当前位置:网站首页>Attention SLAM:一種從人類注意中學習的視覺單目SLAM
Attention SLAM:一種從人類注意中學習的視覺單目SLAM
2022-07-07 00:39:00 【3D視覺工坊】
點擊上方“3D視覺工坊”,選擇“星標”
幹貨第一時間送達

作者丨泡椒味的口香糖
來源丨GiantPandaCV
0. 引言
當人們在一個環境中四處走動時,他們通常會移動眼睛來聚焦並記住顯而易見的地標,這些地標通常包含最有價值的語義信息。基於這種人類本能,"Attention-SLAM: A Visual Monocular SLAM Learning from Human Gaze"的作者提出了一種新的方法來幫助SLAM系統模擬人類導航時的行為模式。該論文為語義SLAM和計算機視覺任務提出了一種全新的模式。此外,作者公開了他們標注了顯著性EuRoc數據集。
1. 論文信息
標題:Attention-SLAM: A Visual Monocular SLAM Learning from Human Gaze
作者:Jinquan Li, Ling Pei, Danping Zou, Songpengcheng Xia, Qi Wu, Tao Li, Zhen Sun, Wenxian Yu
來源:2020 Computer Vision and Pattern Recognition (CVPR)
原文鏈接:https://arxiv.org/abs/2009.06886v1
代碼鏈接:https://github.com/Li-Jinquan/Salient-Euroc
2. 摘要
本文提出了一種新穎的同步定比特與建圖(SLAM)方法,即Attention-SLAM,它通過結合視覺顯著性模型(SalNavNet)和傳統的單目視覺SLAM來模擬人類的導航模式。大多數SLAM方法在優化過程中將從圖像中提取的所有特征視為同等重要。然而,場景中的顯著特征點在人類導航過程中具有更顯著的影響。因此,我們首先提出了一個稱為SalVavNet的視覺顯著性模型,其中我們引入了一個相關性模塊,並提出了一個自適應指數移動平均(EMA)模塊。這些模塊减輕了中心偏差,以使SalNavNet生成的顯著圖能够更多地關注同一顯著對象。此外,顯著圖模擬了人的行為,用於改進SLAM結果。從顯著區域提取的特征點在優化過程中具有更大的權重。我們將語義顯著性信息添加到Euroc數據集,以生成開源顯著性SLAM數據集。綜合測試結果證明,在大多數測試案例中,Attention-SLAM在效率、准確性和魯棒性方面優於Direct Sparse Odometry (DSO)、ORB-SLAM和Salient DSO等基准。
3. 算法分析
如圖1所示是作者提出的Attention-SLAM架構,在架構主要是在基於特征點的視覺單目SLAM中加入顯著性語義信息。首先,作者利用顯著性模型來生成Euroc數據集的相應顯著性圖。這些圖顯示了圖像序列中每一幀的重要區域。其次,作者采用它們作為權值,使特征點在BA過程中具有不同的權重。它幫助系統保持語義的一致性。當圖像序列中存在相似紋理時,傳統的基於特征點的SLAM方法可能會出現誤匹配。這些失配點可能會降低SLAM系統的精度。因此,這種方法確保系統聚焦在最重要區域的特征點上,提高了准確性和效率。此外,作者還利用信息論來選擇關鍵幀和估計姿態估計的不確定性。
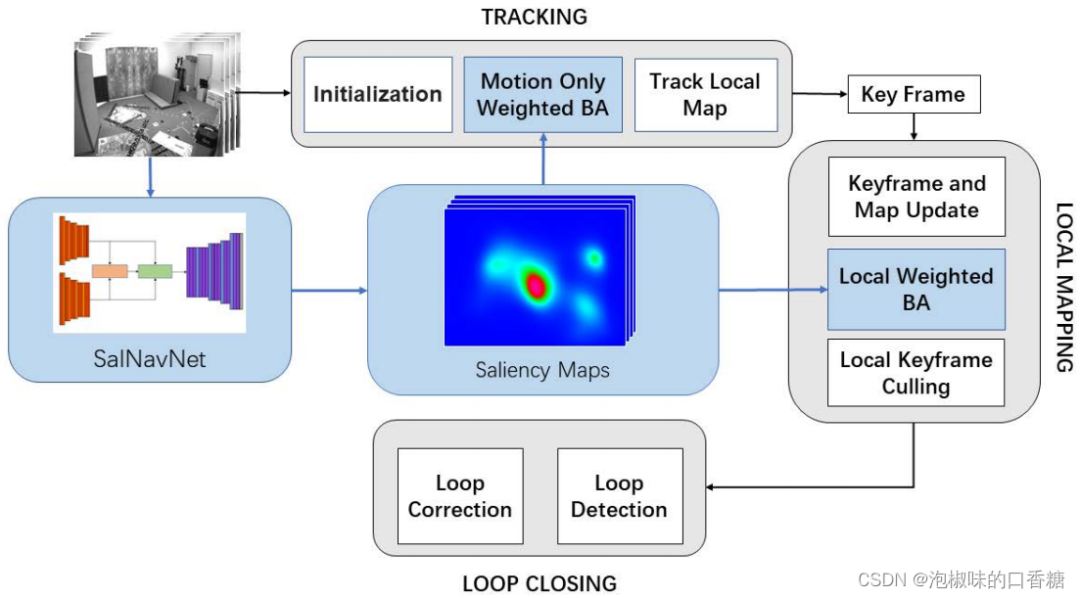
圖1 Attention-SLAM架構總覽
作者的主要貢獻如下:
(1) 作者提出了一種新穎的SLAM架構,即Attention-SLAM。該架構使用一種加權BA方法來代替SLAM中的傳統BA。它能更有效地减小軌迹誤差。通過在導航期間學習人類的注意,顯著特征被用於具有高權重的SLAM後端。與基准相比,Attention-SLAM可以用更少的關鍵幀减少姿態估計的不確定性,並獲得更高的精度。
(2) 作者提出了一個名為SalNavNet的視覺顯著性模型來預測幀中的顯著區域。主要在SalNavNet中引入了一個關聯模塊,並提出了一個自適應EMA模塊。這些模塊可以减輕顯著性模型的中心偏差,並學習幀之間的相關性信息。通過减輕大多數視覺顯著性模型所具有的中心偏差,SalNavNet提取的視覺顯著性語義信息可以幫助Attention-SLAM一致地聚焦於相同顯著對象的特征點。
(3) 通過應用SalNavNet,作者生成了一個基於EuRoc的開源顯著數據集。使用顯著性Euroc數據集的評估證明,Attention-SLAM在效率、准確性和魯棒性方面優於各項基准。
3.1 SalNavNet網絡架構
Attention-SLAM由兩部分組成,第一部分是輸入數據的預處理,第二部分是視覺SLAM系統。在第一部分,作者使用提出的SalNavNet生成對應於SLAM數據集的顯著圖。這些顯著圖被用作輸入來幫助SLAM系統找到顯著的關鍵點。
在幀序列中,顯著物體的比特置會隨著鏡頭移動。由於現有顯著性模型的中心偏差,只有當這些顯著對象到達圖像的中心時,顯著性模型才將其標記為顯著區域。當這些對象移動到圖像的邊緣時,顯著性模型會忽略這些對象。注意力的轉移使得視覺SLAM系統不能一致地聚焦於相同的顯著特征。在Attention-SLAM中,作者希望顯著性模型能够連續聚焦於相同的特征點,而不管它們是否在圖像的中心。因此,作者應用的SalNavNet的網絡結構如圖2所示,它采用與SalEMA和SalGAN相同的編碼器和解碼器結構,其中編碼器部分是VGG-16,解碼器使用與編碼器相反順序的網絡結構。SalNavNet可以在專注於上下文信息的同時,避免注意力的快速變化。
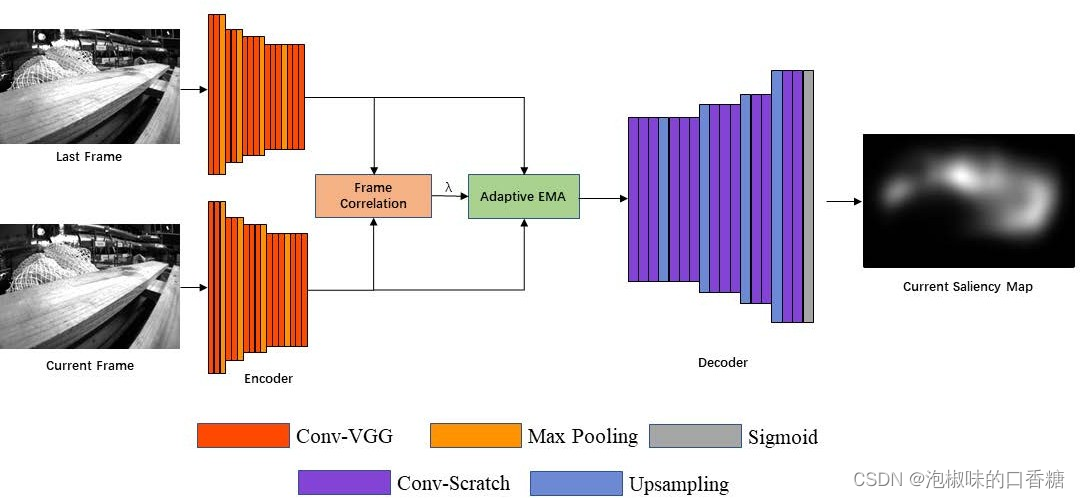
圖2 SalNavNet架構
為了學習幀間的連續信息,作者首先利用圖3所示的幀相關模塊,通過編碼器輸出比較當前幀的特征圖和通過編碼器輸出的前一幀的特征圖。最後,得到兩幀的相關系數λ,並將相關系數引入自適應EMA模塊。當λ接近1時,錶示兩個特征圖沒有變化。當相鄰特征圖的差异較大時,會使λ的值變小。因此,當兩個相鄰特征圖之間存在巨大變化時,顯著性模型生成的顯著性圖具有快速的注意力變化。
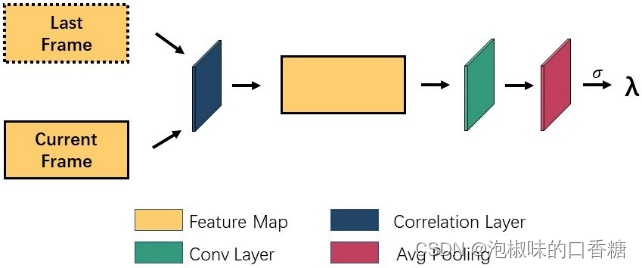
圖3 幀相關模塊架構
此外,作者設計了一個自適應EMA模塊,如圖4所示。一方面,自適應EMA模塊允許模型學習幀之間的連續信息。另一方面,相似系數λ的引入减輕了顯著模型的中心偏差和注意力的快速變化。在視覺顯著性領域,注意力的快速變化可以更好地模仿數據集的真實數據。
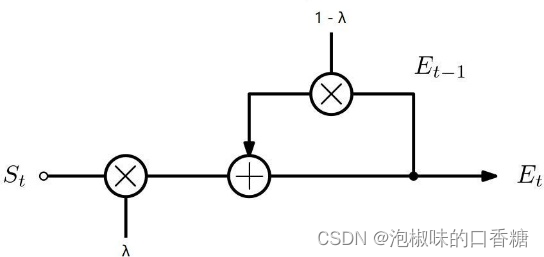
圖4 EMA模塊架構
3.2 權重BA優化及關鍵幀選擇
Attention-SLAM系統的第二部分使用顯著圖來提高優化精度和效率。作者使用視覺顯著性模型生成的模型作為權值。顯著性地圖是灰度地圖,其中白色部分的值為255,黑色部分的值為0。為了使用顯著性映射作為權重,作者將這些映射歸一化:
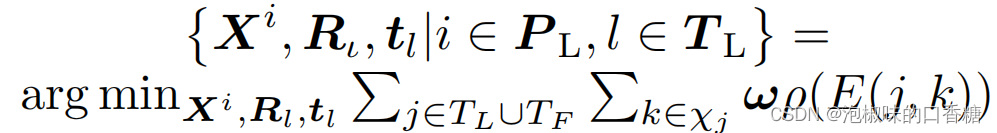
其中,重投影誤差計算公式為:
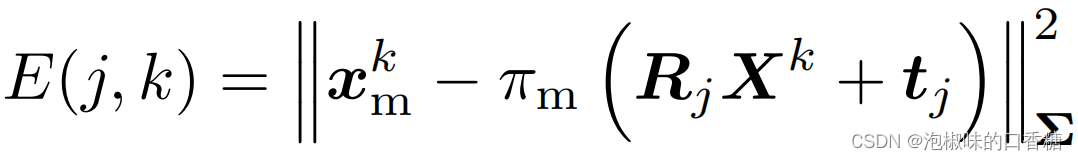
作者使用熵减少的概念作為選擇關鍵幀的標准,以進一步提高Attention-SLAM系統的性能。具體來說有如下幾個步驟:
(1) 利用熵比選擇關鍵幀:在Attention-SLAM的運動估計過程中,使用如下錶達式進行熵比計算:
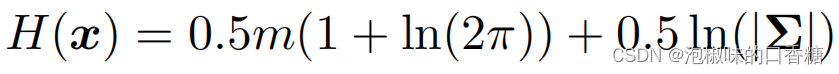
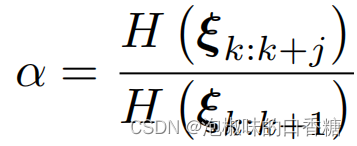
在原文中,作者設置α的閾值為0.9。當一幀的熵比超過0.9時,它將不會被選為關鍵幀。因為這意味著當前幀不能有效地降低運動估計的不確定性。
(2) 熵縮减評估:顯著性模型從環境中提取語義顯著性信息,這可能會使Attention-SLAM估計的軌迹更接近軌迹真值。因此,作者從信息論的角度分析了Attention-SLAM對姿態估計的不確定性的影響。計算公式如下:
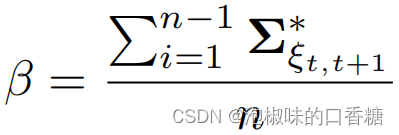
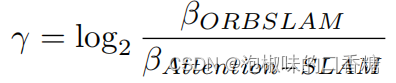
其中,n為關鍵幀數。作者主要計算ORB-SLAM和Attention-SLAM之間的熵縮减γ。如果Attention-SLAM在姿態估計過程中的不確定性小於ORB-SLAM,則γ將大於零。
4.實驗
作者首先分析了不同顯著性模型生成的顯著性圖對Attention-SLAM的影響,並使用顯著性模型生成了一個新的顯著性數據集,稱為顯著EuRoc。然後,作者在顯著的Euroc數據集上將Attention-SLAM與其他SOTA的視覺SLAM方法進行比較。作者使用的計算設備為i5-9300H CPU (2.4 GHz)和16G RAM。
4.1 基於Attention-SLAM的圖像顯著性模型
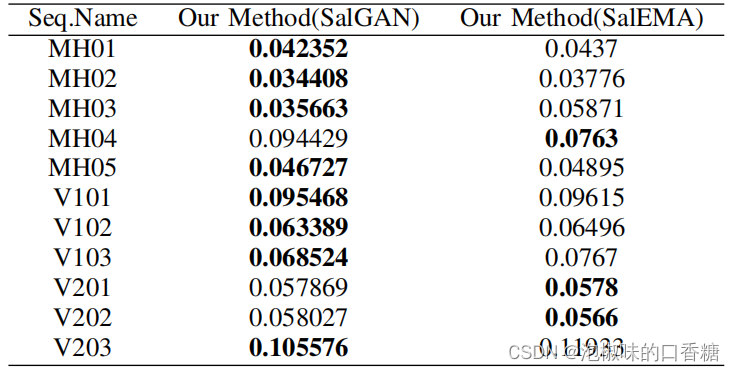
如圖5所示是分別使用顯著性模型SalGAN和顯著性模型SalEMA生成對應於Euroc數據集的顯著圖結果,SalEMA生成的顯著圖中的顯著區域很小,SalGAN生成的顯著圖的中心偏差較弱。錶1所示是計算的絕對軌迹誤差(ate)的均方根(RMSE)。結果顯示,SalGAN生成的顯著圖有助於Attention-SLAM在大多數數據序列中錶現更好,即弱中心偏置的顯著圖使得Attention-SLAM達到更高的精度。

圖5 顯著圖比較:(a)原始圖像序列 (b)SalEMA生成的顯著圖 (c)SalGAN生成的顯著圖
錶1 使用不同顯著性模型生成的權重,計算ORB-SLAM和Attention-SLAM之間的絕對軌迹誤差的RMSE
4.2 視頻顯著性模型與SalNavNet的比較
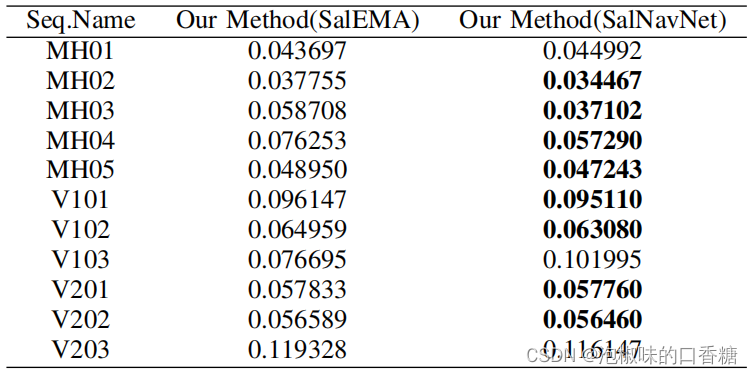
如圖6所示是SalEMA與SalNavNet生成的顯著圖對比。結果顯示,SalEMA生成的顯著圖具有很强的中心偏差。雖然相鄰的三幅原始圖像變化不大,但是SalEMA生成的顯著圖發生了顯著變化。而SalNavNet生成的顯著圖减輕了中心偏差。如錶2所示,SalNavNet在大多數數據序列中的錶現優於SalEMA。這意味著SalNavNet生成的顯著圖可以幫助Attention-SLAM比SalEMA獲得更好的性能。

圖6 顯著圖對比:(a)原始圖像序列 (b)SalEMA生成的顯著圖 (c)SalNavNet生成的顯著圖
錶2 使用最先進的顯著性模型SalEMA與使用SalNavNet的Attention-slam之間的絕對軌迹誤差的RMSE
4.3 顯著性Euroc數據集
為了驗證Attention-SLAM的有效性,作者在EuRoc數據集的基礎上建立了一個新的語義SLAM數據集。顯著性EuRoc數據集包括原始數據集中cam0的數據、真實值和相應的顯著性圖。圖7展示了顯著性Euroc數據集中三個連續的相框及其對應的視覺顯著性掩碼。可以發現,注意力隨著相機運動的變化而變化,但對顯著物體的注意是連續的。

圖7 顯著性EuRoc數據集:(a)原始圖像 (b)相應的顯著性錶示,其中白色部分錶示更高的關注度 (c)熱力圖錶示
4.4 與其他SLAM方法的比較
圖8所示是Attention-SLAM在V101數據集上的二維軌迹。結果錶明,使用Attention-SLAM估計的軌迹更接近真值。Attention-SLAM更加關注顯著的特征點,從而使姿態估計更接近真實值。為了更好地分析姿態估計的准確性,作者分別在圖9中繪制了三維姿態的估計值和真實值。並使用一個紅色的框架來擴大軌迹的重要部分。兩種方法在前40秒內都很好地跟踪了軌迹,但之後基線方法在X軸和Z軸上的大偏移量。在50-60秒時,Attention-SLAM可以更好地跟踪Z軸。
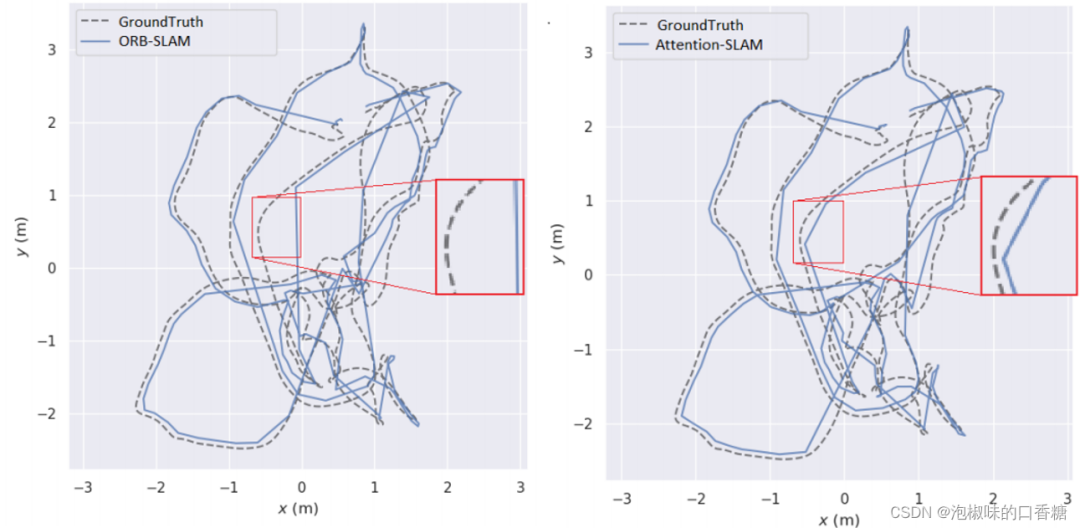
圖8 在v101數據集上ORB-SLAM和Attention-SLAM的2D軌迹比較
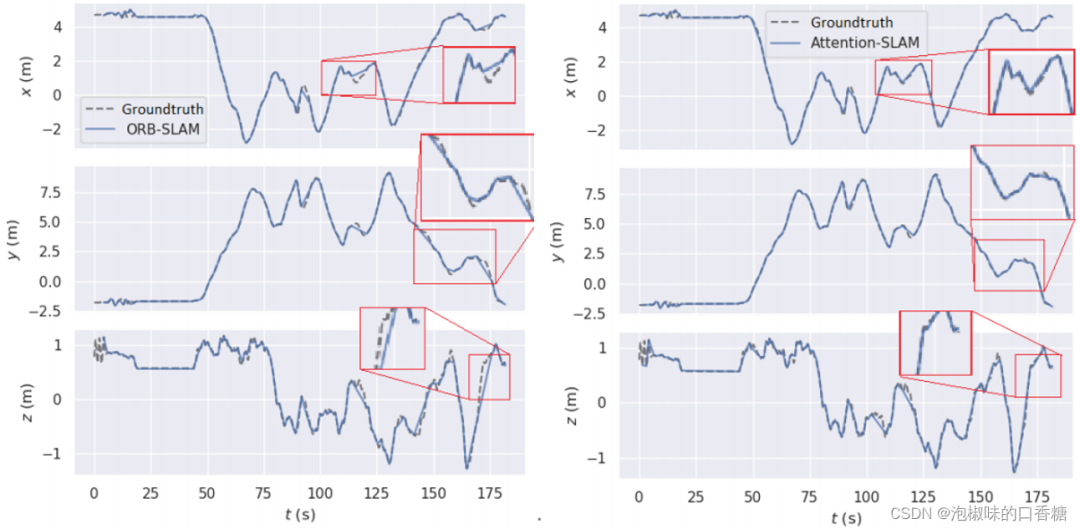
圖9 ORB-SLAM和Attention-SLAM的3D軌迹對比
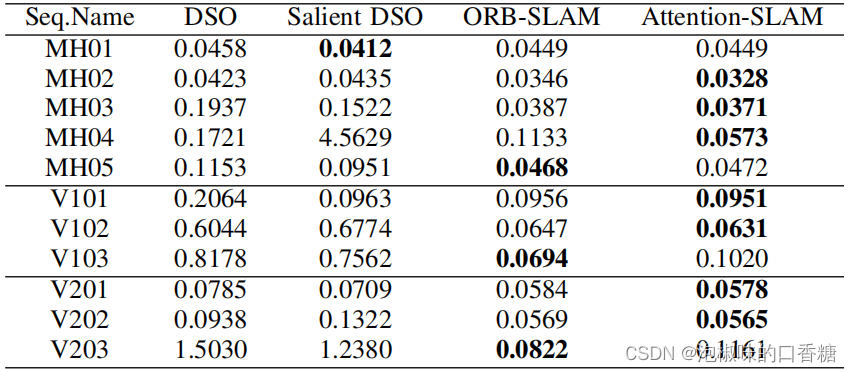
為了進一步評估Attention-SLAM,作者對比了Attention-SLAM和DSO的性能,結果如錶3和錶4所示。結果顯示,Attention-SLAM在大多數場景中獲得了較高精度。
錶3 相關方法和Attention-SLAM的平均絕對軌迹誤差
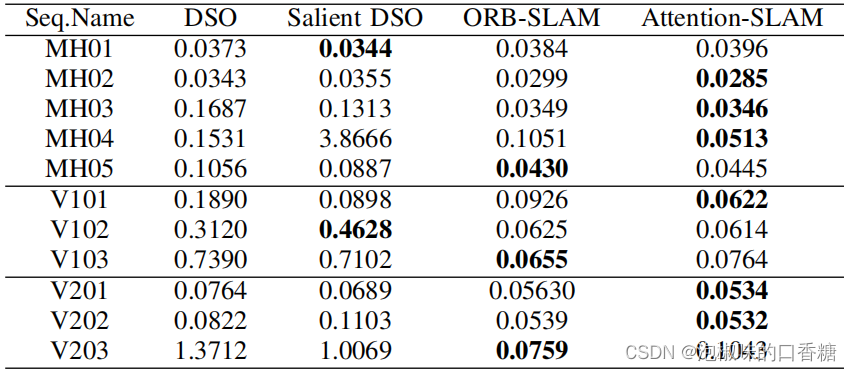
錶4 相關方法和Attention-SLAM的RMSE絕對軌迹誤差
錶5所示是ORB-SLAM和Attention-SLAM生成的關鍵幀對比。結果顯示,Attention-slam在最簡單和中等難度的數據序列中錶現良好,但在困難的序列中錶現不佳,例如MH04、MH05、V203、V103。
錶5 關鍵幀數量
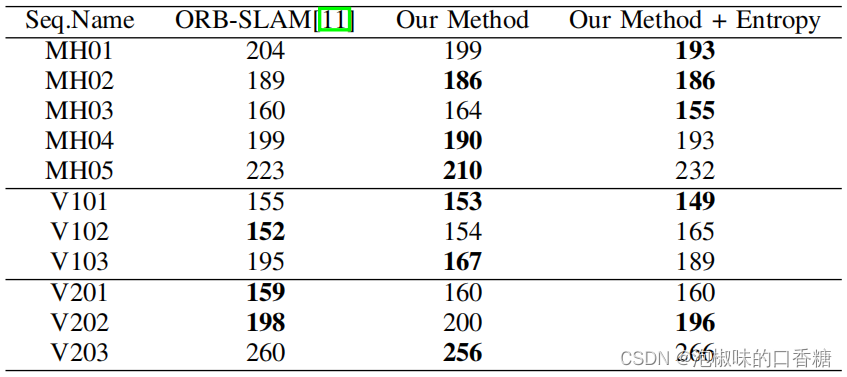
但在作者將熵關鍵幀選擇策略添加到Attention-SLAM之後,這個標准使得Attention-SLAM在困難的數據序列中選擇更多的關鍵幀。如錶6所示,這一標准使Attention-SLAM在困難的數據序列中錶現更好。因此,熵比度量是Attention-SLAM的一個重要策略。當顯著性模型向系統添加足够的語義信息時,就會使系統選擇更少的關鍵幀。當顯著性模型不能降低運動估計的不確定性時,會使系統選擇更多的關鍵幀以獲得更好的性能。
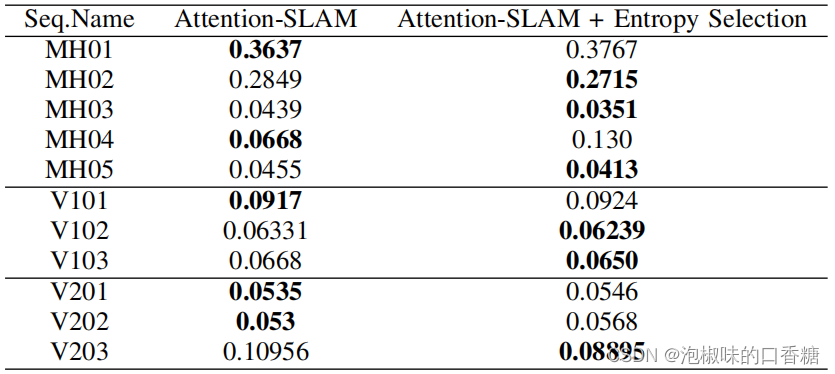
錶6 添加熵比選擇前後Attention-SLAM的平均ATE性能比較
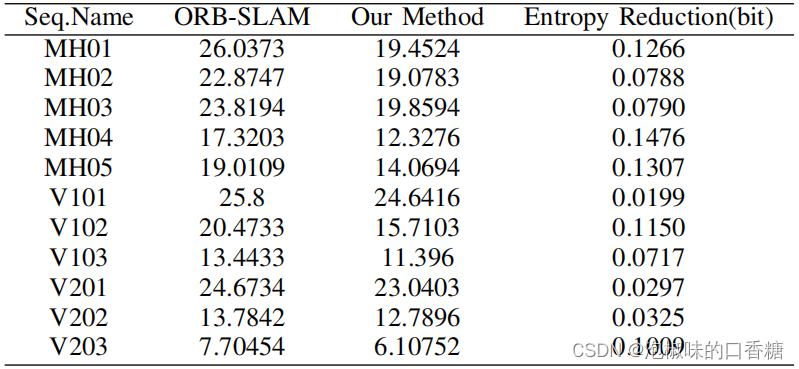
此外,如錶7所示,Attention-SLAM降低了傳統方法的不確定性,熵的减少與Attention-SLAM的精度呈正相關。
錶7 熵縮减的對比
5. 結論
在2020 CVPR論文"Attention-SLAM: A Visual Monocular SLAM Learning from Human Gaze"中,作者提出了一種稱為Attention-SLAM的語義SLAM方法。它結合了視覺顯著性語義信息和視覺SLAM系統。作者基於EuRoc數據集建立了顯著EuRoc,這是一個標注了顯著語義信息的SLAM數據集。與目前主流的單目視覺SLAM方法相比,該方法具有更高的效率和准確性,同時可以降低姿態估計的不確定性。
本文僅做學術分享,如有侵權,請聯系删文。
3D視覺工坊精品課程官網:3dcver.com
2.面向自動駕駛領域的3D點雲目標檢測全棧學習路線!(單模態+多模態/數據+代碼)
3.徹底搞透視覺三維重建:原理剖析、代碼講解、及優化改進
4.國內首個面向工業級實戰的點雲處理課程
5.激光-視覺-IMU-GPS融合SLAM算法梳理和代碼講解
6.徹底搞懂視覺-慣性SLAM:基於VINS-Fusion正式開課啦
7.徹底搞懂基於LOAM框架的3D激光SLAM: 源碼剖析到算法優化
8.徹底剖析室內、室外激光SLAM關鍵算法原理、代碼和實戰(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-學術論文寫作投稿 交流群已成立
掃碼添加小助手微信,可申請加入3D視覺工坊-學術論文寫作與投稿 微信交流群,旨在交流頂會、頂刊、SCI、EI等寫作與投稿事宜。
同時也可申請加入我們的細分方向交流群,目前主要有3D視覺、CV&深度學習、SLAM、三維重建、點雲後處理、自動駕駛、多傳感器融合、CV入門、三維測量、VR/AR、3D人臉識別、醫療影像、缺陷檢測、行人重識別、目標跟踪、視覺產品落地、視覺競賽、車牌識別、硬件選型、學術交流、求職交流、ORB-SLAM系列源碼交流、深度估計等微信群。
一定要備注:研究方向+學校/公司+昵稱,例如:”3D視覺 + 上海交大 + 靜靜“。請按照格式備注,可快速被通過且邀請進群。原創投稿也請聯系。

▲長按加微信群或投稿
▲長按關注公眾號
3D視覺從入門到精通知識星球:針對3D視覺領域的視頻課程(三維重建系列、三維點雲系列、結構光系列、手眼標定、相機標定、激光/視覺SLAM、自動駕駛等)、知識點匯總、入門進階學習路線、最新paper分享、疑問解答五個方面進行深耕,更有各類大廠的算法工程人員進行技術指導。與此同時,星球將聯合知名企業發布3D視覺相關算法開發崗比特以及項目對接信息,打造成集技術與就業為一體的鐵杆粉絲聚集區,近4000星球成員為創造更好的AI世界共同進步,知識星球入口:
學習3D視覺核心技術,掃描查看介紹,3天內無條件退款
圈裏有高質量教程資料、答疑解惑、助你高效解决問題
覺得有用,麻煩給個贊和在看~
边栏推荐
- Business process testing based on functional testing
- Core knowledge of distributed cache
- Three sentences to briefly introduce subnet mask
- Things like random
- Basic information of mujoco
- Wechat applet UploadFile server, wechat applet wx Uploadfile[easy to understand]
- Jenkins' user credentials plug-in installation
- Lombok 同时使⽤ @Data 和 @Builder 的坑,你中招没?
- 什么是时间
- Personal digestion of DDD
猜你喜欢
Business process testing based on functional testing

Mujoco second order simple pendulum modeling and control

How can computers ensure data security in the quantum era? The United States announced four alternative encryption algorithms
X.509 certificate based on go language
从外企离开,我才知道什么叫尊重跟合规…
一图看懂对程序员的误解:西方程序员眼中的中国程序员

If the college entrance examination goes well, I'm already graying out at the construction site at the moment
三维扫描体数据的VTK体绘制程序设计

37頁數字鄉村振興智慧農業整體規劃建設方案
How to set encoding in idea
随机推荐
Model-Free Prediction
iMeta | 华南农大陈程杰/夏瑞等发布TBtools构造Circos图的简单方法
How to judge whether an element in an array contains all attribute values of an object
Three methods to realize JS asynchronous loading
ZYNQ移植uCOSIII
Model-Free Control
What can the interactive slide screen demonstration bring to the enterprise exhibition hall
Data analysis course notes (III) array shape and calculation, numpy storage / reading data, indexing, slicing and splicing
陀螺仪的工作原理
"Latex" Introduction to latex mathematical formula "suggestions collection"
Leecode brush question record sword finger offer 56 - ii Number of occurrences of numbers in the array II
Operation test of function test basis
Explain in detail the implementation of call, apply and bind in JS (source code implementation)
C language input / output stream and file operation [II]
Advanced learning of MySQL -- basics -- transactions
Lombok makes ⽤ @data and @builder's pit at the same time. Are you hit?
Things like random
[CVPR 2022] target detection sota:dino: Detr with improved detecting anchor boxes for end to end object detection
DAY FOUR
Use mujoco to simulate Cassie robot