当前位置:网站首页>alexnet实验偶遇:loss nan, train acc 0.100, test acc 0.100情况
alexnet实验偶遇:loss nan, train acc 0.100, test acc 0.100情况
2022-07-06 16:50:00 【ddrrnnpp】
场景:数据集:官方的fashionminst + 网络:alexnet+pytroch+relu激活函数
源代码:https://zh-v2.d2l.ai/chapter_convolutional-modern/alexnet.html
知识点:梯度爆炸,梯度弥散
学习文献(向大佬看齐)有:
https://zh-v2.d2l.ai/chapter_multilayer-perceptrons/numerical-stability-and-init.html
https://www.bilibili.com/video/BV1X44y1r77r?spm_id_from=333.999.0.0&vd_source=d49d528422c02c473340ce042b8c8237
https://zh-v2.d2l.ai/chapter_convolutional-modern/alexnet.html
https://www.bilibili.com/video/BV1u64y1i75a?p=2&vd_source=d49d528422c02c473340ce042b8c8237
实验现象:
现象一:
1、代码一开始运行就出现以下情况
现象二:
2、我尝试把学习率调小之后,中途出现loss nan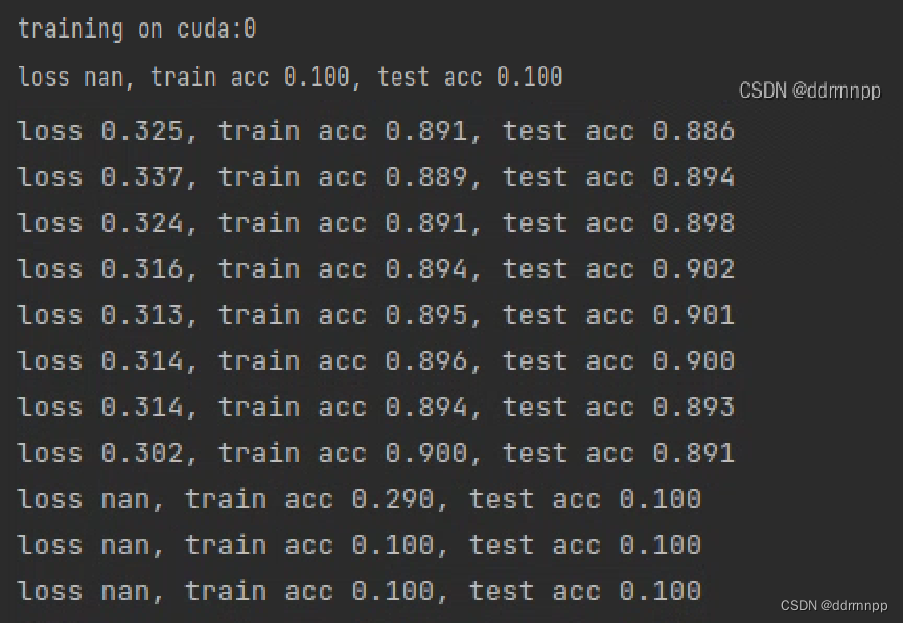
现象三:
群友a:有时候跑没什么问题,网络也没改什么,有时候出现loss nan,有时候不出现
群友b:可能原因:随机初始化变量值的影响
群友a:尝试解决办法:换了随机种子,出现的轮次只是变后了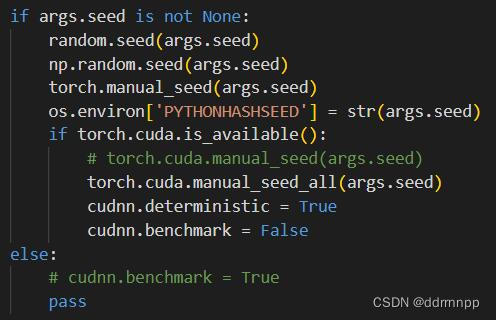
我的最短路径解决办法:加入BN层(吃的到老鼠的就是好猫,hhh)
https://zh-v2.d2l.ai/chapter_convolutional-modern/batch-norm.html
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0)
var = ((X - mean) ** 2).mean(dim=0)
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。
# 这里我们需要保持X的形状以便后面可以做广播运算
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)
# 训练模式下,用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y, moving_mean.data, moving_var.data
class BatchNorm(nn.Module):
# num_features:完全连接层的输出数量或卷积层的输出通道数。
# num_dims:2表示完全连接层,4表示卷积层
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 非模型参数的变量初始化为0和1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var
# 复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y
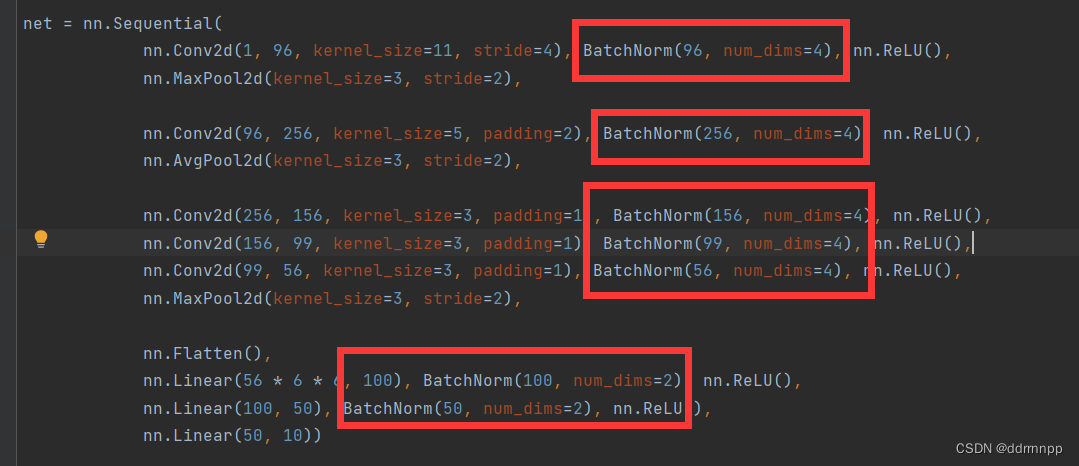
csdn的其他解决办法:

原理一:
https://www.bilibili.com/video/BV1u64y1i75a?p=2&vd_source=d49d528422c02c473340ce042b8c8237
1、梯度求导+链式法则


1.1、relu激活函数求导性质+梯度爆炸
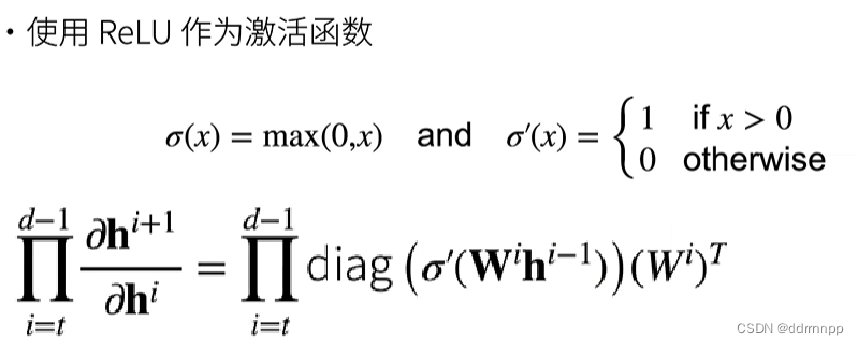
1、relu的激活函数的导数1或0
2、梯度爆炸:由于导数的链式法则,连续多层大于1的梯度相乘会使梯度越来越大,最终导致梯度太大的问题。
3、梯度爆炸 会使得某层的参数w过大,造成网络不稳定,极端情况下,数据乘以一个大w发生溢出,得到NAN值。
1.2、梯度爆炸的问题:

2.1、sigmoid 激活函数求导性质+梯度消失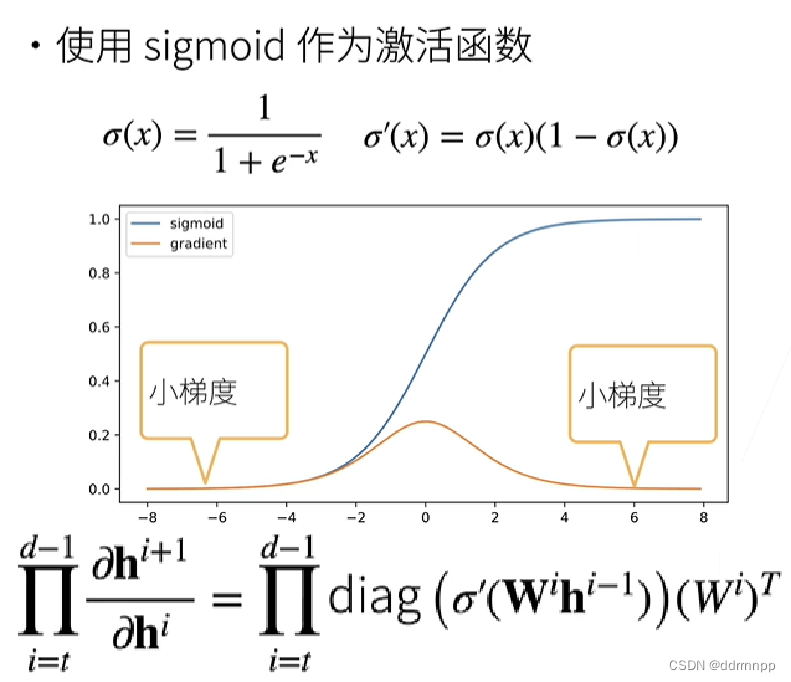
1、由于导数的链式法则,在连续的层中,将小于1的梯度相乘会使梯度越来越小,最终在一层中梯度为0。
2.2、梯度消失的问题:

实验现象分析:
1、relu激活函数
2、调整学习率可以使得网络中途输出nan
------》结论:梯度爆炸
原理二:
https://www.bilibili.com/video/BV1X44y1r77r?spm_id_from=333.999.0.0&vd_source=d49d528422c02c473340ce042b8c8237
1、alexnet相对是比较深的网络:

2、批量归一化中抽取的是“小批量”,带有一定的随机性。一定程度上,这里的小批量会 给网络 带来一定的噪音来控制模型复杂度。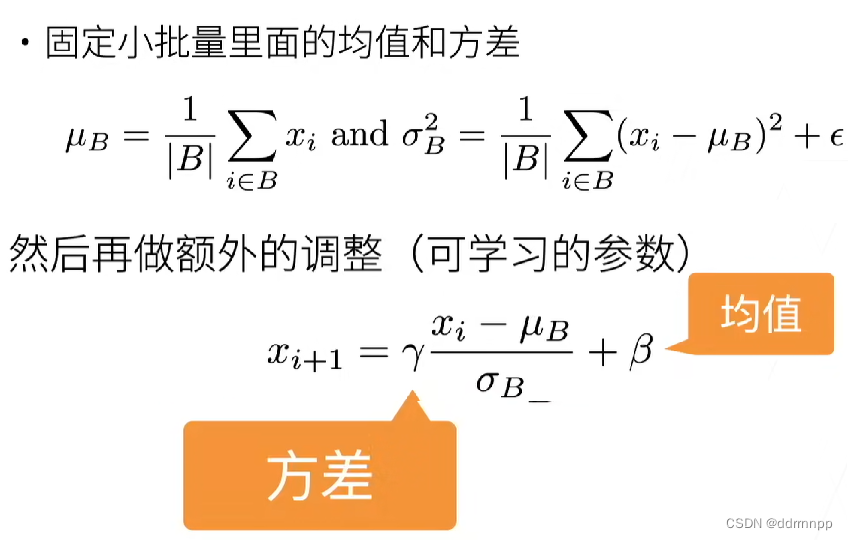
3、批量归一化后,lr学习率可以设置大的数,具有加速收敛的作用
非常感谢李沐大佬的讲解视频!!!!,本文以一个实际的问题出发,了解大佬讲解的知识点。有自己的独特之处
,如有侵权、雷同、错误之处!!,请君指点!!!!!

边栏推荐
- 基於GO語言實現的X.509證書
- What is web penetration testing_ Infiltration practice
- Win10 startup error, press F9 to enter how to repair?
- vector的使用方法_vector指针如何使用
- Three sentences to briefly introduce subnet mask
- Value Function Approximation
- Everyone is always talking about EQ, so what is EQ?
- 509 certificat basé sur Go
- Cross-entrpy Method
- [2022 the finest in the whole network] how to test the interface test generally? Process and steps of interface test
猜你喜欢

Designed for decision tree, the National University of Singapore and Tsinghua University jointly proposed a fast and safe federal learning system
Basic information of mujoco
DAY ONE

The difference between redirectto and navigateto in uniapp
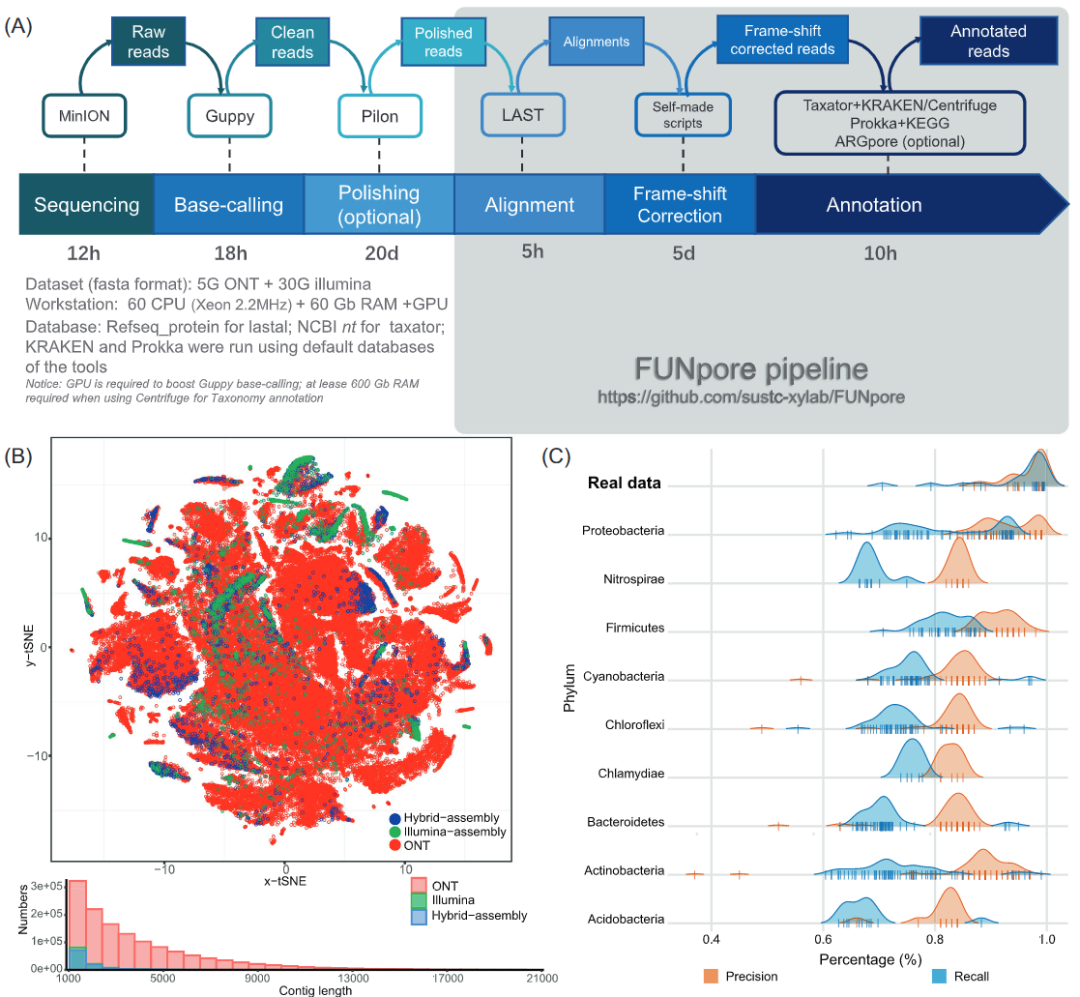
Imeta | Chen Chengjie / Xia Rui of South China Agricultural University released a simple method of constructing Circos map by tbtools
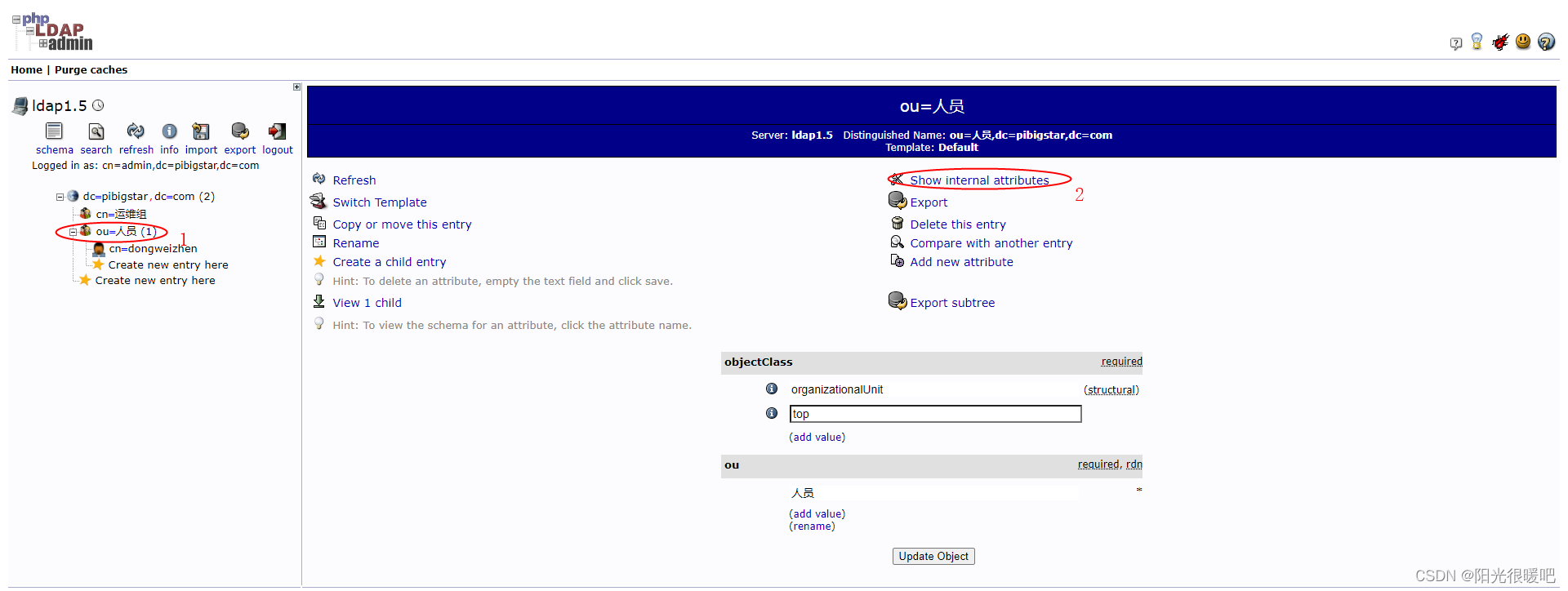
rancher集成ldap,实现统一账号登录
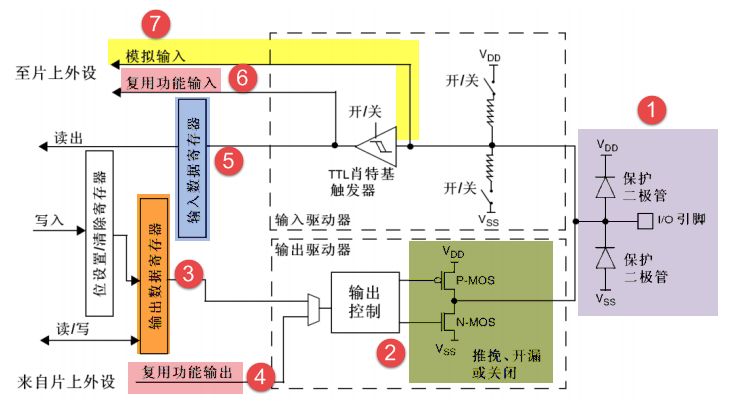
GPIO簡介

2022 PMP project management examination agile knowledge points (9)
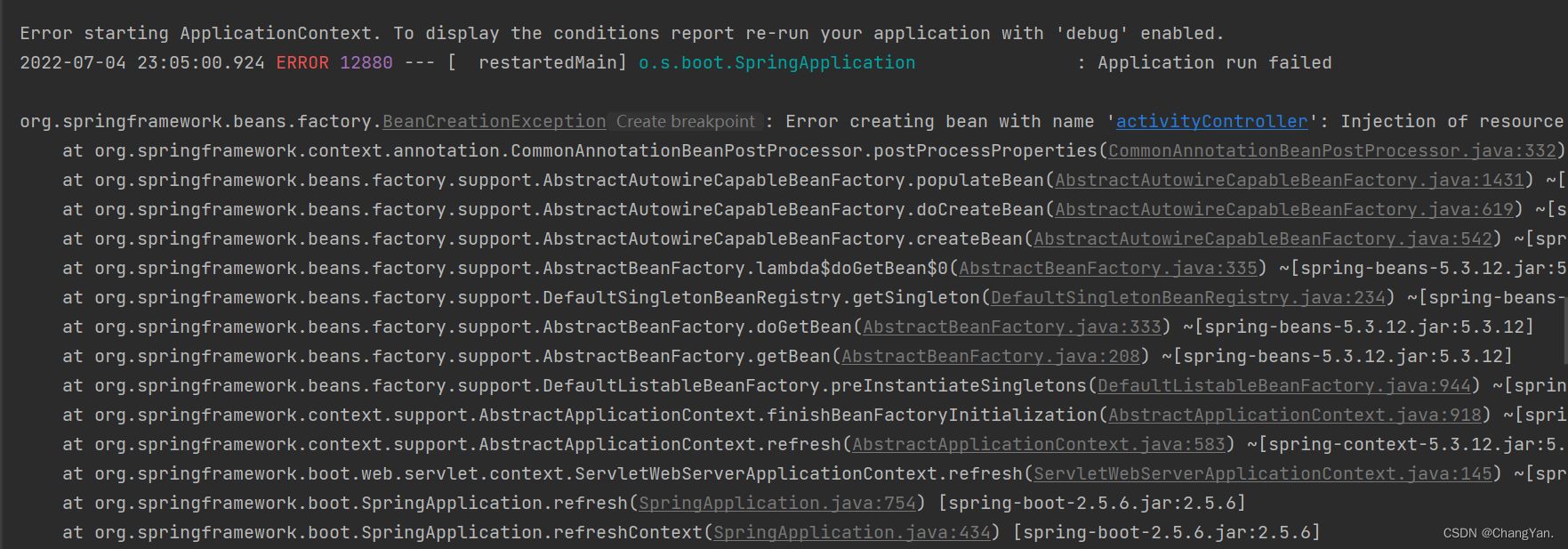
@TableId can‘t more than one in Class: “com.example.CloseContactSearcher.entity.Activity“.
2022/2/11 summary
随机推荐
沉浸式投影在线下展示中的三大应用特点
What can the interactive slide screen demonstration bring to the enterprise exhibition hall
Cross-entrpy Method
Rails 4 asset pipeline vendor asset images are not precompiled
量子时代计算机怎么保证数据安全?美国公布四项备选加密算法
Why should a complete knapsack be traversed in sequence? Briefly explain
openresty ngx_ Lua subrequest
509 certificat basé sur Go
Devops can help reduce technology debt in ten ways
Use Yum or up2date to install the postgresql13.3 database
Geo data mining (III) enrichment analysis of go and KEGG using David database
Leecode brush questions record sword finger offer 11 Rotate the minimum number of the array
【向量检索研究系列】产品介绍
DAY ONE
Interface master v3.9, API low code development tool, build your interface service platform immediately
【2022全网最细】接口测试一般怎么测?接口测试的流程和步骤
rancher集成ldap,实现统一账号登录
Clipboard management tool paste Chinese version
Pytest multi process / multi thread execution test case
智能运维应用之道,告别企业数字化转型危机