当前位置:网站首页>Learn self 3D representation like ray tracing ego3rt
Learn self 3D representation like ray tracing ego3rt
2022-07-07 00:46:00 【3D vision workshop】
Click on the above “3D Visual workshop ”, choice “ Star standard ”
The dry goods arrive at the first time

Author Huang Yu
Source Computer vision, deep learning and automatic driving
arXiv Upload on 2022 year 6 month 8 Day's paper “Learning Ego 3D Representation as Ray Tracing“, It's the work of Professor Zhang's team in Fudan University .

The autopilot perception model aims to integrate multiple cameras 3D Semantic representation is extracted from the self vehicle BEV In coordinate system , Lay the foundation for downstream planners . Existing perception methods usually rely on error prone depth estimation of the whole scene , Or learning sparse virtual without target geometry 3D characterization , These two methods are in performance and / Or the ability is still limited .
This paper proposes an end-to-end architecture ,Ego3RT, Used to learn from any number of unconstrained camera views 3D characterization . Raytraced (ray-tracing) Inspired by the principle , To design a “ Imagine eyes (imaginary eye)” As a learnable self 3D characterization , And combine “3D To 2D Projection ”, This learning process is formulated by using the adaptive attention mechanism .
The key is , This formula allows from 2D Image extraction is rich 3D characterization , No in-depth supervision signal is required , And has a relationship with BEV Consistent embedded geometry . Despite its simplicity and versatility , But the standard BEV Visual task ( for example , Camera based 3D Target detection and BEV Division ) A lot of experiments show that , This model has additional advantages in the computational efficiency of multi task learning .
As shown in the figure, it is from 3D Representational learning (Ego3RT) Schematic diagram :BEV、 Multi camera input and 3D object detection

Code link :https://fudan-zvg.github.io/Ego3RT
Take the image as the input , Existing visual models are usually either ignored ( for example , Image classification )、 Or direct consumption ( for example , object detection , Image segmentation ) Coordinate frame entered during result prediction .
For all that , This paradigm is not consistent with autonomous driving “ Open the box (out-of-the-box)” The perceived environment , The input source is multiple cameras , Each camera has a specific coordinate system , It is completely different from all input frames , Perception model of downstream tasks ( for example ,3D object detection 、 Lane segmentation ) It is necessary to predict in the self driving coordinate system .
in other words , The perception model of automatic driving needs to be from the multi view image 2D Reasoning in visual representation 3 D semantics , This is a very complex and challenging problem .
As shown in the figure , Most methods adopt the following two strategies :
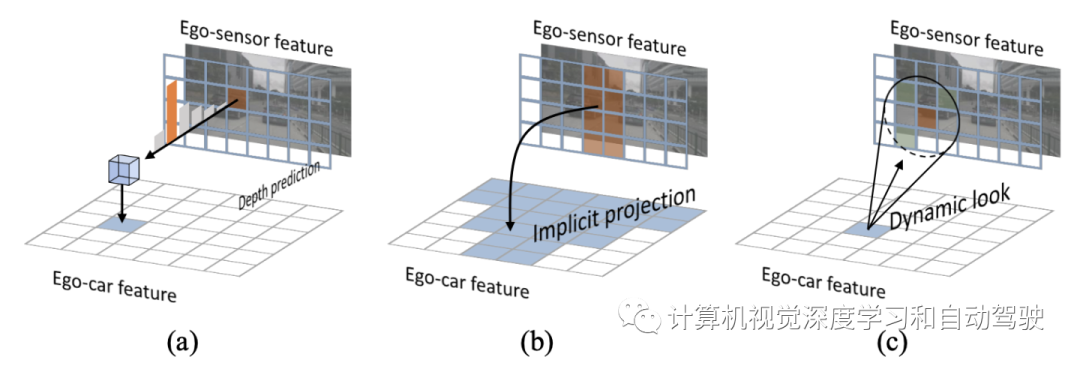
(a) Show the first strategy ( for example LSS and CaDDN) Depends on pixel level depth estimation , Is used to 2D The visual representation is projected into the self driving coordinate system , And the projection of internal and external parameters . Usually , Deep prediction performs end-to-end learning within the model , No supervision , There may be extra 3D supervise . One disadvantage of these methods is , Depth estimation in unconstrained scenes is usually error prone , This will be further propagated to subsequent components . This is also known as the error propagation problem , To a large extent, this kind of assembly line is inevitable .
In order to solve the above problems , The second strategy ( for example Image2Map、OFT、DETR3D) Through structural innovation from 2D Image direct learning 3D Express to eliminate the depth dimension . This method has been proved to be superior to the corresponding method based on depth estimation , It means learning 3D Expression is a superior general strategy . especially ,Image2Map and PON utilize Transformer or FC Layer forward learning from 2D Image frame to BEV Projection of coordinate frame . However , Such as (b) Shown ,3D It is structurally related to 2D The correspondence of is inconsistent , Because we can't use strict internal and external parameter projection , That is, there is no clear one-to-one correspondence between coordinate systems , Therefore, a suboptimal solution is generated . Inspired by the image-based target detection model , The most advanced recently DETR3D A plan with Transformer Model 3D Representational learning model . However , Its 3D Representation is not only sparse , And virtual , In the sense that the geometric structure of the self driving coordinate system is not explicitly involved . Therefore, intensive prediction tasks cannot be performed , For example, segmentation .
This method belongs to the third strategy (c) from BEV Specially designed in geometry “ Imaginary eye ” Middle backtracking 2D Information . The whole method architecture can be divided into two parts (1) Self car 3D It means learning (Ego3RT) and (2) Downstream task header . As shown in the figure below :
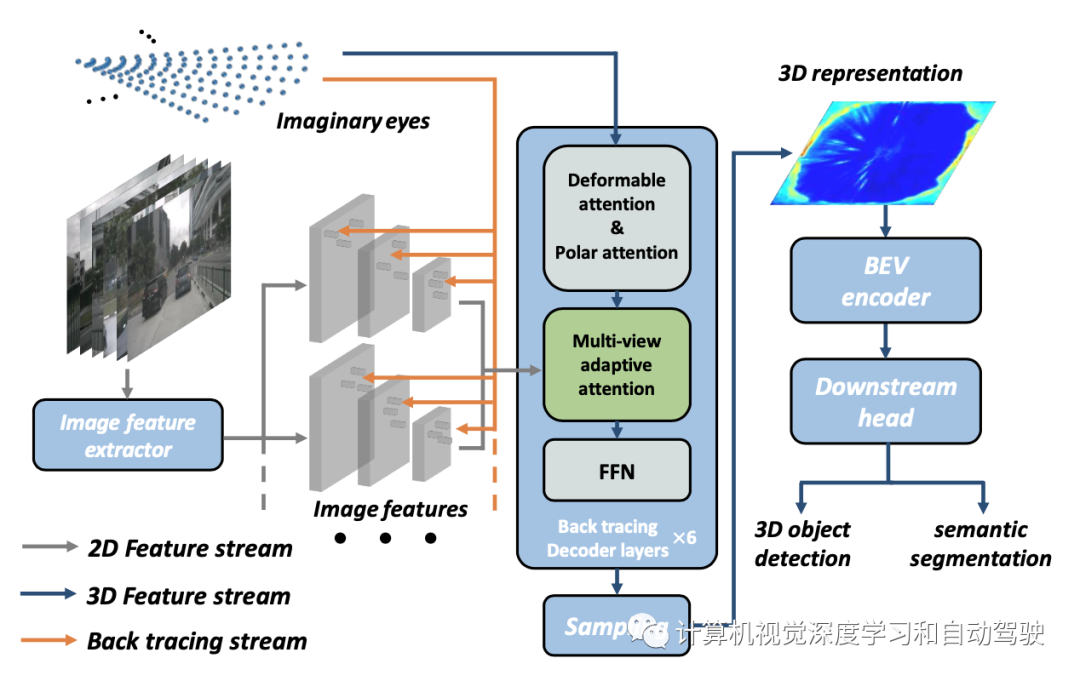
Ego3RT It's made up of two parts : Image feature extraction and backtracking (back tracing) decoder . In order to clearly illustrate the backtracking decoder , First introduced “ Imaginary eye “、3D Go back to 2D Mechanism and multi view and multi-scale adaptive attention mechanism .
Detailed below Ego3RT How to go from 2D Study 3D Express . In order to avoid exhaustive pixel level prediction and inconsistent coordinate projection , The idea of backtracking is simulated by ray tracing .
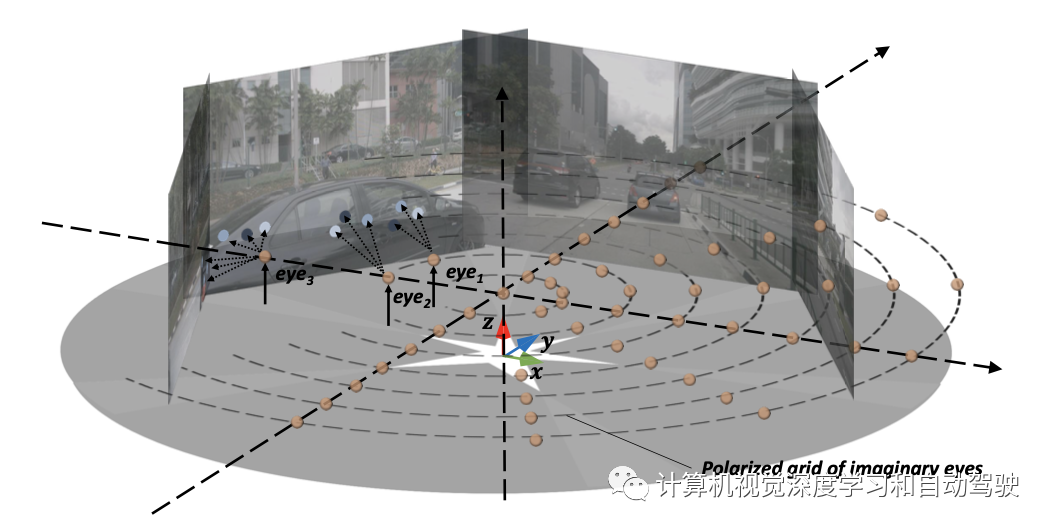
First, introduce dense “ Imaginary eye ” Polarization grid (polarized grid), be used for BEV Express , Each eye naturally occupies a specific geometric position with built-in depth information . The mesh size of the eyes is R×S, among R Is the number of eyes per polar ray ,S Is the number of polar rays . To construct or “ Rendering ”BEV Express , These imaginary eyes follow the above 3D-2D The projection program sends rays backward to 2D Visual representation . Because each eye only occupies a fixed geometric position , The limitation of local observation makes the corresponding 2D There is less location backtracking information . To solve this problem , Encourage your eyes to look around , Multi scale and multi camera views across each image , Focus the key feature points adaptively . This leads to a multi view and multi-scale adaptive attention module (MVAA). Last , These imaginary eye features will be final 3D Express .
” Imaginary eye “ The schematic diagram is shown in the figure : Golden balls represent dense “ Imaginary eye ” Polarization grid ; especially , For having multiple visible images ( for example eye3) Eyes of , Multiple images will be traced , Only a single visible image ( for example eye1) Your eyes will go back to a single image ; The blue dots on the image from light blue to dark blue show the importance of the eyes , Thus promoting adaptive attention .
To illustrate the backtracking mechanism , First of all 3D and 2D Coordinate transformation between . In a typical case , There is usually a lidar coordinate (3D)、Nview Camera coordinates (3D) and Nview Image coordinates (2D). First , Lidar coordinates to be corrected 3D spot xlidar Convert to corrected camera coordinates xcam, And use the matrix given by external parameters Mex. Next , Through the following formula xcam Projection to image plane point ximg:
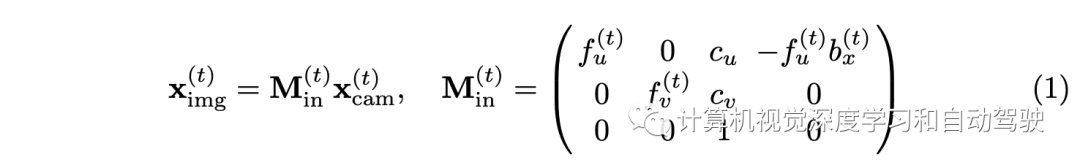
All in all , Through the projection matrix M=MinMex take 3D spot xlidar Project to image points ximg. If 0<u,v<1, Then this 3D The point will be projected into the image , Otherwise, it will be projected out of the image . If ximg In the image , Call the image to the corresponding point xlidar so . In this method , Encourage imaginary eyes in each image coordinate “ gaze ” Its 2D Around the projection point . Will be the first q The visible image set of eyes is represented by Iq.
MVAA Yes, it will 2D The representation is converted to 3D At the heart of . These imaginary eyes are learned in the framework of adaptive self attention detection . This is based on the idea of regarding the eyes as the target query , Write it down as y. Give Way r Record the position of the eyes in the self vehicle coordinates . Formally , Every eye ( I.e. inquiry ) Will be in 2D Dynamic selection on each scale of image representation Npoint Characteristic points . then ,MVAA Select the most important feature points , And integrate it into the desired... Across multiple scales and views 3D In the middle . The process can be expressed as

vector yq It's No q A query (eye),rq Is its location ,Nh It's the number of heads ,M(t) It's a projection matrix .A and ∆r By learnable parameters yq restriction :
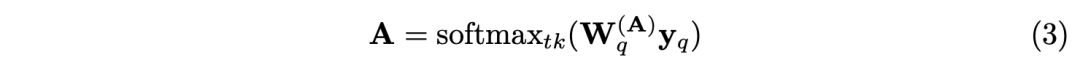
among
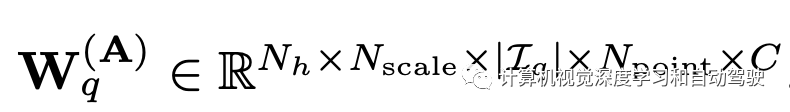
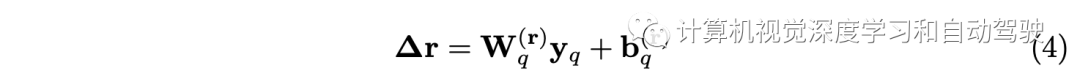
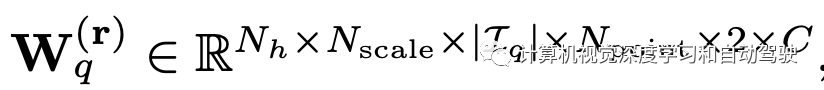
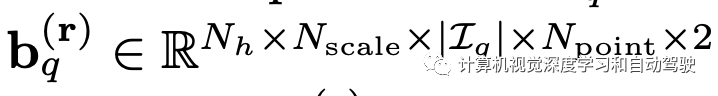
To avoid these Npoint Feature points collapse into one point , use | bq[·,·,·,k]|=k initialization bq, therefore Npoint The more , The larger the offset of these feature points . therefore , Parameters Npoint It can be used to control receptive fields .φ(x,r) Indicates that from x Access No. r Characteristic points . In order to adaptively assign importance to Nscale×| Iq |×Npoint spot , At all participating feature points 、 Scale and view application Softmax function :
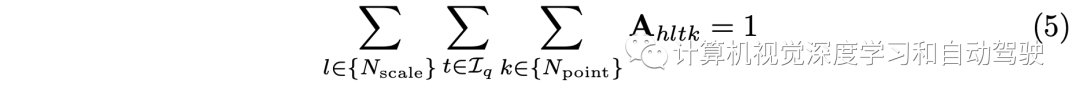
Technically speaking , The backtracking decoder randomly extracts the initialization features of the imaginary eye and the features of the image feature extractor 2D Feature scale as input , Finally, the fine-grained features of the imaginary eye are output as 3D characterization . The backtracking decoder consists of a stack of attention layers , These layers of attention are changed from transformer Decoder layer . Each layer is stacked with two self attention modules and one cross attention module in order : Deformable attention module 、 Pay great attention to modules and MVAA.
Compared with self attention , The memory efficiency of deformation attention is higher . stay 3D On Characterization , Apply standard self attention to a group of eyes with the same polar ray to do polar attention . Besides , Feedforward networks (FFN) The block is equipped with depth by depth (depth-wise) Convolution .MVAA Responsible for 2D The feature goes back to 3D In representation .
The following is the head design of the downstream task :
In the downstream task, before processing the characteristics of the imaginary eye , Firstly, the polarization features are gridded and sampled into the rectangular self propelled coordinate system , Match dataset annotations .
For multitasking 3D Representation is encoded , Use from OFT In the same BEV Encoder module . This sub network is also widely used in lidar based 3D detector .
The detection head is designed to predict the target at 3D The location of space 、 Size and orientation , And target categories . Although dense BEV features , Popular CenterPoint Medium 3D Detection head , No changes needed .
about BEV Split task , Select a set of semantic segmentation decoder headers based on progressive up sampling convolution , To deal with different elements in the map . Technically speaking ,1×1 Conv layer 、 have ReLU Of BN Layer and bilinear upsampling convolution layer together constitute an upsampling module . The decoder header used to predict different map elements is BEV Use accurate after encoder BEV features .
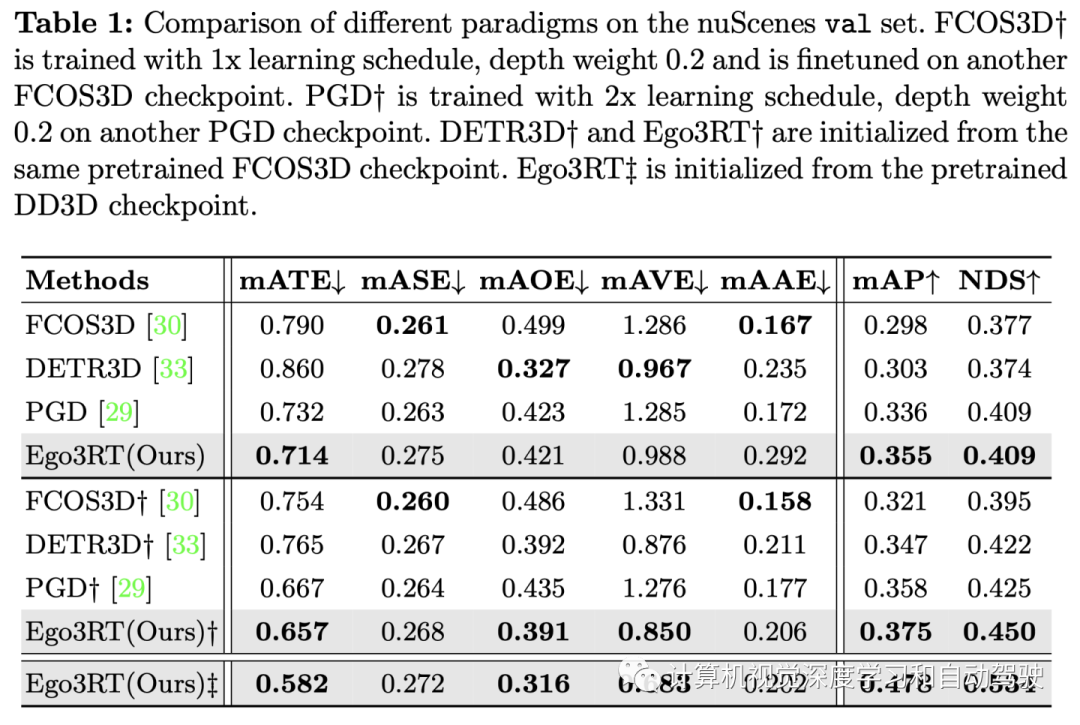
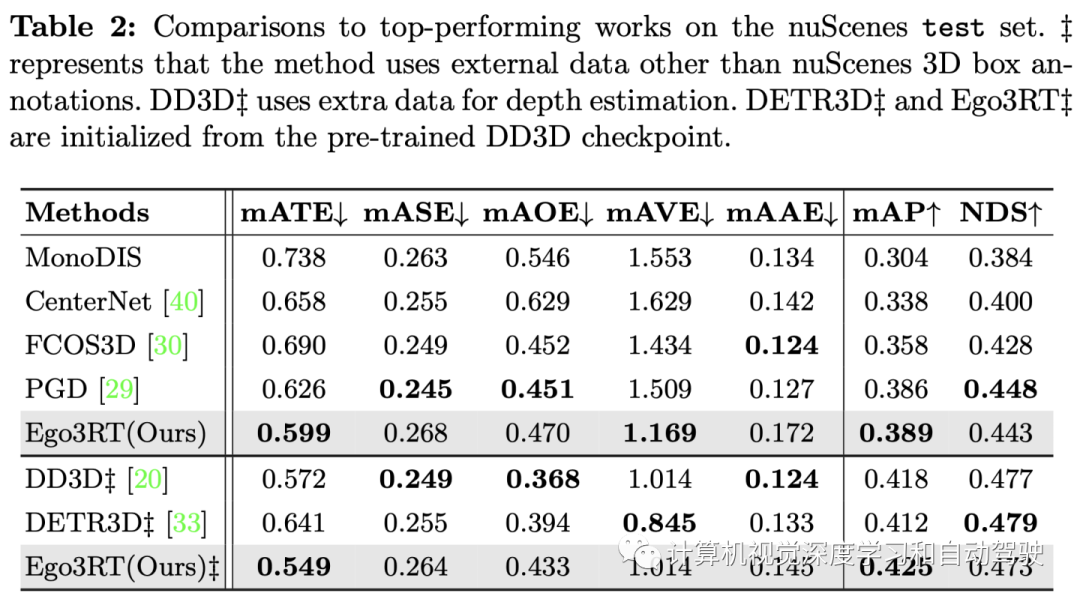
The experimental results are as follows :
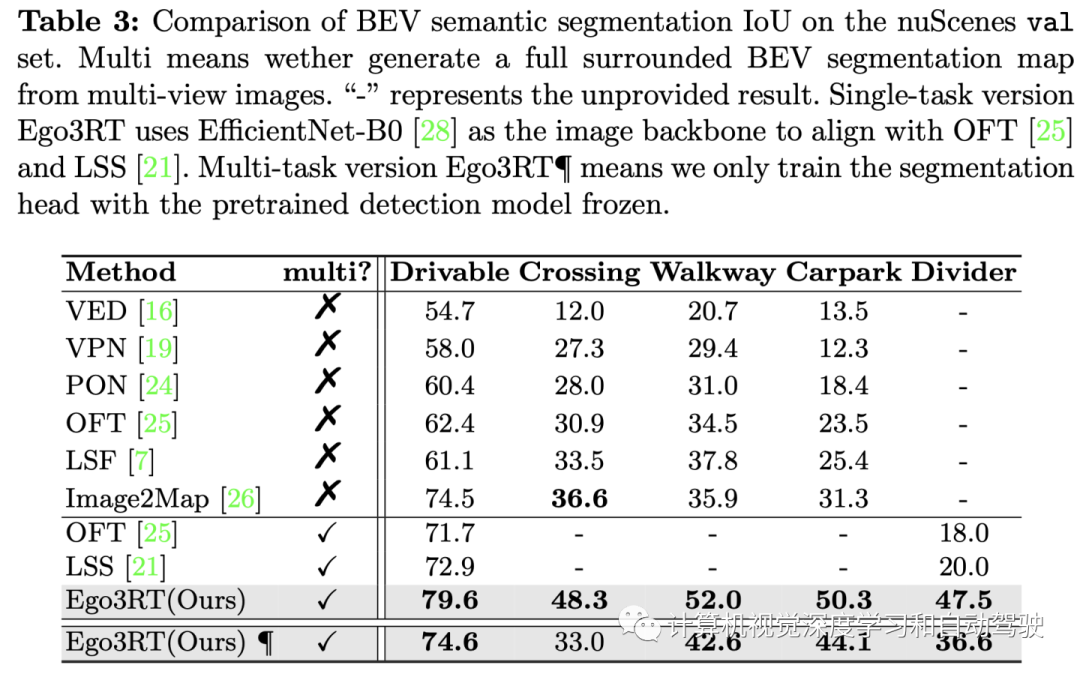
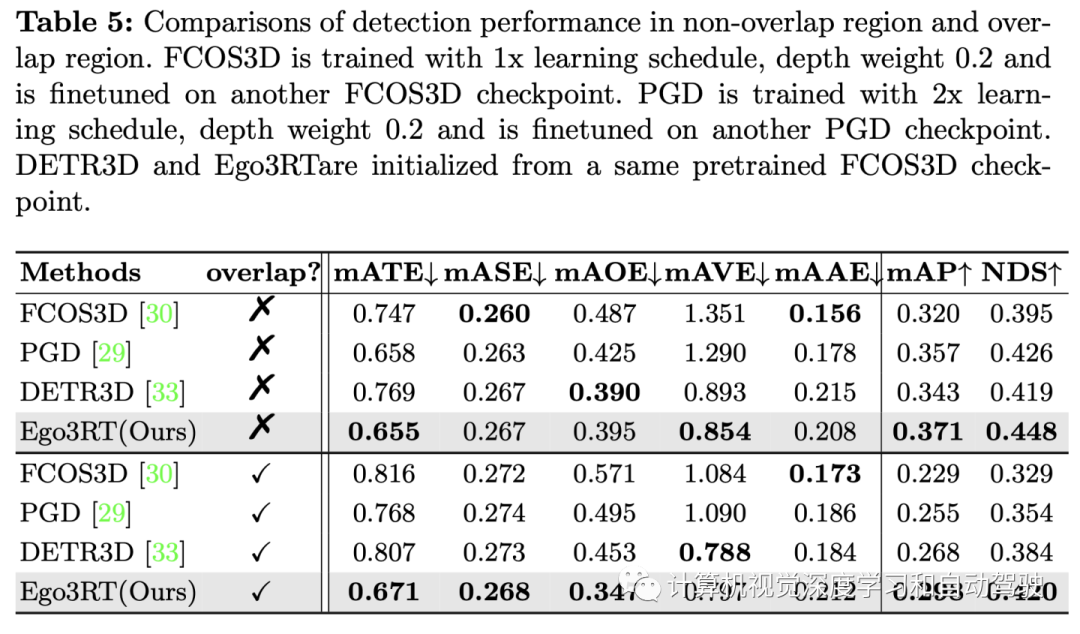
This article is only for academic sharing , If there is any infringement , Please contact to delete .
3D Visual workshop boutique course official website :3dcver.com
1. Multi sensor data fusion technology for automatic driving field
2. For the field of automatic driving 3D Whole stack learning route of point cloud target detection !( Single mode + Multimodal / data + Code )
3. Thoroughly understand the visual three-dimensional reconstruction : Principle analysis 、 Code explanation 、 Optimization and improvement
4. China's first point cloud processing course for industrial practice
5. laser - Vision -IMU-GPS The fusion SLAM Algorithm sorting and code explanation
6. Thoroughly understand the vision - inertia SLAM: be based on VINS-Fusion The class officially started
7. Thoroughly understand based on LOAM Framework of the 3D laser SLAM: Source code analysis to algorithm optimization
8. Thorough analysis of indoor 、 Outdoor laser SLAM Key algorithm principle 、 Code and actual combat (cartographer+LOAM +LIO-SAM)
10. Monocular depth estimation method : Algorithm sorting and code implementation
11. Deployment of deep learning model in autopilot
12. Camera model and calibration ( Monocular + Binocular + fisheye )
13. blockbuster ! Four rotor aircraft : Algorithm and practice
14.ROS2 From entry to mastery : Theory and practice
15. The first one in China 3D Defect detection tutorial : theory 、 Source code and actual combat
16. be based on Open3D Introduction and practical tutorial of point cloud processing
blockbuster !3DCVer- Academic paper writing contribution Communication group Established
Scan the code to add a little assistant wechat , can Apply to join 3D Visual workshop - Academic paper writing and contribution WeChat ac group , The purpose is to communicate with each other 、 Top issue 、SCI、EI And so on .
meanwhile You can also apply to join our subdivided direction communication group , At present, there are mainly 3D Vision 、CV& Deep learning 、SLAM、 Three dimensional reconstruction 、 Point cloud post processing 、 Autopilot 、 Multi-sensor fusion 、CV introduction 、 Three dimensional measurement 、VR/AR、3D Face recognition 、 Medical imaging 、 defect detection 、 Pedestrian recognition 、 Target tracking 、 Visual products landing 、 The visual contest 、 License plate recognition 、 Hardware selection 、 Academic exchange 、 Job exchange 、ORB-SLAM Series source code exchange 、 Depth estimation Wait for wechat group .
Be sure to note : Research direction + School / company + nickname , for example :”3D Vision + Shanghai Jiaotong University + quietly “. Please note... According to the format , Can be quickly passed and invited into the group . Original contribution Please also contact .

▲ Long press and add wechat group or contribute

▲ The official account of long click attention
3D Vision goes from entry to mastery of knowledge : in the light of 3D In the field of vision Video Course cheng ( 3D reconstruction series 、 3D point cloud series 、 Structured light series 、 Hand eye calibration 、 Camera calibration 、 laser / Vision SLAM、 Automatically Driving, etc )、 Summary of knowledge points 、 Introduction advanced learning route 、 newest paper Share 、 Question answer Carry out deep cultivation in five aspects , There are also algorithm engineers from various large factories to provide technical guidance . meanwhile , The planet will be jointly released by well-known enterprises 3D Vision related algorithm development positions and project docking information , Create a set of technology and employment as one of the iron fans gathering area , near 4000 Planet members create better AI The world is making progress together , Knowledge planet portal :
Study 3D Visual core technology , Scan to see the introduction ,3 Unconditional refund within days
There are high quality tutorial materials in the circle 、 Answer questions and solve doubts 、 Help you solve problems efficiently
Feel useful , Please give me a compliment ~
边栏推荐
- 【vulnhub】presidential1
- 三维扫描体数据的VTK体绘制程序设计
- MIT 6.824 - raft Student Guide
- Mujoco finite state machine and trajectory tracking
- Advanced learning of MySQL -- basics -- multi table query -- joint query
- Command line kills window process
- 【vulnhub】presidential1
- PXE server configuration
- Memory optimization of Amazon memorydb for redis and Amazon elasticache for redis
- 【软件逆向-自动化】逆向工具大全
猜你喜欢

Amazon MemoryDB for Redis 和 Amazon ElastiCache for Redis 的内存优化
【vulnhub】presidential1
Jenkins' user credentials plug-in installation
File and image comparison tool kaleidoscope latest download

37 pages Digital Village revitalization intelligent agriculture Comprehensive Planning and Construction Scheme

Testers, how to prepare test data
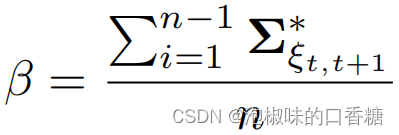
Slam d'attention: un slam visuel monoculaire appris de l'attention humaine
用tkinter做一个简单图形界面

On February 19, 2021ccf award ceremony will be held, "why in Hengdian?"
一图看懂对程序员的误解:西方程序员眼中的中国程序员
随机推荐
Sword finger offer 26 Substructure of tree
Slam d'attention: un slam visuel monoculaire appris de l'attention humaine
Three methods to realize JS asynchronous loading
Three sentences to briefly introduce subnet mask
The difference between redirectto and navigateto in uniapp
alexnet实验偶遇:loss nan, train acc 0.100, test acc 0.100情况
System activity monitor ISTAT menus 6.61 (1185) Chinese repair
Three application characteristics of immersive projection in offline display
Policy Gradient Methods
【软件逆向-自动化】逆向工具大全
Attention SLAM:一种从人类注意中学习的视觉单目SLAM
Leecode brush questions record sword finger offer 44 A digit in a sequence of numbers
PXE server configuration
Interface master v3.9, API low code development tool, build your interface service platform immediately
Data analysis course notes (III) array shape and calculation, numpy storage / reading data, indexing, slicing and splicing
Zynq transplant ucosiii
threejs图片变形放大全屏动画js特效
Geo data mining (III) enrichment analysis of go and KEGG using David database
【YoloV5 6.0|6.1 部署 TensorRT到torchserve】环境搭建|模型转换|engine模型部署(详细的packet文件编写方法)
Model-Free Prediction