当前位置:网站首页>Alexnet experiment encounters: loss Nan, train ACC 0.100, test ACC 0.100
Alexnet experiment encounters: loss Nan, train ACC 0.100, test ACC 0.100
2022-07-07 00:36:00 【ddrrnnpp】
scene : Data sets : Official fashionminst + The Internet :alexnet+pytroch+relu Activation function
Source code :https://zh-v2.d2l.ai/chapter_convolutional-modern/alexnet.html
Knowledge point : Gradient explosion , Gradient dispersion
Learning literature ( Keep up with the big guys ) Yes :
https://zh-v2.d2l.ai/chapter_multilayer-perceptrons/numerical-stability-and-init.html
https://www.bilibili.com/video/BV1X44y1r77r?spm_id_from=333.999.0.0&vd_source=d49d528422c02c473340ce042b8c8237
https://zh-v2.d2l.ai/chapter_convolutional-modern/alexnet.html
https://www.bilibili.com/video/BV1u64y1i75a?p=2&vd_source=d49d528422c02c473340ce042b8c8237
Experimental phenomena :
Phenomenon one :
1、 As soon as the code starts running, the following occurs 
Phenomenon two :
2、 After I try to reduce the learning rate , Appear halfway loss nan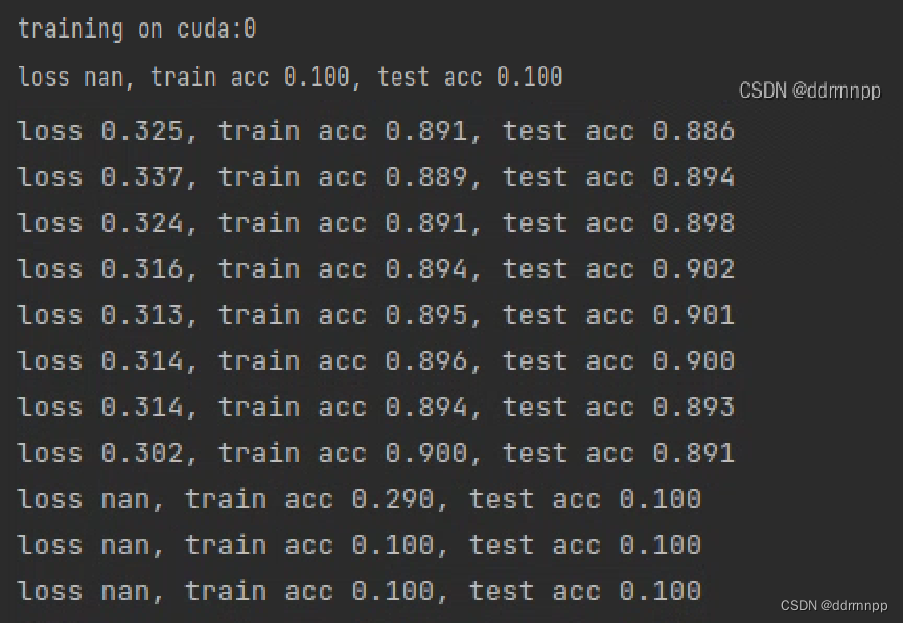
Phenomenon three :
Friends a: Sometimes running is no problem , The network has not changed much , Sometimes there are loss nan, Sometimes it doesn't appear
Friends b: Possible causes : Influence of random initialization variable value
Friends a: Try a solution : Changed random seeds , The rounds that appear are just changed 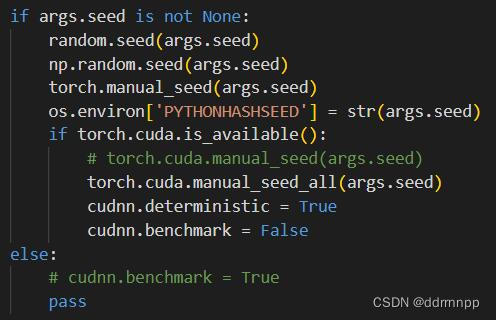
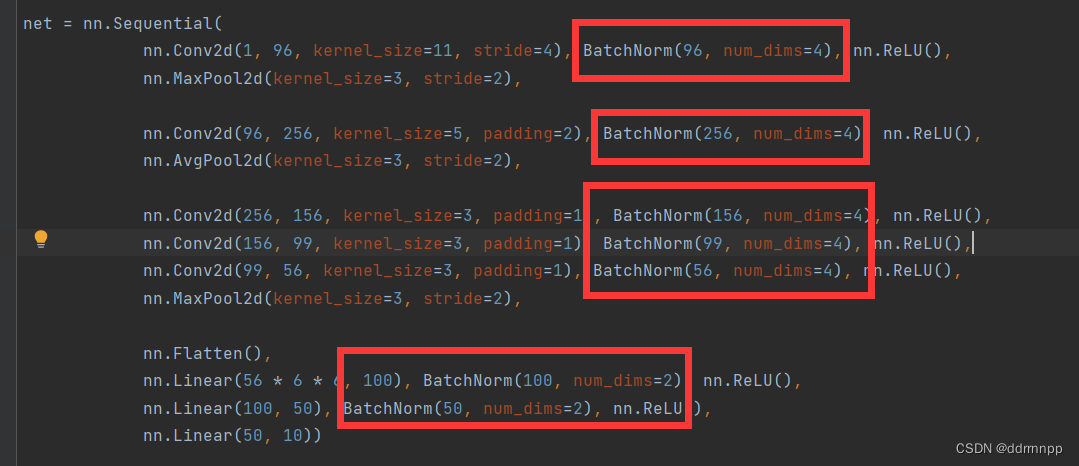
My shortest path solution : Join in BN layer ( What eats mice is a good cat ,hhh)
https://zh-v2.d2l.ai/chapter_convolutional-modern/batch-norm.html
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# adopt is_grad_enabled To determine whether the current mode is training mode or prediction mode
if not torch.is_grad_enabled():
# If it is in prediction mode , The mean and variance obtained by directly using the incoming moving average
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# The case of using the full connection layer , Calculate the mean and variance on the characteristic dimension
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# Use of two-dimensional convolution , Calculate the channel dimension (axis=1) The mean and variance of .
# Here we need to keep X So that the broadcast operation can be done later
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# In training mode , Standardize with the current mean and variance
X_hat = (X - mean) / torch.sqrt(var + eps)
# Update the mean and variance of the moving average
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # Zoom and shift
return Y, moving_mean.data, moving_var.data
class BatchNorm(nn.Module):
# num_features: The number of outputs of the fully connected layer or the number of output channels of the convolution layer .
# num_dims:2 Represents a fully connected layer ,4 Represents a convolution layer
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# Stretch and offset parameters involved in gradient sum iteration , Initialize into 1 and 0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# Variables that are not model parameters are initialized to 0 and 1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# If X Not in memory , take moving_mean and moving_var
# Copied to the X On the video memory
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# Save the updated moving_mean and moving_var
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y
csdn Other solutions :

Principle 1 :
https://www.bilibili.com/video/BV1u64y1i75a?p=2&vd_source=d49d528422c02c473340ce042b8c8237
1、 Gradient derivation + The chain rule


1.1、relu Derivation property of activation function + Gradient explosion
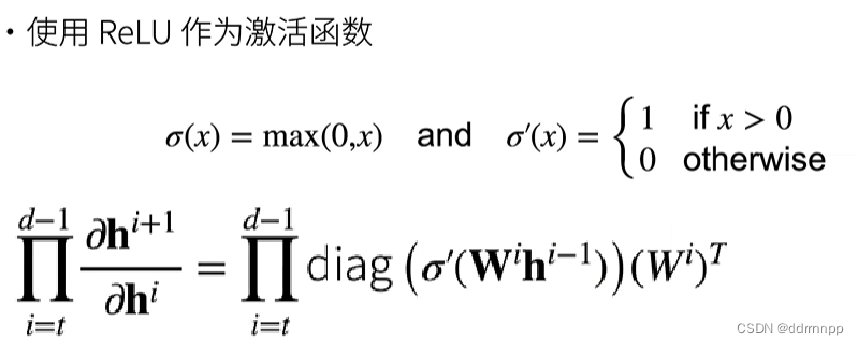
1、relu The derivative of the activation function of 1 or 0
2、 Gradient explosion : Because of the chain rule of derivatives , continuity Multiple layers are greater than 1 The gradient of the product Will make the gradient bigger and bigger , Eventually, the gradient is too large .
3、 Gradient explosion Will make the parameters of a certain layer w Too big , Cause network instability , In extreme cases , Multiply the data by a big w There is an overflow , obtain NAN value .
1.2、 The problem of gradient explosion :

2.1、sigmoid Derivation property of activation function + The gradient disappears 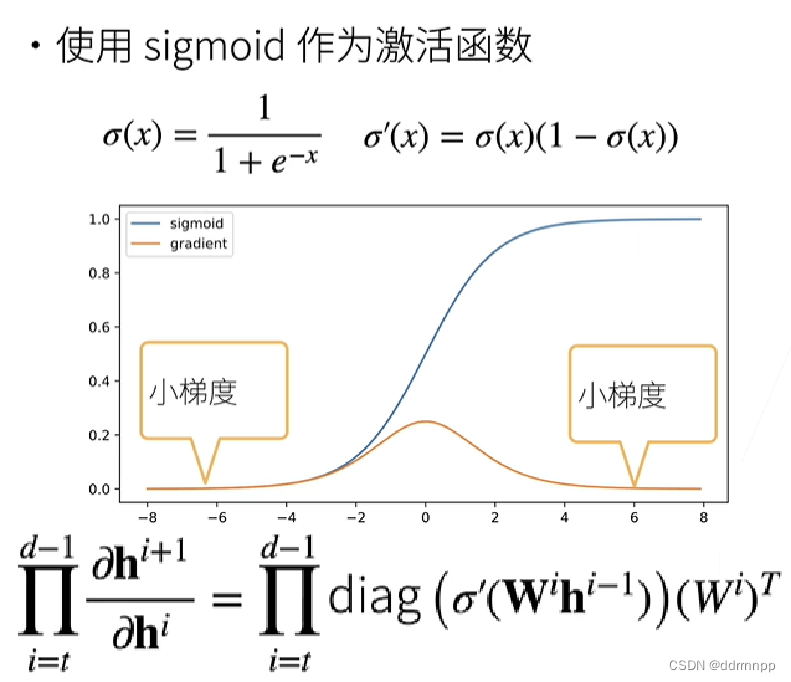
1、 Because of the chain rule of derivatives , In successive layers , take Less than 1 The gradient of the product Will make the gradient smaller and smaller , Finally, the gradient in the first layer is 0.
2.2、 The problem of gradient disappearance :

Analysis of experimental phenomena :
1、relu Activation function
2、 Adjusting the learning rate can make the network output halfway nan
------》 Conclusion : Gradient explosion
Principle 2 :
https://www.bilibili.com/video/BV1X44y1r77r?spm_id_from=333.999.0.0&vd_source=d49d528422c02c473340ce042b8c8237
1、alexnet Relatively deep network :

2、 What is extracted from batch normalization is “ Small batch ”, With certain Randomness . a certain extent , The small batch here will To the network Bring some The noise Come on Control model complexity .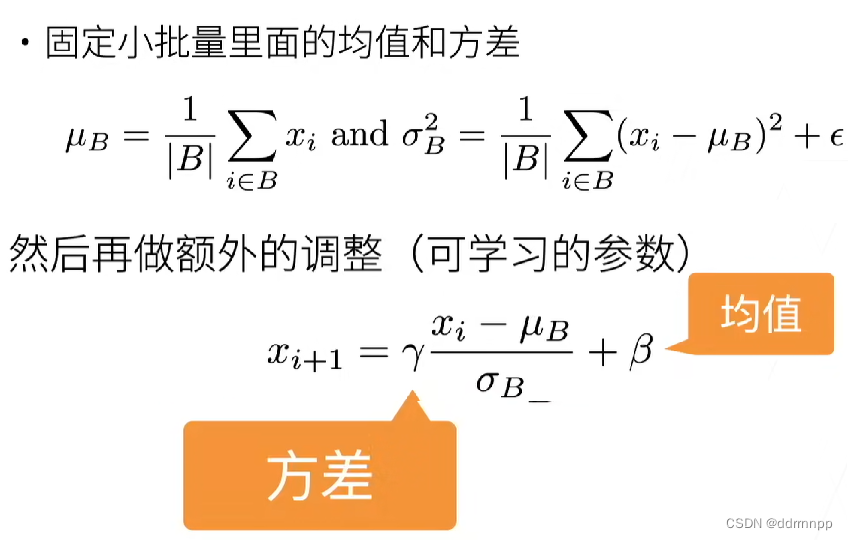
3、 After batch normalization ,lr The learning rate can be set to a large number , have Accelerate convergence The role of
Thank you very much for Li Mu's explanation video !!!!, This paper starts with a practical problem , Understand the knowledge points explained by the boss . It's unique
, If there is any infringement 、 The same 、 The error of !!, Please give me some advice !!!!!

边栏推荐
- Article management system based on SSM framework
- Lombok 同时使⽤ @Data 和 @Builder 的坑,你中招没?
- How can computers ensure data security in the quantum era? The United States announced four alternative encryption algorithms
- Command line kills window process
- GPIO简介
- 智能运维应用之道,告别企业数字化转型危机
- After leaving a foreign company, I know what respect and compliance are
- 【vulnhub】presidential1
- 37 page overall planning and construction plan for digital Village revitalization of smart agriculture
- 48 page digital government smart government all in one solution
猜你喜欢

DAY SIX

DAY FOUR
Uniapp uploads and displays avatars locally, and converts avatars into Base64 format and stores them in MySQL database
Geo data mining (III) enrichment analysis of go and KEGG using David database

Designed for decision tree, the National University of Singapore and Tsinghua University jointly proposed a fast and safe federal learning system
Clipboard management tool paste Chinese version
智能运维应用之道,告别企业数字化转型危机
DAY ONE

The difference between redirectto and navigateto in uniapp

【软件逆向-求解flag】内存获取、逆变换操作、线性变换、约束求解
随机推荐
What is AVL tree?
沉浸式投影在线下展示中的三大应用特点
Pdf document signature Guide
37 page overall planning and construction plan for digital Village revitalization of smart agriculture
[daily problem insight] prefix and -- count the number of fertile pyramids in the farm
Article management system based on SSM framework
SQL的一种写法,匹配就更新,否则就是插入
Supersocket 1.6 creates a simple socket server with message length in the header
rancher集成ldap,实现统一账号登录
"Latex" Introduction to latex mathematical formula "suggestions collection"
JWT signature does not match locally computed signature. JWT validity cannot be asserted and should
The way of intelligent operation and maintenance application, bid farewell to the crisis of enterprise digital transformation
Hero League | King | cross the line of fire BGM AI score competition sharing
DAY SIX
Racher integrates LDAP to realize unified account login
刘永鑫报告|微生物组数据分析与科学传播(晚7点半)
The programmer resigned and was sentenced to 10 months for deleting the code. Jingdong came home and said that it took 30000 to restore the database. Netizen: This is really a revenge
@TableId can‘t more than one in Class: “com.example.CloseContactSearcher.entity.Activity“.
Business process testing based on functional testing
Interface master v3.9, API low code development tool, build your interface service platform immediately