当前位置:网站首页>集合(泛型 & List & Set & 自定义排序)
集合(泛型 & List & Set & 自定义排序)
2022-07-06 16:53:00 【一个很懒的人】
本文主要介绍了集合的指示,包括但不限于以下知识:
- 泛型
- 集合体系层级
- 集合体系中的接口及其实现类
- 集合自定义排序
集合
1.泛型
(1)概念
将 数据类型 作为 参数 进行传递
(泛型在使用时,接收到的是什么数据类型,此泛型就是什么数据类型)
(2)定义
1,<T>:T 声明一个泛型,可以使用任何字母,代指泛型,eg:<T>、<X>
2,<T,X,...>:声明多个泛型,T、X.....
(3)使用
注意:
- 泛型必须:先定义,再使用
- 泛型在使用时,接收到的是什么数据类型,此泛型就是什么数据类型
- 泛型可以在数据类型处定义
- 泛型在类中定义的只能在类中使用,在方法中定义的只能在方法中使用(泛型作用域范围)
- 使用泛型的类,在 创建对象 时要指明 实际 的数据类型(只能用引用数据类型)
- 使用泛型的接口,公共抽象方法可以用泛型(静态修饰的成员不能使用泛型)
- 实现 使用泛型的接口的类,在类和接口后都需要加泛型,但是一般使用匿名内部类创建接口实例
eg01:在方法中使用
public class Test {
public static void main(String[] args) {
Integer i = test(1);
String str = test("123");
Test t = new Test();
Test test = test(t);
}
/** * 要求,传入的参数类型就是返回值类型 * 泛型在使用时,接收到的是什么数据类型,此泛型就是什么数据类型 */
public static <X> X test(X str) {
return str;
}
/** * 可以传入任何一种类型 */
public static <X,Y> void test01(X str,Y y,Y y2) {
}
}
eg02:在类中使用
- 类上定义泛型,必须在类名之后继承与实现之前,紧随类名
- 泛型在使用时,接收到的是什么数据类型,此泛型就是什么数据类型
/** * 类上定义泛型,必须在类名之后继承与实现之前,紧随类名 */
class Person<K,Y,Z> extends Object {
private K k;
private Y y;
private Z z;
private String str;
public Person() {
super();
}
public Person(K k, Y y, Z z, String str) {
super();
this.k = k;
this.y = y;
this.z = z;
this.str = str;
}
public class Test02 {
public static void main(String[] args) {
//泛型在使用时,接收到的是什么数据类型,此泛型就是什么数据类型
Person<Integer, String, Boolean> person = new Person<Integer, String, Boolean>();
Person<String, Integer, Integer> person2 = new Person<String, Integer, Integer>();
}
}
eg03:在接口中使用
public class Test03 {
public static void main(String[] args) {
//1.匿名内部类使用泛型
MyInterfaceTest<String> test = new MyInterfaceTest<String>();
new MyInterface<Integer>() {
@Override
public void test01(Integer k) {
// TODO Auto-generated method stub
}
@Override
public Integer test02(Integer k) {
// TODO Auto-generated method stub
return null;
}
};
}
}
interface MyInterface<K>{
void test01(K k);
K test02(K k);
}
//2.类实现泛型接口
/*接口和实现类后都需要增加泛型 */
class MyInterfaceTest<K> implements MyInterface<K>{
@Override
public void test01(K k) {
// TODO Auto-generated method stub
}
@Override
public K test02(K k) {
// TODO Auto-generated method stub
return null;
}
}
2.集合
(1)概念
存储一组数据类型相同的数据(引用数据类型),长度可变
(2)体系层级
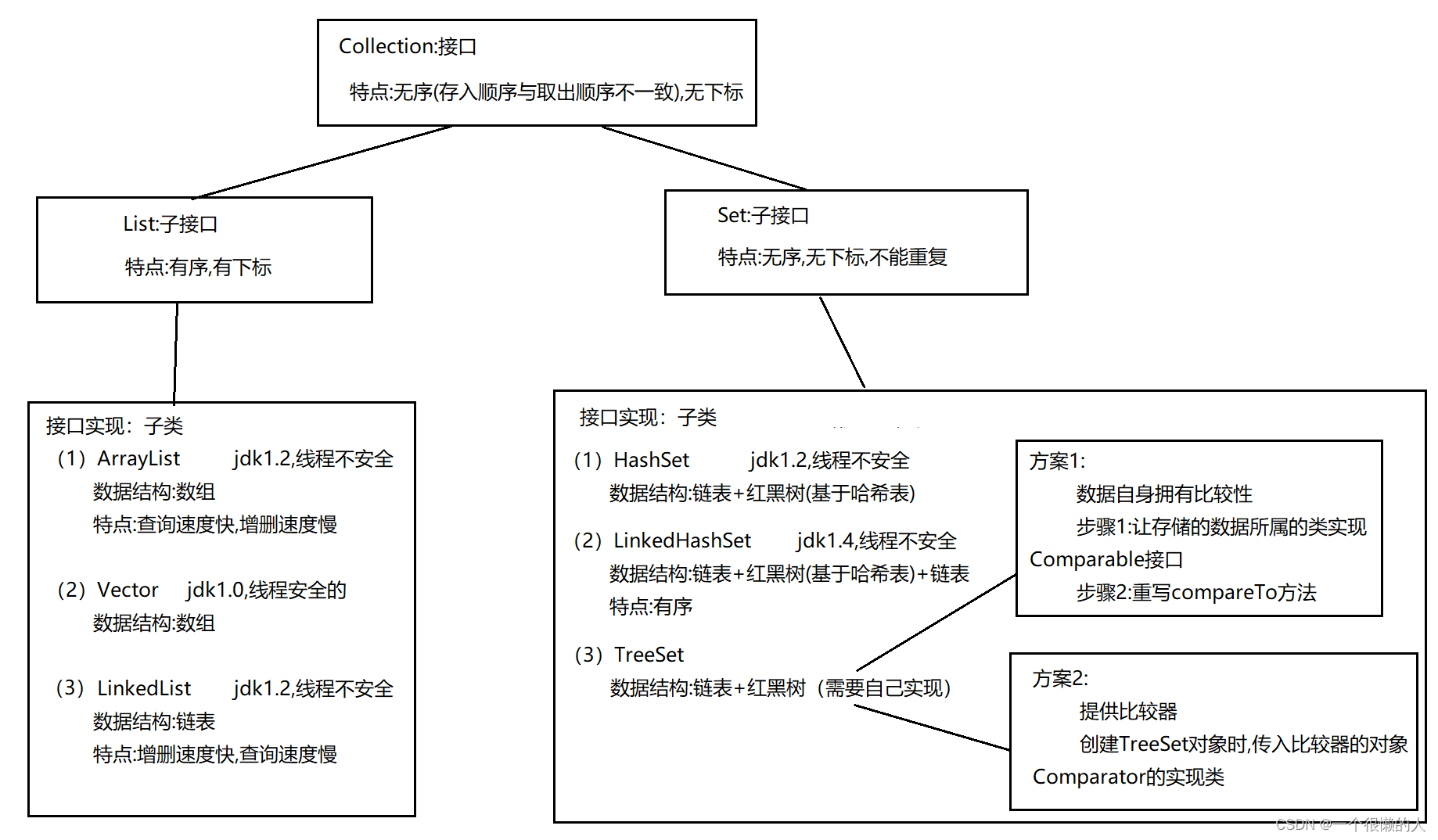
(3)Collection:接口(集合一级父类)
Collection:接口
特点:无序(存入顺序与取出顺序不一致),无下标
方法:
增
boolean add(E e):添加一个数据
boolean addAll(Collection<? extends E> c):将子集合中数据添加到集合中
删
boolean remove(Object o);:删除一个数据
boolean removeAll(Collection<?> c):将子集合中所有数据从集合中删除
void clear():清空
改
无
查
int size():获取集合中元素的个数
boolean contains(Object o):判断指定元素是否在集合中存在
boolean containsAll(Collection<?> c):判断子集合中所有数据是否在集合中存在
Iterator<E> iterator():迭代器
其他
boolean isEmpty():判断集合中是否存在元素
Object[] toArray():将集合转换为数组
(4)List:子接口(集合二级父类)
List:子接口
特点:有序,有下标
子类特有方法(除去继承Collection的方法)
增
一次插入一个数据,1参:插入的位置,2参:插入的数据
void add(int index, E element);
一次插入一组数据,1参:插入的位置,2参:插入的数据
boolean addAll(int index, Collection<? extends E> c);
删
按照下标删除指定位置的数据
E remove(int index);
改
修改:1参:下标,2参:修改后的元素
E set(int index, E element);
查
获取指定位置的元素,参数:下标
E get(int index):
(5)Set:子接口(集合二级父类)
Set
特点:无序(存入顺序与取出顺序不一致,但存储到其内部输出是有序的(由大到小或由小到大)),无下标,不能重复
子类特有方法:无(除去继承Collection方法,没有其他自己的方法)
(6)子接口实现类(集合)
List子接口实现类
(1)ArrayList jdk1.2,线程不安全
数据结构:数组
特点:查询速度快,增删速度慢
(2)Vector jdk1.0,线程安全的
数据结构:数组
(3)LinkedList jdk1.2,线程不安全
数据结构:链表
特点:增删速度快,查询速度慢
Set子接口实现类
(1)HashSet jdk1.2,线程不安全
数据结构:链表+红黑树(基于哈希表)
(2)LinkedHashSet jdk1.4,线程不安全
数据结构:链表+红黑树(基于哈希表,jdk源码封装实现)+链表
特点:有序
(3)TreeSet
数据结构:链表+红黑树(需要自己实现)
方案1:
数据自身拥有比较性
步骤1:让存储的数据所属的类实现Comparable接口
步骤2:重写compareTo方法
方案2:
提供比较器
创建TreeSet对象时,传入比较器的对象Comparator接口实现类
(7)迭代遍历
- 获取到集合的迭代器
- hasNext() 方法判断其要迭代的位置是否含有元素
- iterator.next()获取到迭代器指示位置的元素,并将迭代器指示位置向下移一个位置
- 如此循环,直到迭代器中元素遍历完毕
//迭代遍历
Iterator<Person> iterator=treeSet.iterator();
while(iterator.hasNext()) {
Person person=iterator.next();
System.out.println(person);
}
3.集合实现自定义排序
(1)Comparable接口
- 在java的jdk中提供了Comparable接口,其提供了一个抽象方法compareTo(T o),其中T代表泛型,将其与集合使用可以实现自定义排序
- java的8中基本数据类型均实现类Comparable接口,实现类其中的方法
1.以TreeSet为例,分析Comparable接口,进而实现自定义排序
- Person实现Comparable接口
- 重写compareTo(Person o)方法
其中方法中 this 代之集合中add(e)的值,将其依次与集合中原有的元素比较,确定其位置在存储数据的 数据结构 中的位置,进而插入数据结构中(使用某种数据结构实现数据值的按序存储)- TreeSet其存储是红黑树,jdk中没有实现其排序方法,需要自己实现,使其存储的类实现Comparable接口是实现其排序的方法之一
public class Person implements Comparable<Person> {
private String name;
private String sex;
private int age;
private int height;
public Person() {
super();
}
public Person(String name, String sex, int age, int height) {
super();
this.name = name;
this.sex = sex;
this.age = age;
this.height = height;
}
/* ............省略了标准类的其他方法 */
//自定义比较
@Override
public int compareTo(Person o) {
// TODO Auto-generated method stub
if (this.height!=o.height) {
return this.height-o.height;
}else if (this.age!=o.age) {
return this.age-o.age;
}
else {
return this.name.compareTo(o.name)+this.sex.compareTo(o.sex);
}
}
}
(2)Comparator接口
- Comparator接口中提供了compare(T o1, T o2)抽象方法,其中T代表泛型,其可以配合集合使用,实现集合的自定义排序
2.以TreeSet为例,分析Comparator接口,进而实现自定义排序
- 其可以看作是自定义比较器,在操作中使用,不需要对其操作对象的类进行实现接口
- 在创建TreeSet集合时,传入比较器(Comparator接口的实现类),下面使用匿名内部类的方式创建传入
compare(T o1, T o2)方法在使用时,其o1参数代表集合正在add(e)的对象,o2代表集合中原有的对象元素,将o1其依次与集合中原有的元素(o2)比较,确定其位置在存储数据的 数据结构 中的位置,进而插入数据结构中(使用某种数据结构实现数据值的按序存储)- TreeSet其存储是红黑树,jdk中没有实现其排序方法,需要自己实现,在创建TreeSet对象时,传入自定义比较器(Comparator接口实现类)是实现其集合有序排序的方法之一
TreeSet<Person01> treeSet=new TreeSet<Person01>(new Comparator<Person01>() {
//实现比较器
@Override
public int compare(Person01 o1, Person01 o2) {
// TODO Auto-generated method stub
if (o1.getHeight()!=o2.getHeight()) {
return o1.getHeight()-o2.getHeight();
}
else if (o1.getAge()!=o2.getAge()) {
return o1.getAge()-o2.getAge();
}
else {
return o1.getName().compareTo(o2.getName())+o1.getSex().compareTo(o2.getSex());
}
}
});
(3)Comparable接口与Comparator接口的区别
Comparable接口
- 可以将其看作是小学时由高到低排座位,其排序方式是自己与别人去比较,确定你的位置
- 抽象为代码中就是,add(e)的对象与集合中已经存在的对象进行比较,确定add(e)的对象在底层数据结构中存储的位置
Comparator接口
- 可以将其看作是小学时由高到低排座位,其排序方式是老师给你们两两比较,然后再确定你的位置
- 抽象为代码中就是,add(e)的对象与集合中已经存在的对象进行比较,其内部的compare(T o1, T o2)方法中,o1代表add(e)的对象,o2代表合中已经存在的对象,将其两两比较确定add(e)的对象在底层数据结构中存储的位置
(4)操作集合的工具类:Collections(实现自定义排序)
- 常用方法
Collections.sort(list);//排序
Collections.reverse(list);//翻转
Integer max = Collections.max(list);//寻找最大值
Integer min = Collections.min(list);//寻找最小值
- Collections中sort方法
public static <T extends Comparable<? super T>> void sort(List<T> list)
public static <T> void sort(List<T> list, Comparator<? super T> c)
以上两个方法是Collections提供的两个重载的sort方法,从其参数可以看出其实现集合排序的两种方式也是和Comparable和Comparator有关,即若想使用此工具类实现对集合的排序有两种方式:
方案一:集合中存储的数据类型自身拥有比较性
调用Collections.sort(list)对list集合进行排序时,要求list集合中村存储的数据类型的类实现了Comparable接口,并重写了其中的comparaTo方法方案二:提供自定义比较器
调用Collections.sort(list,new Comparator(compara的实现方法))对list集合进行排序时,1参代表要排序的集合,2参代表自己创建的比较器(提供实现了Comparator接口的实现类,要求其重写了compara接口)
使用工具类Collections实现对集合排序的代码,可以参考我的另一篇博客:
JAVA_自定义排序(Comparable、Comparator)详解
4.双列集合(Map)
(1)概念
概念: 存储一组数据类型相同的数据,长度可变
存储数据的要求: 键值对应
(2)体系层级
Map(接口)
- HashMap(类)
特点: 链表+红黑树(哈希表),线程不安全,1.2
-------在其内部是以键值Key 由小到大排序的- HashTable(类)
特点: 链表+红黑树(哈希表),线程安全,1.0
-------在其内部是以键值Key 由小到大排序的
Properties(类)- TreeMap(类)
特点: 链表+红黑树(需要自己提供)
-------在其内部没有进行默认的排序,需要存储数据自身具有比较性或提供比较器
注意: TreeMap存储数据, 键(key) 要么拥有比较性,要么在创建TreeMap时传入比较器(类似TreeSet集合)
(3)Map的方法
增
V put(K key, V value);
注意:如果字典中key不存在,则是添加,如果key存在,那么将修改key对应的value
void putAll(Map<? extends K, ? extends V> m);
删
V remove(Object key);
void clear();
改
V put(K key, V value);
查
int size();
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
Set<K> keySet();
Collection<V> values();
Set<Map.Entry<K, V>> entrySet();
其他:
Entry
getKey();
getValue();
(4)Map的遍历
Set<Integer> keySet = hashMap.keySet();
//遍历方式1
for (Integer key : keySet) {
String value=hashMap.get(key);
System.out.println(key+","+value);
}
//遍历方式2
Set<Entry<Integer,String>> entrySet = hashMap.entrySet();
for (Entry<Integer, String> entry : entrySet) {
int key=entry.getKey();
String value=entry.getValue();
System.out.println(key+","+value);
}
边栏推荐
- Huawei mate8 battery price_ Huawei mate8 charges very slowly after replacing the battery
- Interesting wine culture
- 【vulnhub】presidential1
- 英雄联盟|王者|穿越火线 bgm AI配乐大赛分享
- After leaving a foreign company, I know what respect and compliance are
- Things like random
- Mujoco finite state machine and trajectory tracking
- DAY ONE
- 什么是响应式对象?响应式对象的创建过程?
- DAY SIX
猜你喜欢
Introduction au GPIO
GPIO簡介

Understand the misunderstanding of programmers: Chinese programmers in the eyes of Western programmers
What is AVL tree?
2022/2/11 summary

alexnet实验偶遇:loss nan, train acc 0.100, test acc 0.100情况
智能运维应用之道,告别企业数字化转型危机

Core knowledge of distributed cache
工程师如何对待开源 --- 一个老工程师的肺腑之言
Data analysis course notes (V) common statistical methods, data and spelling, index and composite index
随机推荐
37 pages Digital Village revitalization intelligent agriculture Comprehensive Planning and Construction Scheme
What can the interactive slide screen demonstration bring to the enterprise exhibition hall
Win10 startup error, press F9 to enter how to repair?
刘永鑫报告|微生物组数据分析与科学传播(晚7点半)
Amazon MemoryDB for Redis 和 Amazon ElastiCache for Redis 的内存优化
Introduction to GPIO
Testers, how to prepare test data
The way of intelligent operation and maintenance application, bid farewell to the crisis of enterprise digital transformation
Common shortcuts to idea
Devops can help reduce technology debt in ten ways
The programmer resigned and was sentenced to 10 months for deleting the code. Jingdong came home and said that it took 30000 to restore the database. Netizen: This is really a revenge
如何判断一个数组中的元素包含一个对象的所有属性值
Huawei mate8 battery price_ Huawei mate8 charges very slowly after replacing the battery
How engineers treat open source -- the heartfelt words of an old engineer
MySQL master-slave multi-source replication (3 master and 1 slave) setup and synchronization test
什么是响应式对象?响应式对象的创建过程?
Interesting wine culture
Jenkins' user credentials plug-in installation
File and image comparison tool kaleidoscope latest download
Leecode brush questions record sword finger offer 44 A digit in a sequence of numbers