当前位置:网站首页>Data operation platform - data collection [easy to understand]
Data operation platform - data collection [easy to understand]
2022-07-06 23:57:00 【Java architects must see】
Catalog
Business data collection and conversion
Third party systems API docking
Behavioral data collection
1. Buried point collection
① Cross platform connection
Deterministic method identification
Use the user account system , Can be system generated UserID, It can be a cell phone number , It could be a mailbox , The situation of different products is slightly different , In short, it is the unique identification of the user . If applied to Android、iOS、Web、 WeChat official account operates on four platforms , Each platform uses a unified account system . If Xiao Ming has Android、iOS、PC Three devices , In the morning Android The WeChat official account read a recommendation. , At noon, I logged in to the web page to view the details , Go home in the evening iOS The mobile phone has placed an order , Then you can pass UserID Connect user behavior .
Probability method matching
Use device related indirect data to match ,Cookie、IDFA、 Internet time 、Wifi、IP wait , Analyze through machine learning or other complex rules . But it depends heavily on the diversity of data and algorithms , For a relatively deterministic approach , There is a big gap in accuracy , Not recommended .
② Design of buried point scheme
User behavior is composed of a series of events , contain 5 Basic elements : Who , when , And where , By what means , What happened , A complete buried point scheme consists of events 、 Event attribute and user attribute are composed of three parts :
event : Record users using the website 、APP Or the behavior triggered in the process of an applet .
Part of the user's behavior will be automatically collected in the process of their use , The common ones are : Access related “ Page view ”,“ The length of stay ”; The other part contains specific business meanings , Then it needs to be buried to get , for example :“ register ”、“ Sign in ”、“ payment ” wait .
Event properties : Supplement relevant information for events through attributes , for example : Location , Way and content .
When users generate behavior, they will report specific attribute values , For example, yes. “ Buying Events ” Defined “ Method of payment ” The attribute value , Wechat payment may be reported according to different behaviors , Alipay pay .
for example : Spend 100000 yuan to buy a car on the procurement platform . This action produces a called “ Buy ” Events ; and “ Buy ” event , It can also include :“ brand ”,“ Price ” These two properties , and “ dongfeng ” and “ One hundred thousand yuan ” Is the specific value of the attribute .
Event elements | Element description | Collected data | Example |
|---|---|---|---|
Who | Users involved in the event | The only user ID | H522a3bd525a2af |
When | Time of event | Automatically get the current time of the event | 11 month 11 Japan 00:02:03 |
Where | The location of the incident | Automatic access to IP、GPS Information | 114.242.249.113 |
How | The way it happened | Environment used | Equipment brand :Apple Model of equipment :iPhone 6s operating system :iOS Screen resolution :1920*1680 Operator, : China Unicom Network type :Wifi …… |
What | The content of the incident | Custom collected Events :EventID Event properties :Key-Value | add_to_cart product_name: headset product_price:666 |
user 、 Time 、 Location 、 The environment in which the event occurs can be automatically collected , What events are collected 、 The richer attributes of events need to be reported by the user .
Event templates :
event ID | Event name | Event description | attribute ID | The attribute name | Attribute specification | Property value type |
|---|---|---|---|---|---|---|
PayOrder | Payment order | Trigger... When you click the pay button | paymentMethod | Method of payment | Character | |
ViewDetailPage | Browse page details | Trigger... When you click on the details page | PageID | page ID | Character |
Template example :
platform | event ID | Event display name | Event description | attribute ID | Property display name | Attribute specification | Attribute value data type |
|---|---|---|---|---|---|---|---|
Android,iOS | $signup | register | Triggered when the registration is successful | username | user name | User name entered by the user | character string |
company | Company | Company information | character string | ||||
age | Age | User age | character string | ||||
Android,iOS | login | Sign in | Click to trigger... When login is successful |
Analyze the current stage of application , Set reasonable goals , La Xin 、 Promoting activity, etc ;
Analyze what data needs to be collected to achieve the goal ;
Sort out the events requiring buried points according to the template 、 Event properties
platform : Enter the platform to be buried , Only input... Is supported Android、iOS、Web/H5、 Applet 、 other 、 Unknown this 6 An option , When multiple platforms , Comma separated
event ID: For engineers to bury points , Uniquely identifies the event , Support only 、 Letter 、 Numbers and underscores , Cannot start with a number or underscore , ceiling 125 Half width characters , For preset events only
Event display name : Used to display the event name in the product , Special characters are not supported , ceiling 50 Half width characters
Event description : Used to describe the trigger condition of the event 、 The location of buried points helps engineers understand the requirements of buried points , Special characters are not supported , ceiling 100 Half width characters
attribute ID: Richer description of events , attribute ID The attribute used to uniquely identify the event , The naming rules are the same as those of events ID, When there are multiple attributes , Add rows by yourself
Property display name : Used to display the attribute name , Special characters are not supported , ceiling 50 Half width characters
Attribute specification : Property used to describe the event , Special characters are not supported , ceiling 100 Half width characters
Property value type : Select different attribute value types , Different types have different processing methods when analyzing , Only support defined as character string 、 The number 、 Boolean 、 Date or collection type
User properties : During analysis , More dimensions of registered users need to be introduced , For example, registered users ID、 full name 、 User level and so on , It also needs to be combed , Method is the same as event attribute .
User properties ID | User attribute name | Attribute specification | Property value type | ||||
|---|---|---|---|---|---|---|---|
UserLevel | User level | Upload the user's level information | Character | ||||
User properties ID | Property display name | Attribute specification | Attribute value data type | ||||
username | user name | user name | character string | ||||
company | Company | Company name | character string | ||||
age | Age | User age | character string | ||||
Determine the user dimension to analyze ;
Sort out the user attributes to be uploaded according to the template format :
User properties ID: Uniquely identifies the user dimension described , Support only 、 Letter 、 Numbers and underscores , Cannot start with a number or underscore , ceiling 125 Half width characters , For preset properties only , When there are multiple attributes , Add rows by yourself ;
Property display name : Used to display the attribute name , Special characters are not supported , ceiling 50 Half width characters ;
Attribute specification : Used to explain the meaning of user attributes 、 Reporting time, etc , Special characters are not supported , ceiling 100 Half width characters ;
Property value type : Select different attribute value types , Different types have different processing methods when analyzing , Only support defined as character string 、 The number 、 Boolean 、 date or aggregate type ;
Write the collected buried points to Kafka in , Demand for real-time data consumption of various businesses , We provide separate services for each business Kafka, The traffic distribution module will regularly read the meta information provided by the buried point management platform , All businesses that distribute traffic in real time Kafka in .
③ Client buried point data verification
Verify the execution after embedding points , The best way is to make a visual buried point verification tool according to the actual verification requirements , Or connect with the third-party buried point verification service . But if you don't want to spend this cost , You can also do the following schemes :
When the client has operations , Verify that escalation is triggered correctly ;
View the properties of the reported event ( name 、 Attribute name and type ) Is it in line with expectations ;
Understand the behavior sequence of client operation ;
Website buried point (JS)
When debug mode is on :
debugMode: 1 or 2;SDK The log is output to the browser's console . The log will contain some alarms 、 error , It will also include the content of reported events .
With Chrome For example , Steps are as follows :
· start-up Chrome, And visit websites that have been buried
· Press F12 or Ctl/Cmd + Alt/Opt + I open “ Developer tools ”
· Click on “Console” Tab to enter the console
· Browse the page normally , Then you can see that there are a lot of logs on the console
Next , To facilitate viewing the contents of the event message , We can set keywords in the filter “analysys” Filter out the message .
· SDK Initialize related logs
· Send message to server: ** Actual reporting address **
· Report data related logs
If the log is sent successfully , The console will output :Send message success
When debugging mode is not turned on :
debugMode: 0, Production environments usually turn off debug mode , When debug mode is not on SDK No logs will be sent to the browser's console , This has caused some disadvantages to debugging . However, you can also view the reported event content through the browser's own developer tool . Let's say Chrome For example , Introduce the corresponding test methods .
Steps are as follows :
· start-up Chrome, And visit websites that have been buried
· Press F12 or Ctl/Cmd + Alt/Opt + I open “ Developer tools ”
· Pictured above , Click on “Network” Tab
· Browse the page normally , You can see the reported buried point log in the browser
· Pictured above , Enter... In the filter in the upper left red box “up?”
· Click on each record , Can be in the red box on the right “Request Payload” See the content of the reported message in .
APP Buried point (iOS/Android)
Mobile SDK The log will also be output , Developers can start debugging mode by following the instructions below , adopt SDK Log debugging for . At the same time, we also provide a platform for non developers , View the submission log through the packet capture tool .
developer , First, set the debugging status in the code to enable :
Andorid Environmental Science
AnalysysAgent.setDebugMode(this, 2);
0: close Debug Pattern
1: open Debug Pattern , However, the data sent in this mode is only used for debugging , Not included in platform data statistics
2: open Debug Pattern , The data sent in this mode can be included in the platform data statistics
iOS Environmental Science
AnalysysAgent setDebugMode:AnalysysDebugButTrack
AnalysysDebugOff: close Debug Pattern
AnalysysDebugOnly: open Debug Pattern , However, the data sent in this mode is only used for debugging , Not included in platform data statistics
AnalysysDebugButTrack: open Debug Pattern , The data sent in this mode can be included in the platform data statistics
Use Eclipse、AndroidStudio or Xcode Tools etc. , Please be there. Console Mid search tag by “Analysys”
After successful initialization , The console will output :
· SDK Initialize related logs
· Send message to server: ** Actual reporting address **
· Report data related logs
Log sent successfully , The console will output :Send message success
Non developer , Often App Already installed on the phone , If you want to debug, you need to App Send the traffic to the traffic analysis tool for debugging . Here are some well-known tools for reference :
mitmproxy
https://mitmproxy.org/#mitmweb
Charles
https://www.charlesproxy.com/download/
Fiddler
https://www.telerik.com/fiddler
Steps are as follows :
From the above traffic monitoring tools, select the one that is suitable for you , Install and follow the prompts to send you app Forward traffic to the tool
· Enter in the filter in the tool “up?”
· Normal use app, You can see the reported buried point log in the tool
· Click on each record , You can view the contents of the reported message
④Matomo collection
- Matomo Statistical addition method
A. stay Matomo Create a website on
Edit content
The project website is the target website to be counted , After the statistics code is added, everything that starts with this will be recorded in the Matomo, After adding, the following website records will be generated , Watch that. ID The following statistical codes need to be used
B. Add statistics code
Vue The way
import Vue from 'vue'import VueMatomo from 'vue-matomo'// matomo User statistics -- Similar to friends
Vue.use(VueMatomo, {
// Configure your own... Here piwik Server address and website ID
host: 'https://bayes.test.com/piwik',
siteId: 412,
// according to router Automatic registration
router: router,
// Whether you need to request permission before sending tracking information
// Default false
requireConsent: false,
// Whether to track the initial page
// Default true
trackInitialView: true,
// The final tracking js file name
// Default 'piwik'
trackerFileName: 'piwik'
})
pure Js The way
<!-- Matomo --><script type="text/javascript">
var _paq = _paq || [];
/* tracker methods like "setCustomDimension" should be called before "trackPageView" */
_paq.push(['trackPageView']);
_paq.push(['enableLinkTracking']);
(function() {
var u="//bayes.test.com/piwik/";
_paq.push(['setTrackerUrl', u+'piwik.php']);
_paq.push(['setSiteId', '412']); // Notice the setSiteId, The following number is your website id, stay matomo You can find... On the website
var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
g.type='text/javascript'; g.async=true; g.defer=true; g.src=u+'piwik.js'; s.parentNode.insertBefore(g,s);
})();</script>
<!-- End Matomo Code -->
- vue+vue-matomo Realize the buried point
After installation vue After scaffolding , First introduce vue-matomo:npm i vue-matomo
stay main.js Middle configuration :
import VueMatomo from 'vue-matomo'
Vue.use(VueMatomo, {
host: ` Your own matomo Address `,
siteId: ' This value page needs to go to matomo Go up and apply for ', // siteId value
// according to router Automatic registration , It should be noted that if the value transmitted by a route is too long, it will matomo Will not be able to monitor and report 414, You can't use this method
router: router,
// Whether you need to request permission before sending tracking information
// Default false
requireConsent: false,
enableLinkTracking: true,
// Whether to track the initial page
// Default true
trackInitialView: false,
// The final tracking js file name , Because my side matomo Older version , So it's using piwik, If the current version is new, this value should be matomo
trackerFileName: 'piwik',
debug: true,
userId:' Current user login Id, It can be set according to requirements , Not necessarily , It can also be set after the user logs in successfully '})
Here we are , You can already listen to page access 、 Loading time 、 Number of visits 、 Access time 、 Real time visitors and other data . Pictured :
- matomo Data collection cases
Content collection - example :
<div id="class1" class="class1" data-track-content data-content-name="employee_id_list" data-content-piece="show_id_list">
<span align="center"><a id="btn_exit" href="{ { url_for('.stat')}}" data-track-content data-content-name="stat_pagelink" data-content-piece="stat_pagelink"> Statistical analysis </a></span>
Event collection - example :
_paq.push(['trackPageView']);
_paq.push(['trackEvent', 'Img', 'Clicked', 'handle']);
_paq.push(['trackAllContentImpressions']);
2、 Log collection
Mode one 、 By collecting the log data of the architecture , Thus, a log based user behavior analysis mechanism is formed , The implementation process is as follows :
The overall architecture of log analysis is to use Flume from nginx Collect log files on the same server , And stored in HDFS On the file system , Use mapreduce Cleaning log files , Finally using HIVE Build a data warehouse for offline analysis . Task scheduling uses Shell Script completion , Of course, you can also try some automatic task scheduling tools , for instance AZKABAN perhaps OOZIE etc. . The click stream log files used for analysis are mainly from Nginx Of access.log Log files , It should be noted that it is not used here Flume Pull directly from the production environment nginx Log file , But an extra layer FTP Server to cache all log files , And then use Flume monitor FTP Pull the log files from the specified directory on the server to HDFS Server . Push log files from production environment to FTP The operation of the server can be through Shell Script with Crontab Timer to achieve . Generally in WEB In the system , Users' access to the pages of the site , A series of data such as click behavior will be recorded in the log , Each log record represents a data point in the figure above ; Click stream data focuses on a complete website browsing behavior record after all these points are connected , It can be regarded as a user's browsing of the website session. For example, from which outstation users enter the current website , Which pages of the current website did the user browse next , A series of behavior records such as which pictures, links and buttons are clicked , This overall information is called the click stream record of the user . The off-line analysis system designed this time is to collect WEB These data logs generated in the system , And clean the log content to store distributed data HDFS On the file storage system , Then use HIVE To count the click stream information of all users .
PageViews Modeling examples
Visits Modeling examples
Mode two 、ELK Log analysis system
ELK Is the abbreviation of a group of open source software , It includes Elasticsearch、Logstash and Kibana, At present, the most popular centralized logging solution .
Elasticsearch: It can store large capacity data in near real time , Search and analysis operations . Mainly through Elasticsearch Store all acquired logs .
Logstash: Data collection engine , Support dynamic data acquisition from various data sources , And filter the data , analysis , Enrich , Unified format and other operations , Then store it in the location specified by the user .
Kibana: Data analysis and visualization platform , Yes Elasticsearch Visual analysis of stored data , Show it in the form of a table .
Filebeat: Lightweight open source log file data collector . It is usually installed on the client that needs to collect data Filebeat, And specify the directory and log format ,Filebeat Can quickly collect data , And send it to logstash To analyze , Or send it directly to Elasticsearch Storage .
Redis:NoSQL database (key-value), Also data lightweight message queuing , It can not only cut the peak of high concurrency logs, but also decouple the whole architecture
Logstash The main components are as follows :
inpust: must , Responsible for generating events (Inputs generate events), Commonly used :File、syslog、redis、beats( Such as :Filebeats)
filters: Optional , Responsible for data processing and conversion (filters modify them), Commonly used :grok、mutate、drop、clone、geoip
outpus: must , Responsible for data output (outputs ship them elsewhere), Commonly used :elasticsearch、file、graphite、statsd
Filebeats As a lightweight log collector , It does not occupy system resources , Since its emergence , Quickly updated the original elk framework .Filebeats Send the collected data to Logstash Parse filter , stay Filebeats And Logstash In the process of transmitting data , For safety reasons , Can pass ssl Authentication to enhance security . Then send it to Elasticsearch Storage , And by the kibana Visual analysis .
Business data collection and conversion
The big data platform has a wide range of data sources , According to the source , It can be roughly divided into two categories :
1) Inside
a) Fill in manually
b) flow + Real time data collection
c) Batch
2) external
a) File import
b) Web crawler
c) External interface services
According to the above classification, the following schemes are provided :
1、 Real time data acquisition and conversion
Real time acquisition Flume technology 、 Select message queue Kafka technology , Online real-time processing Storm technology 、 Relational database can choose MySQL、Oracle Multiple types , Real time memory database Redis、 Historical big data storage is optional MongoDB. The architecture of data acquisition system is shown in the figure below :
Flume It's a distribution 、 Highly reliable and available data acquisition system . For different data sources 、 Efficient collection of massive data with different structures 、 Aggregation and transmission , It has good expansibility 、 Scalability and fault tolerance .Flume By a series of called Agent The components of , every last Agent It contains three components , Namely Source、Channel、Sink.Flume Each component of is pluggable 、 Customizable , It is essentially a middleware , It effectively shields the heterogeneity between the data source and the target source , It is convenient for system expansion and upgrading .Source Customizable development from external systems or Agent receive data , And write one or more Channel;Channel It's a buffer , buffer Source Written data , know Sink Send out ;Sink In charge of from Channel Read data from , And send it to the message queue or storage system , Even another Agent.
For different communication protocols or data sources with different data levels , Custom develop a Agent, stay Agent Internal use Memory Channel cache , To improve performance , use Kafka Sink take Channel Data write in Kafka.
in application , Different data sources ( Data producers ) Real time data generated , It needs to go through different systems for logic and business processing , It is written to the historical database and Storm colony ( Data consumers ) Conduct offline big data analysis and online real-time analysis . use Kafka As a message buffer ,Kafka Provides high fault tolerance and scalability , Allows reliable caching of more real-time data , To facilitate repeated reading by multiple consumers .
Storm It is convenient for online real-time processing , Real time data collection , stay Storm Realize modeling processing in 、 Simple statistical analysis 、 Data storage and other functions .Storm According to the requirements of actual business applications , Store the data in a real-time memory database Redis、 Relational database MySQL、 Big historical database MongoDB、HDFS Such as system .
Kafka and Storm from Zookeeper Cluster management , Even though Kafka After downtime and restart, you can find the last consumption record , Then from the point of last outage, continue from Kafka Of Broker In the process of consumption . However, due to the existence of non atomic operations that consume first and then log or record first and then consume , If you have just consumed a message and haven't recorded the information to Zookeeper Similar problems of downtime when , More or less, there will be a small amount of data loss or repeated consumption , Can choose Kafka Of Broker and Zookeeper All deployed on the same machine . The next step is to use user-defined Storm Topology To analyze the data and output it to Redis Cache database ( You can also persist ).
stay Flume and Storm Add a layer in the middle Kafka The messaging system , Because under the condition of high concurrency , Data will grow in a blowout , If Storm The rate of consumption (Storm That's one of the fastest , But there are exceptions , And it is said that now Twitter Open source real-time computing framework Heron Than Storm faster ) Slower than data generation , add Flume Own limitations , It will inevitably lead to a large amount of data lag and loss , So I added Kafka The message system acts as a data buffer , and Kafka Is based on log File Message system , In other words, messages can be persisted on the hard disk , Coupled with its full use Linux Of I/O characteristic , Provides considerable throughput . Use... In the architecture Redis As a database, it is also because in the real-time environment ,Redis It has high reading and writing speed .
2、 Batch data acquisition conversion
There are many schemes for batch data collection , For example, through open source components sqoop、kettle etc. , Or through Ali's DataX Offline synchronization service completed . The execution cycle of batch data can self write scheduled tasks , You can also use the tool's own timing mechanism to complete .
1)Sqoop
Mainly used in Hadoop(HDFS、Hive、HBase) With the database (mysql、postgresql、MongoDB…) Transfer of data between , You can import data from a database into Hadoop Of HDFS in , Can also be HDFS The data in a relational database .
Sqoop Client adopt shell Command to use Sqoop,Sqoop Medium Task Translater Convert the command to Hadoop Medium MapReduce The task performs specific data operations . for example Mysql The data of a table in is synchronized to Hadoop This scene ,Sqoop Will divide the table records into multiple copies , Each is assigned to its own Mapper Go to the ground Hadoop( Ensure synchronization efficiency ), there MapReduce No, reduce, Only map.
2)Kettle
Kettle As an open source ETL Tools , It has relatively complete functions , It also supports the collection and conversion function of multiple data sources , At the same time, it has its own task mechanism , There is no need to manually write scheduled tasks ;kettle Provide Spoon Visualization components , You can complete the creation of conversion tasks and jobs in the form of views , Improve work efficiency .
3)DataX
DataX It is an offline data synchronization tool widely used in Alibaba group / platform , Implementation include MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS And other efficient data synchronization functions among various heterogeneous data sources .
The supported data sources are as follows , You can also develop your own plug-ins :
3、API Interface
adopt Restful API Historical data can be reported to the big data platform through the network , This method is generally applicable to the case where the amount of data is not too large .
Call the interface , Data that conforms to a specific format is represented as POST Report to the server . The receiving server verifies the reported data , If it does not conform to the format, the corresponding error prompt will be returned . The reported data will exist temporarily Kafka in , The stream processing engine will run at about 3000 strip / Seconds to drop the data into the database and can be used for query , The process performance is affected by the server , But the deviation is generally not too large .
Interface protocol :HTTP(S),POST The way
Request address :http(s)://host:port/up
Request data : Requested Body The body stores the specific data to be reported , The data is in clear text JsonArray In the form of . Examples of reported data plaintext are as follows :
[{
"appid": "demo",
"xwho": "8c0eebf0-2383-44bc-b8ba-a5c719fc6194",
"xwhat": "confirmOrder",
"xwhen": 1532514947857,
"xcontext": {
"$channel": " Pea pods ",
"$app_version": "4.0.4.001",
"$model": "MI 6X",
"$os": "Android",
"$os_version": "8.1.0",
"$lib": "Android",
"$platform": "Android",
"$is_login": false,
"$lib_version": "4.0.4",
"$debug": 2,
"
}
}]
Data encoding : Use UTF-8 code . The reported data can be reported in plaintext , You can also compress the data / Report after coding . Compress / The coding process is : to Gzip Compress , Then proceed Base64 code , Finally, put the encoded data directly into Body Just report inside the body .
Response format
The report was successful :{"code":200}
Report failed :{"code":500}
Report data format error :{"code":xxx, "msg":"xxxxx"}, The returned reply message contains "msg" Field , The content is specific exception information .
4、 Web crawler
Web crawlers act as intrusive collectors , Special existence , Involving many security issues , Use with caution .
Third party systems API docking
1、 Docking summary
The most reasonable way to obtain data from a third-party platform is to obtain the required data through an open interface , After obtaining the required interface , The first thing to do is :
1) If you need an account number, you should apply for an account number first .
2) After applying for account number , Develop the interface strictly against the interface documents .
3) Notice every field in the document . Has its special meaning .
4) It is better to write the parameter interface of the splicing third party in the configuration file , Easy to modify
5) Like a third party ( WeChat ,qq) Login authorization , WeChat , UnionPay payment, etc Where splicing parameters are required , Send a request . After success, return the required information for business processing .
2、 Docking program
1) Docking mode
The docking modes between the platform and external systems are mostly web service The way .
System interface standards :
With SOA Architecture based , Service bus technology realizes data exchange and communication between business subsystems 、 Information sharing and integration between external business systems , therefore SOA The system standard is the core interface standard we adopt . It mainly includes :
Service catalog standard : Service catalog API The interface format refers to the country and the metadata guidance specification on the service directory , about W3C UDDI v2 API Structural specifications , take UDDI v2 Of API Model of , Definition UDDI Query and publishing service interface , Customization is based on Java and SOAP Access interface . In addition to based on SOAP1.2 Of Web Service The interface way , For the message based interface JMS perhaps MQ The way .
Exchange standards : Service based switching , use HTTP/HTTPS As a transport protocol , The message body is stored based on SOAP1.2 Agreed SOAP The message format .SOAP The message body includes service data and service operations , Service data and service operations adopt WSDL Describe .
Web Service standard : use WSDL Describe business services , take WSDL Publish to UDDI Used to design / Create services ,SOAP/HTTP The service follows WS-I Basic Profile 1.0, utilize J2EE Session EJBs Implement new business services , Provide... On demand SOAP/HTTP or JMS and RMI/IIOP Interface .
Business process standards : Use standards without extensions BPEL4WS, For business processes, use SOAP Access as a service , Calls between business processes are made through SOAP.
Data exchange security : The security of external access shall be considered when interfacing with external systems , adopt IP White list 、SSL Ensure the legitimacy and security of integrated mutual visits by means of authentication .
Data exchange standards : Formulate unified data exchange standards suitable for both systems , Support automatic data synchronization for incremental data , Avoid manual repeated entry .
2) Interface normative design
There are many interfaces in the system platform , Dependency is complex , The data and interface calls exchanged through the interface must be designed according to the unified interface model . In addition to following the unified data standard and interface specification standard of the project , Implement the functions defined in the interface specification , Need to start with data management 、 Integrity management 、 Interface security 、 Interface access efficiency 、 Design interface specifications in terms of performance and scalability .
Interface definition conventions
The interface message protocol between the client and the system platform and between the system platforms is based on HTTP Agreed REST Style interface implementation , The protocol stack is shown in the figure .
Schematic diagram of interface message protocol stack
The system is in http The application data transmitted in the protocol adopts the method with self interpretation 、 Self contained features JSON data format , The encoding and decoding of communication packets are realized by configuring the implementation components of serialization and deserialization of data objects .
In the interface protocol , Contains the version information of the interface , Service function specification constrained by protocol version , Support the upgrade and expansion of interface cooperation between service platforms . A service provider can support multiple versions of clients at the same time by version difference , Thus, the providers and consumers of component services can meet the actual needs , Independent evolution , Reduce the complexity of system upgrade , Ensure that the system has the ability of flexible expansion and continuous evolution .
Business message agreement
The request message URI The parameters in are UTF-8 Code and go through URLEncode code .
Request interface URL Format :{http|https}://{host}:{port}/
{app name}/{business component name}/{action}; among :
agreement :HTTP REST Formal interface
host: Application support platform interactive communication service IP Address or domain name
port: Port of application support platform interactive communication service
app name: Application name of the application support platform interactive communication service deployment
business component name: Business component name
action: Interface name of business operation request , The interface name can be configured
The message body of the response adopts JSON Data format coding , Character encoding adopts UTF-8.
The root node of the response message is “response”, Each response contains two fixed attribute nodes :“status” and “message”. They represent the return value of the operation and the return message description, respectively , Other child nodes at the same level return object attributes for the business , According to different business types , There are different attribute names .
When the client supports data compression transmission , It needs to be in the header of the request “Accept-Encoding” Field to specify the compression method (gzip), If the message can be compressed and transmitted, the platform compresses the data message of the response and returns it as the response data ,Content-Length Is the compressed data length . For details, see HTTP/1.1 RFC2616.
Response code rule Convention
The response result code is at the end of the response message “status” Properties of the , The corresponding interpretation information is displayed in the response message “message” Properties of the . Interpret messages as end-user readable messages , The terminal application can be presented directly to the end user without parsing . The response result code is 6 Bit string . Depending on the response type , Including the following types of response codes . As shown in the table 4-1 Defined in the .
surface 4-1 Response code correspondence table
Response code | describe |
|---|---|
0 | success |
1XXXXX | System error |
2XXXXX | Illegal input parameter error |
3XXXXX | Application level return code , Define application level exception return . |
4XXXXX | Normal application level return code , Define the application level return description for a specific scenario . |
Data management
A. Business data check
The interface shall provide service data check function , That is to check the legitimacy of the received data , Refuse to receive illegal data and wrong data , To prevent illegal intrusion of foreign data , Reduce the processing load of the host of the application support platform system .
For interfaces , The main contents of its business data inspection are as follows :
• Legitimacy of data format : If data in unexpected format is received . Including the length of the received data , type , Start and end signs, etc .
• Legitimacy of data sources : Such as receiving data from unauthorized interfaces .
• Legitimacy of business type : If an access request other than the service type specified by the interface is received .
For illegal data parsed in business data inspection, the following processing methods shall be provided :
• Incident alarm : Automatic alarm in case of abnormal conditions , So that the system administrator can handle it in time .
• The analysis reason : In the event of an abnormal situation , It can automatically analyze the cause of the error . If the data source is illegal and the business type is illegal , Local records and subsequent management , If the data format is illegal , Analyze the causes of network transmission or end-to-end data processing , And deal with it accordingly .
• Statistical analysis : Regularly make statistical analysis of all illegal records , Analyze whether various sources of illegal data are malicious , And deal with it accordingly .
B. data compression / decompression
The interface shall provide data compression according to specific requirements / Decompression function , To reduce the pressure of network transmission , Improve transmission efficiency , So that the whole system can quickly respond to concurrent requests , Efficient operation .
Using data compression / Decompression function , The transmission process of each type of service shall be analyzed in detail 、 Treatment process 、 Network media for transmission 、 The host system processed and the concurrency of this kind of business 、 Peak value and proportional relationship to all businesses, etc , So as to determine whether such services need to be compressed / Decompression processing . For the service of transferring files , Must be compressed and transmitted , To reduce network pressure , Increase transmission speed .
The compression tool used in the interface must be based on general lossless compression technology , The model and coding of compression algorithm must comply with standards and be efficient , The tool function of the compression algorithm must be a stream oriented function , And provide verification and inspection function .
Integrity management
According to the characteristics of business processing and interface services , The business of the application system mainly includes real-time request business and batch transmission business . The characteristics of the two types of business are as follows :
1. Real time request service :
(1) The transaction processing mechanism is adopted to realize
(2) Service transmission is carried out in the form of data packets
(3) It requires high real-time transmission and processing
(4) There are high requirements for data consistency and integrity
(5) Ensure efficient processing of a large number of concurrent requests
2. Batch transmission service :
(1) Business transmission is mainly in the form of data files
(2) The service receiver can handle a large number of transmissions concurrently , It can adapt to peak transmission and processing
(3) High reliability of transmission is required
According to the above characteristics , Integrity management for real-time trading business , To ensure the integrity of the transaction ; For batch transmission services , To ensure the integrity of data transmission .
3) Responsibilities of both sides of the interface
Message sender
Follow the verification rules specified in this interface specification , Provide relevant verification functions for interface data , Ensure data integrity 、 accuracy ;
The platform of message initiation supports timeout retransmission mechanism , The number of retransmissions and retransmission interval can be configured .
Provide interface metadata information , Including interface data structure 、 Inter entity dependencies 、 Calculate the relationship 、 Association relationship and various management rules in the process of interface data transmission ;
Provide encryption function for sensitive data ;
Timely solve the problems on the side of the data provider in the process of providing interface data ;
Message responder
Follow the verification rules specified in this interface specification , Verify the received data , Ensure data integrity 、 accuracy .
Timely carry out relevant transformation of the system according to the change instructions provided by the message sender .
Timely respond to and solve the problems in the process of interface data reception .
exception handling
An exception occurred during the call to the interface process , If the process is abnormal 、 Data exception 、 Session transfer exception 、 Retransmission exception, etc , Perform corresponding exception handling , Include :
Generate an exception record file for the record generating the exception .
For exception records that can be recycled , Carry out automatic or manual recycling .
Log abnormal events , Contains exception categories 、 Time of occurrence 、 Exception description and other information .
When the interface call is abnormal , Perform relevant exception handling according to pre configured rules , And conduct automatic alarm .
4) Interface scalability planning and design
The version information of the communication interface between each system defines the data protocol type of interaction between each system platform 、 The functional features of the system interface released by a specific version 、 Interface specifications such as access parameters of specific functions . Through the version division of interface protocol , Upgrade for client 、 Upgrading of other integrated systems 、 And the deployment of the system provides a high degree of freedom and flexibility .
The system can realize the downward compatibility of the interface according to the interface protocol version contained in the interface request . The system platform can be based on the cluster strategy of the system , Deploy by protocol version , You can also deploy multiple versions simultaneously . Because the system platform can support multiple versions of external systems and client application access systems at the same time , Especially when a new version of the client is released , Users are not required to force upgrade , It can also reduce the probability of forced upgrade installation package release . So as to support the continuous evolution of the separation of the system client and the system platform .
5) Interface security design
In order to ensure the safe operation of the system platform , All kinds of integrated external systems should ensure their access security .
Interface security is an important part of platform system security . Ensure the safety of the interface , The technical security control is realized through the interface , Be aware of security incidents “ You know 、 controllable 、 Predictable ”, It is an important basis for system security .
According to the interface connection characteristics and business characteristics , Develop a special security technology implementation strategy , Ensure the safety of data transmission and data processing of the interface .
The system shall implement interface security control at the network boundary of the access point of the interface .
The security control of the interface logically includes : Safety assessment 、 Access control 、 Intrusion detection 、 password authentication 、 Security audit 、 prevent ( poison ) Malicious code 、 Encryption, etc .
Safety assessment
Security managers use network scanners regularly ( Once a week )/ Irregular ( When new security vulnerabilities are discovered ) Conduct vulnerability scanning and risk assessment of the interface . The scanning objects include the interface communication server itself and the switch associated with it 、 Firewall, etc , Require scanning and evaluation by scanner , Discover network vulnerabilities that can be exploited by intruders , And give comprehensive information of detected vulnerabilities , Including the location 、 Describe in detail and suggest improvements , So as to improve the security strategy in time , Reduce security risks .
The security manager uses the system scanner to check the operating system of the interface communication server regularly ( Once a week )/ Irregular ( When new security vulnerabilities are discovered ) Security vulnerability scanning and risk assessment . On the interface communication server operating system , Detect vulnerabilities inside the server through the scanner agent attached to the server , Including the lack of security patches 、 A password that can be guessed in the dictionary 、 Improper user rights 、 Incorrect system login permissions 、 Whether there are hacker programs inside the operating system , Security service configuration, etc . In addition to operating system level security scanning and risk assessment, the application of system scanner also needs to realize document baseline control .
The interface configuration file includes the configuration file of mutual coordination between interface services 、 Configuration file for coordination between system platform and interface peer system , Strictly control the configuration file of interface service application , And the password plaintext should not appear in the configuration file , The system permission configuration is limited to the minimum permission that can meet the requirements , Key configuration files are encrypted and saved . In order to prevent illegal modification or deletion of the configuration file , The configuration file is required to be subject to file level baseline control .
Access control
Access control mainly controls the mutual access between the end-to-end system and the application support platform through the firewall , Avoid abnormal access between systems , Ensure the availability of interface interaction information 、 Integrity and confidentiality . In addition to ensuring the security of the interface itself, access control , It also further ensures the safety of the application support platform .
In order to effectively resist the threat , Heterogeneous dual firewall structure shall be adopted , Improve the difficulty of destroying the security access control mechanism of firewall . The dual firewall adopts heterogeneous mode in type selection , That is, completely heterogeneous firewalls of different manufacturers and brands are adopted . meanwhile , At least one of the dual firewalls shall have the ability to interact with the real-time intrusion detection system . When an attack or improper access occurs , The real-time intrusion detection system detects relevant information , Notify the firewall in time , The firewall can be configured dynamically automatically , Automatically block normal access to the source address within a defined time period .
The system to interface is integrated, and the system only opens specific ports defined by the application .
Adopt the address translation function of firewall , Hide the system internal network , Provide the translated interface communication server address and port to the agent system , Prohibit the access of the interface end-to-end system to other addresses and ports .
Yes / Log all access that does not pass through the firewall .
Intrusion detection
The interface security mechanism shall have intrusion detection function (IDS) function , Real time monitoring of suspicious connections, illegal access and other security events . Once the intrusion to the network or host is found , Alarm shall be given and corresponding safety measures shall be taken , Including automatically blocking communication connections or implementing user-defined security policies .
Implement network and host based intrusion detection . Detect attacks and illegal access , Automatically disconnect , And notify the firewall to block the access to the source address within the specified time period , Log and alarm according to different levels , Implement automatic recovery policies for important system files .
password authentication
For the request for business operation of relevant integrated systems through the interface security control system , Implement one-time password authentication .
To ensure the safety of the interface , Strong password authentication mechanism is required for the operation and management of interface communication server and other equipment , That is, dynamic password authentication mechanism is adopted .
Security audit
In order to ensure the safety of the interface , The system log of the interface communication server is required 、 The application logs of the interface application server are collected in real time 、 Sorting and statistical analysis , Archive on different media .
Protection against malicious code or viruses
because Internet Provide customers with WEB service , therefore , about Internet The interface shall establish a powerful anti malicious code system at the network boundary point , The system can filter malicious code based on network in real time . Establish a centralized anti malicious code system control and management center .
encryption
In order to improve the confidentiality of interface communication information , At the same time, ensure the security of the application support platform , Link encryption can be implemented for relevant communication between the system platform and the interface integration system 、 Network encryption or application encryption , Ensure that irrelevant personnel and irrelevant applications cannot obtain key business information through network link monitoring , Fully ensure the security of business information .
3、 Concrete realization
1) Native JDK structure HTTP Requesting client , call API
Manually create HTTP Connect , And write the data to the stream , Then convert the data into JSON Object parsing
2) stay SpringBoot Next use RestTemplate, And how to extract the configuration API
Extract some configurations , It is common practice to run different configuration files in different environments . For example, we can put the above appKey Put it in application.yml In profile .
3) Use OpenFeign And how to extract the configuration API
take API Calling becomes as convenient as calling a normal interface . The original OpenFeign Do not rely on Spring Independent use ( https://github.com/OpenFeign/feign),SpringCloud Integrated OpenFeign, stay SpringCloud2.x,Feign Become SpringCloud First level projects ( https://cloud.spring.io/spring-cloud-openfeign/).
OpenFeign It provides a solution for the call between services under the microservice architecture , At the same time, it can be combined with other components to achieve load balancing HTTP client .
User data association
The association of user data collected from different data sources can be based on ID-Mapping Technical realization id Data Association .
At present, there are two ways to realize data association: services provided by third parties and self-development :
1、 Three party service
There are many options for third-party services , You can use Ali 、 Huawei 、 Various related solutions or services provided by Shence and other manufacturers , Native development support , There are also direct SAAS How to support . With Ali's ID-Mapping The scheme of the system OneData The system, for example
2、 Self development
1) be based on ID-Mapping The implementation of user data association can be summarized into the following three types :
① Based on the account system, the most commonly used method in enterprises is based on the account system ID To get through , When users register , Give the user a uid, With uid To strongly associate the information of all registered users .
② Device based : For unregistered users, you can use the terminal device ID Accurate identification , contain Android/iOS Identification of two types of mainstream terminals ; adopt SDK Various kinds ID Collection and reporting , Backstage use ID Relational libraries and calibration algorithms , Real-time generation / Retrieve the terminal unique ID And issue .
③ Based on account number & equipment : Combine various accounts 、 Relationship between various equipment models , And user data such as equipment usage rules ; Adopt rules and regulations 、 Methods of data mining algorithms , The output relationship is stable ID The relationship is right , And generate a UID As the identification code that uniquely identifies the object .
2) Technical realization ID-Mapping
① With the help of redis
a. Extract various identifiers from log data id
b. The extracted identification id, Go to redis identification id Query the library for the existence of
c. If it doesn't exist , Then create a new one " Unified logo "+“id set”
d. If it already exists , Then use the existing unified identity
② Calculate with the aid of a graph
By means of graph calculation , To find all kinds of id Identify the association between , To identify which id The logo belongs to the same person ;
The core idea of graph Computing :
Express the data as “ spot ”, Point to point can be established through some kind of business meaning “ edge ”; then , You can start from the point 、 Find various types of data relationships on the edge : Like connectivity 、 Shortest path planning, etc ;
The overall implementation process :
A. All user identification fields in the data of the current day will be displayed , And the association between flag fields , Generate point set 、 Edge set
B. Put the last day's ids->guid The mapping relation of , Also generate point sets 、 Edge set
C. Set the above two types of points 、 Edge sets are combined to produce a graph
D. Then execute... On the above diagram “ maximal connected subgraph ” Algorithm , Get a connected subgraph result
E. What to get from the result graph id In the same group , And generate a unique identification
F. Compare the unique ID generated in the above steps with that of the previous day ids->guid The mapping table ( If a person already exists guid, The original guid)
Manual data acquisition
Mainly through the implementation of data import tools , To realize the collection of manual processing data ; For example, customize the data template , After filling in the data template manually , Import and upload... In the data tool , Then enter the automatic file processing mechanism process of the big data platform .
Data output
Data export methods include API export 、 File export 、 Consumption message data 、 Database export 、 Tools export in centralized mode .
1)API export
Custom development data output API Interface , Realize external data query or export data file , The interface is made into a detailed reference 《2.2.1.3 Third party systems API docking - Interface normative design 》, Output API The call of is roughly divided into the following steps :
authentication -> For a link -> download / data
Through the external API Interface , Provide external data output .
2) File export
It can be visualized , Provides page level operations , Export the required data file , The premise is to obtain the corresponding permission .
3) Consumption message data
With kafka For example , Meet more usage scenarios by consuming real-time data . The server receives a SDK After sending the data , It does some preprocessing to the data and writes it to the message queue Kafka For various calculation modules in the middle and downstream and external use .
Be careful :
A. The server that starts consumption needs to authenticate with the data server , Make the consumer server and the data server in the same network segment or network interworking , And can parse the data server host.
B. Try to choose compatible kafka edition , The higher version server is compatible with the lower version client , On the contrary, it is prone to compatibility problems
① Consumption parameters
Parameter name | Parameter values |
|---|---|
topic | event{appid}/profile{appid}( among {appid} Of a project appid) |
partition | partitionid( from 0 Start , At least 3 individual partition) |
zookeeper | ark1:2181,ark2:2181,ark3:2181 |
broker | ark1:9092,ark2:9092, ark3:9092 |
② Consumption data
Consumption has shell、 Native API And so on , You can choose a way suitable for the use scenario .
Here are two Shell An example of how to start consumption , Use Shell The method can write data to a file for post-processing by redirecting standard output or directly use a pipeline as input to other processes , It can interface with processing programs implemented in various programming languages .
Use Kafka Console Consumer
· have access to Kafka Self contained Kafka Console Consumer Consume... From the command line , For example, start consuming from the latest data :bin/kafka-console-consumer.sh --zookeeper ark1:2181 --topic event_topic
· Can be stdout Output to a file or as input to other data processing processes .
Use Simple Consumer Shell
· Use Simple Consumer Shell Can achieve more flexible consumption , for example :
bin/kafka-run-class.sh kafka.tools.SimpleConsumerShell \
--broker-list ark2:9092 \
--offset 1234 \
--partition 2 \
--topic event_topic \
--print-offsets
③ data format
The format of the consumed data is basically the same as that of the imported data .
4) Database export
namely JDBC、presto-cli、python or R Data query , Achieve more efficient 、 The stability of the SQL A query , This time, we use JDBC The way .
JDBC Information
Field | Information |
|---|---|
jdbc url | jdbc:presto://xxxx.xxxx.xxx:port/hive/default |
driver | com.facebook.presto.jdbc.PrestoDriver |
user | daxiang |
SSL | true |
password | edit /etc/presto/presto-auth.properties The file to view |
SSLKeyStorePath | presto.jks Path to file , It's usually /etc/presto/presto.jks |
SSLKeyStorePassword | The value can be in a stand-alone environment ark1, Cluster environment /etc/presto/config.properties Found in file , Corresponding http-server.https.keystore.key Value |
5) Tool export
It can be exported externally through self-developed export tools or third-party export tools , The output data can be obtained by downloading the authorized data export tool .
边栏推荐
- There are only two TXT cells in the ArrayExpress database. Can you only download the sequencing run matrix from line to ENA?
- The programmer refused the offer because of low salary, HR became angry and netizens exploded
- SQL的一种写法,匹配就更新,否则就是插入
- DAY THREE
- GPIO簡介
- 求帮助xampp做sqlilab是一片黑
- 每年 2000 亿投资进入芯片领域,「中国芯」创投正蓬勃
- web渗透测试是什么_渗透实战
- MySQL主从之多源复制(3主1从)搭建及同步测试
- Please help xampp to do sqlilab is a black
猜你喜欢

量子时代计算机怎么保证数据安全?美国公布四项备选加密算法
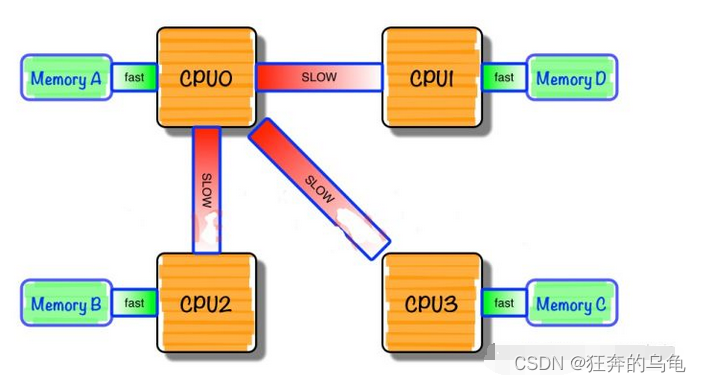
Server SMP, NUMA, MPP system learning notes.

谁说新消费品牌大溃败?背后有人赢麻了

Close unregistering application XXX with Eureka with status down after Eureka client starts
《数字经济全景白皮书》保险数字化篇 重磅发布

氢创未来 产业加速 | 2022氢能专精特新创业大赛报名通道开启!
![[communication] optimal power allocation in the uplink of two-layer wireless femtocell network with matlab code](/img/47/741b89d94a2b0003937f32bdedfa19.png)
[communication] optimal power allocation in the uplink of two-layer wireless femtocell network with matlab code

英国都在试行4天工作制了,为什么BAT还对996上瘾?
Basic chart interpretation of "Oriental selection" hot out of circle data

专为决策树打造,新加坡国立大学&清华大学联合提出快速安全的联邦学习新系统
随机推荐
pytest多进程/多线程执行测试用例
PostgreSQL使用Pgpool-II实现读写分离+负载均衡
Rider离线使用Nuget包的方法
[communication] optimal power allocation in the uplink of two-layer wireless femtocell network with matlab code
快讯 l Huobi Ventures与Genesis公链深入接洽中
Why is bat still addicted to 996 when the four-day working system is being tried out in Britain?
Matplotlib draws a histogram and adds values to the graph
快手的新生意,还得靠辛巴吆喝?
leetcode:236. The nearest common ancestor of binary tree
Experiment 5: common automation libraries
1000字精选 —— 接口测试基础
DAY FIVE
(leetcode) sum of two numbers
【系统分析师之路】第七章 复盘系统设计(面向服务开发方法)
求帮助xampp做sqlilab是一片黑
GEO数据挖掘(三)使用DAVID数据库进行GO、KEGG富集分析
Wasserstein Slim GAIN with Gradient Penalty(WSGAIN-GP)介绍及代码实现——基于生成对抗网络的缺失数据填补
什么是响应式对象?响应式对象的创建过程?
Interface joint debugging test script optimization v4.0
【自动化测试框架】关于unittest你需要知道的事