当前位置:网站首页>Master-slave mode of redis cluster
Master-slave mode of redis cluster
2022-07-05 12:18:00 【Xujunsheng】
Redis Master-slave mode of cluster
- How to ensure Redis The reliability of the
- Redis A master-slave mode
- Why should we use the method of separation of reading and writing ?
- How to synchronize between master and slave libraries for the first time ?
- 「 Master slave cascade mode 」 Share the main reservoir pressure during full replication
- What to do when the network between master and slave databases is broken ?
- replication_buffer And replication_backlog_buffer
How to ensure Redis The reliability of the
We are in the front Article to read Redis Persistence mechanism Analysis of , If the server goes down , You can re read RDB File or playback AOF Log data recovery , So as to ensure as little data loss as possible , Improve reliability .
Here is another simple comparison between the two persistence :
- AOF What's recorded is every write command , The most comprehensive data , But the file is big , Data recovery is slow .
- RDB use 「 Binary system + data compression 」 Write to disk in , So the file size is small , Data recovery is also fast . however RDB The problem is , The frequency of snapshot execution is difficult to control . Too fast frequency will affect the performance of the system , Too slow frequency will cause more data loss .
Redis 4.0 The above version is supported Mix persistence , Combining the advantages of the two :
- RDB With 「 Binary system + data compression 」 Way to store , Small file size ;
- AOF Record every write command , The most comprehensive data .
After such optimization , Improve the efficiency of data recovery , When an outage occurs , We can use persistent files to recover quickly Redis Data in .
Although we have optimized the efficiency of persistence to the maximum , But data recovery still takes time , During this period, business applications will still be affected , What to do ?
So that's the point Redis Of high reliability Problem. .
Redis The high reliability of requires two guarantees :
- Data loss as little as possible
- Service interruption as little as possible
Persistence can only guarantee the former , And for the latter , The usual way is 「 Add copy redundancy 」. By deploying multiple Redis example , Then keep the instance data synchronized in real time , So when an instance goes down , Let's just choose one of the remaining examples to continue to provide services .
This plan is Redis Master slave library mode . Next let's analyze Redis Of 「 Master slave copy : Multiple copies 」.
Redis A master-slave mode
Redis The master-slave library mode is provided , To ensure the consistency of data copies , The master and slave libraries are 「 Read / write separation 」 The way .
- Read operations : Main library 、 It can be received from the library ;
- Write operations : First, go to the main library to execute , then , The master synchronizes the write operations to the slave .
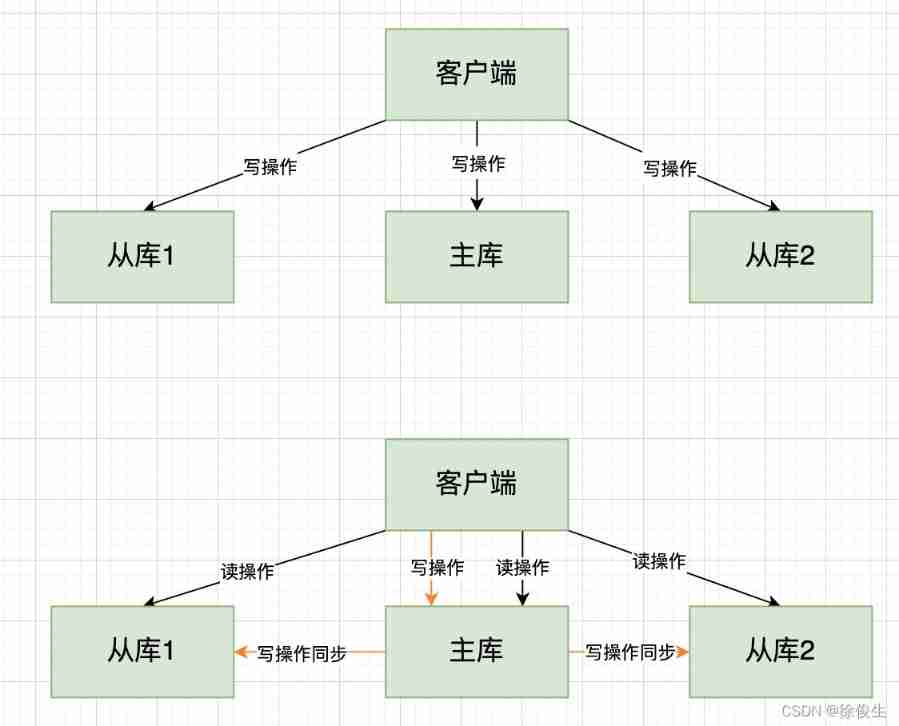
Why should we use the method of separation of reading and writing ?
If the slave library can also be like the master library , If you can receive a write request , A direct problem is 「 Data inconsistency 」.
For example, the client has the same key It has been revised three times in a row , These three requests are sent to three different instances . that , The copies of this data on the three instances are inconsistent ( Namely v1、v2 and v3). Later, when reading this data , It is possible to read the old value .
If you want to keep this data consistent on the three instances , It's about locking 、 A series of operations such as whether to complete modification are negotiated among instances , But it's going to cost a lot , Obviously, it is not acceptable .
use 「 Read / write separation 」, All data changes will only be made on the main database , There's no need to coordinate three instances . After the main database has the latest data , It will be synchronized to the slave library , such , The data of master-slave database is consistent .
Before analyzing master-slave synchronization , We need to figure out three things :
- How is master-slave synchronization accomplished ?
- The master database data is transferred to the slave database at one time , Or batch synchronization ?
- The network between master and slave databases is disconnected , Is the data still consistent ?
Next , First, let's analyze how the first synchronization between master and slave libraries is carried out ? This is also Redis The specified action after the instance establishes the master-slave mode .
How to synchronize between master and slave libraries for the first time ?
From node configuration
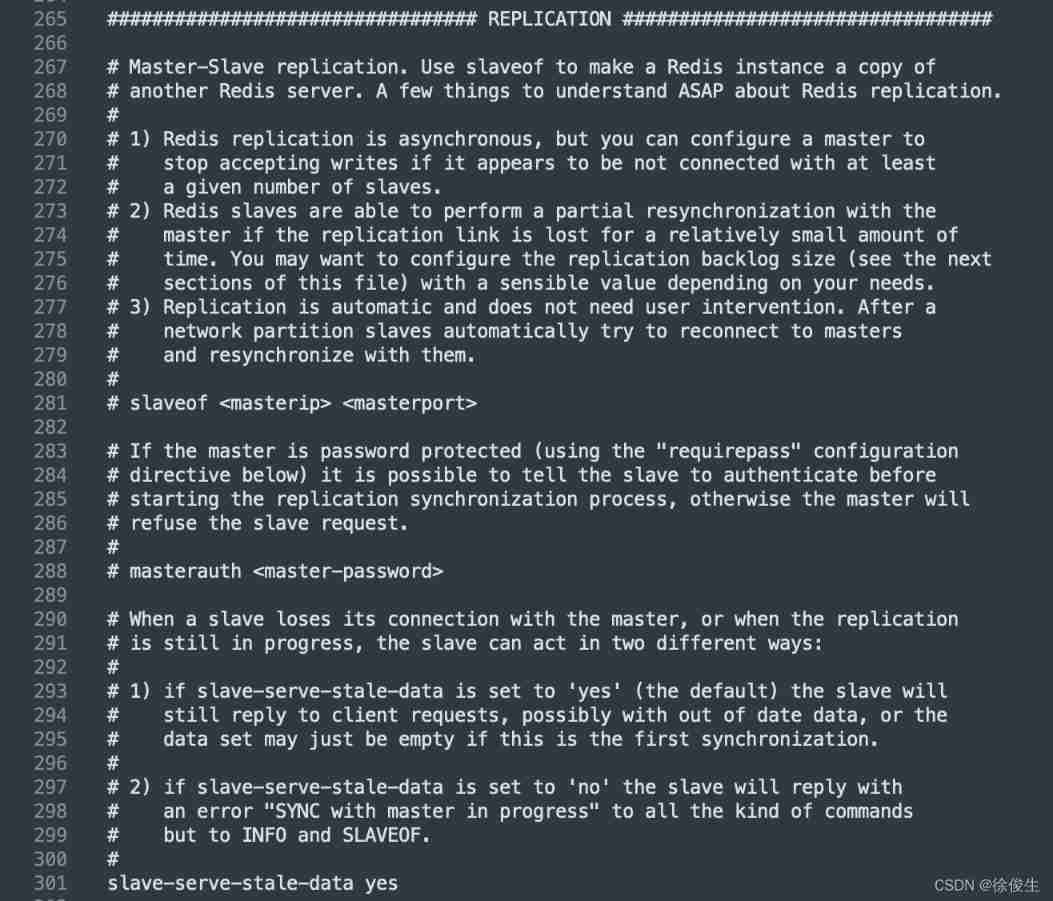
Start the machine with the default configuration , All machines are master nodes . If you want to make the machine become a slave node , Need to be in conf file Configure the relevant parameters of master-slave replication .
# Configure the ip And port
slaveof 192.168.1.1 6379
# from redis2.6 Start , The slave node is read-only by default
slave-read-only yes
# Suppose the master node has a login password , yes 123456
masterauth 123456
The first synchronization of data between master and slave databases includes three stages , Let's analyze it .
The first stage
The first stage is to establish a connection between the master and slave libraries 、 The process of negotiating synchronization , Mainly to prepare for full replication .
Command format :
PSYNC <runid> <offset>
say concretely , Send from the slave to the master psync command , Indicates that you want to synchronize data , The master database starts replication based on the parameters of this command . psync The command contains the runID And replication progress offset Two parameters .
psyncyes Redis 2.8 The command provided by version , For resolutionsync「 Duplicate after disconnection 」 The problem of inefficiency of .
- runID: Is each Redis When the instance is started, it will automatically generate a random ID, Used to uniquely mark this instance . When the slave and master are copied for the first time , Because I don't know about the main database runID, So will runID Set to “?”.
- offset: Copy offset , This is set to -1, For the first time .
PSYNC ? -1It means full replication .
Master library received psync After the command , Will use FULLRESYNC The response command takes two parameters :「 Main library runID」 And the current 「 Replication progress offset」, Back to the slave Library . After receiving a response from the library , These two parameters will be recorded , In the next send psync Use .
It should be noted that ,
FULLRESYNCResponse representation 「 The first replication adopts full replication 」, in other words , The master database will copy all the current data to the slave database .
If the primary server returns+CONTINUEIt means that 「 Partial synchronization 」.
The second stage
In the second phase , The master database synchronizes all data to the slave database . After receiving data from the library , Load data locally .
The specific steps are as follows :
- After the master database receives the complete resynchronization request , It will be performed in the background
bgsavecommand , Generate RDB file , And use a 「 buffer :replication buffer」 Record 「 From now on, all write commands 」. - When
bgsaveOrder executed , The main service will RDB The file is sent to the slave library . Received... From library RDB After the document , The current database will be emptied first , Then load RDB file .
Why should there be an empty action ?
This is because the slave library is passing throughslaveofBefore the command starts to synchronize with the main library , There may be other data stored . To avoid the impact of previous data , You need to clear the current database from the database .
In the process of synchronizing data from the master database to the slave database , The main library will not be blocked , Still can receive requests normally . otherwise ,Redis The service was interrupted . however , The write operations in these requests are not recorded in the newly generated RDB In file . In order to ensure the data consistency of master-slave database , The main library will use special replication buffer ( Copy buffer ), Record RDB All writes received after file generation .
The third stage
Last , That's the third stage , The main database will send the newly received write commands during the second stage execution , And send it to the slave library .
The specific operation is , When the master library is finished RDB After the file is sent , It will put this time replication buffer The modification operation in is sent to the slave library , Redo these operations from the library . thus , The master and slave libraries are synchronized .
PSYN2.0
PSYN2.0 yes Redis 4.0 Of One of the new features . Compare with the original PSYN function , The biggest change is to support partial resynchronization in two scenarios .
- slave The node is promoted to master After node , other slave Nodes can be upgraded master Perform partial resynchronization ;
- Another scenario is slave After restart , Partial resynchronization is possible .
「 Master slave cascade mode 」 Share the main reservoir pressure during full replication
Through the analysis above 「 The first data synchronization between master and slave databases 」 The process of , You can see , One full copy , There are two time-consuming operations for the main library :
- Generate RDB file ;
- transmission RDB file .
If the number of slave libraries is large , And all of them have to be fully replicated with the main database , It will lead to two problems :
- The main library is busy fork Child process generation RDB file , Full data synchronization ,fork This operation blocks the main thread from processing normal requests , As a result, the main library is slow to respond to the application's request .
- Generate RDB file It takes a lot of time for the main server CPU, Memory and disk I/O resources . transmission RDB Files also take up the network bandwidth of the main library , It also affects the response time of the master server to the command request .
that , Is there a good solution to share the pressure of the main reservoir ?
There is , This is it. 「“ Lord - from - from ” Pattern 」.
" Lord - from - from " Pattern
The master-slave library mode introduced above , Yes, all slave databases are connected to the master database , All full replication is done with the master database .
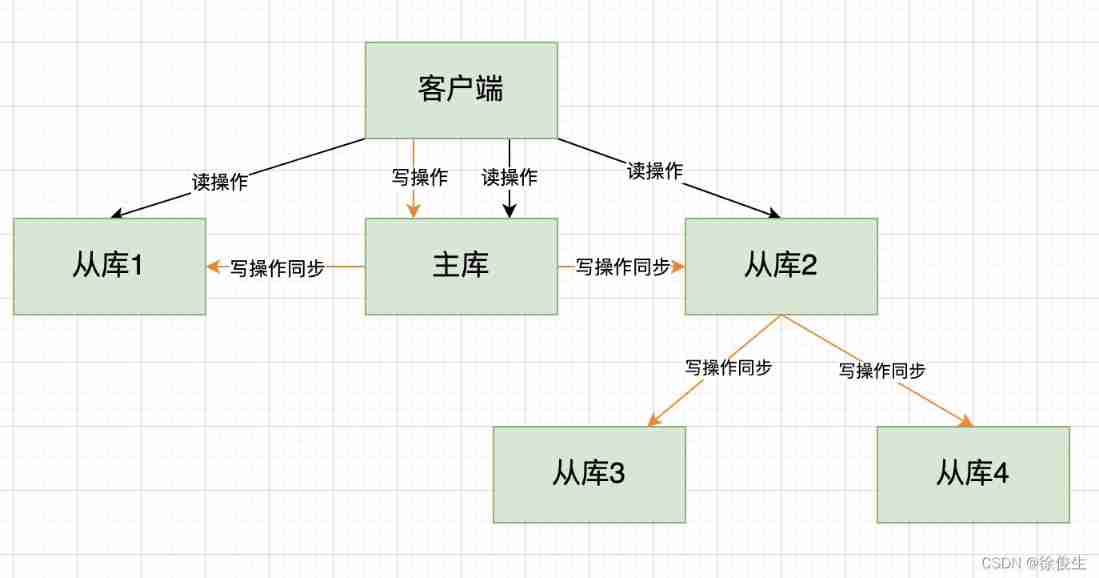
Now? , We can go through 「“ Lord - from - from ” Pattern 」 Build the main library into RDB And transmission RDB The pressure of the , In a cascading way, it is distributed to the slave libraries .
Simply speaking , When we deploy the master-slave cluster , You can manually select a slave Library ( For example, select the slave library with high memory resource configuration ), Used to cascade other slaves . then , We can choose some more from the library ( For example, one third of the slaves ), Execute the following commands on these slave Libraries , Let them and the selected slave Library , Establish a master-slave relationship .
salveof Selected from the library IP 6379
thus , These will be known from the library , During synchronization , No more interaction with the main library , Just synchronize the write operation with the cascaded slave library , This will relieve the pressure on the main reservoir , As shown in the figure below :
Okay , Come here , We analyzed the passage between master and slave databases 「 Copy in full 」 The process of data synchronization , And by 「“ Lord - from - from ” Pattern 」 The way to share the pressure of the main reservoir . that , Once the master-slave database has completed full replication , They will always maintain a network connection between them , Through this connection, the master database will synchronize the subsequent command operations received successively to the slave database , This process is also known as command propagation based on long connections , It can avoid the overhead of frequent connection establishment .
It sounds simple , But it can not be ignored , There are risks in this process , The most common is network disconnection or blocking . If the network is disconnected , There is no command propagation between master and slave libraries , Naturally, the data in the slave database can't be consistent with that in the master database , The client may read the old data from the library .
Next , Let's talk about the solution after the network is disconnected .
What to do when the network between master and slave databases is broken ?
stay Redis 2.8 Before , The master-slave library uses sync Command to synchronize . If the network flickers when the command is transmitted , that , The slave database will make a full copy with the master database again , It's very expensive .
We mentioned the impact of full replication on the previous page :
- Generate RDB file : It takes a lot of time for the main server CPU, Memory and disk I/O resources ;
- transmission RDB file : Occupy the network bandwidth of the main library , It also affects the response time of the master server to the command request .
from Redis 2.8 Start , After the Internet was disconnected , The master-slave library will use 「 Incremental replication 」 Keep syncing in the same way . You can guess from the name that it's different from full copy : Full replication is to synchronize all data , and Incremental replication will only the commands received by the master database during the disconnection of the master-slave database network , Synchronize to slave database .
that , Incremental replication , How to keep synchronization between master and slave databases ? The answer to this question and repl_backlog_buffer ( Copy backlog buffer ) of .
Copy backlog buffer : It is a fixed length queue maintained by the main database , The default size is 1MB.
Let's first analyze the incremental synchronization process of master-slave libraries .
1)、 When the master-slave database synchronizes data , The main library will put RDB New operation command writing received during communication replication buffer, At the same time, these operation commands will also be written repl_backlog_buffer This buffer .
repl_backlog_buffer It's a ring buffer , The main database will record where it writes , From the library, you will record the position you have read .
2)、 At the beginning , The write and read positions of the master and slave libraries are together , That is to say 「 Copy offset 」 identical , This is where they start . As the master library continues to receive new writes , Its write position in the buffer will gradually deviate from the starting position , We usually use offset to measure the offset distance , For the main library , The corresponding offset is master_repl_offset. The more new writes received by the master database , The larger the value is .
Again , After copying the write command from the library , Its read position in the buffer also begins to shift gradually from the starting position , here , Offset copied from library slave_repl_offset It's also increasing . Under normal circumstances , These two offsets are basically equal .
3)、 In case of disconnection from the Library , After restart , The connection between master and slave libraries is restored , The slave will first send to the master psync command , And put your current slave_repl_offset Send to master library , The master library will judge its own master_repl_offset and slave_repl_offset The gap between . If found in slave_repl_offset The subsequent data still exists in the replication backlog buffer , Master database send +CONTINUE reply , Indicates incremental replication .
As shown in the figure below :

Here is a place to focus on .
because repl_backlog_buffer It's a ring buffer , So after the buffer is full , The main library will continue to write , here , It will override the previous write operations . If the reading speed from the library is slow , It is possible that the operations not read from the slave database will be covered by the new operations written by the master database , This will prevent incremental replication , Full replication must be used .
So find a way to avoid this situation , generally speaking , We can adjust the configuration file repl-backlog-size This parameter .
How to avoid incremental replication failure
Redis The default size set for the replication backlog buffer is 1MB. If the main library needs to execute a large number of write commands , Or it takes a long time to reconnect after disconnection , This size is obviously inappropriate .
We can use : second * write_size_per_second Formula to estimate the buffer 「 Minimum 」 size .
- second : The average time required to reconnect to the main library after disconnection from the Library , Company : second ;
- write_size_per_second: The average amount of write command data generated by the main library per second .
We are in practical application , Considering that there may be some unexpected request pressure , We usually need to double that buffer space , namely repl-backlog-size = second * write_size_per_second * 2.
for instance , If the main database generates 1 MB Of writing data , On average, it takes 5 Seconds to reconnect to the main database . This requires at least 5 MB The buffer space of . otherwise , The new command will override the old operation . In order to deal with possible sudden pressure , We finally put repl-backlog-size Set to 10 MB.
thus , Incremental replication reduces the risk of data inconsistency between master and slave databases . however , If the number of concurrent requests is very large , If you can't store twice the buffer space for new operation requests , here , Master slave database data may still be inconsistent .
In this case , One side , According to Redis The memory resources of the server are properly increased repl-backlog-size value , For example, it is set to the size of buffer space 4 times , On the other hand , Consider using Cluster slicing To share the request pressure of a single master database .
replication_buffer And replication_backlog_buffer
replication_buffer
For clients or from libraries with Redis signal communication ,Redis Will allocate a memory buffer Data interaction . All data interaction is through this buffer On going .Redis First write the data into this buffer in , Then take it. buffer The data in is sent to client socket And then send it through the network , This completes the data interaction .
So the master-slave in incremental synchronization , Slave library as one client, You'll also be assigned a buffer, It's just this buffer Specifically used to propagate user write commands to slave libraries , Make sure the master and slave data are consistent . We usually call it Replication Buffer.
Redis adopt client-output-buffer-limit Set this parameter buffer Size . The master database creates a client for each slave , therefore replication buffer Not shared , Instead, each slave library has a corresponding client .
If the master and slave propagate commands , For some reason, processing from the library is very slow , So this one on the main library buffer It will continue to grow , A lot of memory , even to the extent that OOM.
therefore Redis Provides client-output-buffer-limit Parameters limit this buffer Size , If you exceed the limit , The master database will force this to be disconnected client The connection of ,
In other words, slow processing of slave database results in main database memory buffer When the backlog reaches the limit , The master library will forcibly disconnect the slave library ,
At this point, the master-slave replication will be interrupted , If the replication request is initiated again from the library after the interruption , Then this may lead to a vicious circle , Trigger a replication storm , This situation requires special attention .
replication_backlog_buffer
and replication_buffer Dissimilarity ,repl_backlog_buffer It is shared by all slave libraries ,slave_repl_offset Recorded by the slave library itself , This is also because the replication progress of each slave library is not necessarily the same . When disconnected from the library and then restored , Will send... To the main library psync command , And put your current slave_repl_offset Send to master library .slave_repl_offset The data pointed to is not overwritten , Can continue to recover . If you disconnect from the library for too long ,repl_backlog_buffer The ring buffer will be overwritten by the write command of the main library , After reconnecting from the database, you can only synchronize in full .
Okay , We have analyzed the problem of master-slave replication here . If you want to see more quality original articles , Welcome to my official account. 「ShawnBlog」.
边栏推荐
- Matlab struct function (structure array)
- Network five whip
- Xi IO flow
- Error modulenotfounderror: no module named 'cv2 aruco‘
- Reinforcement learning - learning notes 3 | strategic learning
- Is investment and finance suitable for girls? What financial products can girls buy?
- Principle of persistence mechanism of redis
- 信息服务器怎么恢复,服务器数据恢复怎么弄[通俗易懂]
- 投资理财适合女生吗?女生可以买哪些理财产品?
- byte2String、string2Byte
猜你喜欢
Simply solve the problem that the node in the redis cluster cannot read data (error) moved
Take you two minutes to quickly master the route and navigation of flutter

Pytorch weight decay and dropout
调查显示传统数据安全工具在60%情况下无法抵御勒索软件攻击
HiEngine:可媲美本地的云原生内存数据库引擎

The most comprehensive new database in the whole network, multidimensional table platform inventory note, flowus, airtable, seatable, Vig table Vika, flying Book Multidimensional table, heipayun, Zhix

报错ModuleNotFoundError: No module named ‘cv2.aruco‘

Seven ways to achieve vertical centering

Thoughts and suggestions on the construction of intelligent management and control system platform for safe production in petrochemical enterprises

7月华清学习-1


随机推荐
【ijkplayer】when i compile file “compile-ffmpeg.sh“ ,it show error “No such file or directory“.
跨平台(32bit和64bit)的 printf 格式符 %lld 输出64位的解决方式
1 plug-in to handle advertisements in web pages
报错ModuleNotFoundError: No module named ‘cv2.aruco‘
Differences between IPv6 and IPv4 three departments including the office of network information technology promote IPv6 scale deployment
Learn the memory management of JVM 02 - memory allocation of JVM
Multi table operation - Auto Association query
嵌入式软件架构设计-消息交互
[untitled]
Wireless WiFi learning 8-channel transmitting remote control module
PXE启动配置及原理
Get all stock data of big a
Sentinel sentinel mechanism of master automatic election in redis master-slave
Flutter2 heavy release supports web and desktop applications
多表操作-自关联查询
byte2String、string2Byte
[cloud native | kubernetes] actual battle of ingress case (13)
Multi table operation - sub query
Recyclerview paging slide
查看rancher中debug端口信息,并做IDEA Remote Jvm Debug