当前位置:网站首页>B 站弹幕 protobuf 协议还原分析
B 站弹幕 protobuf 协议还原分析
2022-07-06 15:42:00 【VIP_CQCRE】
这是「进击的Coder」的第 657 篇技术分享
作者:TheWeiJun
来源:逆向与爬虫的故事
“
阅读本文大概需要 3 分钟。
”目录
一、什么是protobuf?
二、网站调试分析
三、protobuf协议还原
四、完整代码实现
五、心得分享及总结
趣味模块
小红是一名数据分析工程师,自从上次小红解决了字体反爬的问题后,小红还未遇到过有难度的问题。但是天有不测风云,今天小红在分析弹幕君的时候,遇到了新的问题。数据乱码无规律,据说是protobuf,那么今天我们去分析下小红同学遇到的新问题吧!
一、什么是protobuf协议?
前言:Protobuf (Protocol Buffers) 是谷歌开发的一款无关平台,无关语言,可扩展,轻量级高效的序列化结构的数据格式,用于将自定义数据结构序列化成字节流,和将字节流反序列化为数据结构。所以很适合做数据存储和为不同语言,不同应用之间互相通信的数据交换格式,只要实现相同的协议格式,即后缀为proto文件被编译成不同的语言版本,加入各自的项目中,这样不同的语言可以解析其它语言通过Protobuf序列化的数据。目前官方提供c++,java,go等语言支持。
二、网站调试分析
1、首先打开我们本次分析的网站,搜索指定弹幕内容,截图如下所示:
说明:由于弹幕内容使用了protobuf协议,所以无法直接搜索定位,我们需要分析数据包请求,去定位具体的url链接。
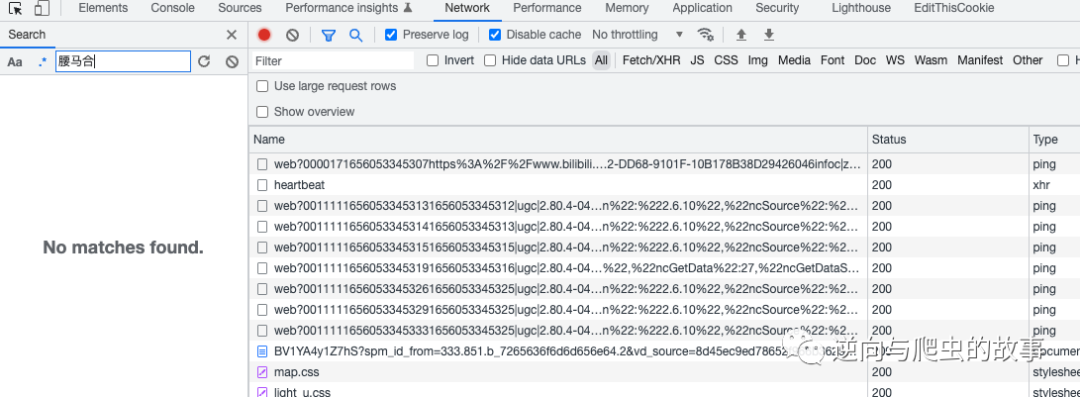
2、分析数据包请求,定位到弹幕链接,截图如下所示:
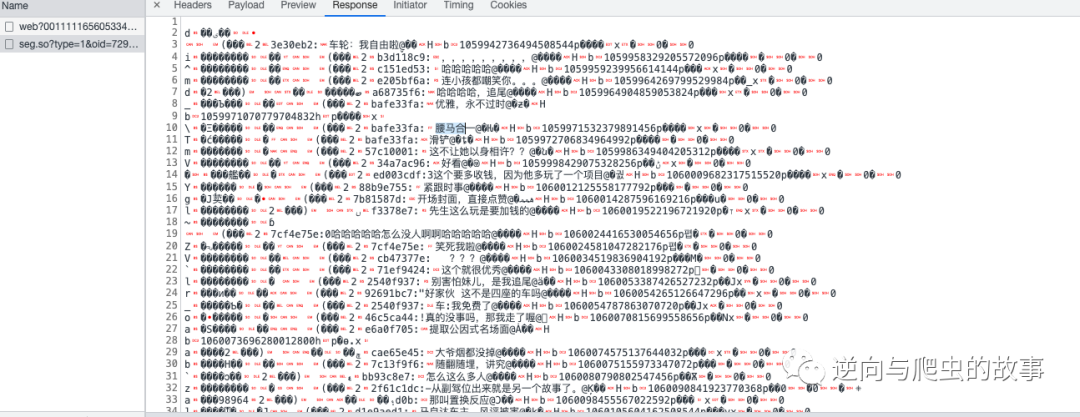
说明:从截图中我们可以清楚看出,这就是弹幕的内容。但是毕竟使用了protobuf协议编码,我们如果想还原出明文信息,接下来需要去进行JS断点调试分析了。
3、使用xhr/fetch对该请求打断点调试,截图如下所示:
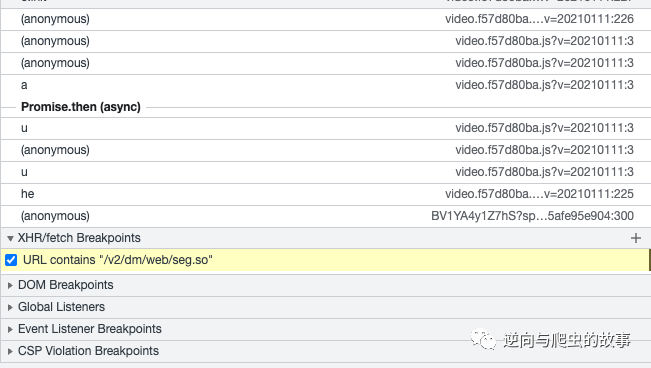
说明:因为该请求是对response进行了protobuf协议编码,所以我们在定位到该请求发包位置后,只需要关注后面的解码逻辑即可。
4、执行断点操作按钮后,截图如下所示:
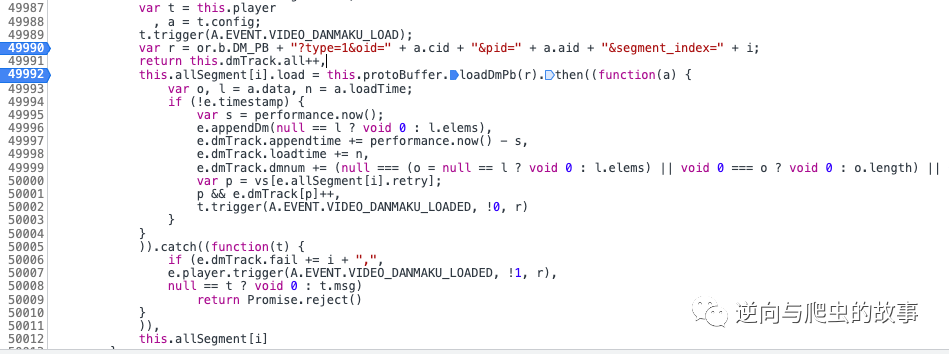
说明:此刻r变量即为我们要访问的弹幕url地址;接下来继续执行断点。
5、继续执行断点,持续更近,截图如下所示:
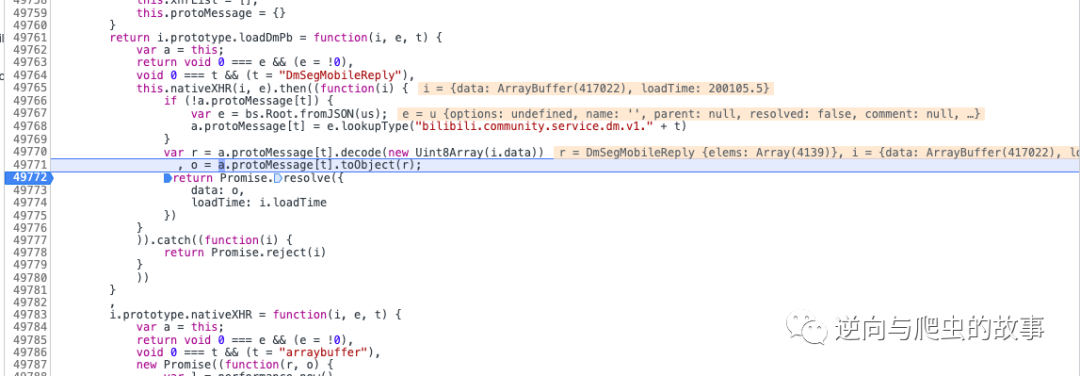
此刻我们打印变量r的值,截图如下所示:

说明:这不就是我们想要的明文信息么?接下来,我们只需要找到protobuf协议初始化参数id定义就可以还原明文了。
6、经过JS断点调试,最终定位到protobuf协议初始化参数如下:

7、将Console中的数据复制后进行JSON在线格式化解析,截图如下:

总结:知道response明文及protobuf协议定义的参数及id后,接下来我们只需要构建proto文件即可完成对整个明文信息的还原。
三、protobuf协议还原
1、还原protobuf协议,编辑代码结构如下:
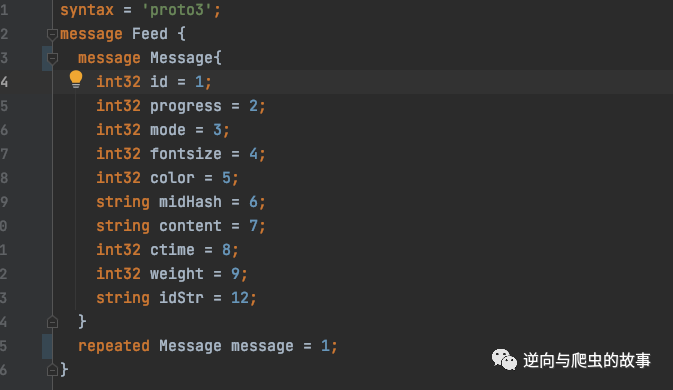
2、执行如下命令,编译为python protobuf可执行文件:
protoc --python_out=. *.proto3、运行命令后,生成protobuf文件,截图如下所示:
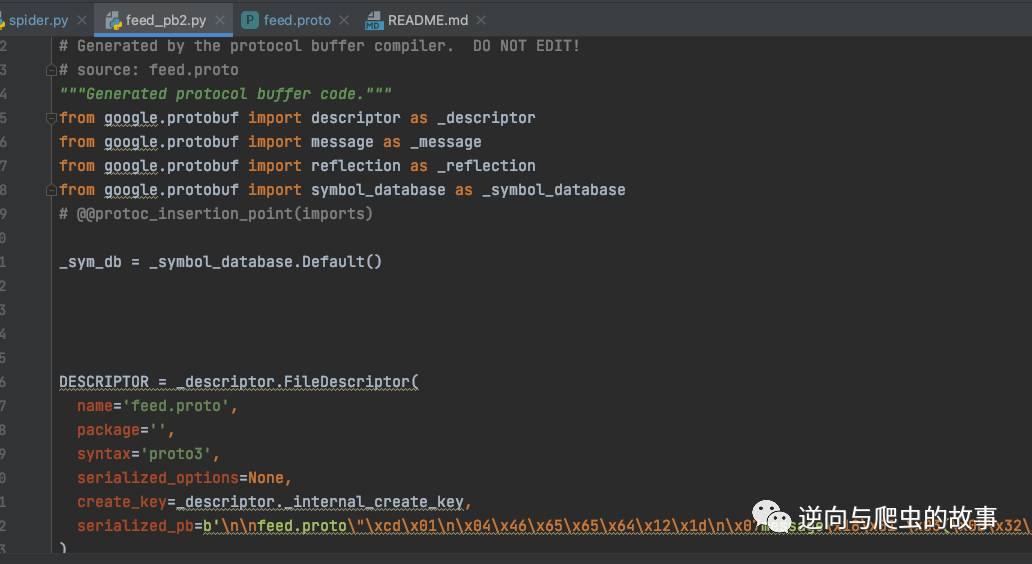
总结:走到这里protobuf协议就完全还原了,接下来让我们进入完整代码实现环节吧。
四、完整代码实现
1、整个项目完整代码如下
# -*- coding: utf-8 -*-
# --------------------------------------
# @author : 公众号:逆向与爬虫的故事
# --------------------------------------
import requests
from feed_pb2 import Feed
from google.protobuf.json_format import MessageToDict
def start_requests():
cookies = {
'rpdid': '|(J~RkYYY|k|0J\'uYulYRlJl)',
'buvid3': '794669E2-CEBC-4737-AB8F-73CB9D9C0088184988infoc',
'buvid4': '046D34538-767A-526A-8625-7D1F04E0183673538-022021413-+yHNrXw7i70NUnsrLeJd2Q%3D%3D',
'DedeUserID': '481849275',
'DedeUserID__ckMd5': '04771b27fae39420',
'sid': 'ij1go1j8',
'i-wanna-go-back': '-1',
'b_ut': '5',
'CURRENT_BLACKGAP': '0',
'buvid_fp_plain': 'undefined',
'blackside_state': '0',
'nostalgia_conf': '-1',
'PVID': '2',
'b_lsid': '55BA153F_18190A78A34',
'bsource': 'search_baidu',
'innersign': '1',
'CURRENT_FNVAL': '4048',
'b_timer': '%7B%22ffp%22%3A%7B%22333.1007.fp.risk_794669E2%22%3A%2218190A78B5F%22%2C%22333.788.fp.risk_794669E2%22%3A%2218190A797FF%22%2C%22333.42.fp.risk_794669E2%22%3A%2218190A7A6C5%22%7D%7D',
}
headers = {
'authority': 'xxxxxx',
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'origin': 'https://www.xxxxx.com',
'pragma': 'no-cache',
'referer': 'https://www.xxxxxx.li.com/video/BV1434y1L7rb?spm_id_from=333.851.b_7265636f6d6d656e64.1&vd_source=8d45ec9ed78652f966b3625afe95e904',
'sec-ch-ua': '".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
}
params = {
'type': '1',
'oid': '729126061',
'pid': '896926231',
'segment_index': '1',
}
response = requests.get('https://xxxx.xxxx.com/x/v2/dm/web/seg.so', params=params, cookies=cookies,
headers=headers)
info = Feed()
info.ParseFromString(response.content)
_data = MessageToDict(info, preserving_proto_field_name=True)
messages = _data.get("message") or []
for message in messages:
print(message.get("content"))
if __name__ == '__main__':
start_requests()2、运行代码后,截图如下所示:
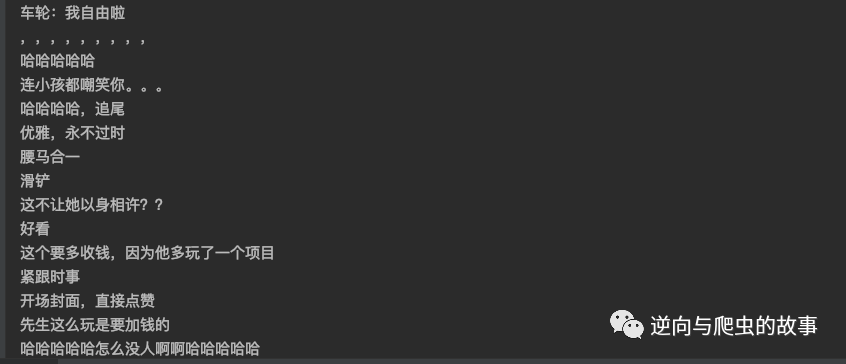
五、心得分享及总结
回顾整个分析流程,本次难点主要概括为以下几点:
如何快速定位加密参数的位置
了解并熟练掌握protobuf协议
能够通过源码还原proto文件
如何在python中使用protobuf

End
崔庆才的新书《Python3网络爬虫开发实战(第二版)》已经正式上市了!书中详细介绍了零基础用 Python 开发爬虫的各方面知识,同时相比第一版新增了 JavaScript 逆向、Android 逆向、异步爬虫、深度学习、Kubernetes 相关内容,同时本书已经获得 Python 之父 Guido 的推荐,目前本书正在七折促销中!
内容介绍:《Python3网络爬虫开发实战(第二版)》内容介绍

扫码购买


点个在看你最好看

边栏推荐
- B站大佬用我的世界搞出卷積神經網絡,LeCun轉發!爆肝6個月,播放破百萬
- 「小程序容器技术」,是噱头还是新风口?
- #DAYU200体验官# 首页aito视频&Canvas绘制仪表盘(ets)
- CRMEB商城系统如何助力营销?
- CSDN 上传图片取消自动加水印的方法
- 浅谈现在的弊端与未来的发展
- [launched in the whole network] redis series 3: high availability of master-slave architecture
- Bipartite graph determination
- 同构+跨端,懂得小程序+kbone+finclip就够了!
- cuda 探索
猜你喜欢

cuda 探索
With the help of this treasure artifact, I became the whole stack
The problem that dockermysql cannot be accessed by the host machine is solved
PDF批量拆分、合并、书签提取、书签写入小工具

COSCon'22 社区召集令来啦!Open the World,邀请所有社区一起拥抱开源,打开新世界~
Efficient ETL Testing

European Bioinformatics Institute 2021 highlights report released: nearly 1million proteins have been predicted by alphafold

DR-Net: dual-rotation network with feature map enhancement for medical image segmentation

mysql连接vscode成功了,但是报这个错
dockermysql修改root账号密码并赋予权限

随机推荐
Balanced Multimodal Learning via On-the-fly Gradient Modulation(CVPR2022 oral)
自动更新Selenium驱动chromedriver
案例推荐丨安擎携手伙伴,保障“智慧法院”更加高效
Improving Multimodal Accuracy Through Modality Pre-training and Attention
DevSecOps软件研发安全实践——发布篇
dockermysql修改root账号密码并赋予权限
asp读取oracle数据库问题
How to choose the server system
Redis 持久化机制
mysql-cdc 的jar包 ,在flink运行模式下,是不是要放在不同的地方呢?
Hard core observation 545 50 years ago, Apollo 15 made a feather landing experiment on the moon
Station B boss used my world to create convolutional neural network, Lecun forwarding! Burst the liver for 6 months, playing more than one million
The problem of ASP reading Oracle Database
Graphite document: four countermeasures to solve the problem of enterprise document information security
允许全表扫描 那个语句好像不生效set odps.sql.allow.fullscan=true;我
cuda 探索
Some suggestions for foreign lead2022 in the second half of the year
【Unity】升级版·Excel数据解析,自动创建对应C#类,自动创建ScriptableObject生成类,自动序列化Asset文件
Demonstration of the development case of DAPP system for money deposit and interest bearing financial management
MySQL中正则表达式(REGEXP)使用详解