当前位置:网站首页>The Chinese word segmentation task is realized by using traditional methods (n-gram, HMM, etc.), neural network methods (CNN, LSTM, etc.) and pre training methods (Bert, etc.)
The Chinese word segmentation task is realized by using traditional methods (n-gram, HMM, etc.), neural network methods (CNN, LSTM, etc.) and pre training methods (Bert, etc.)
2022-07-02 06:14:00 【JackHCC】
Natural language processing Chinese word segmentation
Using traditional methods (N-gram,HMM etc. )、 Neural network method (CNN,LSTM etc. ) And pre training methods (Bert etc. ) Chinese word segmentation task implementation 【The word segmentation task is realized by using traditional methods (n-gram, HMM, etc.), neural network methods (CNN, LSTM, etc.) and pre training methods (Bert, etc.)】
Project address :https://github.com/JackHCC/Chinese-Tokenization
Methods an overview
- Traditional algorithms : Use N-gram,HMM, Maximum entropy ,CRF Wait to realize Chinese word segmentation
- nerve ⽹ Collateral ⽅ Law :CNN、Bi-LSTM、Transformer etc.
- Pre training language ⾔ Model ⽅ Law :Bert etc.
Data set Overview
- PKU And MSR yes SIGHAN On 2005 Organized in ⽂ participle ⽐ " the ⽤ Data set of , It is also an academic test of word segmentation ⼯ Standard data set with .
Experimental process
traditional method :
Neural network method
Pre training model method
experimental result
PKU Data sets
| Model | Accuracy rate | Recall rate | F1 fraction |
|---|---|---|---|
| Uni-Gram | 0.8550 | 0.9342 | 0.8928 |
| Uni-Gram+ The rules | 0.9111 | 0.9496 | 0.9300 |
| HMM | 0.7936 | 0.8090 | 0.8012 |
| CRF | 0.9409 | 0.9396 | 0.9400 |
| Bi-LSTM | 0.9248 | 0.9236 | 0.9240 |
| Bi-LSTM+CRF | 0.9366 | 0.9354 | 0.9358 |
| BERT | 0.9712 | 0.9635 | 0.9673 |
| BERT-CRF | 0.9705 | 0.9619 | 0.9662 |
| jieba | 0.8559 | 0.7896 | 0.8214 |
| pkuseg | 0.9512 | 0.9224 | 0.9366 |
| THULAC | 0.9287 | 0.9295 | 0.9291 |
MSR Data sets
| Model | Accuracy rate | Recall rate | F1 fraction |
|---|---|---|---|
| Uni-Gram | 0.9119 | 0.9633 | 0.9369 |
| Uni-Gram+ The rules | 0.9129 | 0.9634 | 0.9375 |
| HMM | 0.7786 | 0.8189 | 0.7983 |
| CRF | 0.9675 | 0.9676 | 0.9675 |
| Bi-LSTM | 0.9624 | 0.9625 | 0.9624 |
| Bi-LSTM+CRF | 0.9631 | 0.9632 | 0.9632 |
| BERT | 0.9841 | 0.9817 | 0.9829 |
| BERT-CRF | 0.9805 | 0.9787 | 0.9796 |
| jieba | 0.8204 | 0.8145 | 0.8174 |
| pkuseg | 0.8701 | 0.8894 | 0.8796 |
| THULAC | 0.8428 | 0.8880 | 0.8648 |
边栏推荐
- Page printing plug-in print js
- Let every developer use machine learning technology
- LeetCode 27. 移除元素
- ZABBIX server trap command injection vulnerability (cve-2017-2824)
- Detailed notes of ES6
- 官方零基础入门 Jetpack Compose 的中文课程来啦!
- Current situation analysis of Devops and noops
- LeetCode 283. 移动零
- Redis Key-Value数据库【初级】
- Community theory | kotlin flow's principle and design philosophy
猜你喜欢
来自读者们的 I/O 观后感|有奖征集获奖名单

The difference between session and cookies

经典文献阅读之--Deformable DETR
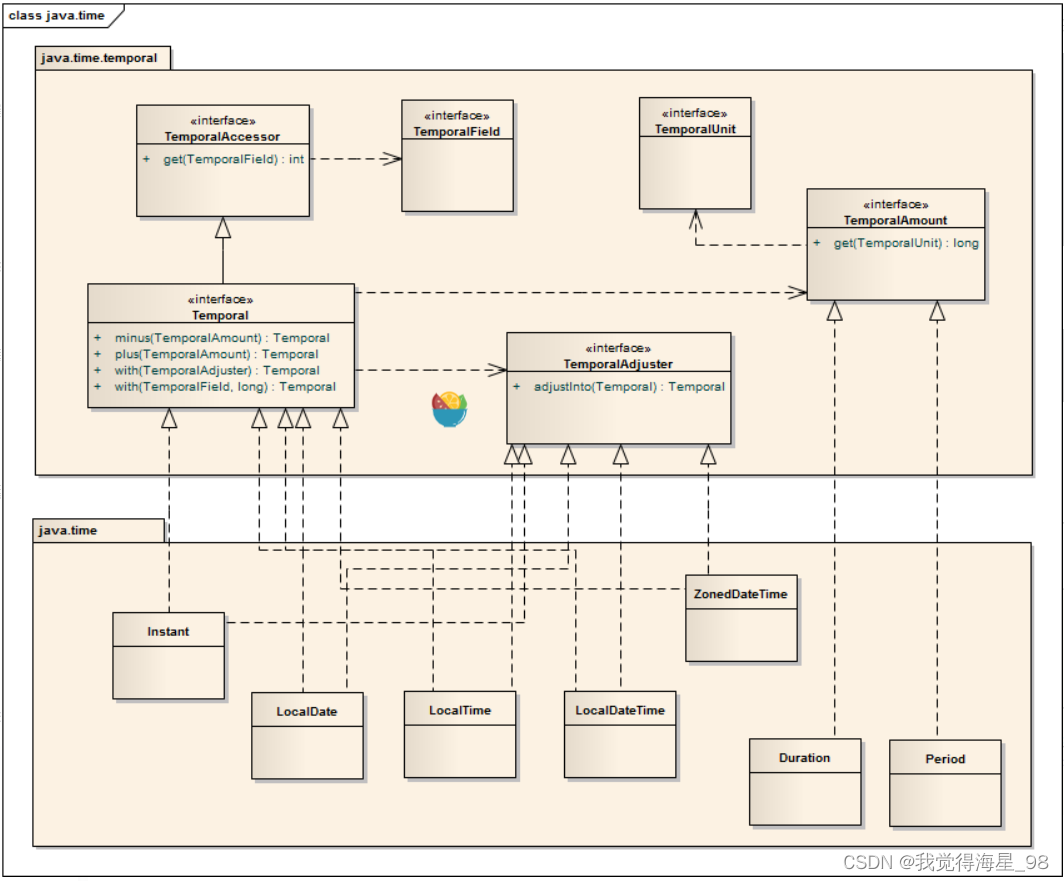
日期时间API详解
Zhuanzhuanben - LAN construction - Notes
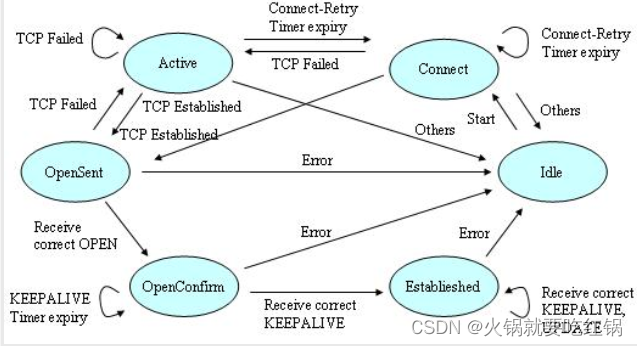
State machine in BGP

Flutter hybrid development: develop a simple quick start framework | developers say · dtalk
深入学习JVM底层(三):垃圾回收器与内存分配策略

Lucene Basics
Reading classic literature -- Suma++
随机推荐
Flutter 混合开发: 开发一个简单的快速启动框架 | 开发者说·DTalk
深入了解JUC并发(二)并发理论
复杂 json数据 js前台解析 详细步骤《案例:一》
Contest3145 - the 37th game of 2021 freshman individual training match_ H: Eat fish
WLAN相关知识点总结
LeetCode 90. Subset II
Redis key value database [seckill]
社区说|Kotlin Flow 的原理与设计哲学
神机百炼3.54-染色法判定二分图
Deep learning classification network -- Network in network
锐捷EBGP 配置案例
Reading classic literature -- Suma++
ES6的详细注解
Little bear sect manual query and ADC in-depth study
递归(迷宫问题、8皇后问题)
LeetCode 83. 删除排序链表中的重复元素
I/o impressions from readers | prize collection winners list
Redis Key-Value数据库【初级】
Database learning summary 5
Introduce uview into uni app