当前位置:网站首页>Attention slam: a visual monocular slam that learns from human attention
Attention slam: a visual monocular slam that learns from human attention
2022-07-07 00:41:00 【3D vision workshop】
Click on the above “3D Visual workshop ”, choice “ Star standard ”
The dry goods arrive at the first time

The author: Pepper flavored gum
Source GiantPandaCV
0. introduction
When people move around in an environment , They usually move their eyes to focus and remember obvious landmarks , These landmarks usually contain the most valuable semantic information . Based on this human instinct ,"Attention-SLAM: A Visual Monocular SLAM Learning from Human Gaze" The author of proposed a new method to help SLAM The system simulates the behavior pattern of human navigation . This paper is semantic SLAM And computer vision task . Besides , The author disclosed that they marked the significance EuRoc Data sets .
1. Paper information
title :Attention-SLAM: A Visual Monocular SLAM Learning from Human Gaze
author :Jinquan Li, Ling Pei, Danping Zou, Songpengcheng Xia, Qi Wu, Tao Li, Zhen Sun, Wenxian Yu
source :2020 Computer Vision and Pattern Recognition (CVPR)
Link to the original text :https://arxiv.org/abs/2009.06886v1
Code link :https://github.com/Li-Jinquan/Salient-Euroc
2. Abstract
This paper presents a novel method of synchronous location and mapping (SLAM) Method , namely Attention-SLAM, It combines visual saliency models (SalNavNet) And traditional monocular vision SLAM To simulate human navigation mode . majority SLAM Methods in the optimization process, all the features extracted from the image are regarded as equally important . However , The salient feature points in the scene have a more significant impact on human navigation . therefore , We first propose a new concept called SalVavNet Visual saliency model , Among them, we introduce a correlation module , An adaptive exponential moving average is proposed (EMA) modular . These modules reduce the center deviation , In order to make SalNavNet The generated saliency map can pay more attention to the same saliency object . Besides , Saliency diagram simulates human behavior , For improvement SLAM result . The feature points extracted from the salient region have greater weight in the optimization process . We add semantic saliency information to Euroc Data sets , To generate open source saliency SLAM Data sets . The comprehensive test results prove , In most test cases ,Attention-SLAM In efficiency 、 The accuracy and robustness are better than Direct Sparse Odometry (DSO)、ORB-SLAM and Salient DSO Wait for the benchmark .
3. Algorithm analysis
Pictured 1 Shown is the author's proposal Attention-SLAM framework , The architecture is mainly based on feature points of visual monocular SLAM Add significant semantic information . First , The author uses the significance model to generate Euroc The corresponding significance diagram of the data set . These figures show the important areas of each frame in the image sequence . secondly , The author uses them as weights , Make the feature point at BA There are different weights in the process . It helps the system maintain semantic consistency . When there are similar textures in the image sequence , Traditional feature point based SLAM Methods may be mismatched . These mismatches may be reduced SLAM The accuracy of the system . therefore , This method ensures that the system focuses on the feature points of the most important areas , Improved accuracy and efficiency . Besides , The author also uses information theory to select key frames and estimate the uncertainty of attitude estimation .
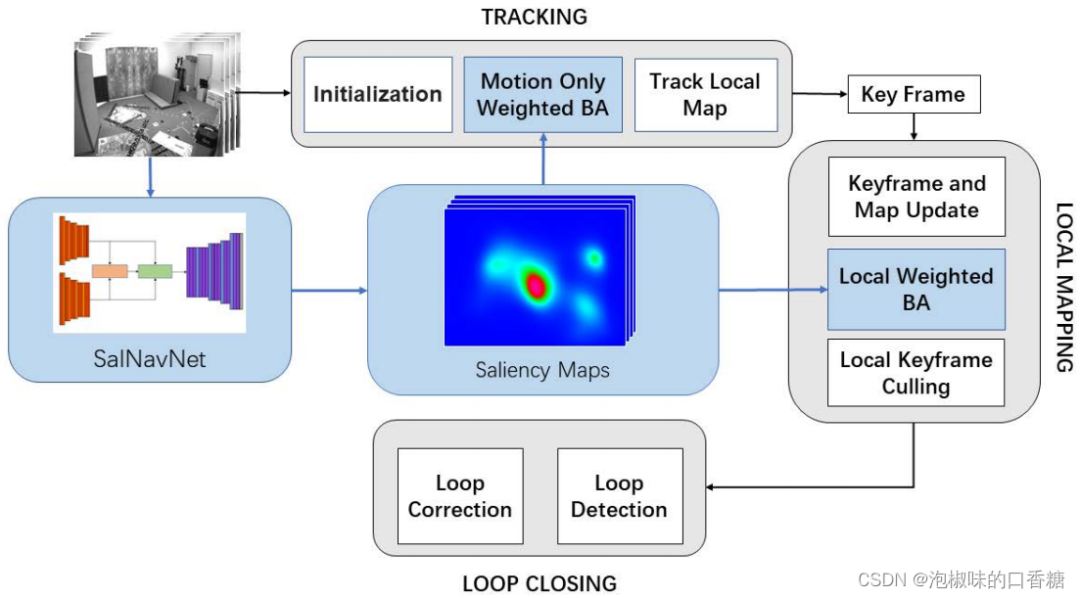
chart 1 Attention-SLAM Architectural Overview
The main contributions of the author are as follows :
(1) The author puts forward a novel SLAM framework , namely Attention-SLAM. The architecture uses a weighting BA Instead of SLAM The tradition of BA. It can reduce the trajectory error more effectively . By learning human attention during navigation , Salient features are used for SLAM Back end . Compared with the benchmark ,Attention-SLAM Fewer keyframes can be used to reduce the uncertainty of attitude estimation , And obtain higher accuracy .
(2) The author puts forward a new idea called SalNavNet Visual saliency model to predict the significant areas in the frame . Mainly in the SalNavNet An association module is introduced in , An adaptive EMA modular . These modules can reduce the center deviation of the saliency model , And learn the correlation information between frames . By reducing the center deviation of most visual saliency models ,SalNavNet The extracted visual saliency semantic information can help Attention-SLAM Focus uniformly on the feature points of the same prominent object .
(3) By applying the SalNavNet, The author has generated a web-based EuRoc Open source significant data set . Use significance Euroc The evaluation of the data set proves ,Attention-SLAM In efficiency 、 The accuracy and robustness are better than the benchmarks .
3.1 SalNavNet Network architecture
Attention-SLAM It's made up of two parts , The first part is the preprocessing of input data , The second part is vision SLAM System . In the first part , The author uses the proposed SalNavNet The generation corresponds to SLAM Saliency graph of data set . These salient figures are used as input to help SLAM The system finds significant key points .
In the frame sequence , The position of prominent objects will move with the lens . Due to the center deviation of the existing significance model , Only when these prominent objects reach the center of the image , The significance model marks it as a significant area . When these objects move to the edge of the image , The saliency model ignores these objects . The shift of attention makes vision SLAM The system cannot focus on the same salient features consistently . stay Attention-SLAM in , The author hopes that the saliency model can continuously focus on the same feature points , Whether or not they are in the center of the image . therefore , The author applied SalNavNet The network structure is shown in the figure 2 Shown , It uses and SalEMA and SalGAN Same encoder and decoder structure , The encoder part is VGG-16, The decoder uses a network structure in the reverse order of the encoder .SalNavNet You can focus on contextual information while , Avoid rapid changes in attention .
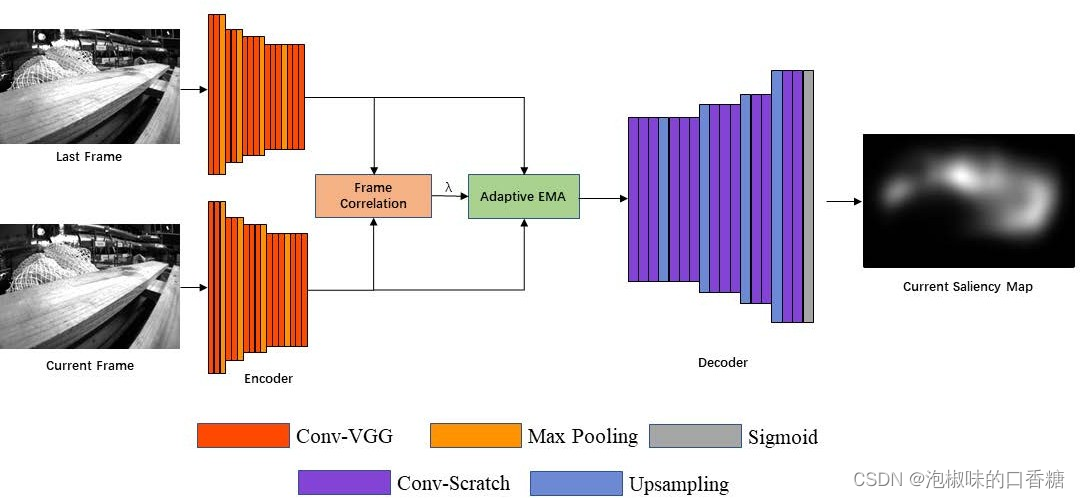
chart 2 SalNavNet framework
In order to learn continuous information between frames , The author first uses the graph 3 The frame correlation module shown , Compare the feature map of the current frame with the feature map of the previous frame output by the encoder . Last , Get the correlation coefficient of two frames λ, And the correlation coefficient is introduced into the adaptive EMA modular . When λ near 1 when , It indicates that the two characteristic diagrams have not changed . When the difference between adjacent feature maps is large , Can make λ The value of becomes smaller . therefore , When there are great changes between two adjacent feature maps , The saliency map generated by the saliency model has rapid attention changes .
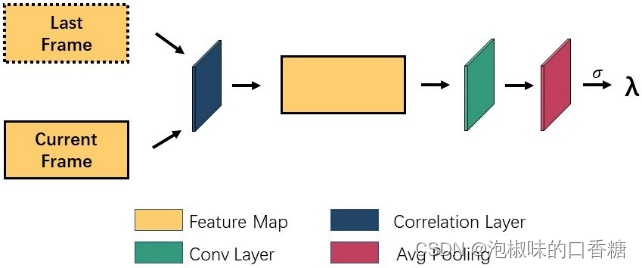
chart 3 Frame related module architecture
Besides , The author designed an adaptive EMA modular , Pictured 4 Shown . One side , The adaptive EMA The module allows the model to learn continuous information between frames . On the other hand , Similarity coefficient λ The introduction of reduces the center deviation of the significant model and the rapid change of attention . In the field of visual saliency , The rapid change of attention can better simulate the real data of the data set .
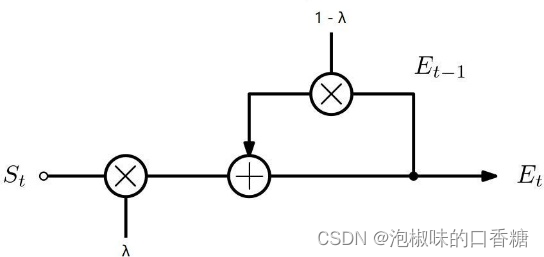
chart 4 EMA Module architecture
3.2 The weight BA Optimization and key frame selection
Attention-SLAM The second part of the system uses saliency graph to improve the optimization accuracy and efficiency . The author uses the model generated by the visual saliency model as the weight . The saliency map is a grayscale map , The value of the white part is 255, The value of the black part is 0. In order to use significance mapping as weight , The author normalizes these mappings :
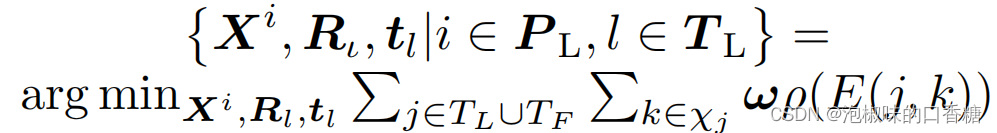
among , The calculation formula of re projection error is :
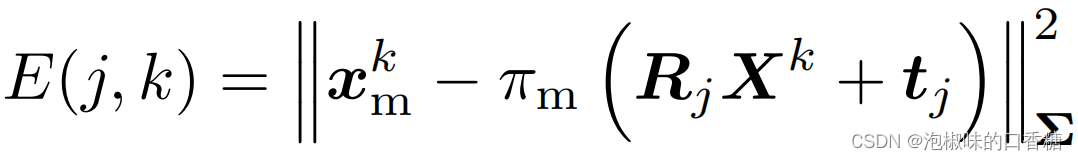
The author uses the concept of entropy reduction as the criterion for selecting key frames , To further improve Attention-SLAM System performance . Specifically, there are the following steps :
(1) Use entropy ratio to select key frames : stay Attention-SLAM In the process of motion estimation , Use the following expression to calculate the entropy ratio :
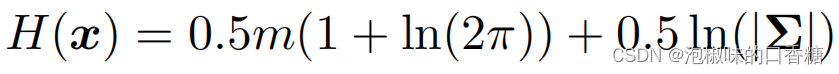
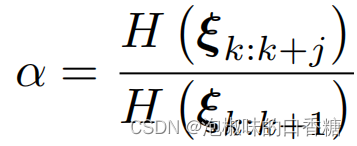
in the original , Author settings α The threshold of is 0.9. When the entropy ratio of a frame exceeds 0.9 when , It will not be selected as a key . Because this means that the current frame cannot effectively reduce the uncertainty of motion estimation .
(2) Entropy reduction assessment : Saliency model extracts semantic saliency information from the environment , This may make Attention-SLAM The estimated trajectory is closer to the true value of the trajectory . therefore , The author analyzes Attention-SLAM Influence on the uncertainty of attitude estimation . The calculation formula is as follows :
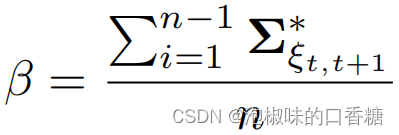
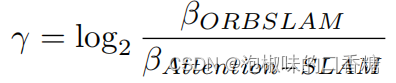
among ,n Is the number of key frames . The author mainly calculates ORB-SLAM and Attention-SLAM Entropy reduction between γ. If Attention-SLAM The uncertainty in attitude estimation is less than ORB-SLAM, be γ Will be greater than zero .
4. experiment
The author first analyzes the saliency map pairs generated by different saliency models Attention-SLAM Influence , A new significance data set is generated by using the significance model , Called significant EuRoc. then , The author is obviously Euroc There will be Attention-SLAM And others SOTA Vision of SLAM Methods for comparison . The computing device used by the author is i5-9300H CPU (2.4 GHz) and 16G RAM.
4.1 be based on Attention-SLAM Image saliency model
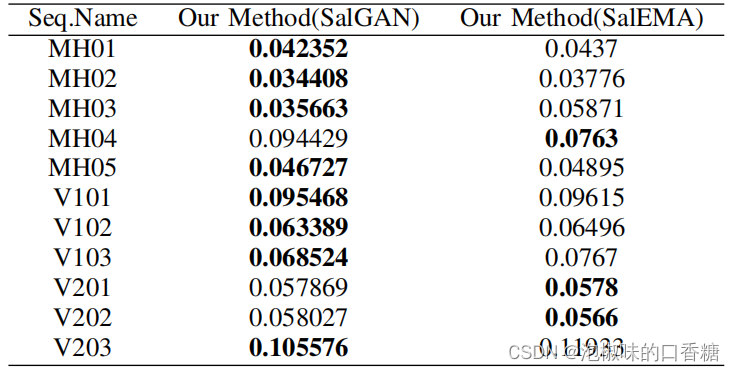
Pictured 5 It is shown that the significance models are used respectively SalGAN And significance model SalEMA The generation corresponds to Euroc Significant graph results of the data set ,SalEMA The saliency area in the generated saliency map is very small ,SalGAN The center deviation of the generated saliency map is weak . surface 1 The calculated absolute trajectory error is shown (ate) Root mean square of (RMSE). Results show ,SalGAN The resulting saliency map helps Attention-SLAM It performs better in most data sequences , That is, the saliency graph of weak center offset makes Attention-SLAM To achieve higher precision .

chart 5 Saliency map comparison :(a) Original image sequence (b)SalEMA Generated saliency map (c)SalGAN Generated saliency map
surface 1 Weights generated using different significance models , Calculation ORB-SLAM and Attention-SLAM Between the absolute trajectory error RMSE
4.2 Video saliency model and SalNavNet Comparison
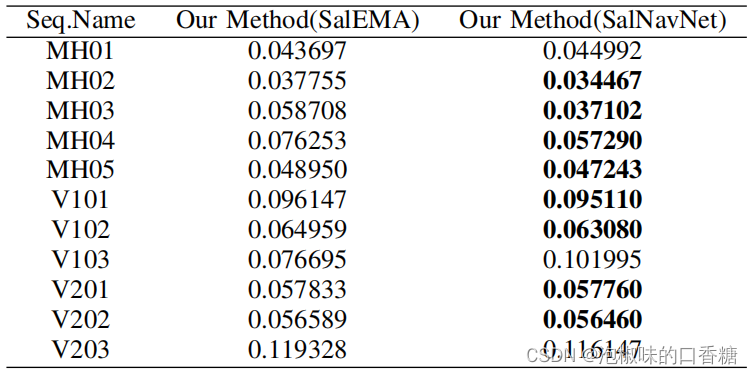
Pictured 6 It shows SalEMA And SalNavNet Generated saliency map comparison . Results show ,SalEMA The generated saliency graph has a strong center deviation . Although the adjacent three original images have little change , however SalEMA The generated saliency map has changed significantly . and SalNavNet The resulting saliency map reduces the center deviation . As shown in the table 2 Shown ,SalNavNet In most data series, the performance is better than SalEMA. It means SalNavNet The generated saliency map can help Attention-SLAM Than SalEMA Get better performance .

chart 6 Saliency chart comparison :(a) Original image sequence (b)SalEMA Generated saliency map (c)SalNavNet Generated saliency map
surface 2 Use the most advanced saliency model SalEMA And use SalNavNet Of Attention-slam Between the absolute trajectory error RMSE
4.3 Significance Euroc Data sets
In order to verify Attention-SLAM The effectiveness of the , The author in EuRoc A new semantic is established based on the dataset SLAM Data sets . Significance EuRoc The dataset includes the original dataset cam0 The data of 、 True value and corresponding significance diagram . chart 7 Shows the significance Euroc Three consecutive frames in the dataset and their corresponding visual saliency masks . You can find , Attention changes as the camera moves , But attention to significant objects is continuous .

chart 7 Significance EuRoc Data sets :(a) original image (b) The corresponding significance indicates , The white part indicates higher attention (c) Thermodynamic diagram shows
4.4 And others SLAM Comparison of methods
chart 8 It shows Attention-SLAM stay V101 Two dimensional trajectory on data set . It turns out that , Use Attention-SLAM The estimated trajectory is closer to the truth .Attention-SLAM Pay more attention to the salient features , Thus, the attitude estimation is closer to the real value . In order to better analyze the accuracy of attitude estimation , The author is in Figure 9 The estimated and real values of three-dimensional pose are plotted in . And use a red frame to expand important parts of the track . Two methods are first 40 Track the track well within seconds , But then the baseline method is X Axis and Z Large offset on the axis . stay 50-60 seconds ,Attention-SLAM Can better track Z Axis .
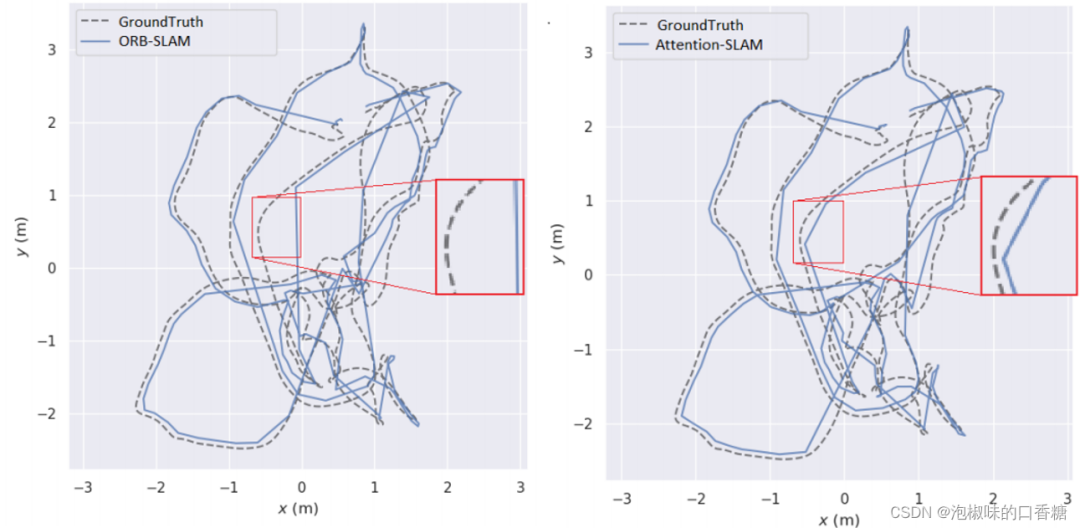
chart 8 stay v101 On dataset ORB-SLAM and Attention-SLAM Of 2D Trajectory comparison
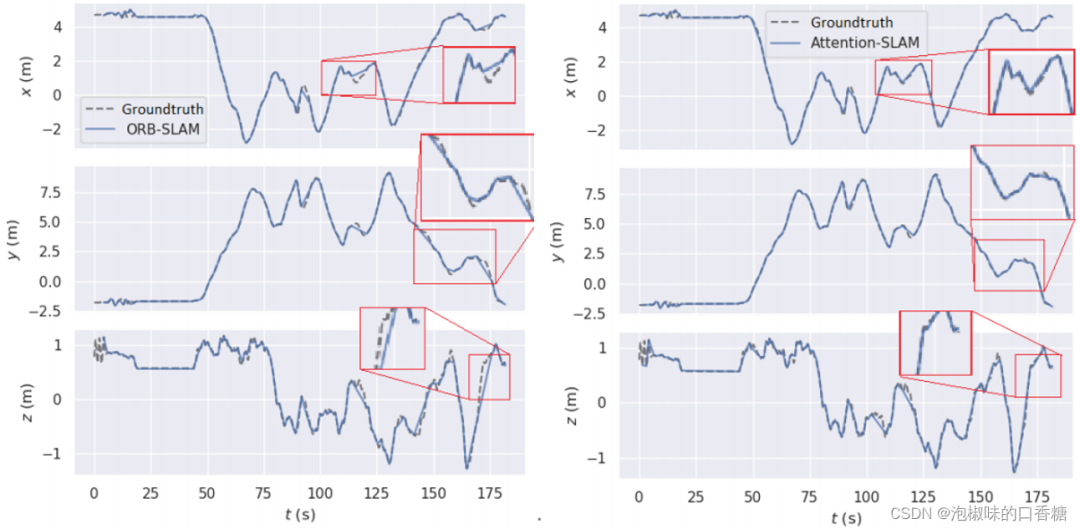
chart 9 ORB-SLAM and Attention-SLAM Of 3D Trajectory comparison
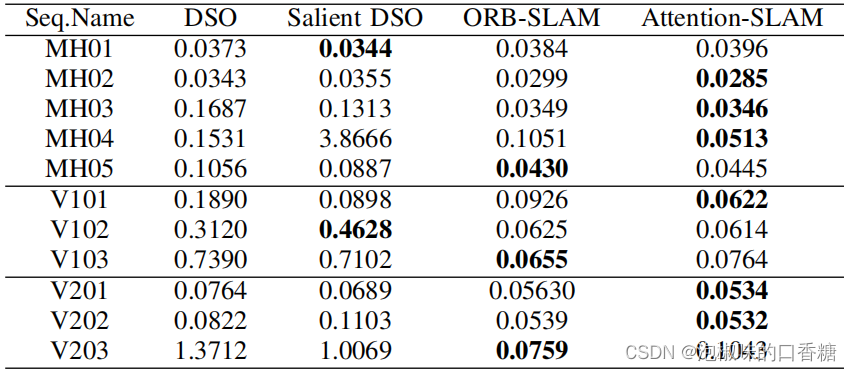
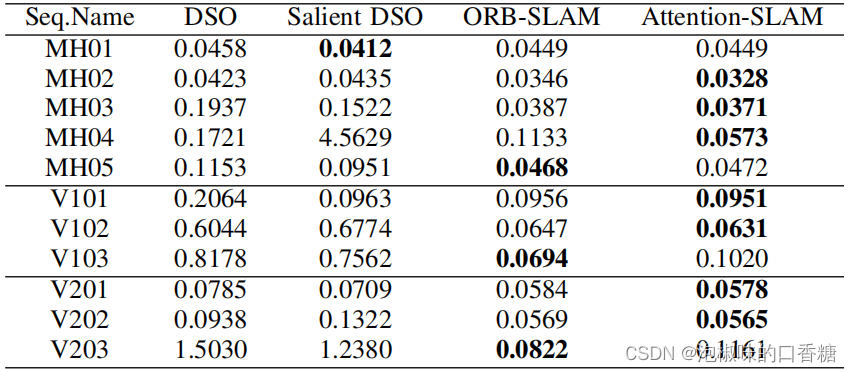
To further assess Attention-SLAM, The author contrasts Attention-SLAM and DSO Performance of , Results such as table 3 And table 4 Shown . Results show ,Attention-SLAM High accuracy is achieved in most scenes .
surface 3 Related methods and Attention-SLAM Mean absolute trajectory error of
surface 4 Related methods and Attention-SLAM Of RMSE Absolute trajectory error
surface 5 It shows ORB-SLAM and Attention-SLAM Generated key frame comparison . Results show ,Attention-slam It performs well in the simplest and moderately difficult data series , But it doesn't perform well in difficult sequences , for example MH04、MH05、V203、V103.
surface 5 Number of keyframes
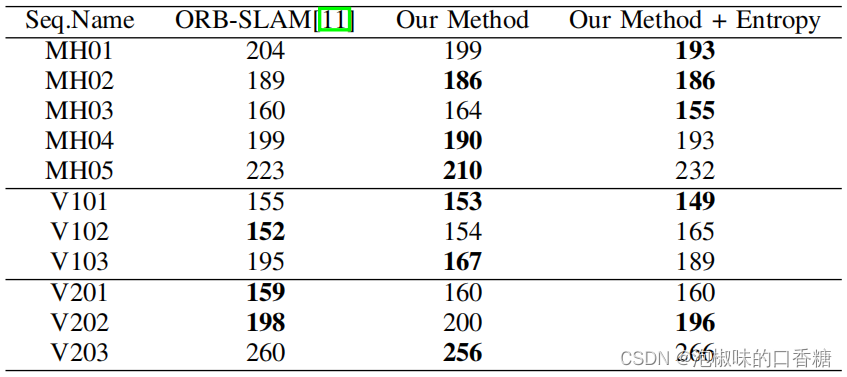
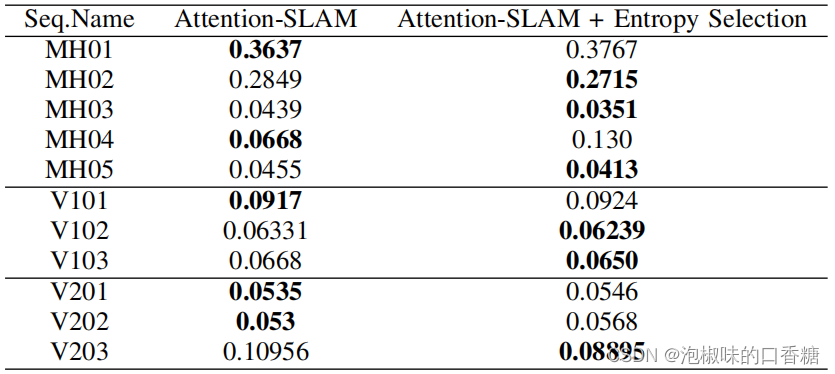
But after the author added the entropy key frame selection strategy to Attention-SLAM after , This standard makes Attention-SLAM Choose more keyframes in difficult data sequences . As shown in the table 6 Shown , This standard makes Attention-SLAM Perform better in difficult data sequences . therefore , The entropy ratio measure is Attention-SLAM An important strategy of . When the saliency model adds enough semantic information to the system , It will make the system choose fewer keyframes . When the significance model cannot reduce the uncertainty of motion estimation , It will enable the system to select more keyframes for better performance .
surface 6 Add entropy ratio before and after selection Attention-SLAM The average of ATE Performance comparison
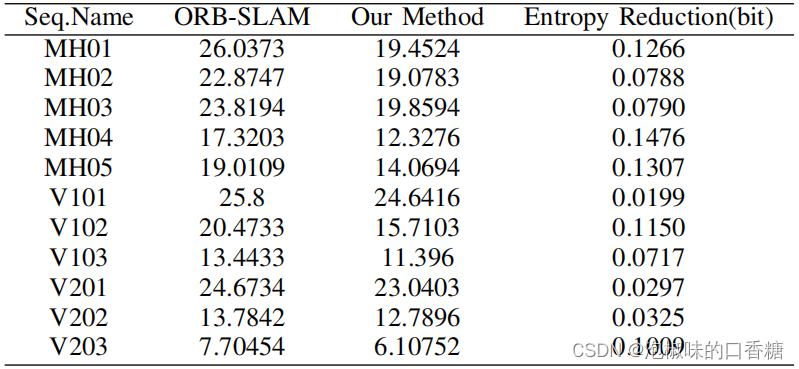
Besides , As shown in the table 7 Shown ,Attention-SLAM It reduces the uncertainty of traditional methods , The reduction of entropy is related to Attention-SLAM The accuracy of is positively correlated .
surface 7 Contrast of entropy reduction
5. Conclusion
stay 2020 CVPR The paper "Attention-SLAM: A Visual Monocular SLAM Learning from Human Gaze" in , The author proposes a method called Attention-SLAM The semantics of the SLAM Method . It combines visual saliency semantic information with visual SLAM System . The author is based on EuRoc The data set establishes significant EuRoc, This is a marked with significant semantic information SLAM Data sets . With the current mainstream monocular vision SLAM Methods compared , This method has higher efficiency and accuracy , At the same time, the uncertainty of attitude estimation can be reduced .
This article is only for academic sharing , If there is any infringement , Please contact to delete .
3D Visual workshop boutique course official website :3dcver.com
1. Multi sensor data fusion technology for automatic driving field
2. For the field of automatic driving 3D Whole stack learning route of point cloud target detection !( Single mode + Multimodal / data + Code )
3. Thoroughly understand the visual three-dimensional reconstruction : Principle analysis 、 Code explanation 、 Optimization and improvement
4. China's first point cloud processing course for industrial practice
5. laser - Vision -IMU-GPS The fusion SLAM Algorithm sorting and code explanation
6. Thoroughly understand the vision - inertia SLAM: be based on VINS-Fusion The class officially started
7. Thoroughly understand based on LOAM Framework of the 3D laser SLAM: Source code analysis to algorithm optimization
8. Thorough analysis of indoor 、 Outdoor laser SLAM Key algorithm principle 、 Code and actual combat (cartographer+LOAM +LIO-SAM)
10. Monocular depth estimation method : Algorithm sorting and code implementation
11. Deployment of deep learning model in autopilot
12. Camera model and calibration ( Monocular + Binocular + fisheye )
13. blockbuster ! Four rotor aircraft : Algorithm and practice
14.ROS2 From entry to mastery : Theory and practice
15. The first one in China 3D Defect detection tutorial : theory 、 Source code and actual combat
16. be based on Open3D Introduction and practical tutorial of point cloud processing
blockbuster !3DCVer- Academic paper writing contribution Communication group Established
Scan the code to add a little assistant wechat , can Apply to join 3D Visual workshop - Academic paper writing and contribution WeChat ac group , The purpose is to communicate with each other 、 Top issue 、SCI、EI And so on .
meanwhile You can also apply to join our subdivided direction communication group , At present, there are mainly 3D Vision 、CV& Deep learning 、SLAM、 Three dimensional reconstruction 、 Point cloud post processing 、 Autopilot 、 Multi-sensor fusion 、CV introduction 、 Three dimensional measurement 、VR/AR、3D Face recognition 、 Medical imaging 、 defect detection 、 Pedestrian recognition 、 Target tracking 、 Visual products landing 、 The visual contest 、 License plate recognition 、 Hardware selection 、 Academic exchange 、 Job exchange 、ORB-SLAM Series source code exchange 、 Depth estimation Wait for wechat group .
Be sure to note : Research direction + School / company + nickname , for example :”3D Vision + Shanghai Jiaotong University + quietly “. Please note... According to the format , Can be quickly passed and invited into the group . Original contribution Please also contact .

▲ Long press and add wechat group or contribute
▲ The official account of long click attention
3D Vision goes from entry to mastery of knowledge : in the light of 3D In the field of vision Video Course cheng ( 3D reconstruction series 、 3D point cloud series 、 Structured light series 、 Hand eye calibration 、 Camera calibration 、 laser / Vision SLAM、 Automatically Driving, etc )、 Summary of knowledge points 、 Introduction advanced learning route 、 newest paper Share 、 Question answer Carry out deep cultivation in five aspects , There are also algorithm engineers from various large factories to provide technical guidance . meanwhile , The planet will be jointly released by well-known enterprises 3D Vision related algorithm development positions and project docking information , Create a set of technology and employment as one of the iron fans gathering area , near 4000 Planet members create better AI The world is making progress together , Knowledge planet portal :
Study 3D Visual core technology , Scan to see the introduction ,3 Unconditional refund within days
There are high quality tutorial materials in the circle 、 Answer questions and solve doubts 、 Help you solve problems efficiently
Feel useful , Please give me a compliment ~
边栏推荐
- Huawei mate8 battery price_ Huawei mate8 charges very slowly after replacing the battery
- What is web penetration testing_ Infiltration practice
- What is AVL tree?
- 基於GO語言實現的X.509證書
- Advanced learning of MySQL -- basics -- multi table query -- self join
- "Latex" Introduction to latex mathematical formula "suggestions collection"
- Personal digestion of DDD
- Typescript incremental compilation
- alexnet实验偶遇:loss nan, train acc 0.100, test acc 0.100情况
- stm32F407-------DAC数模转换
猜你喜欢
【YoloV5 6.0|6.1 部署 TensorRT到torchserve】环境搭建|模型转换|engine模型部署(详细的packet文件编写方法)

stm32F407-------DAC数模转换
从外企离开,我才知道什么叫尊重跟合规…

The programmer resigned and was sentenced to 10 months for deleting the code. Jingdong came home and said that it took 30000 to restore the database. Netizen: This is really a revenge

AI超清修复出黄家驹眼里的光、LeCun大佬《深度学习》课程生还报告、绝美画作只需一行代码、AI最新论文 | ShowMeAI资讯日报 #07.06
三维扫描体数据的VTK体绘制程序设计
Clipboard management tool paste Chinese version
stm32F407-------SPI通信

equals()与hashCode()
AI super clear repair resurfaces the light in Huang Jiaju's eyes, Lecun boss's "deep learning" course survival report, beautiful paintings only need one line of code, AI's latest paper | showmeai info
随机推荐
JWT signature does not match locally computed signature. JWT validity cannot be asserted and should
[CVPR 2022] semi supervised object detection: dense learning based semi supervised object detection
Amazon MemoryDB for Redis 和 Amazon ElastiCache for Redis 的内存优化
Model-Free Control
Introduction au GPIO
Leecode brush question record sword finger offer 58 - ii Rotate string left
Racher integrates LDAP to realize unified account login
stm32F407-------SPI通信
Clipboard management tool paste Chinese version
[daily problem insight] prefix and -- count the number of fertile pyramids in the farm
uniapp中redirectTo和navigateTo的区别
Jenkins' user credentials plug-in installation
Data sharing of the 835 postgraduate entrance examination of software engineering in Hainan University in 23
基于SSM框架的文章管理系统
C语言输入/输出流和文件操作【二】
Interface master v3.9, API low code development tool, build your interface service platform immediately
ldap创建公司组织、人员
48页数字政府智慧政务一网通办解决方案
Are you ready to automate continuous deployment in ci/cd?
Leecode brushes questions and records interview questions 01.02 Determine whether it is character rearrangement for each other