当前位置:网站首页>Amazon MemoryDB for Redis 和 Amazon ElastiCache for Redis 的内存优化
Amazon MemoryDB for Redis 和 Amazon ElastiCache for Redis 的内存优化
2022-07-06 16:46:00 【亚马逊云开发者】

前言
Amazon MemoryDB for Redis 和 Amazon ElastiCache for Redis 是云上内存数据存储。ElastiCache 通常用作缓存, 而MemoryDB 是一种可持久的数据库,专为具有高性能要求的应用程序而设计。
客户喜欢 Redis 作为内存中数据引擎。随着使用和访问的数据呈指数级增长,充分利用可用内存变得越来越重要。在这篇博文中,我提供了多种策略以及代码片段,以帮助您在使用 MemoryDB for Redis 和 ElastiCache for Redis 时减少应用程序的内存消耗。这有助于优化成本,并允许您在现有集群的实例中容纳更多数据。
在进行这些优化之前,请记住 ElastiCache for Redis 支持数据分层,它会自动将数据放置在内存和本地高性能固态硬盘 (SSD) 中。数据分层非常适合定期访问最高 20% 数据集的应用程序。ElastiCache for Redis 提供了一种便捷的方式,可以以较低的成本将集群扩展到最高 1 PB 的数据。它可以实现每 GB 容量节省 60% 以上,同时对定期访问其数据子集的工作负载的性能影响最小。ElastiCache for Redis 还支持自动扩展,通过添加或移除分片或副本节点来自动水平调整集群。
Amazon MemoryDB for Redis:
https://aws.amazon.com/cn/memorydb/
Amazon ElastiCache for Redis :
https://aws.amazon.com/cn/elasticache/redis/
Redis:
https://insights.stackoverflow.com/survey/2021#most-loved-dreaded-and-wanted-database-love-dread
数据分层:
https://docs.aws.amazon.com/AmazonElastiCache/latest/red-ug/data-tiering.html
每 GB 容量节省 60% 以上:
https://aws.amazon.com/cn/blogs/database/scale-your-amazon-elasticache-for-redis-clusters-at-a-lower-cost-with-data-tiering/
自动扩展,通过添加或移除分片或副本节点来自动水平调整集群:
https://docs.aws.amazon.com/AmazonElastiCache/latest/red-ug/AutoScaling.html
先决条件
在此演练中,您需要具备以下各项:
一个亚马逊云科技账户(您可以使用 Amzaon Free Tier)
一个 ElastiCache for Redis 或 MemoryDB 集群(一个实例就足够了)
您的本地计算机或可连接到集群的远程环境(如 Amazon Cloud9)
远程连接到您的实例的 redis-cli 客户端
具有以下库的 Python 3.5 或更高版本
亚马逊云科技账户:
https://portal.aws.amazon.com/billing/signup#/start/email
Amzaon Free Tier:
https://aws.amazon.com/cn/memorydb/
远程连接:
https://docs.aws.amazon.com/memorydb/latest/devguide/getting-startedclusters.connecttonode.html
要运行这篇博文中的一些示例,您需要以下 Python 库:
pip install redis-py-cluster # 用于连接到您的 elasticache 或 memorydb 集群
pip install faker # 用于模拟不同类型的数据
pip install msgpack # 用于以二进制格式序列化复杂数据
pip install lz4 pyzstd # 用于压缩长数据类型和短数据类型*左滑查看更多
为知道使用了多少内存,redis-cli 提供了 memory usage 命令:
redis-cli -h <your_instance_endpoint> --tls -p 6379
>>memory usage "my_key"
(integer) 153*左滑查看更多
要从 Python 连接到我们的 Redis 集群,我们使用 redis-py-cluster(https://redis-py-cluster.readthedocs.io/en/stable/)。在我们的示例中,为了简单起见,我们忽略了 RedisCluster对象的创建。要检查您是否已连接到 Redis 实例,可以使用以下代码:
>>from rediscluster import RedisCluster
>>HOST="<Your host URL>"
>>redis_db = RedisCluster(host=HOST, port=6379, ssl=True)*左滑查看更多
如果您要执行多个操作,请考虑使用管道(https://redis-py-cluster.readthedocs.io/en/stable/pipelines.html)。管道允许您批量处理多个操作并保存多次网络行程以获得更高的性能。请参阅以下代码:
>>pipe = redis_db.pipeline()
>>pipe.set(key_1, value_1)
...
>>pipe.set(key_n, value_n)
>>pipe.execute()要在将项插入到 Redis 之前检查其大小,我们使用以下代码:
>>import sys
>>x = 2 # x 可以是任何 python 对象
>>sys.getsizeof(x) # 返回对象 x 的大小(以字节为单位)
24为了模拟更真实的数据,我们使用 Faker(https://faker.readthedocs.io/en/master/) 库:
>>from faker import Faker
>>fake = Faker()
>>fake.name()
'Lucy Cechtelar'
>>fake.address()
'426 Jordy Lodge'基本优化
在进行高级优化之前,我们会应用基本优化。这些都是简单的操作,所以我们不在这篇博文中提供代码。
在我们的示例中,我们假设有一个很大的键值对列表。作为间, —> 作为键。作为值,我们有访问次数、报告的名称和最近的操作计数器:
IP:123.82.92.12 → {"visits":"1", "name":"John Doe", "recent_actions": "visit,checkout,purchase"},
IP:3.30.7.124 → {"visits":"12", "name":"James Smith", "recent_actions": "purchase,refund"},
...
IP:121.66.3.5 → {"visits":"5", "name":"Peter Parker", "recent_actions": "visit,visit"}*左滑查看更多
使用以下代码以编程方式插入这些内容:
redis_db.hset("IP:123.82.92.12", {"visits":"1", "name":"John Doe", "recent_actions": "visit,checkout,purchase"})
redis_db.hset("IP:3.30.7.124", {"visits":"12", "name":"James Smith", "recent_actions": "purchase,refund"})
...
redis_db.hset("IP:121.66.3.5", {"visits":"5", "name":"Peter Parker", "recent_actions": "visit,visit"})*左滑查看更多
缩短字段名称
Redis 字段名称在每次使用时都会消耗内存,因此您可以通过使名称尽可能简短来节省空间。在前面的示例中,我们可能希望使用 v,而不是 visits 作为字段名称。同样,我们可以使用 n 代替 name,用 r 代替 recent_actions。我们也可以将键名称缩短为 i 而不是 IP。
在字段本身中,您还可以使用符号缩短常用词。我们可以将最近的操作切换为首字符(v 而不是 visit)。
以下代码是我们之前的示例在简化后的样子:
i:123.82.92.12 → {"v":"1", "n":"John Doe", "r": "vcp"},
i:3.30.7.124 → {"v":"12", "n":"James Smith", "r": "pr"},
...
i:121.66.3.5 → {"v":"5", "n":"Peter Parker", "r": "vv"}*左滑查看更多
在我们的具体示例中,这将节省 23% 的内存。
使用位置指示数据类型
如果所有字段都存在,我们可以使用列表而不是哈希,位置告诉我们字段名称是什么。这允许我们完全删除字段名称。请参阅以下代码:
i:123.82.92.12 → [1, "John Doe", "vcp"],
i:3.30.7.124 → [12, "James Smith", "pr"],
...
i:121.66.3.5 → [5, "Peter Parker", "vv"]在我们的案例中,这将额外节省 14% 的内存。
序列化复杂类型
有多种方法可以序列化复杂的对象,这使您可以高效地存储这些对象。大多数语言都有自己的序列化库(Python 中的 pickle、Java 中的 Serializable 等等)。有些库可以跨语言工作,而且通常空间效率更高,例如 ProtoBuff 或 MsgPack。
以下代码显示了一个使用 MsgPack (https://msgpack.org/)的示例:
import msgpack
def compress(data: object) -> bytes:
return msgpack.packb(data, use_bin_type=True)
def write(key, value):
key_bytes = b'i:'+compress(key) # 我们也可以对键进行序列化
value_bytes = compress(value)
redis_db.set(key_bytes, value_bytes)
write([121,66,3,5] , [134,"John Doe","vcp"])*左滑查看更多
在本例中,原始对象为 73 字节,而序列化对象为 49 字节(空间减少 33%)。
为了恢复该值,MsgPack 非常方便,返回准备使用的 Python 对象:
def decompress(data: bytes) -> object:
return msgpack.unpackb(data, raw=False)
def read(key):
value_bytes = redis_db.get(key)
return decompress(value_bytes)
# 现在我们可以恢复值对象了
value = read([121,66,3,5])特定于 Redis 的优化
为了提供快速访问和 TTL 等功能,Redis 可能需要在内存中使用数据本身所需的额外空间。接下来的两部分可帮助我们将额外开销降至最低。然后我们展示一些可以进一步帮助减少内存的概率结构。
从字符串或列表移动到哈希
在最初的示例中,我们将许多小字符串存储为独立列表。Redis 上的每个条目都有 60 字节(没有过期)或 100 字节(有过期)的额外空间,如果我们存储数百万项(1 亿个条目 x 100 字节 = 10 GB 的开销),这将很有意义。在第一个示例中,它们存储为 Redis 列表:
"i:123.82.92.12" → [1, "John Doe", "vcp"],
"i:3.30.7.124" → [12, "James Smith", "pr"],
...
"i:121.66.3.5" → [5, "Peter Parker", "vv"]在最终的优化中,所有字段都存储在一个哈希中:
mydata → {
"i:123.82.92.12" : "1, John Doe, vcp",
"i:3.30.7.124" : "12, James Smith, pr",
...
"i:121.66.3.5" : "5, Peter Parker, vv"
}*左滑查看更多
这使我们可以为每个条目节省 90 字节。在前面的示例中,假定每个条目都相对较小,表示内存使用量减少了 40%。
转换为较小的哈希(使用压缩列表)
Redis 中的哈希可以在内存中编码为哈希表或压缩列表(Redis 7 中的列表包)。使用哪个参数取决于参数组(https://docs.aws.amazon.com/AmazonElastiCache/latest/red-ug/ParameterGroups.html)中的两个参数:
hash-max-ziplist-value(默认为 64)
hash-max-ziplist-entries(默认为 512)如果键的任何值超过两个配置,它将自动存储为哈希表而不是压缩列表。哈希表使用的内存量是压缩列表的两倍,但对于大哈希可能会更快。其想法是使用压缩列表,同时将每个哈希中的项数保持在合理的数字。
为了在压缩列表中高效地存储项,我们将单个大哈希迁移到许多大小相似的小哈希中:
mydata:001 → {
i:12.82.92.12 : [1, "John Doe", "vcp"],
i:34.30.7.124 : [12, "James Smith", "pr"],
i:121.66.3.5 : [5, "Peter Parker", "vv"]
}
mydata:002 → {
i:1.82.92.12 : [1, "John Doe", "vcp"],
i:9.30.7.124 : [12, "James Smith", "pr"],
i:11.66.3.5 : [5, "Peter Parker", "vv"]
}
...
mydata:999 → {
i:23.82.92.12 : [1, "John Doe", "vcp"],
i:33.30.7.124 : [12, "James Smith", "pr"],
i:21.66.3.5 : [5, "Peter Parker", "vv"]
}*左滑查看更多
为了实现这种空间效率,我们使用以下代码:
import binascii
SHARDS = 1000 # 存储桶数,目标是每个桶少于 1000 项
PREFIX = "mydata:" # 用于轻松地在我们的数据库中查找数据的前缀
def get_shard_key(key: bytes) -> str:
"""
根据 CRC 和分片数量计算给定键的 shard_key。
"""
shard_id = binascii.crc32(key) % SHARDS # 使用模数精确获得 1000 个存储桶
return PREFIX+str(shard_id)
def write(key, value):
shard_key = get_shard_key(key) # 分片是键的函数
redis_db.hset(shard_key, key, value)
write(b'i:21.66.3.5', b'1, John Doe, vcp')*左滑查看更多
要读回这些值,我们使用以下代码:
def read(key):
shard_key = get_shard_key(sample_key)
return redis_db.hget(shard_key, sample_key)
value = read(sample_key)*左滑查看更多
以下屏幕截图显示了如何在 Amazon ElastiCache for Redis 控制台上编辑参数组的示例。
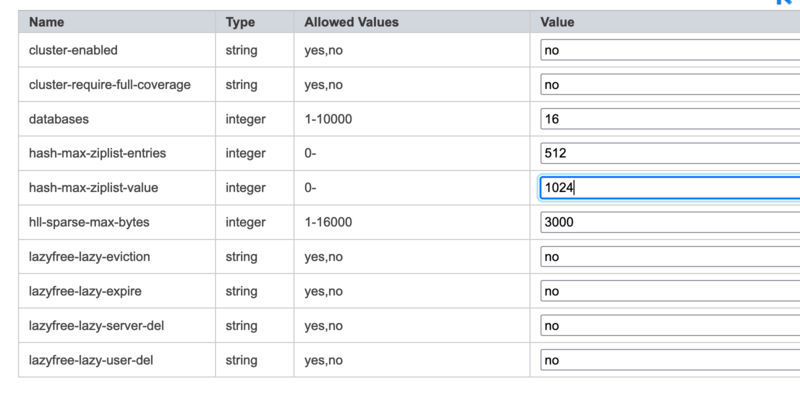
为了确保您实际上使用的是压缩列表,您可以使用 object encoding 命令:
>>object encoding "mydata:001"
"ziplist"
>>memory usage "mydata:001"
(integer) 5337内存使用量也应该比我们存储为哈希列表时少 40% 左右。如果您没有看到类型为压缩列表,请检查两个参数并确保两个条件都得到满足。
使用概率结构
如果您需要计算集合中的项数,但不需要精确,HyperLogLOG (https://redis.com/redis-best-practices/counting/hyperloglog/)是一种原生支持的概率数据结构,用于计算集合中的唯一项。HyperLogLog 算法(https://en.wikipedia.org/wiki/HyperLogLog)能够使用 1.5 kB 的内存以 2% 的典型准确度(标准误差)估计超过 109 的基数。
Bloom 筛选器(https://en.wikipedia.org/wiki/Bloom_filter)也是一种高度节省空间和时间的概率数据结构。尽管原生不支持,但可以实现。Bloom 筛选器用于测试元素是否是误报概率很小(但没有误报)的集合的成员。它允许您以 1% 的误报概率存储少于 10 位的项。
如果您需要简单地检查具有最小冲突机会的等效性,您可以存储内容的哈希值。例如,您可以使用 xxHash (https://github.com/Cyan4973/xxHash)之类的快速、非加密哈希函数:
>>import xxhash
>>hashed_content = xxh32_intdigest(b'134, John William Doe, vcpvvcppvvcc')
>>redis_db.set("my_key",hashed_content)*左滑查看更多
没有办法恢复原始值(除非您把它存储在其他地方),但是我们可以使用哈希版本来检查是否存在:
>>new_content = xxh32_intdigest(b'131, Peter Doe, vcpvvcppvvcc')
>>if redis_db.get("my_key") == new_content:
>> print("No need to store")*左滑查看更多
数据压缩
减少内存消耗的一种最简单的方法是减小键和值的大小。这不是 Redis 所特有的,但特别适用于它。
通常,Redis(以及半结构化和结构化数据库)的压缩与文件压缩有很大不同。原因是,在 Redis 中,我们通常存储短字段。
长数据的压缩
要压缩长数据,您可以使用常用的压缩算法,例如 Gzip、LZO 或 Snappy。在本例中,我们使用了 LZ4(https://github.com/lz4/lz4),它在速度和压缩比之间取得了很好的平衡:
import lz4.frame
from faker import Faker
fake = Faker()
def compress(text: str)-> bytes:
text_bytes = str.encode(text) # 转换为字节
return lz4.frame.compress(text_bytes)
text = fake.paragraph(nb_sentences=100) # 生成包含 100 个句子的段落
compressed_bytes = compress(text)*左滑查看更多
要恢复原始值,我们可以简单地将压缩后的字节传递给 LZ4 库
def decompress(data: bytes) -> str:
return lz4.frame.decompress(data)
original = decompress(compressed_bytes)在本例中,压缩后的字符串比压缩前小 20%。请注意,对于小字符串(通常存储在数据库中),这不太可能产生好的结果。如果您的数据非常大,您可以考虑将其存储在其他地方,例如 Amazon Simple Storage Service (Amazon S3)(https://aws.amazon.com/cn/s3/)。
如前所述,对于小字符串(在 Redis 中更为常见),这不会产生好的结果。我们可以尝试压缩值组(例如值分片),但这会增加代码的复杂性,因此接下来的选项更有可能对我们有所帮助。
自定义基础编码
减少所用空间的一种方法是使用特定数据类型的有限字符范围。例如,我们的应用程序可能会强制要求用户名只能包含小写字母 (a-z) 和数字 (0-9)。如果是这样的话,base36 (https://en.wikipedia.org/wiki/Base36)编码比简单地将它们存储为字符串更有效。
您也可以根据自己的字母创建自己的基础。在本例中,我们假设正在记录石头剪刀布游戏玩家的所有动作。为了有效地对其进行编码,我们将每个动作存储为单个字符串。在我们的示例中,我们将石头表示为 0,将布表示为 1,剪刀表示为 2。然后,我们可以通过将其存储为使用所有潜在值的整数来进一步压缩它:
>>BASE=3
>>ALPHABET="012"
>>player_moves=b"20110012200120000110" # 0 是石头,1 是布,2 是剪刀
>>compressed=int(player_moves, BASE) # 转换为 base-3 数字
2499732264*左滑查看更多
虽然原始 player_moves 字符串需要 20 字节,但压缩后的整数可以存储在 4 字节中(减少 75% 的空间)。解压缩稍微复杂一些:
def decompress(s) -> str:
res = ""
while s:
res+=ALPHABET[s%BASE]
s//= BASE
return res[::-1] or "0"
decompress(2499732264) # 这将返回“20110012200120000110”*左滑查看更多
使用 base-36 可以减少约 64% 的使用空间。有一些常用的编码(https://en.wikipedia.org/wiki/Binary-to-text_encoding)和一些易于使用的库(https://www.npmjs.com/package/base-x)。
使用域字典压缩短字符串
大多数压缩算法(例如 Gzip、LZ4、Snappy)在压缩小字符串(例如人名或 URL)方面效果不佳。这是因为他们在压缩数据的同时了解数据。
一种有效的技巧是使用预训练的字典(https://pyzstd.readthedocs.io/en/latest/#dictionary)。在以下示例中,我们使用 Zstandard 来训练用于压缩和解压缩作业名称的字典:
import pyzstd
from faker import Faker
fake = Faker()
Faker.seed(0)
def data() -> list:
samples = []
for i in range(1024): # 使用 1000+ 个作业进行训练
tmp_bytes = str.encode(fake.job())
samples.append(tmp_bytes)
return samples
job_dictionary = pyzstd.train_dict(data(), 100*1024)*左滑查看更多
拥有 job_dictionary 后,压缩任何随机作业都很简单:
def compress(job_string) -> bytes:
return pyzstd.compress(job_string, 10, job_dictionary)
compressed_job = compress(b'Armed forces technical officer') # 我们可以压缩任何作业*左滑查看更多
解压缩也很简单,但需要原始字典:
uncompressed_job = pyzstd.decompress(compressed_job, job_dictionary)在这个简单的示例中,最初的未压缩作业是 30 字节,而压缩后的作业是 21 字节(节省了 30% 的空间)。
适用于短字段的其他编码技术
短字符串压缩在文件压缩中很常见,但您可以根据用例使用其他方法。您可以从 Amazon Redshift 压缩编码中获得灵感:
Byte-dictionary — 如果数据的基数很小,则可以为符号而不是完整字符串编码索引。这方面的一个示例是客户所在的国家/地区。由于国家/地区数量较少,因此您可以通过仅存储国家/地区的索引来节省大量空间。
Delta — 购买时间之类的内容可能会按差异使用完整时间戳进行存储,差异会更小。
Mostly — 当列的数据类型大于大多数存储值所需的值时,Mostly 编码很有用。
Run length — Run length 编码将连续重复的值替换为由该值和连续出现次数(运行长度)组成的标记。
Text255 和 text32k — Text255 和 text32k 编码对于压缩经常出现相同单词的字符串字段非常有用。
通常,短字符串压缩受益于结构信息约束(例如,IPv4 由 0-255 之间的四个数字组成)和分发信息(例如,许多使用者电子邮件都有一个免费域,如 gmail.com、yahoo.com 或 hotmail.com)。
Amazon Redshift:
https://aws.amazon.com/cn/redshift/
压缩编码:
https://docs.aws.amazon.com/redshift/latest/dg/c_Compression_encodings.html
Byte-dictionary:
https://docs.aws.amazon.com/redshift/latest/dg/c_Byte_dictionary_encoding.html
Delta:
https://docs.aws.amazon.com/redshift/latest/dg/c_Delta_encoding.html
Mostly:
https://docs.aws.amazon.com/redshift/latest/dg/c_MostlyN_encoding.html
Run length:
https://docs.aws.amazon.com/redshift/latest/dg/c_Runlength_encoding.html
Text255 和 text32k:
https://docs.aws.amazon.com/redshift/latest/dg/c_Text255_encoding.html
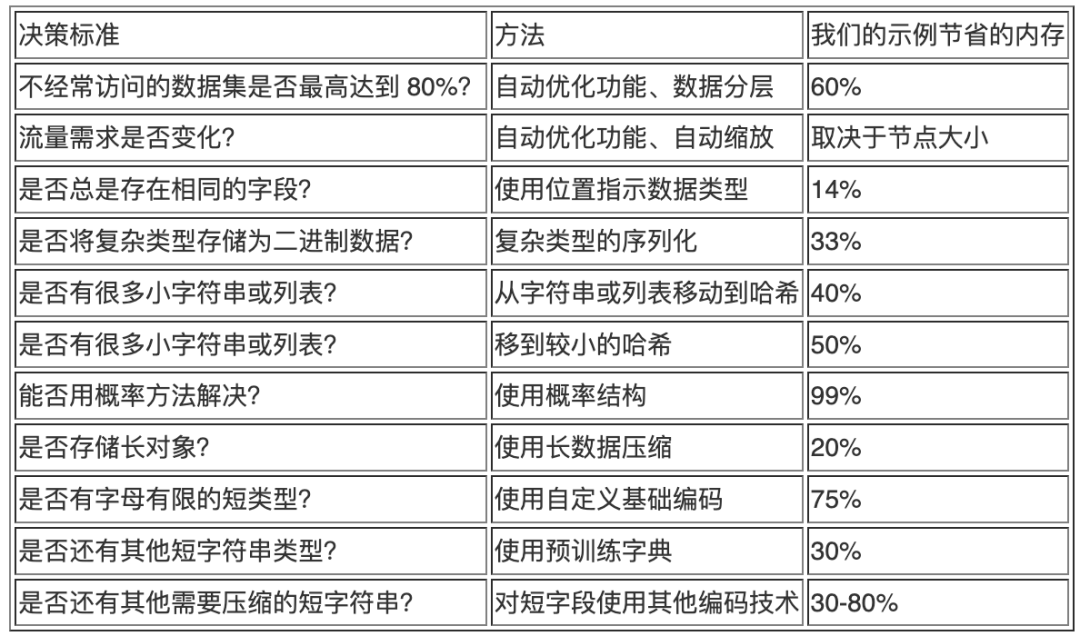
决策表
下表列出了应用每种技术的摘要和必要要求。
结论
在这篇博文中,我向您展示了优化 Redis 实例内存消耗的多种方法。这可能会对成本和性能产生积极影响。任何优化都会在用于读写的空间和时间之间进行权衡。根据数据的存储方式,可能会丢失一些原生 Redis 功能(例如驱逐策略)。Redis 也提供了一个很好的内存优化指南(https://docs.redis.com/latest/ri/memory-optimizations/),与这篇博文有些重叠。
您如何有效地将数据存储在与 Redis 兼容的数据库中?请在评论部分告诉我。
本篇作者

Roger Sindreu
Amazon Web Services 的解决方案构架师。他是一名数据库工程师,在过去的 20 年中一直领导工程团队。他的兴趣是 AI/ML、数据库、FSI 以及与 亚马逊云科技相关的一切。

听说,点完下面4个按钮
就不会碰到bug了!
边栏推荐
- DAY SIX
- 37頁數字鄉村振興智慧農業整體規劃建設方案
- 三句话简要介绍子网掩码
- Racher integrates LDAP to realize unified account login
- Interface joint debugging test script optimization v4.0
- Interesting wine culture
- openresty ngx_ Lua subrequest
- Rails 4 asset pipeline vendor asset images are not precompiled
- Pdf document signature Guide
- Automatic test tool katalon (WEB) test operation instructions
猜你喜欢

DAY SIX
@TableId can‘t more than one in Class: “com.example.CloseContactSearcher.entity.Activity“.

Testers, how to prepare test data
Rider离线使用Nuget包的方法

How can computers ensure data security in the quantum era? The United States announced four alternative encryption algorithms

Liuyongxin report | microbiome data analysis and science communication (7:30 p.m.)
509 certificat basé sur Go
DAY SIX

DAY FIVE

Designed for decision tree, the National University of Singapore and Tsinghua University jointly proposed a fast and safe federal learning system
随机推荐
【CVPR 2022】目标检测SOTA:DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
互动滑轨屏演示能为企业展厅带来什么
Supersocket 1.6 creates a simple socket server with message length in the header
Imeta | Chen Chengjie / Xia Rui of South China Agricultural University released a simple method of constructing Circos map by tbtools
Leecode brushes questions to record interview questions 17.16 massagist
Racher integrates LDAP to realize unified account login
How to use vector_ How to use vector pointer
web渗透测试是什么_渗透实战
2022/2/12 summary
Leecode brush questions record sword finger offer 11 Rotate the minimum number of the array
1000字精选 —— 接口测试基础
Introduction to GPIO
刘永鑫报告|微生物组数据分析与科学传播(晚7点半)
SQL的一种写法,匹配就更新,否则就是插入
Quickly use various versions of PostgreSQL database in docker
Geo data mining (III) enrichment analysis of go and KEGG using David database
基于GO语言实现的X.509证书
Sword finger offer 26 Substructure of tree
app通用功能測試用例
openresty ngx_lua子请求