当前位置:网站首页>Teacher lihongyi, NTU -- tips for DNN regulation
Teacher lihongyi, NTU -- tips for DNN regulation
2022-06-11 22:53:00 【Learning uncle】
List of articles
Recipe of Deep Learning

stay Deep learning in , We must have seen training data Is your performance good , Then look at testing data The above performance . If in training data It's not good , First adjust the model to achieve good performance .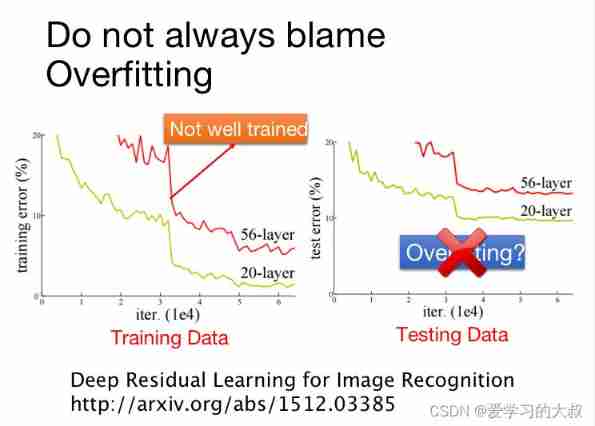
So we don't want to see 20-layer Than 50-layer stay testing Perform well , Just say 50-layer Over fitting , First, go and see what they are doing testing data Result . It can be seen from the results ,20-layer stay training data Have more than 50-layer Okay , There are many possible reasons , such as 50-layer Of local minimum Point to 20 The height of .
So not all the methods we can use , For example, when traning data When the effect of , You can't use dropout. Just say training data We did a good job , however testing data When you're not doing well , Just can use .
 # Vanishing Problem
# Vanishing Problem
stay MINIST In the project , Why the more layers , The lower the accuracy ?
Because the activation function uses sigmoid function ,sigmoid Function because it maps large values to 0-1 Within the range of , So the more layers , Right back output The smaller the impact of the output , It leads to more and more training , The front has changed a lot , It's hard to change later , Close to convergence .
ReLU


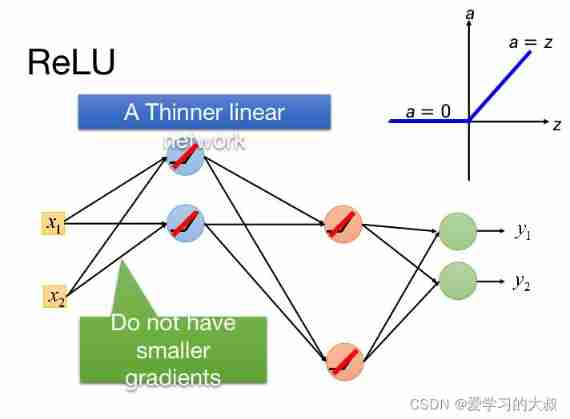
because ReLU Characteristics of , A linear network that makes the network very thin , But this can still solve the problem of non-linear , Because it is multi-layered .( I understand )
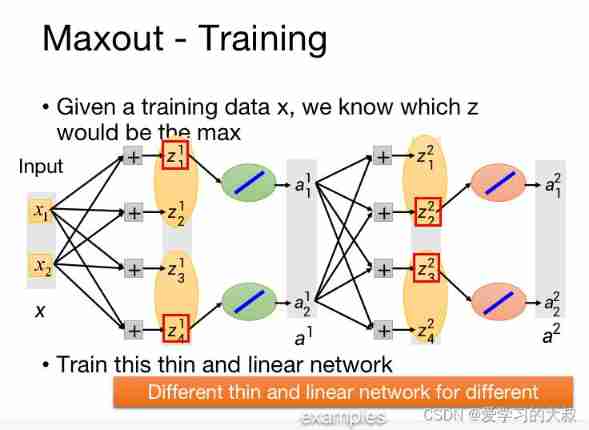
Maxout

Maxout Network amount to Max Pooling Application in neural network .


because Maxout Some neurons will disappear , But every time traning data The difference that disappears , As a result, the length of each activation function is different . Is a learnable activation function .
Adagrad & RMSprop



Local Minimum

Yan Lecun stay 07 Year said , If every dimension has a bottom , that 1000 individual features Namely 1000 A valley bottom , At every bottom p. So that is p**1000. So don't worry about a lot local minimum, Most likely what you find is global Or close to global.
Adam

Early Stopping

there testing set In fact, that is validation set
Regularization

We do regularization When , Don't consider bias, Because our main purpose of regularization is to make the function smoother ,bias Generally no matter smooth , Instead, the function moves up and down .
L2 norm The formula of , We can see w Will multiply by a factor close to 1 Value , therefore w Whether positive or negative , Will continue to approach 0. And because the gradient is subtracted , So this value will keep approaching the following value .L2 In fact, the effect of regularization in neural networks is not SVM good , It's equivalent to a weight decay.
L1 norm It's the absolute value , The derivation of the absolute value is used here sgn, If it's a positive number , The derivative is 1, If it's a negative number , The derivative is -1.
from L1 We can see that , It always ends up subtracting a fixed value ( Blue line section ). and L2 Always by multiplying by one 1 To attenuate .
So if we have a big w, such as w=1000000. This w stay L1 The decrease of is a fixed value every time , So it's slow , Maybe it will be big in the end . But in L2 above , It will drop quickly , Because it's a constant multiplication . So that's why L1 Regularization of , It makes the parameters sparse , yes , we have w It's big , Some tend to 0. and L2 Regularization does not achieve this effect .
Weight Decay

Dropout

Each time for a different mini batch, neural network drop Of neuron Is different .

Testing When , Using all the neurons . And all of w Ducheng 1-p.
Intuitive explain :


Explanation of principle :
Dropout Like the ultimate ensemble. Integrated learning .

every time dropout The neural networks are different . But in the end testing When , Will use all the neurons , This is the time w Need to take 1-p
Integrated y The average and y Is approximately equal .
For example, we use linear activation function , You can see these two situations y They are equal. . If not linear activation , The final result is approximate .
边栏推荐
- Learn to crawl for a month and earn 6000 a month? Don't be fooled. The teacher told you the truth about the reptile
- 点云读写(二):读写txt点云(空格分隔 | 逗号分隔)
- [matlab] second order saving response
- 【Uniapp 原生插件】商米钱箱插件
- The second bullet of in-depth dialogue with the container service ack distribution: how to build a hybrid cloud unified network plane with the help of hybridnet
- leetcode 257. Binary Tree Paths 二叉树的所有路径(简单)
- If I take the college entrance examination again, I will study mathematics well!
- 习题8-5 使用函数实现字符串部分复制 (20 分)
- 【Day8 文献泛读】Space and Time in the Child‘s Mind: Evidence for a Cross-Dimensional Asymmetry
- volatile的解构| 社区征文
猜你喜欢

Games-101 Yan Lingqi 5-6 lecture on raster processing (notes sorting)

华为云、OBS、
![Tensorflow [actual Google deep learning framework] uses HDF5 to process large data sets with tflearn](/img/d0/586b9f09dc19d5aaf8ccca687b7b10.jpg)
Tensorflow [actual Google deep learning framework] uses HDF5 to process large data sets with tflearn

The key to the safe was inserted into the door, and the college students stole the mobile phone numbers of 1.1 billion users of Taobao alone

Only three steps are needed to learn how to use low code thingjs to connect with Sen data Dix data

【Day10 文献泛读】Temporal Cognition Can Affect Spatial Cognition More Than Vice Versa: The Effect of ...
想做钢铁侠?听说很多大佬都是用它入门的

Fastapi 5 - common requests and use of postman and curl (parameters, x-www-form-urlencoded, raw)

How to do investment analysis in the real estate industry? This article tells you

Why can't Google search page infinite?
随机推荐
IEEE-754 floating point converter
Exercise 9-6 statistics of student scores by grade (20 points)
Brief introduction to integrity
向线程池提交任务
Lekao.com: what is the difference between Level 3 health managers and level 2 health managers?
Svn deploys servers and cleints locally and uses alicloud disks for automatic backup
Jsonparseexception: unrecognized token 'username': was expecting error when submitting login data
习题6-2 使用函数求特殊a串数列和 (20 分)
电脑强制关机 oracle登录不上
Matlab point cloud processing (XXV): point cloud generation DEM (pc2dem)
[JS] 1347- high level usage of localstorage
【Day10 文献泛读】Temporal Cognition Can Affect Spatial Cognition More Than Vice Versa: The Effect of ...
Exercise 9-5 address book sorting (20 points)
习题9-1 时间换算 (15 分)
Games-101 Yan Lingqi 5-6 lecture on raster processing (notes sorting)
Huawei equipment configuration hovpn
How to do investment analysis in the real estate industry? This article tells you
[solution] solution to asymmetric and abnormal transformation caused by modifying the transform information of sub objects
What is deadlock? (explain the deadlock to everyone and know what it is, why it is used and how to use it)
SecurityContextHolder. getContext(). getAuthentication(). Getprincipal() gets username instead of userdetails