当前位置:网站首页>[vector retrieval research series] product introduction
[vector retrieval research series] product introduction
2022-07-06 23:58:00 【Luoyger】
1. Product profile
1.1 Product comparison
There are many excellent products in the field of vector retrieval , Different products have their own characteristics , For different scenarios , Next, we will talk about what we have learned 8 Excellent vector retrieval products for a simple introduction .
- Milvus
- Faiss
- HNSWlib
- ScaNN
- SPTAG
- Vearch
- Zsearch
- Proxima
The comparison of these products is as follows , Advantages and disadvantages are briefly introduced here , For detailed introduction, please refer to the detailed introduction of each product .
Serial number | Product name | source | Open source or not | developer | Github Star Count | advantage | shortcoming |
|---|---|---|---|---|---|---|---|
1 | Milvus | external | yes | Zilliz( Shanghai ) | 9.1k | There are many index types , The community is active | Data fragmentation is not supported , The architecture is complex |
2 | Faiss | external | yes | 15.9k | Good performance , There are many index types , mature | Service orientation is not supported | |
3 | HNSWlib | external | yes | nmslib | 1.8k | Good performance , High recall rate | Service orientation is not supported |
4 | ScaNN | external | yes | 21.4k | Good performance , High recall rate | Service orientation is not supported | |
5 | SPTAG | external | yes | Microsoft | 4.1k | Good performance | Few index types |
6 | Vearch | external | yes | JD.COM | 1.3k | Good performance | Can't update in real time |
7 | Zsearch | external | no | The ant gold dress | / | There are many index types | Not open source |
8 | Proxima | external | no | Aridamo house | / | There are many index types | Not open source |
1.2 Technical comparison
Serial number | product | Real time updates | Filter function | CPU and GPU | Cluster pattern | Servability | development language | SDK |
|---|---|---|---|---|---|---|---|---|
1 | Milvus | yes | yes | yes | yes | yes | Go/Python | Python/Go/Java/Node |
2 | Faiss | yes | no | yes | no | no | C++ | C++/Python |
3 | HNSWlib | yes | no | yes | no | no | C++ | C++/Python |
4 | ScaNN | yes | no | yes | no | no | C++/Python | C++/Python |
5 | SPTAG | yes | no | yes | yes | yes | C++ | Python/C# |
6 | Vearch | no | no | yes | yes | yes | Go | Python |
1.3 Performance comparison
ANN-Benchmark The website has tested the performance of the existing popular vector retrieval products , The test results are displayed on its official website .
ANN-Benchmark Official website :http://ann-benchmarks.com/
Github Address :https://github.com/erikbern/ann-benchmarks
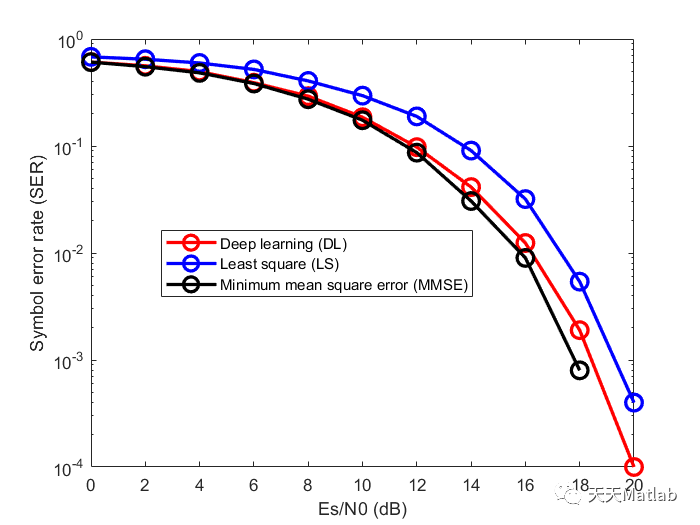
Some performance test results are as follows , For more test results, please refer to the official website . It can be seen from the test results Google Of ScaNN Indexing and based on HNSW The index performance of is better .
- glove-100-angular (k = 10) Vector retrieval inner product distance of data set top 10 test result
- fashion-mnist-784-euclidean (k = 10) Vector retrieval of data set Euclidean distance top 10 test result
2. Product introduction
2.1 Milvus
Milvus It is a domestic company named Zilliz The company's open source vector retrieval product ,Zilliz The company is Shanghai norui Information Technology Co., Ltd., which was established in 2017 Founded in the AI Unstructured data processing and analysis brand .
Zilliz Official website :https://zilliz.com/
Milvus On 2019 In open source , Mainly used for storage 、 Index and manage massive vector data generated by deep neural networks and machine learning models . References are as follows :
- Mivlvus Official website :https://milvus.io/cn/
- Github Address :https://github.com/milvus-io/milvus
- Hub Warehouse :https://hub.docker.com/search?q=milvus&type=image
- Cluster configuration :https://github.com/zilliz-bootcamp/Milvus_distributed_based_mishards
- Monitoring configuration :https://github.com/milvus-io/docs/tree/master/v1.1.0/assets/monitoring
- Development guidelines :https://github.com/milvus-io/milvus/blob/master/docs/developer_guides/chap01_system_overview.md
- The performance data :https://github.com/milvus-io/milvus/blob/master/docs/test_report/milvus_ivfsq8_test_report_detailed_version.md
- test result :https://github.com/milvus-io/bootcamp/tree/master/benchmark_test
- Docker Internal compilation Server:https://github.com/milvus-io/milvus/blob/1.1/INSTALL.md
- Introduction to data catalogue :https://mp.weixin.qq.com/s/_x5XtbaBMO9JCBG2r6VkWQ
- CSDN:https://zilliz.blog.csdn.net/
Milvus newest 2.0 Version Architecture
advantage
- High performance : Excellent performance , Vector similarity retrieval can be carried out on massive data sets .
- High availability 、 Highly reliable :Milvus Support for cloud expansion , The availability of disaster recovery services can be guaranteed .
- Hybrid query :Milvus Support scalar field filtering in the process of vector similarity retrieval , Implement hybrid query .
- Developer friendly : Support for multiple languages 、 Multi Tool Milvus The ecological system .
- More information , Has joined linux Fund projects , The technology community is well maintained , I also have my own blog updated in time .
- Support CPU and GPU Pattern .
- Support service-oriented and clustered deployment .
- Support filtering function .
- Support real-time update .
shortcoming
- Data fragmentation is not supported .
- Use third-party storage , The access delay is slightly worse .
- The architecture is complex , There are many dependent components , There are many factors affecting stability .
2.2 Faiss
Faiss yes Facebook An excellent open source product , The supported index types are very rich , The product is also very mature ,Faiss It mainly combines various basic algorithms to form high-performance index types in different scenarios , Many other excellent products are based on Faiss Further optimization .
Github Address :https://github.com/facebookresearch/faiss
file :https://github.com/facebookresearch/faiss/wiki
Supported indexes , Common indexing algorithms can be found in Faiss See the application .
- IndexFlatL2
- IndexFlatIP
- IndexHNSWFlat
- IndexIVFFlat
- IndexLSH
- IndexScalarQuantizer
- IndexPQ
- IndexIVFScalarQuantizer
- IndexIVFPQ
- IndexIVFPQR
- IndexBinaryFlat
- IndexBinaryIVF
- IndexBinaryHNSW
- IndexBinaryHash
- IndexBinaryMultiHash
advantage
- Index types are very rich .
- The product is very mature .
- The documents are quite complete .
- Support CPU and GPU Pattern .
- Support real-time update .
shortcoming
- Service and cluster deployment are not supported .
- Filtering function is not supported .
2.3 HNSWlib
HNSWlib(Hierarchical Navigating Small World lib)nmslib One of the best performance vector retrieval libraries , Yes HNSW The algorithm is optimized , It has faster retrieval speed and higher recall rate , It is also quoted and optimized by most other products .
Github Address :https://github.com/nmslib/hnswlib
advantage
- Fast retrieval .
- High recall rate .
- Support CPU and GPU Pattern .
- Support real-time update .
shortcoming
- It takes a long time to build the index .
- High memory usage .
- Service and cluster deployment are not supported .
- Filtering function is not supported .
2.4 ScaNN
ScaNN (Scalable Nearest Neighbors) yes Google stay 2020 An excellent vector retrieval library opened in , yes google-research Next sub project , It has a very good retrieval performance . Because the open source time is not long , There is very little information that can be searched .
ScaNN The vector search of index is mainly divided into the following three stages :
- Partition ( An optional step ): Partition the data set during training , When querying, select Top Divide the area to score . The partition uses kmeans_tree.
- Scoring : Calculate the distance between the query vector and the data in the whole data set or partition , This distance does not need to be very accurate .
- Re score ( An optional step ): Get from the scoring stage TopK Vector , Then calculate the distance from the query vector more accurately , Get from the calculated vector TopK Vector list .
ScaNN Anisotropic vector quantization technology is used to improve the accuracy of vector retrieval .
Github Address :https://github.com/google-research/google-research/tree/master/scann
advantage
- Fast retrieval .
- High recall rate .
- Support CPU and GPU Pattern .
- Support real-time update .
shortcoming
- There are few learning materials .
- Service and cluster deployment are not supported .
- Filtering function is not supported .
2.5 SPTAG
SPATG (Space Partition Tree And Graph) By Microsoft Research (MSR) and Microsoft Bing Jointly published spatial partition tree and graph index , It mainly adopts the technology of tree and graph to speed up the retrieval , It can support service-oriented and clustered deployment .
SPTAG Two indexes are provided , Here's the picture
- kd-tree And related neighborhood map (SPTAG-KDT), It has more advantages in index construction .
- Balance k-means Trees and related neighborhood graphs (SPTAG-BKT), It has more advantages in the accuracy of high-dimensional data search .
Github Address :https://github.com/microsoft/SPTAG
advantage
- Support service-oriented and clustered deployment .
- Support CPU and GPU Pattern .
- Support real-time update .
shortcoming
- Filtering function is not supported .
- Inner product distance is not supported .
2.6 Vearch
Vearch Jd.com is an open-source elastic distributed system that performs high-performance similarity search on large-scale deep learning vectors .
Github Address :https://github.com/vearch/vearch
file :https://vearch.readthedocs.io/zh_CN/latest/overview.html
Architecture diagram
advantage
- Support service-oriented and clustered deployment .
- Support CPU and GPU Pattern .
shortcoming
- Filtering function is not supported .
- Search is not supported during data insertion and indexing .
- Adding data to... In real time is not supported GPU Indexes , The new data will take effect only after the index is updated .
2.7 Zsearch
Zsearch It's ant gold based on ES More expansion and performance optimization , stay ES Implemented on LSH、IVSPQ、HNSW plug-in unit , The project is not open source .
Architecture diagram
advantage
- be based on K8s base , Quick creation ZSearch Components , Fast operation and maintenance , The faulty machine is replaced automatically ;
- Cross room replication , Important business side high security ;
- Plug in platform , User defined plug-in hot load ;
- SmartSearch Simplify user search , Open the box ;
- Router coordination ES Internal multi tenant plug-in , Improve resource utilization ;
shortcoming
- Not open source .
2.8 Proxima
Proxima It is a general vector search engine framework developed by the internal Dharma Institute of Ali , Be similar to Facebook Open source Faiss, Multiple index types are supported .
Architecture diagram
advantage
- Support a variety of vector retrieval algorithms .
- Unified approach and Architecture , It's easy to use .
- Support heterogeneous computing ,GPU.
shortcoming
- Not open source .
3. summary
This paper mainly compares the excellent products related to the field of vector retrieval 、 Technical comparison and performance comparison , And a brief introduction to each product , And expounds its advantages and disadvantages . Due to the limited knowledge of personal contact , Some excellent products fail to understand , Or some data in the article is wrong , Please also correct me . Later, we will share the detailed introduction of Vector Retrieval Technology 、 test 、 Application and thinking .
4. Reference
- https://milvus.io/cn/
- https://github.com/facebookresearch/faiss
- https://github.com/nmslib/hnswlib.
- https://github.com/google-research/google-research/tree/master/scann
- https://github.com/microsoft/SPTAG
- https://vearch.readthedocs.io/zh_CN/latest/overview.html
- https://git.code.oa.com/elasticfaiss/elasticfaiss
边栏推荐
猜你喜欢
GEO数据挖掘(三)使用DAVID数据库进行GO、KEGG富集分析

The programmer refused the offer because of low salary, HR became angry and netizens exploded

Gold three silver four, don't change jobs
【OFDM通信】基于深度学习的OFDM系统信号检测附matlab代码

app通用功能测试用例
Résumé des connaissances de gradle

Eureka Client启动后就关闭 Unregistering application xxx with eureka with status DOWN
求帮助xampp做sqlilab是一片黑
Wind chime card issuing network source code latest version - commercially available
服务器SMP、NUMA、MPP体系学习笔记。
随机推荐
Designed for decision tree, the National University of Singapore and Tsinghua University jointly proposed a fast and safe federal learning system
STM32 enters and wakes up the stop mode through the serial port
How to find out if the U disk file of the computer reinstallation system is hidden
DAY THREE
Yaduo Sangu IPO
Please help xampp to do sqlilab is a black
openresty ngx_lua子请求
服务器SMP、NUMA、MPP体系学习笔记。
After 3 years of testing bytecan software, I was ruthlessly dismissed in February, trying to wake up my brother who was paddling
What is a responsive object? How to create a responsive object?
PostgreSQL高可用之repmgr(1主2从+1witness)+Pgpool-II实现主从切换+读写分离
[boutique] Pinia Persistence Based on the plug-in Pinia plugin persist
Gold three silver four, don't change jobs
Gradle knowledge generalization
《数字经济全景白皮书》保险数字化篇 重磅发布
Cas d'essai fonctionnel universel de l'application
【精品】pinia 基于插件pinia-plugin-persist的 持久化
(leetcode) sum of two numbers
Server SMP, NUMA, MPP system learning notes.
陀螺仪的工作原理