every server should do, in ever state, for every incoming RPC, as well as when certain other things should happen (such as when it is safe to apply an entry in the log). At first, you might be tempted to treat Figure 2 as sort of an informal guide; you read it once, and then start coding up an implementation that follows roughly what it says to do. Doing this, you will quickly get up and running with a mostly working Raft implementation. And then the problems start.
chart 2 It defines how each server responds to each incoming RPC What to do , And when something else should happen ( For example, when is it safe to apply an entry in the log ). In limine , You may want to put the picture 2 As an informal Guide ; Read it once , Then start writing an implementation , Do roughly as it says . To do so , You will soon have a basically feasible Raft Realization . then , The question begins .
In fact, Figure 2 is extremely precise, and every single statement it makes should be treated, in specification terms, as MUST, not as SHOULD. For example, you might reasonably reset a peer’s election timer whenever you receive an AppendEntries or RequestVote RPC, as both indicate that some other peer either thinks it’s the leader, or is trying to become the leader. Intuitively, this means that we shouldn’t be interfering. However, if you read Figure 2 carefully, it says:
in fact , chart 2 Is very accurate , In terms of norms , Every statement of it should be regarded as necessary , Not as it should be . for example , Every time you receive AppendEntries or RequestVote RPC when , You may reasonably reset the election timer of a peer , Because both of these indicate that other peers either consider themselves leaders , Or trying to be a leader . Intuitively speaking , This means that we should not interfere . However , If you read the picture carefully 2, It said :
If election timeout elapses without receiving AppendEntries RPC from current leader or granting vote to candidate: convert to candidate. If the election goes out of time , I haven't received from the current leader AppendEntries RPC, No voting rights have been granted to candidates : Convert to candidate . |
|---|
The distinction turns out to matter a lot, as the former implementation can result in significantly reduced liveness in certain situations.
This difference turns out to be very important , Because the implementation of the former will lead to significantly reduced effectiveness in some cases .
The importance of details
To make the discussion more concrete, let us consider an example that tripped up a number of 6.824 students. The Raft paper mentions heartbeat RPCs in a number of places. Specifically, a leader will occasionally (at least once per heartbeat interval) send out an AppendEntries RPC to all peers to prevent them from starting a new election. If the leader has no new entries to send to a particular peer, the AppendEntries RPC contains no entries, and is considered a heartbeat.
To make the discussion more specific , Let's consider a trip up some 6.824 Examples of students .Raft My paper mentioned heartbeat in many places RPC. say concretely , Leaders occasionally ( At least once per heartbeat ) Send to all peers AppendEntries RPC, To prevent them from starting a new election . If the leader has no new entries to send to a specific peer , that AppendEntries RPC It doesn't contain any entries , And is considered a heartbeat .
Many of our students assumed that heartbeats were somehow “special”; that when a peer receives a heartbeat, it should treat it differently from a non-heartbeat AppendEntries RPC. In particular, many would simply reset their election timer when they received a heartbeat, and then return success, without performing any of the checks specified in Figure 2. This is extremely dangerous. By accepting the RPC, the follower is implicitly telling the leader that their log matches the leader’s log up to and including the prevLogIndex included in the AppendEntries arguments. Upon receiving the reply, the leader might then decide (incorrectly) that some entry has been replicated to a majority of servers, and start committing it.
Many of our students think , The heartbeat is... To some extent " special " Of ; When a peer receives a heartbeat , It should be related to non heartbeat AppendEntries RPC Differential treatment . especially , Many people receive heartbeats , Will simply reset their election timers , Then return to success , Without executing the diagram 2 Any inspection specified in . It's very dangerous . By accepting RPC, The follower implicitly tells the leader , Their logs match the leaders' logs , Include AppendEntries In the parameter prevLogIndex. After receiving the reply , Leaders may ( by error ) Think that some entries have been copied to most servers , And start submitting it .
Another issue many had (often immediately after fixing the issue above), was that, upon receiving a heartbeat, they would truncate the follower’s log following prevLogIndex, and then append any entries included in the AppendEntries arguments. This is also not correct. We can once again turn to Figure 2:
Another problem many people encounter ( Usually after fixing the above problems ) yes , When receiving the heartbeat , They will be in prevLogIndex Then truncate the followers' logs , Then add AppendEntries Any entries included in the parameter . That's not true . We can turn to figure again 2:
If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it. If an existing entry conflicts with a new entry ( Same index , But different tenure ), Please delete the existing entries and all subsequent entries . |
|---|
The if here is crucial. If the follower has all the entries the leader sent, the follower MUST NOT truncate its log. Any elements following the entries sent by the leader MUST be kept. This is because we could be receiving an outdated AppendEntries RPC from the leader, and truncating the log would mean “taking back” entries that we may have already told the leader that we have in our log.
there if Is the key . If the follower has all the items sent by the leader , Followers must not truncate their logs . Any elements that follow the items sent by the leader must be preserved . This is because we may receive an outdated AppendEntries RPC, And truncating the log will mean " Take back " We may have told our leaders about the entries in our logs .
Debugging Raft
Inevitably, the first iteration of your Raft implementation will be buggy. So will the second. And third. And fourth. In general, each one will be less buggy than the previous one, and, from experience, most of your bugs will be a result of not faithfully following Figure 2.
Inevitably , Yours Raft The first iteration of the implementation will be wrong . The second time will be the same . third time . And the fourth time . Generally speaking , Every time there are fewer mistakes than the previous time , and , Based on experience , Most of your mistakes are not faithful to the picture 2 Result .
When debugging, Raft, there are generally four main sources of bugs: livelocks, incorrect or incomplete RPC handlers, failure to follow The Rules, and term confusion. Deadlocks are also a common problem, but they can generally be debugged by logging all your locks and unlocks, and figuring out which locks you are taking, but not releasing. Let us consider each of these in turn:
When debugging ,Raft There are usually four main bug source : Deadlock 、 Incorrect or incomplete RPC The handler 、 Failure to follow the rules and confusion of tenure . Deadlock is also a common problem , But they can usually be debugged by recording all your locks and unlocks , And find the lock you are using but haven't released . Let's consider these issues in turn :
Livelocks
When your system livelocks, every node in your system is doing something, but collectively your nodes are in such a state that no progress is being made. This can happen fairly easily in Raft, especially if you do not follow Figure 2 religiously. One livelock scenario comes up especially often; no leader is being elected, or once a leader is elected, some other node starts an election, forcing the recently elected leader to abdicate immediately.
When your system is locked , Every node in the system is doing something , But on the whole, the node is in such a state without any progress . In this case Raft It is easy to happen , Especially if you don't follow the diagram faithfully 2 when . There is a kind of loose lock that occurs very frequently ; No leader was elected , Or once the leader is elected , Other nodes start voting again , Force the recently elected leader to abdicate immediately .
There are many reasons why this scenario may come up, but there is a handful of mistakes that we have seen numerous students make:
There are many reasons for this , But there are several mistakes that we see many students make :
- Make sure you reset your election timer exactly when Figure 2 says you should. Specifically, you should only restart your election timer if a) you get an AppendEntries RPC from the current leader (i.e., if the term in the AppendEntries arguments is outdated, you should not reset your timer); b) you are starting an election; or c) you grant a vote to another peer.
Make sure you are in the picture 2 Describe exactly where to reset your election timer . say concretely , You should reset your election timer only if :a) You get one from your current leader AppendEntries RPC( namely , If AppendEntries The term of office in the parameter is out of date , You should not restart your timer );b) You are starting an election ; perhaps c) You grant another peer a vote .
This last case is especially important in unreliable networks where it is likely that followers have different logs; in those situations, you will often end up with only a small number of servers that a majority of servers are willing to vote for. If you reset the election timer whenever someone asks you to vote for them, this makes it equally likely for a server with an outdated log to step forward as for a server with a longer log.
The last situation is particularly important in unreliable networks , Because followers are likely to have different logs ; In these cases , You end up with only a few servers , And most servers are willing to vote for it . If you reset the election timer every time someone asks you to vote for him , This makes it possible for a server with outdated logs to stand up as well as a server with long logs .
In fact, because there are so few servers with sufficiently up-to-date logs, those servers are quite unlikely to be able to hold an election in sufficient peace to be elected. If you follow the rule from Figure 2, the servers with the more up-to-date logs won’t be interrupted by outdated servers’ elections, and so are more likely to complete the election and become the leader.
in fact , Because there are too few servers with enough up-to-date logs , It is very unlikely that these servers will be elected in a sufficiently calm election . If you follow the diagram 2 The rules of , Servers with more up-to-date logs will not be interrupted by the election of outdated servers , So it is more likely to complete the election , Become a leader .
- Follow Figure 2’s directions as to when you should start an election. In particular, note that if you are a candidate (i.e., you are currently running an election), but the election timer fires, you should start another election. This is important to avoid the system stalling due to delayed or dropped RPCs.
You should follow the picture 2 Instructions to start the election . Special attention is paid to , If you are a candidate ( namely , You are currently holding an election ), But the election timer started , You should start another election . This is important , It can avoid the system from RPC Delay or packet loss and stagnate .
- Ensure that you follow the second rule in “Rules for Servers” before handling an incoming RPC. The second rule states:
Processing incoming RPC Before , Please make sure you follow " Server rules " The second rule in . The second rule says :
If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1) If RPC The request or response contains T > currentTerm: Set up currentTerm = T, Convert to follower(§5.1). |
|---|
For example, if you have already voted in the current term, and an incoming RequestVote RPC has a higher term that you, you should first step down and adopt their term (thereby resetting votedFor), and then handle the RPC, which will result in you granting the vote!
for example , If you have voted during your current term , And the incoming RequestVote RPC Your tenure is higher than yours , You should step down first , Adopt their tenure ( To reset votedFor), Then process RPC, This will result in you granting the right to vote .
Incorrect RPC handlers
Even though Figure 2 spells out exactly what each RPC handler should do, some subtleties are still easy to miss. Here are a handful that we kept seeing over and over again, and that you should keep an eye out for in your implementation:
Despite the picture 2 Clearly explain each RPC What should the handler do , But some nuances are still easy to ignore . Here are some things we have seen repeatedly , You should pay attention to these situations in your implementation :
- If a step says “reply false”, this means you should reply immediately, and not perform any of the subsequent steps.
If one step says " Reply error ", This means that you should reply immediately , Instead of performing any subsequent steps .
- If you get an AppendEntries RPC with a prevLogIndex that points beyond the end of your log, you should handle it the same as if you did have that entry but the term did not match (i.e., reply false).
If you get one AppendEntries RPC, Its prevLogIndex Point to the end of your log , You should deal with it like you do have that item but the tenure doesn't match ( namely , reply false).
- Check 2 for the AppendEntries RPC handler should be executed even if the leader didn’t send any entries.
AppendEntries RPC Check the handler 2 Should be implemented , Even if the leader doesn't send any entries .
- The min in the final step (#5) of AppendEntries is necessary, and it needs to be computed with the index of the last new entry. It is not sufficient to simply have the function that applies things from your log between lastApplied and commitIndex stop when it reaches the end of your log. This is because you may have entries in your log that differ from the leader’s log after the entries that the leader sent you (which all match the ones in your log). Because #3 dictates that you only truncate your log if you have conflicting entries, those won’t be removed, and if leaderCommit is beyond the entries the leader sent you, you may apply incorrect entries.
AppendEntries The last step of (#5) Medium min be necessary , It needs to be calculated with the index of the last new entry . Just let the application lastApplied and commitIndex It is not enough for the function of the log content between to stop when it reaches the end of the log . This is because your log may have different entries from the leader's log , After the items sent to you by the leader ( These entries are consistent with those in your log ). because #3 It determines that you will truncate your log only when there are conflicting entries , Those entries will not be deleted , If leaderCommit It exceeds the items sent by the leader , You may apply incorrect entries .
- It is important to implement the “up-to-date log” check exactly as described in section 5.4. No cheating and just checking the length!
It is important to , Follow paragraph 5.4 Section to achieve " The latest log " The inspection of . Don't cheat , Check length only !.
Failure to follow The Rules
While the Raft paper is very explicit about how to implement each RPC handler, it also leaves the implementation of a number of rules and invariants unspecified. These are listed in the “Rules for Servers” block on the right hand side of Figure 2. While some of them are fairly self-explanatory, the are also some that require designing your application very carefully so that it does not violate The Rules:
although Raft The paper clearly explains how to realize each RPC The handler , But it also does not clearly stipulate the realization of some rules and invariable factors . These rules are listed in Figure 2 On the right side of the " Server rules " part . Although some of them are self-evident , But there are also some applications that need to be designed very carefully , Make it not violate the rules :
- If commitIndex > lastApplied at any point during execution, you should apply a particular log entry. It is not crucial that you do it straight away (for example, in the AppendEntries RPC handler), but it is important that you ensure that this application is only done by one entity. Specifically, you will need to either have a dedicated “applier”, or to lock around these applies, so that some other routine doesn’t also detect that entries need to be applied and also tries to apply.
If at any time during the execution commitIndex > lastApplied, You should apply a specific log entry . It doesn't matter whether you do it directly ( for example , stay AppendEntries RPC In process ), But it's important to make sure that this application is done by only one entity . say concretely , You need a special "applier", Or lock around these applications , In this way, other routines will not detect the items that need to be applied , And also try to apply .
- Make sure that you check for commitIndex > lastApplied either periodically, or after commitIndex is updated (i.e., after matchIndex is updated). For example, if you check commitIndex at the same time as sending out AppendEntries to peers, you may have to wait until the next entry is appended to the log before applying the entry you just sent out and got acknowledged.
Make sure to check regularly commitIndex > lastApplied, Or in commitIndex After the update ( namely matchIndex After the update ) Check . for example , If you are checking commitIndex Send to the peer at the same time AppendEntries, You may have to wait until the next entry is appended to the log , Then apply the items you just sent and confirmed .
- If a leader sends out an AppendEntries RPC, and it is rejected, but not because of log inconsistency (this can only happen if our term has passed), then you should immediately step down, and not update nextIndex. If you do, you could race with the resetting of nextIndex if you are re-elected immediately.
If a leader sends out AppendEntries RPC, And it was rejected , But it's not because the logs are inconsistent ( This can only happen when our term of office has expired ), Then you should step down immediately , Instead of updating nextIndex. If you do , Then if you are re elected immediately , You may be with nextIndex The reset of conflicts .
- A leader is not allowed to update commitIndex to somewhere in a previous term (or, for that matter, a future term). Thus, as the rule says, you specifically need to check that log[N].term == currentTerm. This is because Raft leaders cannot be sure an entry is actually committed (and will not ever be changed in the future) if it’s not from their current term. This is illustrated by Figure 8 in the paper.
Leaders are not allowed to commitIndex Update to somewhere in the previous term ( perhaps , Future tenure ). therefore , As the rules say , You need special examination log[N].term == currentTerm. This is because , If an entry is not from their current tenure ,Raft The leader cannot be sure that it is really submitted ( And will not be changed in the future ). Graph in the paper 8 It shows that .
One common source of confusion is the difference between nextIndex and matchIndex. In particular, you may observe that matchIndex = nextIndex - 1, and simply not implement matchIndex. This is not safe. While nextIndex and matchIndex are generally updated at the same time to a similar value (specifically, nextIndex = matchIndex + 1), the two serve quite different purposes. nextIndex is a guess as to what prefix the leader shares with a given follower. It is generally quite optimistic (we share everything), and is moved backwards only on negative responses. For example, when a leader has just been elected, nextIndex is set to be index index at the end of the log. In a way, nextIndex is used for performance – you only need to send these things to this peer.
A common source of problems is nextIndex and matchIndex The difference between . especially , You may observe matchIndex = nextIndex - 1, But not at all matchIndex. It's not safe . although nextIndex and matchIndex It is usually updated to a similar value at the same time ( say concretely ,nextIndex = matchIndex + 1), But their functions are completely different . It is usually quite optimistic ( We share everything ), And only move backwards in negative reactions . for example , When a leader is just elected ,nextIndex Is set as the index index at the end of the log . In a way ,nextIndex For performance -- You just need to send these things to this peer .
matchIndex is used for safety. It is a conservative measurement of what prefix of the log the leader shares with a given follower. matchIndex cannot ever be set to a value that is too high, as this may cause the commitIndex to be moved too far forward. This is why matchIndex is initialized to -1 (i.e., we agree on no prefix), and only updated when a follower positively acknowledges an AppendEntries RPC.
matchIndex It is used for safety .MatchIndex Cannot be set to a value too high , Because it can lead to commitIndex Moved too far forward . That's why matchIndex Is initialized to -1( in other words , We don't agree with any prefix ), And only when the follower affirms AppendEntries RPC It's only updated when .
Term confusion
Term confusion refers to servers getting confused by RPCs that come from old terms. In general, this is not a problem when receiving an RPC, since the rules in Figure 2 say exactly what you should do when you see an old term. However, Figure 2 generally doesn’t discuss what you should do when you get old RPC replies. From experience, we have found that by far the simplest thing to do is to first record the term in the reply (it may be higher than your current term), and then to compare the current term with the term you sent in your original RPC. If the two are different, drop the reply and return. Only if the two terms are the same should you continue processing the reply. There may be further optimizations you can do here with some clever protocol reasoning, but this approach seems to work well. And not doing it leads down a long, winding path of blood, sweat, tears and despair.
Term confusion means that the server is RPC Bewildered . Generally speaking , Upon receipt of RPC when , It's not a problem , Because of the picture 2 The rules in explain exactly what you should do when you see an old term . However , chart 2 Generally there is no discussion when you receive the old RPC What should you do when replying . Based on experience , We found that so far , The simplest way is to record the term of office in the reply first ( It may be higher than your current term ), Then compare your current tenure with yours in the original RPC Compare the terms sent in . If the two are different , Give up reply and return . Only when the two terms of office are the same , You should continue to deal with the reply . Maybe you can make further optimization here through some clever protocol reasoning , But this method seems to be very effective . Failure to do so will lead to a long and tortuous sweat 、 Tears and desperate road .
A related, but not identical problem is that of assuming that your state has not changed between when you sent the RPC, and when you received the reply. A good example of this is setting matchIndex = nextIndex - 1, or matchIndex = len(log) when you receive a response to an RPC. This is not safe, because both of those values could have been updated since when you sent the RPC. Instead, the correct thing to do is update matchIndex to be prevLogIndex + len(entries[]) from the arguments you sent in the RPC originally.
A related but not identical problem is , Preset your status when you send RPC There is no change between you and the reply you receive . A good example of this is , When you receive RPC The response , Set up matchIndex = nextIndex - 1, perhaps matchIndex = len(log). It's not safe , Because these two values may be sent by you RPC Later updated . contrary , The right thing to do is to matchIndex Update that you were originally in RPC Among the parameters sent in prevLogIndex + len( entries[]) .
An aside on optimizations
The Raft paper includes a couple of optional features of interest. In 6.824, we require the students to implement two of them: log compaction (section 7) and accelerated log backtracking (top left hand side of page 8). The former is necessary to avoid the log growing without bound, and the latter is useful for bringing stale followers up to date quickly.
Raft The paper includes several optional functions . stay 6.824 in , We ask students to realize two of them : Log compression ( The first 7 section ) And accelerating log backtracking ( The first 8 Top left of page ). The former is necessary to avoid unlimited growth of logs , The latter is useful for making old followers update quickly .
These features are not a part of “core Raft”, and so do not receive as much attention in the paper as the main consensus protocol. Log compaction is covered fairly thoroughly (in Figure 13), but leaves out some design details that you might miss if you read it too casually:
These functions are not " The core Raft " Part of , Therefore, it does not receive as much attention as the main consensus agreement in this article . The content of log compression is quite comprehensive ( In the figure 13 in ), But some design details are missing , If you read too casually , May miss :
- When snapshotting application state, you need to make sure that the application state corresponds to the state following some known index in the Raft log. This means that the application either needs to communicate to Raft what index the snapshot corresponds to, or that Raft needs to delay applying additional log entries until the snapshot has been completed.
When snapshot application state , You need to ensure that the application state is consistent with Raft The state after a known index in the log corresponds to . This means that the application needs to Raft Convey the index corresponding to the snapshot , perhaps Raft Need to delay the application of additional log entries , Until the snapshot is completed .
- The text does not discuss the recovery protocol for when a server crashes and comes back up now that snapshots are involved. In particular, if Raft state and snapshots are committed separately, a server could crash between persisting a snapshot and persisting the updated Raft state. This is a problem, because step 7 in Figure 13 dictates that the Raft log covered by the snapshot must be discarded.
The recovery protocol when the server crashes and recovers is not discussed , Because now it comes to snapshots . especially , If Raft The state and snapshot are submitted separately , The server may insist on snapshots and updates Raft Collapse between States . That's a problem , Because of the picture 13 No 7 Step determines what the snapshot covers Raft Logs must be discarded .
If, when the server comes back up, it reads the updated snapshot, but the outdated log, it may end up applying some log entries that are already contained within the snapshot. This happens since the commitIndex and lastApplied are not persisted, and so Raft doesn’t know that those log entries have already been applied. The fix for this is to introduce a piece of persistent state to Raft that records what “real” index the first entry in Raft’s persisted log corresponds to. This can then be compared to the loaded snapshot’s lastIncludedIndex to determine what elements at the head of the log to discard.
If when the server restarts , It reads the updated snapshot , Instead of outdated logs , Then it may eventually apply some log entries that have been included in the snapshot . This will happen , because commitIndex and lastApplied Not persisted , therefore Raft I don't know that these log entries have been applied . The solution to this problem is in Raft Introduce a persistent state in , Record Raft Corresponding to the first entry in the persistence log " real " Indexes . then , This can be compared with the loaded snapshot lastIncludedIndex Compare , To determine which elements of the log header to discard .
The accelerated log backtracking optimization is very underspecified, probably because the authors do not see it as being necessary for most deployments. It is not clear from the text exactly how the conflicting index and term sent back from the client should be used by the leader to determine what nextIndex to use. We believe the protocol the authors probably want you to follow is:
The optimization of accelerating log backtracking is very ambiguous , It may be because the author believes that it is not necessary in most deployments . The text does not clearly point out , How should leaders use the conflict index and tenure sent back from the client to decide which one to use NextIndex. We think the agreement that the author may want you to follow is :
- If a follower does not have prevLogIndex in its log, it should return with conflictIndex = len(log) and conflictTerm = None.
If a follower's log does not prevLogIndex, It should be in the form of conflictIndex = len(log) and conflictTerm = None return .
- If a follower does have prevLogIndex in its log, but the term does not match, it should return conflictTerm = log[prevLogIndex].Term, and then search its log for the first index whose entry has term equal to conflictTerm.
If a follower does have prevLogIndex, But the tenure does not match , It should return conflictTerm = log[prevLogIndex].Term, Then search their logs for entries with terms equal to conflictTerm The first index of .
- Upon receiving a conflict response, the leader should first search its log for conflictTerm. If it finds an entry in its log with that term, it should set nextIndex to be the one beyond the index of the last entry in that term in its log.
After receiving the conflict response , Leaders should first search their logs conflictTerm. If it finds an entry with that term in its log , It should nextIndex Set as the index other than the index of the last entry of the term in its log .
- If it does not find an entry with that term, it should set nextIndex = conflictIndex.
If it does not find an entry for that term , It should be set to nextIndex = conflictIndex.
A half-way solution is to just use conflictIndex (and ignore conflictTerm), which simplifies the implementation, but then the leader will sometimes end up sending more log entries to the follower than is strictly necessary to bring them up to date.
A halfway solution is to use only conflictIndex( And ignore conflictTerm), This simplifies the implementation of , But this way , Leaders sometimes send more log entries to followers , Not strictly required , So that they can reach the latest state .
Applications on top of Raft
When building a service on top of Raft (such as the key/value store in the second 6.824 Raft lab, the interaction between the service and the Raft log can be tricky to get right. This section details some aspects of the development process that you may find useful when building your application.
stay Raft When building services on ( Such as the second one. 6.824 Raft In the laboratory k/v Storage ), Services and Raft The interaction between logs can be tricky , It needs to be handled correctly . This section details some aspects of the development process , You may find that when building your application , These aspects are useful .
Applying client operations
You may be confused about how you would even implement an application in terms of a replicated log. You might start off by having your service, whenever it receives a client request, send that request to the leader, wait for Raft to apply something, do the operation the client asked for, and then return to the client. While this would be fine in a single-client system, it does not work for concurrent clients.
You may be confused about how to implement an application in terms of replicated logs . You can first let your service when it receives a client request , Send the request to the leader , wait for Raft Apply something , Do the operations required by the client , And then back to the client . Although this is very good in the single customer system , But for concurrent customers , It doesn't work .
Instead, the service should be constructed as a state machine where client operations transition the machine from one state to another. You should have a loop somewhere that takes one client operation at the time (in the same order on all servers – this is where Raft comes in), and applies each one to the state machine in order. This loop should be the only part of your code that touches the application state (the key/value mapping in 6.824). This means that your client-facing RPC methods should simply submit the client’s operation to Raft, and then wait for that operation to be applied by this “applier loop”. Only when the client’s command comes up should it be executed, and any return values read out. Note that this includes read requests!
contrary , Services should be built as a state machine , The client operation transitions the machine from one state to another . You should have a cycle somewhere , Receive one client operation at a time ( The order is the same on all servers -- This is it. Raft The role of ), And apply each operation to the state machine in sequence . This loop should be the only part of your code that touches the application state (6.824 Medium k/v mapping ). This means that you are client oriented RPC Method should simply submit the client operation to Raft, Then wait for the operation to be " User loop " application . Only when the client's command appears , It should be implemented , And read out any return value . Please note that , This includes read requests !
This brings up another question: how do you know when a client operation has completed? In the case of no failures, this is simple – you just wait for the thing you put into the log to come back out (i.e., be passed to apply()). When that happens, you return the result to the client. However, what happens if there are failures? For example, you may have been the leader when the client initially contacted you, but someone else has since been elected, and the client request you put in the log has been discarded. Clearly you need to have the client try again, but how do you know when to tell them about the error?
This brings another problem : How do you know when the client operation is completed ? Without failure , It's very simple -- You just need to wait for what you put into the log to come out ( Is passed to apply()). When that happens , You return the result to the client . However , What if there is failure ? for example , When the client first contacted you , You may be a leader , But then others were elected , And the client request you put in the log is discarded . Obviously , You need to make the client try again , But how do you know when to tell them this mistake ?
One simple way to solve this problem is to record where in the Raft log the client’s operation appears when you insert it. Once the operation at that index is sent to apply(), you can tell whether or not the client’s operation succeeded based on whether the operation that came up for that index is in fact the one you put there. If it isn’t, a failure has happened and an error can be returned to the client.
A simple way to solve this problem is , When you insert the operation of the client , Record it in Raft Where appears in the log . Once the operation of this index is sent to apply(), You can judge whether the operation of the client is successful according to whether the operation of the index is really the operation you put there . If not , Failure occurred , You can return an error to the client .
Duplicate detection
As soon as you have clients retry operations in the face of errors, you need some kind of duplicate detection scheme – if a client sends an APPEND to your server, doesn’t hear back, and re-sends it to the next server, your apply() function needs to ensure that the APPEND isn’t executed twice. To do so, you need some kind of unique identifier for each client request, so that you can recognize if you have seen, and more importantly, applied, a particular operation in the past. Furthermore, this state needs to be a part of your state machine so that all your Raft servers eliminate the same duplicates.
Once you let the client retry the operation when an error occurs , You need some kind of duplicate detection scheme -- If a client sends a to your server APPEND, But there was no reply , And resend it to the next server , Yours apply() The function needs to ensure APPEND Will not be executed twice . Do that , You need to provide some unique identifier for each client request , In this way, you can identify whether you have seen in the past , what's more , Applied a specific operation . Besides , This state needs to be part of your state machine , So that all of you Raft Servers can eliminate the same duplicate content .
There are many ways of assigning such identifiers. One simple and fairly efficient one is to give each client a unique identifier, and then have them tag each request with a monotonically increasing sequence number. If a client re-sends a request, it re-uses the same sequence number. Your server keeps track of the latest sequence number it has seen for each client, and simply ignores any operation that it has already seen.
There are many ways to assign this identifier . A simple and quite effective method is to give each client a unique identifier , Then ask them to mark each request with a monotonically increasing serial number . If a client resends a request , It will reuse the same serial number . Your server will track the latest serial number it sees for each client , And simply ignore any actions it has seen .
Hairy corner-cases
If your implementation follows the general outline given above, there are at least two subtle issues you are likely to run into that may be hard to identify without some serious debugging. To save you some time, here they are:
If your implementation follows the general outline given above , There are at least two subtle problems you may encounter , If you don't debug carefully , It may be difficult to identify . To save your time , Here are two questions :
Re-appearing indices:
Say that your Raft library has some method Start() that takes a command, and return the index at which that command was placed in the log (so that you know when to return to the client, as discussed above). You might assume that you will never see Start() return the same index twice, or at the very least, that if you see the same index again, the command that first returned that index must have failed. It turns out that neither of these things are true, even if no servers crash.
Re emerging index . Suppose your Raft The library has some Start() Method , It receives a command , And return the index of the command in the log ( So that you know when to return to the client , As mentioned above ). You might think , You'll never see Start() Return the same index twice , Or at least , If you see the same index again , The first command to return the index must have failed . The fact proved that , Neither of these things is true , Even if there is no server crash .
Consider the following scenario with five servers, S1 through S5. Initially, S1 is the leader, and its log is empty.
Consider the following scenario with five servers ,S1 To S5. first ,S1 It's the leader , Its log is empty .
- Two client operations (C1 and C2) arrive on S1
Two client operations (C1 and C2) arrive S1 On
- Start() return 1 for C1, and 2 for C2.
Start() Yes C1 return 1, Yes C2 return 2.
- S1 sends out an AppendEntries to S2 containing C1 and C2, but all its other messages are lost.
S1 towards S2 Sent a containing C1 and C2 Of AppendEntries, But all its other messages were lost .
- S3 steps forward as a candidate.
S3 Stood up as a candidate .
- S1 and S2 won’t vote for S3, but S3, S4, and S5 all will, so S3 becomes the leader.
S1 and S2 Will not vote for S3, but S3、S4 and S5 Metropolis , therefore S3 Become a leader .
- Another client request, C3 comes in to S3.
Another client requests ,C3 Arrived S3.
- S3 calls Start() (which returns 1)
S3 call Start()( return 1).
- S3 sends an AppendEntries to S1, who discards C1 and C2 from its log, and adds C3.
S3 towards S1 Sent a AppendEntries,S1 Discarded from its log C1 and C2, And add the C3.
- S3 fails before sending AppendEntries to any other servers.
S3 Sending to other servers AppendEntries Failed before .
- S1 steps forward, and because its log is up-to-date, it is elected leader.
S1 Stand out , Because its log is up-to-date , It was chosen as a leader .
- Another client request, C4, arrives at S1
Another client requests ,C4, Arrived at the S1
- S1 calls Start(), which returns 2 (which was also returned for Start(C2).
S1 call Start(), return 2(Start(C2) This value is also returned ).
- All of S1’s AppendEntries are dropped, and S2 steps forward.
S1 All of the AppendEntries It's all discarded ,S2 Stand up and become a candidate .
- S1 and S3 won’t vote for S2, but S2, S4, and S5 all will, so S2 becomes leader.
S1 and S3 Not for S2 vote , but S2、S4 and S5 Metropolis , therefore S2 Become a leader .
- A client request C5 comes in to S2
A client request C5 Get into S2
- S2 calls Start(), which returns 3.
S2 call Start(), return 3.
- S2 successfully sends AppendEntries to all the servers, which S2 reports back to the servers by including an updated leaderCommit = 3 in the next heartbeat.
S2 Successfully sent to all servers AppendEntries,S2 By adding an updated leaderCommit=3 To report to the server .
Since S2’s log is [C1 C2 C5], this means that the entry that committed (and was applied at all servers, including S1) at index 2 is C2. This despite the fact that C4 was the last client operation to have returned index 2 at S1.
because S2 My journal is [C1 C2 C5], This means that in the index 2 Submitted by ( And on all servers , Include S1 Processing application ) The entry for is C2. Even though C4 Is the last one in S1 Returns the index 2 Client operation , But that's also true .
The four-way deadlock:
All credit for finding this goes to Steven Allen, another 6.824 TA. He found the following nasty four-way deadlock that you can easily get into when building applications on top of Raft.
All the credit for discovering this problem is due to Steven Allen, the other one 6.824 TA. He found the following annoying four-way deadlock , When you are in Raft When building applications on , It's easy to get involved .
Your Raft code, however it is structured, likely has a Start()-like function that allows the application to add new commands to the Raft log. It also likely has a loop that, when commitIndex is updated, calls apply() on the application for every element in the log between lastApplied and commitIndex. These routines probably both take some lock a. In your Raft-based application, you probably call Raft’s Start() function somewhere in your RPC handlers, and you have some code somewhere else that is informed whenever Raft applies a new log entry. Since these two need to communicate (i.e., the RPC method needs to know when the operation it put into the log completes), they both probably take some lock b.
Yours Raft Code , Whatever its structure , There is probably a similar Start() Function of , Allow applications to Raft Add a new command to the log . It may also have a cycle , When commitIndex When updated , In the log lastApplied and commitIndex Each element between calls apply(). Based on Raft In the , You may be in RPC The handler is called somewhere Raft Of Start() function , And there are some codes in other places Raft Be notified when applying new log entries . Because these two need to communicate ( namely RPC Method needs to know when the operation of putting it into the log is completed ), They may all need some locks b.
In Go, these four code segments probably look something like this:
stay Go in , These four code snippets may look like this :
func (a *App) RPC(args interface{}, reply interface{}) { // ... a.mutex.Lock() i := a.raft.Start(args) // update some data structure so that apply knows to poke us later a.mutex.Unlock() // wait for apply to poke us return } |
|---|
func (r *Raft) Start(cmd interface{}) int { r.mutex.Lock() // do things to start agreement on this new command // store index in the log where cmd was placed r.mutex.Unlock() return index } |
func (a *App) apply(index int, cmd interface{}) { a.mutex.Lock() switch cmd := cmd.(type) { case GetArgs: // do the get // see who was listening for this index // poke them all with the result of the operation // ... } a.mutex.Unlock() } |
func (r *Raft) AppendEntries(...) { // ... r.mutex.Lock() // ... for r.lastApplied < r.commitIndex { r.lastApplied++ r.app.apply(r.lastApplied, r.log[r.lastApplied]) } // ... r.mutex.Unlock() } |
Consider now if the system is in the following state:
Now consider , If the system is in the following state :
- App.RPC has just taken a.mutex and called Raft.Start
App.RPC Just got a.mutex And call Raft.Start
- Raft.Start is waiting for r.mutex
Raft.Start Is waiting for r.mutex
- Raft.AppendEntries is holding r.mutex, and has just called App.apply
Raft.AppendEntries hold r.mutex, And just called App.apply.
We now have a deadlock, because:
We now have a deadlock , because :
- Raft.AppendEntries won’t release the lock until App.apply returns.
Raft.AppendEntries It won't release the lock , until App.apply return .
- App.apply can’t return until it gets a.mutex.
App.application In obtaining a.mutex Cannot return before .
- a.mutex won’t be released until App.RPC returns.
a.mutex Will not be released , until App.RPC return .
- App.RPC won’t return until Raft.Start returns.
stay Raft.Start Before returning ,App.RPC Will not return .
- Raft.Start can’t return until it gets r.mutex.
Raft.Start In obtaining r.mutex Cannot return before .
- Raft.Start has to wait for Raft.AppendEntries.
Raft.Start Must wait Raft.AppendEntries.
There are a couple of ways you can get around this problem. The easiest one is to take a.mutex after calling a.raft.Start in App.RPC. However, this means that App.apply may be called for the operation that App.RPC just called Raft.Start on before App.RPC has a chance to record the fact that it wishes to be notified. Another scheme that may yield a neater design is to have a single, dedicated thread calling r.app.apply from Raft. This thread could be notified every time commitIndex is updated, and would then not need to hold a lock in order to apply, breaking the deadlock.
There are several ways to solve this problem . The easiest way is in App.RPC Call in a.raft.Start Post acquisition a.mutex. However , This means that App.RPC Before having the opportunity to record the facts it wants to be informed ,App.apply May be called , be used for App.RPC Just called Raft.Start The operation of . Another solution that may lead to a cleaner design is , By a dedicated thread from Raft call r.app.apply. This thread can be updated every time commitIndex To be informed of , In this way, there is no need to hold a lock for application , Thus breaking the deadlock .
边栏推荐
- STM32通过串口进入和唤醒停止模式
- 【精品】pinia 基于插件pinia-plugin-persist的 持久化
- Oracle对表进行的常用修改命令
- The "white paper on the panorama of the digital economy" has been released with great emphasis on the digitalization of insurance
- [CVPR 2022] semi supervised object detection: dense learning based semi supervised object detection
- Use source code compilation to install postgresql13.3 database
- Pytest multi process / multi thread execution test case
- 本地部署 zeppelin 0.10.1
- DAY SIX
- 从外企离开,我才知道什么叫尊重跟合规…
猜你喜欢
iMeta | 华南农大陈程杰/夏瑞等发布TBtools构造Circos图的简单方法
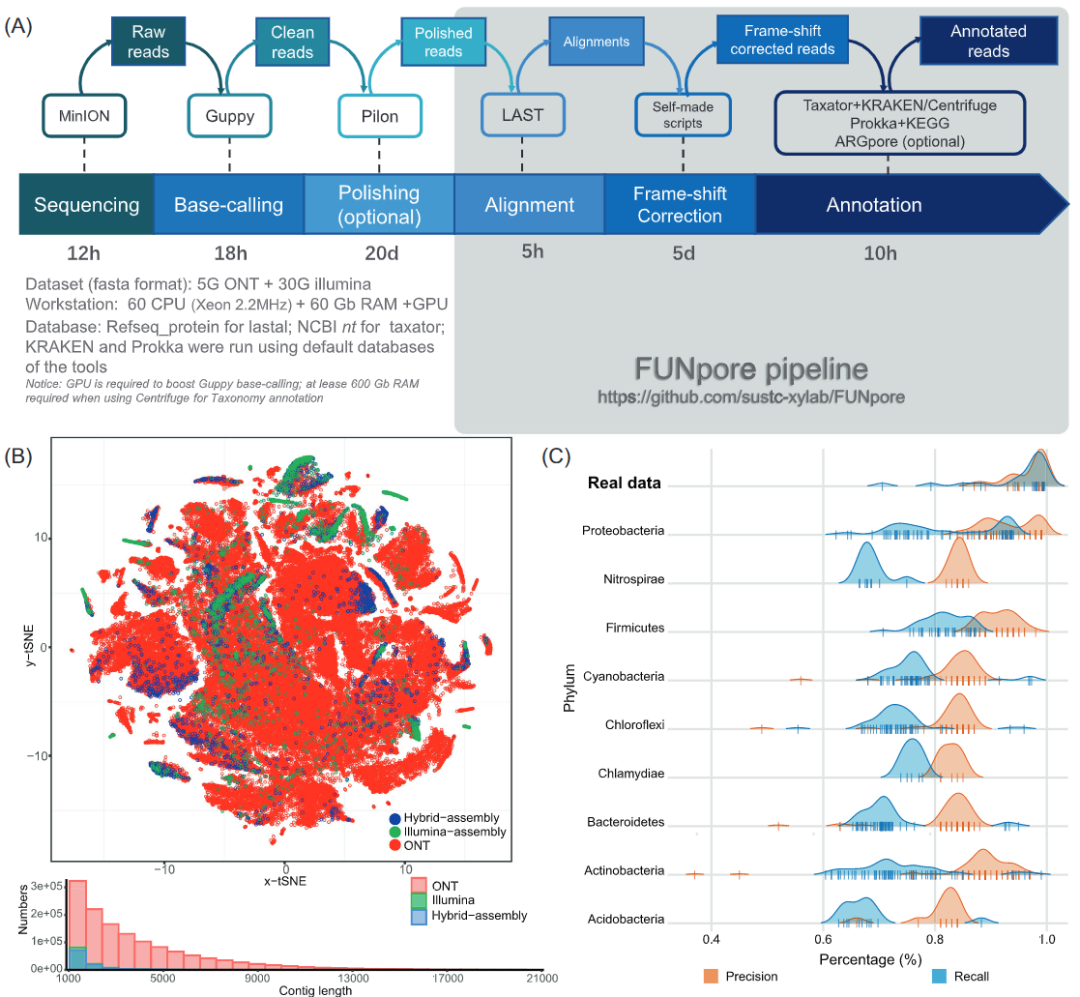
How to find out if the U disk file of the computer reinstallation system is hidden
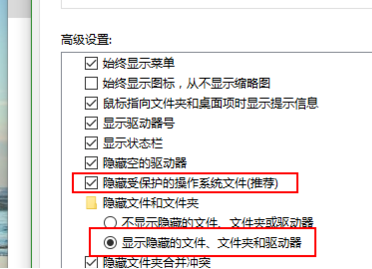
Pytest multi process / multi thread execution test case

Competition between public and private chains in data privacy and throughput
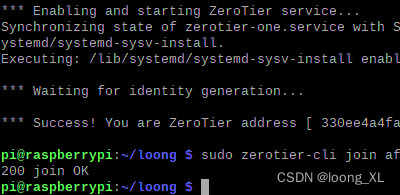
The intranet penetrates the zerotier extranet (mobile phone, computer, etc.) to access intranet devices (raspberry pie, NAS, computer, etc.)
STM32通过串口进入和唤醒停止模式

DAY FIVE
自动化测试工具Katalon(Web)测试操作说明
Introduction au GPIO

快讯 l Huobi Ventures与Genesis公链深入接洽中
随机推荐
The best sister won the big factory offer of 8 test posts at one go, which made me very proud
What is a responsive object? How to create a responsive object?
Yaduo Sangu IPO
【向量检索研究系列】产品介绍
Basic chart interpretation of "Oriental selection" hot out of circle data
kubernetes部署ldap
谷歌百度雅虎都是中国公司开发的通用搜索引擎_百度搜索引擎url
MySQL主从之多源复制(3主1从)搭建及同步测试
SQL的一种写法,匹配就更新,否则就是插入
After 3 years of testing bytecan software, I was ruthlessly dismissed in February, trying to wake up my brother who was paddling
DAY THREE
The largest single investment in the history of Dachen was IPO today
js导入excel&导出excel
【CVPR 2022】半监督目标检测:Dense Learning based Semi-Supervised Object Detection
Unity color palette | color palette | stepless color change function
短链的设计
okcc呼叫中心的订单管理时怎么样的
MVC and MVVM
【无人机】多无人协同任务分配程序平台含Matlab代码
Supersocket 1.6 creates a simple socket server with message length in the header