当前位置:网站首页>Arrangement of basic knowledge points
Arrangement of basic knowledge points
2020-11-06 01:18:00 【Clamhub's blog】
One 、java Set class of basis
1、ArrayList Capacity expansion mechanism of
- Each expansion is the original capacity 1.5 times , By means of shifting .
- Use copyOf In order to expand the capacity .
The expansion algorithm first obtains the size of the container before the expansion . And then through oldCapacity + (oldCapacity >> 1) To calculate the container size after expansion newCapacity. It's used here >> Right shift operation , That is, the capacity of the original 1.5 times . Also note that , When we expand the capacity here , When used Arrays.copyOf Method , It's also used internally System.arraycopy Method .
difference :
- arraycopy() Target array required , Copy the original array into your own defined array , And you can choose the starting point and length of the copy and the position to put in the new array .
- copyOf() Is the system automatically creates an array inside , And return the array .
2、 Array and ArrayList The difference between
- Arrays can contain basic types ,ArrayList Members can only be objects .
- The array size is fixed ,ArrayList It can be dynamically expanded .
3、ArrayList and LinkedList The difference between
- Thread safety
ArrayList and LinkedList It's all out of sync , That is, thread safety is not guaranteed ; - data structure
LinkedList It is based on bidirectional linked list ,ArrayList It's based on arrays . - Fast random access
ArrayList Support random access , So the query speed is faster ,LinkedList add to 、 Insert 、 It's faster to delete elements . - Memory footprint
ArrayList The waste of space is mainly reflected in list A certain amount of space will be reserved at the end of the list ,LinkedList Use Node To store data each Node Not only the values of elements are stored in , It also stores the previous one Node And the next one Node References to , Takes up more memory . - Traversal mode selection
Realized RandomAccess Interface list, Give priority to ordinary for loop , secondly foreach,
Unrealized RandomAccess Interface list, Preference iterator Traverse (foreach Traversing the bottom is also through iterator Realized ), Big size The data of , Never use ordinary for loop .
4、 How to create a synchronized List
Can pass Collections.sychronizeList take list Convert to sync list, Or use it directly CopyOnWriteArrayList.
5、CopyOnWriteArrayList
- Read without lock , Lock when writing , When writing, create a new array, copy the old array into the new array , And add the data to the new array .
- Only final consistency can be guaranteed .
6、Vector
ArrayList A version of thread safety , Through the bottom layer synchronized Lock to achieve thread safety .
7、HashMap Expansion mechanism
HashMap Use resize() Method to expand the capacity , Calculation table The new capacity of the array and Node New position in new array , Copy the values from the old array to the new array , So as to realize automatic expansion .
- In the sky HashMap Instance when adding elements , It will use the default capacity 16 by table The length of the array is expanded , here threshold = 16 * 0.75 = 12.
- When not empty HashMap Instance to add new elements when the array capacity is not enough , It's going to be in the old capacity 2 To expand the capacity of , Of course, the expansion is also limited in size , The new capacity after expansion should be less than or equal to the specified maximum capacity , Use new capacity to create new table Array , Then there are array elements Node The copy of , Calculation Node The method of location is index = (n-1) & hash, The advantage of this calculation is that ,Node The position in the new array either remains unchanged , Either the original position plus the capacity of the old array , The positions in the new array are predictable ( Regular ), And on the list Node And the order of things doesn't change .
8、HashMap Why not thread safe
- There is no lock operation , Two threads operate on the same hashMap There will be thread safety issues , May cause data loss .
- resize There will be a deadlock when , think hash After the conflict is solved by chain address method hash Conflict , But when both threads are expanding , The linked list uses the head insertion method , This leads to a circular reference , Deadlock occurred .1.8 after Linked lists are all tail inserted . It avoids the problem of an endless loop .
9、 Why? HashMap Of hashCode higher 16 Bit exclusive or hashCode
Because the position of the element is only low n Bit related , high 16 Bit and hashcode XOR is used to reduce collisions .
Exclusive or both return 0 Different return 1.
10、 Why? HashMap The capacity of 2 Of N The next power
- The distribution is more uniform when taking the mold .
- The cost of expansion is lower .
2^n There are characteristics below :
x%2^n=x&(2^n-1)
Only 2 The power of the power has this property .
11、ConcurrentHashMap The implementation of the
- jdk1.7 Before , Using segmented lock , The concurrency supported by default is 16,segment Inherited from ReentrantLock,segment Act as a lock . Every segment It contains a small hash surface .size Methods will segment Of count Add up , Count twice , If the two results are the same , It shows that the calculation is accurate , Otherwise each segment Lock calculation again .
- jdk1.8 After that, cancel the design of segmented lock , use CAS+Synchronized Ensure thread safety . It mainly locks the head node of the linked list .size Method using a volatile Variable baseCount Record the number of elements , It is updated when new data is inserted or deleted baseCount Value .
12、ConcurrentHashMap1.7 And 1.8 similarities and differences
- 1.8 The block lock has been cancelled , The granularity of the lock is smaller , Reduce the probability of concurrent conflicts .
- 1.8 The linked list is used + The realization of red and black trees , Great improvement on queries .
13、 Why? ConcurrentHashMap Read operations are not locked
- ConcurrentHashMap Only final consistency is guaranteed , Strong consistency is not guaranteed .
- about value Use volatile keyword , Keep memory visible , Can be read by multiple threads at the same time , And you don't read expired values . according to java Memory model happens-before principle , Yes volatile The write operation precedes the read operation , Even if two threads read and write the same variable at the same time , It can be get The operation gets the latest value
- Node Use volatile Keyword identification is for the visibility of array expansion .
14、LinkedHashMap The implementation of the
be based on hashMap And bidirectional linked list , Thread unsafe .
15、HashSet The implementation of the
- The bottom is through hashMap Realized .
- Determine whether two objects are equal , First judge hashCode Whether it is equal or not , If equal, judge again equals, That's why rewriting equals Method to override hashCode Method .
16、TreeMap The implementation of the
The bottom layer uses red and black trees . Sort by key value ,key Must be realized Comparable Or construct interfaces TreeMap Time passes in Comparator.
17、TreeSet The implementation of the
Bottom use TreeMap Realization , That is to use the red black tree to achieve .
Set Judge whether two elements are equal , First judge hashCode Reuse equals
18、 solve Hash The method of conflict
- Open addressing
- Chain address
- Again hash Law
19、List、Map、Set Stored null value
- list null value , Add a few and save a few .
- set null value Save only one .
- map There is only one null It's worth it .
20、 Balanced binary trees AVL The difference with red and black trees
- Balanced binary trees are highly balanced , Every insert and delete , To carry out rebalance operation .
- Red and black trees are not highly balanced .
Definition of red black tree :
- Nodes are red or black .
- The root node is black .
- The number of black nodes on each path is the same .
- The color of the child node and the parent node are not the same .
Two 、java Basic multithreading
The contents of this arrangement are as follows :

1、 The difference between a process and a thread
A process is an executable program , It is the basic unit of system resource allocation ; Thread is a relatively independent executable unit in a process , It is the basic unit of task scheduling in operating system .
2、 Communication between processes
2.1、 Operating system kernel buffer
Because each process has its own memory space , Data exchange between processes needs to go through the operating system kernel . Need to open up a buffer in the operating system kernel , process A You will need to copy the data into the buffer , process B Read data from buffer . Because shared memory has no exclusive access function , Mutual exclusive access is required with semaphores .
2.2、 The Conduit
How the pipeline is implemented :
- The parent process creates a pipeline , Get two description files pointing to both ends of the pipe .
- The parent process fork Out of child process , The child process also has two description files , Point to both ends of the same pipe .
- The parent process closes the reader (fd(0)), The child process closes the write side (fd(1)). The parent process writes , The child process reads from the pipe .
Characteristics of pipelines :
Only blood related processes are allowed to communicate , Only one way communication is allowed , The process is in the pipeline , The process disappears, the pipeline disappears . The inner part of the pipeline is realized by ring queue .
Famous pipeline ( name pipes ):
Communication between processes is realized by means of files . Allow communication between unrelated processes
2.3、 Message queue
A list of messages , It exists in the system kernel . Overcome the semaphore to transmit less information , Pipeline can only carry unformatted character stream and the size of buffer is limited . Distinguish messages by message type .
2.4、 Semaphore
It's essentially a counter , Not for the purpose of transmitting data , It is mainly used to protect shared resources , It makes the resource only available to one process at a time .
2.5、 Socket
It can be used to communicate processes between different machines .
Socket includes 3 Attributes : Domain 、 type 、 agreement .
- Domains include ip port
- Type refers to two communication mechanisms : flow (stream) And datagram (datagram)
- Agreement means TCP/UDP The underlying transport protocol
establish socket adopt bind Name the binding port ,listen Create a queue to hold outstanding client requests ,accept Waiting for the client to connect ,connect The server connects to the client socket,close Close the connection of the server client .
stream and datagram The difference between :
stream Can provide an orderly 、 reliable 、 Bidirectional 、 Connection based byte stream (TCP), There will be problems of unpacking and sticking .
datagram Yes, there is no connection 、 unreliable 、 Datagram services using fixed size buffers (UDP), Because based on datagrams , And it has a fixed size , So there will be no problem of unpacking and sticking .
Please refer to : Five communication modes between processes are introduced
3、 Communication between threads
Shared memory :
Java It's shared memory , Memory sharing must be through locks or CAS Technology to get or modify shared variables , It looks simple , But the use of locks is more difficult , If the business is complex, deadlock may occur .
The messaging :
Actor The model is an asynchronous 、 Non blocking messaging mechanism .Akka Is for Java Of Actor model base , For building high concurrency 、 Distributed 、 Fault tolerance 、 Event driven is based on JVM Application . Message passing mode is to display the communication between threads by sending messages , For large and complex systems , Maybe it's better .
Please refer to :Java Memory model analysis
4、 The advantages and disadvantages of multithreading
advantage :
make the best of cpu Resources for , Improve cpu The usage rate of , Make the program run more efficiently .
shortcoming :
There are a lot of threads that affect performance , The operating system switches between threads , Will increase the memory cost . There may be a deadlock 、 There is concurrency between threads .
5、 How to create a thread
- Integrate Thread class , rewrite run Method , utilize start Start thread .
- Realization Runable Interface creation thread , rewrite run Method , adopt new Thread Method to create a thread .
- adopt callable and futuretask Create thread , Realization callable Interface , rewrite call Method , Use future Object packaging callable example , adopt new Thread Method to create a thread .
- Creating threads through thread pools .
6、runable and callable difference
- runable It's rewriting run Method ,callable rewrite call Method .
- runable no return value ,callable There is a return value .
- callable Medium call Methods can throw exceptions ,runable Medium run Method cannot throw an exception to the outside world .
- Join the thread pool to run runable Use execute function ,callable Use submit Method .
7、sleep and wait difference
- wait Only in synchronized Call in block , Methods at the object level ,sleep Unwanted , Belong to Thread Methods .
- call wait Method will release the lock ,sleep It won't release the lock .
- wait After the timeout, the thread enters the ready state , Waiting to get cpu Carry on .
8、yield and join difference
- yield Release cpu resources , Put the thread in a ready state , Belong to Thread Static method of , It won't release the lock , Only threads with the same or higher priority have the chance to execute .
- join Wait for the call join Method is executed after the thread execution of the method is completed .join Will release the lock and cpu Resources for , The bottom is through wait Method .
9、 The conditions for deadlock are
- mutual exclusion .
- Request and hold conditions .
- The condition of indivisibility .
- Loop wait condition .
Please refer to : Concurrent programming challenges : Deadlock and context switching
10、 How to solve deadlock
- Break request and hold condition
Static allocation , Each thread gets all the resources it needs before it starts .
Dynamic allocation , Each thread does not own resources when it requests to get resources . - The destruction of the inalienable conditions
When a thread cannot get all the resources , Enter the waiting state , Its acquired resources are implicitly released , Rejoin the system's resource list , Can be used by other threads . - Deadlock detection : Banker Algorithm
11、threadLocal The implementation of the
- ThreadLocal It is used to provide thread local variables. In multi-threaded environment, it can ensure that the variables in each thread are independent of the variables in other threads .
- Bottom use ThreadLocalMap Realization , Each thread has its own ThreadLocalMap, The interior inherited WeakReference Of Entry Array , Contains Key by ThreadLocal, The value is Object.
Please refer to :【SharingObjects】ThreadLocal
12、threadLocal When will a memory leak occur
java.lang.ThreadLocal.ThreadLocalMap.Entry:
1 |
static class Entry extends WeakReference<ThreadLocal<?>> { |
because ThreadLocalMap Medium key Is a weak reference , and key The object is threadLocal, Once put threadLocal Set instance to null after , No strongly referenced objects point to threadLocal object , therefore threadLocal The object will be Gc Recycling , But it's associated with value But it can't be recycled , Only after the current thread ends , Corresponding map value To be recycled . If the current thread does not end , May cause memory leak .
Such as thread pool scenario , In the thread threadlocal Set as null, But threads are not destroyed and never used , It may lead to a memory leak
Calling get、set、remove When the method is used , Will clear the thread map All in key by null Of value. So when you don't use threadLocal Called when the remove Remove the corresponding object .
13、 Thread pool
13.1、 Thread pool class structure
ThreadPoolExecutor Inheritance diagram :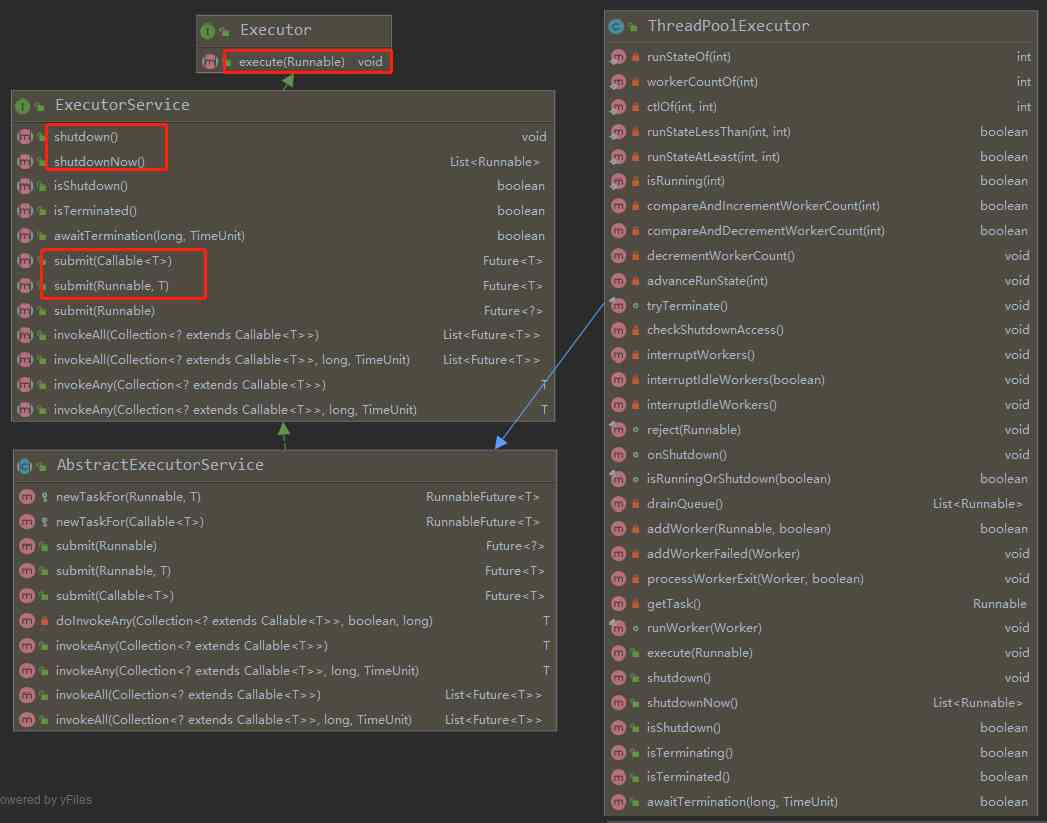
13.2、shutDown and shutDownNow The difference between 、
shutDown After the method is executed, it becomes SHUTDOWN state , Unable to accept new tasks , Then wait for the submitted task to complete .
shutDownNow Then it becomes the execution method STOP state , Unable to accept new tasks . And execute to the thread in execution Thread.interrupt() Method .
- SHUTDOWN: Do not accept new task submission , But it will continue to process tasks in the waiting queue .
- STOP: Do not accept new task submission , Tasks in the queue are no longer waiting to be processed , Interrupt the thread that is executing the task .
13.3、 Parameters of thread pool
- CorePoolSize Number of core threads
- MaximumPoolSize Maximum number of threads , The maximum number of threads allowed to be created by the thread pool
- keepAliveTime Lifetime of idle threads
- wokeQueue Task queue
- handler Saturated strategy
- threadFactory Used to generate threads .
When the mission comes , The number of threads that reach the core if , The task will be added to the blocking queue , If the blocking queue is full , Threads continue to be created until the maximum number of threads is reached , If the number of threads has reached the maximum number of threads , And when the task queue is full , Will execute a rejection strategy .
If you want the core thread to be recycled , have access to allowCoreThreadTimeOut Parameters , If false( The default value is ), The core thread remains active even when it is idle . If true, The core thread uses keepAliveTime To work overtime .
13.4、 Thread pool saturation strategy
- CallerRunsPolicy: The thread that submits the task executes the task itself .
- AbortPolicy ( Default ): Direct selling RejectExecutionException abnormal .
- DisCardPolicy: Don't deal with it , Abandon the current task .
- DiscardOldestPolicy: Get rid of the head of the queue , Submit the current task to the blocking queue .
13.5、 Thread pool classification
java.util.concurrent.Executors class :
newFixedThreadPool
1
2
3
4
5public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}Generate a fixed size thread pool , At this point, the number of core threads is equal to the maximum number of threads ,keepAliveTime = 0 , Task queue takes LinkedBlockingQueue Unbounded queue ( It can also be set to bounded queue ).
It is suitable for meeting the needs of resource management , The application scenarios that need to limit the number of current threads , For example, the server with heavy load .newSingleThreadExecutor
1
2
3
4
5public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));Generate a thread pool with only one thread , Both the number of core threads and the maximum number of threads are 1,keepAliveTime = 0, Task queue takes LinkedBlockingQueue, For tasks that need to be performed sequentially , And at any point in time, there won't be more than one thread active application scenario .
newCachedThreadPool
1
2
3
4
5public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}The number of core threads is 0, The maximum number of threads is int Maximum ,keepaliveTime by 60 second , Task queue takes SynchronousQueue, Small programs that perform many short-term asynchronous tasks , Or a lighter load server .
newScheduledThreadPool
1
2
3
4
5
6
7
8public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}Fixed length thread pool , Support periodic tasks , The maximum number of threads is int Maximum , The timeout is 0, Task queues use DelayedWorkQueue, It is applicable to tasks that require multiple background execution cycles , At the same time, in order to meet the requirements of resource management and need to limit the number of background threads .
13.6、 What happens when an exception occurs during task execution ?
After a mission fails , It only affects the thread that is currently executing the task , There is no impact on the entire thread pool .
Please refer to :ThreadPoolExecutor What happens when a thread pool task fails to execute
13.7、 The underlying implementation of thread pool
- Use hashSet Storage worker
- Every woker Control your state
- After executing the task, loop to get the task in the task queue
13.8、 Restart the service 、 How to shut down thread pool gracefully
kill -9 pid The kernel level of the operating system forcibly kills a process .
kill -15 pid Send a notification , Tell app to shut down actively .
ApplicationContext Accept the notice when you arrive , Will execute DisposableBean Medium destroy Method .
Usually we are in destroy Do some aftercare logic in the method .
call shutdown Method , Shut down .
13.9、 Why use thread pools
- Reduce resource consumption , Reduce the cost of creating destroy threads .
- Improve response time .
- Improve the manageability of threads , Unlimited creation of threads , Consume system resources , Reduce the stability of the system .
3、 ... and 、java Lock of foundation
1、 The lock state
The state of the lock can only be upgraded, not degraded .
- unlocked
There is no lock to lock the resource , All threads can access and modify the same resource , But at the same time, only one thread can modify successfully . Other threads that fail to modify will try again and again , Until the modification is successful , Such as CAS Principle and application is the implementation of lock free . - Biased locking
Biased locking means that a piece of synchronized code is always accessed by a thread , That thread will automatically acquire the lock , Reduce the cost of lock acquisition . - Lightweight lock
When a lock is biased toward a lock , Accessed by another thread , Biased locks will be upgraded to lightweight locks , Other threads try to acquire the lock by spinning , It won't block , To improve performance . adopt cas Operation and spin to solve the lock problem , Spin more than a certain number of times or there is already a thread spinning , When another thread gets the lock , Lightweight locks will be upgraded to heavyweight locks . - Heavyweight lock
Upgrade to heavyweight lock , The thread waiting for the lock will enter the blocking state .
2、 Optimistic lock and pessimistic lock
- Optimism lock , Every time I take the data, I think that no one else will modify it , When updating, judge whether the data has been updated during this period , You can use mechanisms like version numbers , Suitable for reading multiple scenes , Improve performance .
- Pessimistic locking , Every time I get the data, I think someone else will modify it , It's locked , have access to synchronized、 An exclusive lock Lock、 Read write lock and other mechanisms , Suitable for writing more scenes , Make sure that the write operation is correct .
3、 Spinlocks and adaptive spinlocks
- spinlocks : When a thread is acquiring a lock , If the lock has been acquired by another thread , Then the thread will wait in a loop , Then constantly judge whether the lock can achieve success , It doesn't exit the loop until the lock is acquired .
advantage : Thread does not switch context , Reduced context switching time .
The problem is : If the thread holds the lock for a long time , Other threads enter the loop , Consume cpu. - Adaptive spinlock : It means that the time of spin is not fixed , It is determined by the time the previous spin on the same lock and the state of the lock owner . If it's on the same object , Just got the lock by spinning , And the thread holding the lock is running , Then the virtual machine will think that this spin is likely to succeed again . Conversely, spin operations rarely succeed in acquiring locks , Then the acquisition of this lock may directly omit the process of spinning , Blocking threads directly .
4、 Fair lock and unfair lock
- Fair lock refers to that multiple threads directly enter the queue in the order of applying for locks , The first thread in the queue can acquire the lock .
- Unfair lock means that the thread attempts to acquire the lock first , Can't get into the queue , If you can get , The lock can be obtained directly without blocking .
5、 Re - entry and re - locking
Reentrant lock : When the same thread gets the lock in the outer method , When entering the inner layer, the method will automatically acquire the lock , The premise is that the lock objects are the same .
6、 Shared lock and exclusive lock
- Shared lock means that a lock can be held by multiple thread locks .
- Exclusive lock or exclusive lock or mutex lock A lock can only be held by one thread at a time .
7、 Read-write lock
- Read locks are shared , The write lock is exclusive .
- There is no mutual exclusion between reading and reading , Reading and writing are mutually exclusive , Writing mutually exclusive , Read write lock improves read performance .
8、CAS
CompareAndSwap Comparison and exchange , It's a lock free algorithm , Atomic classes use CAS Realized the optimistic lock .
The problems brought about by :
- ABA problem
The solution is to add the version number in front of the variable , Each time the variable is updated, the version number will be +1, Ask for a version every time you update >= current version (AtomicStampedReference) - The cycle time is long and the cost is high ,CAS If the operation is not successful for a long time , Will cause it to spin all the time ,cpu Consume large .
- Only one atomic operation of shared variables can be guaranteed .
You can put multiple variables in one object CAS operation .
9、 Lock the optimization
9.1、 Lock escalation
- Upgrade of biased lock
Threads A When getting the lock object , Will be in java Object headers and stack frames record biased threads A Of id, Threads A When you get the lock again , Just compare java The thread in the header id With the current Id Whether it is equal or not , If it is consistent, there is no need to pass cas Lock and unlock . If it's not consistent , Indicates that there are threads B To get the lock , Then judge java Whether the thread with lock bias in the header survives , If it doesn't survive , The lock object is set to an unlocked state , Threads B Lock can be set as an object B Biased lock of . If you survive , View A Whether you still need to continue to hold the current lock , If you don't need to hold , The lock will be set to the state of no lock , Biased towards new threads , If you continue to hold the lock object , Then pause A Threads , Undo the bias lock , Upgrade lock to lightweight lock . - Lightweight lock upgrade
Threads A When obtaining a lightweight lock, the object header of the lock will be copied to its own thread stack frame , And then through cas Replace the content in the object header with A The recorded address . The thread B Also want to get the lock , Find out A Lock has been acquired , So thread B Just spin and wait . Wait until the spin number reaches or the thread A Being implemented , Threads B Spin wait , Here comes the thread C To compete for lock objects , At this point, lightweight locks will expand to heavyweight locks . A heavyweight lock will turn all threads that have not obtained the lock object into a blocked state to prevent cpu Idle .
9.2、 Lock coarsening
Lock multiple consecutive locks , Unlock operations are linked together , Expand to a wider range of locks , Avoid frequent adding and unlocking operations .
9.3、 Lock elimination
Through escape analysis , Remove locks that cannot compete for shared resources , Eliminate unnecessary locks in this way .
10、synchronized Underlying implementation
- synchronized adopt Monitor Synchronization ,Monitor Rely on the underlying operating system Mutex to achieve thread synchronization .
- java The object head is made up of markword( Tag field ) and klass point( Type a pointer ) form .markword Storing objects hashcode, Generation age and lock flag bit information .Klass point Pointer to object metadata , The virtual machine uses this pointer to determine which class the object is an instance of .
- synchronized Modifying synchronous code blocks , It's using monitorenter and monitorexit Controlled , adopt java Lock counter in object header .
- When decorating a method, the method is identified as ACCSYNCHRONIZE,JVM This flag is used to determine whether the method is synchronous or not .
11、synchronized And ReentrantLock The difference between
- Both are pessimistic locks , Reentrant lock .
- ReentrantLock interruptible , Fair lock can be achieved , You can bind multiple conditions .
- ReentrantLock Call lock and release lock to display ,synchronized Belong to java keyword , There is no need to explicitly release .
12、volatile keyword
- Make sure the variable memory is visible .
- Disable instruction reordering .
volatile and synchronized The difference between :
- volatile It won't block ,synchronized It will block .
- volatile Ensure the memory visibility of data, but not atomicity ,synchronized Both guarantee .
- volatile It mainly solves the visibility of variables between threads , and synchronized It mainly solves the synchronization of multi thread accessing resources .
13、Atomic Atomic classes implement
Use cas operation + volatile + native Method to ensure synchronization .
14、AQS
AQS(AbstractQueuedSynchronizer) The internal maintenance is a FIFO Two way synchronous queue of , If the current thread fails to compete for a lock ,AQS It will construct the current thread and wait state information into a Node Join the synchronization queue , At the same time block the thread . The lock of the thread is released later , Will wake up a blocked node thread from the queue . Use an internal one state To control whether the lock is acquired , When state=0 No lock state ,state>0 Indicates that a thread has acquired the lock .
15、AQS The components of
- semaphore Multiple threads can be specified to access a shared resource at the same time .
- countDownLatch One thread A Wait for other threads to finish executing .
- cyclicBarrier A group of threads wait for a state to execute simultaneously .
countDownLatch and CyclicBarrier The difference between
- countDownLatch It is a thread that waits for a group of threads to execute , cyclicBarrier It is a group of threads waiting for each other to reach a certain state , At the same time .
- countDownLatch It can't be reused ,cyclicBarrier Can be reused .
16、 Lock down
Lock demotion is to demote a write lock to a read lock , This process is when the current thread has obtained the write lock , And get the read lock , Then the process of releasing the write lock , The purpose of this is to ensure the visibility of the data .
17、 Escape analysis
- Escape analysis is to analyze the dynamic scope of the object , When an object is defined in a method , He may be cited by external methods , Pass as parameters to other methods , Become a way to escape , An instance variable assigned to a class variable or an instance variable that can be accessed by other threads becomes thread escape .
- Using escape analysis , The compiler can optimize the code . such as : Synchronous ellipsis ( Lock elimination ), Convert heap allocation to stack allocation , Scalar substitution .
- Disadvantages of using escape analysis , There is no guarantee that the performance of escape analysis will be higher than other performance . In extreme cases, after escape analysis , All the objects have escaped , Then the escape analysis process is wasted .
Four 、java The foundation JVM
1、 Memory model
1.1、 Pile up
- The heap is shared by all threads , It mainly stores object instances and arrays .
- The ratio of the new generation to the old generation is 1:2.
- The proportion of the three regions in the Cenozoic is 8 : 1 : 1.
1.1.1、 The new generation
Object assignment in eden In the area , When eden When the area is full minor gc, take eden The living objects in the zone , Copied to the survivor0 In the area , Empty eden District , When survivor0 When it's full , Will copy live objects to survivor1 In the area , And then survivor0 and survivor1 In exchange for , keep survivor1 It's empty. . Every time yong gc age +1.
- Eden
objects creating , Object assignment in eden District , When eden The district is full , When you create an object again , Will trigger minor gc, Conduct Eden and from survivor Regional garbage collection . - FromSurvivor
- ToSurvivor
minor gc Objects that are still alive will be placed in this area , When the age of the object reaches the threshold, it will enter the old generation . perhaps to survivor The area is full , Will put objects into the older generation .
1.1.2、 Old age
- Big object , Objects that require a lot of contiguous memory space
- Long term survivors , The object is older than 15( The default value is )
- yong gc after survivor The object that can't accommodate .
1.2、JVM Stack
Thread private , Each thread has a stack , It mainly stores the local variables of the current thread , Program running state , Method return value , Method export, etc .
1.3、 Native Method Stack
Used for virtual machines native Method service .
1.4、 Method area
Used to store the class information that has been clipped in , Constant , Static variables ,1.8 After the abolition of the permanent generation , Added meta space , The meta space is not in the virtual machine , It's local memory . The meta space holds the meta information of the class , Static variables and constant pools are moved into the heap .
1.5、 Program counter
- The program is private , The life cycle is the same as the program
- The line number indicator of bytecode executed by the current thread .
- Used to implement branching , loop , Jump , Abnormal and other functions .
2、 What's in the constant pool
Constant pools are determined at compile time , Stored in compiled generated class In file , Contains basic data types and object types (String And an array )
3、 How to judge whether an object is alive or not
How to mark an object recyclable ?
- Reference counting , Each object has a reference counter , Cited +1 When the number of references is 0 That is, can be GC The object of
- Accessibility analysis : Starting from the root node , Search down , Unreachable objects are marked as inaccessible , Recyclable
4、 Which objects can be used as GC ROOT object
- Objects referenced in the virtual machine stack .
- The object referenced by the static object in the method area .
- The object referenced by a constant in the method area .
- Objects referenced in the local method stack .
5、GC Strategy
- Mark removal method , Scan from the root node , Mark the surviving object , After marking , Then scan the whole space for unlabeled objects , Clean up . Easy to cause memory fragmentation .
- Copy , Divide the memory into two parts , When one of them is full , Scan from the root node , Copy the surviving object to another copy of memory . There will be no memory fragmentation problems , But it takes twice as much space .
- Tag to sort out , It's like mark removal , Mark the object , After clearing, move all surviving objects to the left . Avoid memory fragmentation and double space problems , But it increases the cost of moving objects .
6、 Specifically GC The collector
- Serial garbage collector ,serial
- Parallel garbage collectors parNew,parallel Focus on throughput
- cms Focus on the shortest recovery pause time
- G1
cms and G1 The difference between :
- cms It's the garbage collector of the old days , Use the mark to clear .
- G1 It's a garbage collector for the new and the old , Mark up .
- cms Memory fragmentation will occur ,G1 It's not .
- Cms Pursue the minimum pause time ,G1 It's a controlled pause time , Increase throughput as much as possible .
7、 What kind of objects enter the old generation
- Big object , Objects that require a lot of contiguous memory space .
- Long term survivors , The object is older than 15( The default value is ).
- yong Gc after survivor The object that can't accommodate .
8、 Why distinguish between the new generation and the old generation
- Objects exist in different situations, using different GC Algorithm .
- New generation objects can be created and recycled frequently , Older people recycle less .
9、survivor The significance of district existence
- In order to raise the threshold for the object to enter the old age , Reduce fullGC The number of times , because fullGC Very time consuming .
- Two survivor The purpose of this paper is to reduce survivor The memory fragment of the area .
10、 What is? yangGC
To the young generation gc. The trigger condition :
- eden There is not enough space
- Empty eden from to Objects that are not referenced in .
- take eden from The object of survival in Copied to the to in .
- take to To promote to old in , There are two types of objects , One is the age threshold , One is to Can't fit in .
- full gc It will also trigger yong gc
11、 When to trigger fullGC
- Manually triggered GC.
- There was not enough space in the old days .
- The space of the permanent generation is full ( Method area ).
- Statistics to yong gc The average size of promotion to the old age is greater than the size of the remaining generation ( There was not enough space in the old days ).
- jvm Fixed frequency of itself fullGC( By default, it is executed once an hour ).
12、 Memory configuration parameters
- xms xmx Configure the minimum and maximum heap memory
- xmn The initial size of young generation memory
- xss jvm Stack size
13、 Object allocates memory in two ways
- Pointer collision , If memory objects are regular , Using pointer collisions to allocate memory for objects , All used memory is on one side of the pointer , Unused memory is on the other side of the pointer , To allocate memory, just move the pointer .
- Free list , Memory is not regular , Interleaved memory with unused memory , Maintain a memory usage list , Record what memory is available , At the time of allocation, find a large enough space to divide the objects , And update the list .
14、 How to reduce GC The cost of
- Avoid display calls System.gc.
- Minimize the use of temporary objects .
- When the object is not in use , It's better to explicitly set it to null.
- Use as much as possible StringBuffer without String Accumulate string .
- To be able to use basic types is to use basic types .
- Try to use less static object variables .
15、 What is? JAVA Memory model (JMM)
Used to mask memory access differences between various hardware and operating systems , In order to make java The program can achieve the same concurrent effect in each platform .
16、 What is? happens-before
- Ensures the visibility of memory
- There are four rules :
- Rules of procedure sequence : Every operation in a thread happens-before With all subsequent operations .
- Monitor lock rules : A monitor unlocks happens-before On Lock .
- volatile Variable rule : Write operations happens-before Read operations .
- Transitivity A happens-before B ,B happens-before C , that A happens-before C.
17、 Performance Tuning Tools
17.1、jps
jps It is mainly used to output jvm Status information of processes running in .
-l Output main Class or jar Permission name of .
17.2、jstack
jstack pid > log
The thread stack can be transferred to a file .
Log analysis can use fastthread.io.
17.3、jstat
Can show the virtual machine process in the classloader、 Memory 、gc Etc .
Parameters
-class pid Class load statistics .
-gc Garbage collection statistics , It is followed by two parameters, one is the interval output time , One is the total number of outputs .
gc Logs can be used gceasy.io
17.4、jmap
jmap Check heap memory usage :
jmap pid
17.5、jinfo
see java The running environment parameters of the program :
jinfo pid
18、 memory barriers
By making sure that from another CPU Look at , All instructions on both sides of the barrier are in the correct sequence , And keep the external visibility of the program sequence ; Secondly, it can realize the visibility of memory data , Make sure that the memory data is synchronized to CPU Cache subsystem .
19、JVM The resulting memory overflow and solutions
- java heap space
There are large object assignments in the code , many times GC After still can't find allocation space .
terms of settlement : See if there are large object assignments, especially large arrays . adopt jmap Put the log of heap memory dump Come down , Analysis log , If you can't solve this problem, increase the heap memory space . - permspace metaspace
Permanent generation or meta space overflow . Generate a large number of proxy classes or use custom class loaders .
terms of settlement : Check to see if you have configured the size of the permanent generation or meta space . Whether it hasn't been restarted for a long time jvm, Whether there are a lot of reflection operations .
5、 ... and 、java Basic loading mechanism
1、 Class loading process
1.1、 load
Find and import class file .
1.2、 link
verification
Verify loaded class The correctness of the document , integrity .Get ready
Allocate storage space to static variables of a class , The default value of the object type will be assigned .analysis
take class Symbolic references in constant pools are converted to direct references .The difference between symbolic reference and direct reference :
- Symbol reference :java The compilation phase does not know the actual address of the referenced object , Use symbolic references instead of
- Direct reference : A pointer that can be positioned directly to an object , Or relative offset . It can locate the actual memory address of an object .
1.3、 initialization
Static variables for classes , The code block performs the initialization operation , Static variables are assigned in the order defined by the code .
2、 Class loading order
- Parent static member variable
- Parent static code block
- Subclass static member variable
- Subclass static code block
- Parent class non static member variable
- Parent class non static code block
- Parent class constructor
- Subclass non static member variable
- Subclass non static code block
- Subclass construction method
3、 Class loading time
- Create class instances - Use new keyword , Reflection , clone , Deserialization .
- Call static variables or static methods of a class , Or assign values to static variables .
- When initializing a child class, the parent class is initialized first .
- Virtual machine startup , contain main Method's starting class .
Be careful :
- Reference classes defined by arrays , Does not cause class initialization .
- Accessing the static constants of a class does not cause the class to load . Because at compile time , Static constants have been put into the class's constant pool . To access a class static constant is to directly access the constants in the constant pool , There is no need to load classes .
4、 When are static constants assigned
Static constants store the initial values in the compile phase class In the constant pool of files , In the class preparation phase , Assign a value to a static variable .
5、 What is parental delegation
1. Class loaders include :BootstrapClassLoader、ExtensionClassLoader、 ApplicationClassLoader、 Custom class loader .
2. Parent delegation model : If a class loader receives a request to load a class , First, give it to the parent class loader to load , If the parent loader fails to load , The current class will load the class itself .
3. The role of parental delegation : Avoid repeated loading , The parent class is already loaded, and the child class does not need to be loaded , Prevent user-defined loaders from loading java The core api, Bring security risks .
4. Whether a class is loaded or not is determined by the full class name and namespace , The namespace is the loader name of the loading class .
6、 How to customize class loader
Inherit classloader class , rewrite findClass Method .
6、 ... and 、java The foundation Web With the network
1、 The difference between forwarding and redirection
- Forwarding is a server request resource , The server accesses the target address directly url, Return the response to the browser . Redirection requests the address again according to the status code returned by the server .
- Forwarding is server behavior , Redirection is client behavior .
- Forward displayed url Unchanged while redirection shows new url.
- Forward page and forward page share request Information about , Redirection does not share data .
- Forwarding is usually used for user login , Forward to the corresponding module according to the role , Redirection is usually used for user logout , Jump to another place .
2、TCP Three handshakes
When a connection is established TCP Three handshakes :
- The client sends syn To the server Connection request .
- Server send syn ack To the client Grant connection .
- The client sends ack To the server Confirm connection .
The first time the client confirms that its sending is normal , The server confirms that its reception is normal .
The second time the server confirms its sending , Reception is normal , The sending of the client is normal . The client confirms its sending 、 Accept normal , Sending from the server 、 Accept normal .
The third time the client and server confirm that the sending and receiving of both sides are normal .
3、TCP Four waves
- The client sends fin To the server , Turn off data transfer from client to server .
- Server send ack .
- Server send fin, Close the connection between the server and the client .
- The client sends ack, Connection is closed .
4、 Why three handshakes, four waves
When establishing a connection ,syn and ack You can send it at the same time , But when you disconnect fin and ack Can't send at the same time , because server It has not been confirmed whether all messages have been sent , All messages can only be sent after they have been sent fin. So it takes three handshakes to establish a connection , It takes four waves to disconnect .
5、TCP And UDP The difference between
- TCP The protocol is connected , The connection must be made by three handshakes ,UDP It's disconnected .
- TCP Ensure that the data arrives in order ,UDP There is no guarantee .
- TCP It's a byte stream oriented service ,UDP It's a message oriented service .
6、 What is? Servlet
yes http The middle layer between requests and programs . Can read client request data , Process data and generate results .
7、 The difference between interceptors and filters
- Interceptors are based on java Reflection implementation , Filters are based on function callbacks .
- Interceptors don't depend on Servlet Containers , Filter dependency Servlet.
Implement an interceptor inheritance HandlerIntecepterAdapter.
Implement filter inheritance Filter, stay web.xml To configure .
8、HTTPS The process of
- Client initiated https request , Establishing a connection , Send supported ssl/tls Version of , Supported encryption suite, etc .
- After the server receives the request , It will send the server's certificate , Select the ssl/tls Version of , Encryption suite used .
- After receiving the certificate, the client verifies the certificate , Verify that the certificate has been tampered with , Verify the validity of the certificate . Get the server's public key .
- Encrypt a random number using the server's public key , To the server .
- And then we use this random number for symmetric encryption to transmit data .
9、 Encryption related
- Symmetric encryption
Encryption and decryption use the same set of secret keys , Commonly used encryption algorithm : AES、 DES. - Asymmetric encryption
It means using different keys for encryption and decryption , A public key, a private key . Only the private key can decrypt the information encrypted by public key , The information encrypted by the private key can only be decrypted by the public key . - Abstract
A message , After the digest algorithm, we get a string of hash value . Commonly used abstract algorithm :MD5、SHA1、SHA256. - digital signature
First use the digest algorithm , Get a summary of the content , After that, use your private key to encrypt the digest and generate the signature . - digital certificate
The certificate has a signer 、 Use of certificate 、 Public key 、 encryption algorithm 、hash Algorithm 、 Expiration time, etc . The digital certificate will make a digital signature to prevent the certificate from being tampered with . Will use CA The private key is encrypted .CA The public key of is public , The browser will cache .
7、 ... and 、java Other Basics
1、 Custom annotation
@target
Illustrates the Annotation The scope of the object being decorated : constructor、method、field、package、type wait .
@retention
Defines the Annotation How long has it been kept , source( Source file retention )、class( class Retain )、runtime( Run time effective ).
@inherited
A marked type is inherited . A class marked with @inherited Annotations , So his subclass also has this annotation .
@document
The modified annotation will generate javadoc in .
2、 Inner class
- The inner class is divided into : Member inner class , Anonymous inner class , Static inner class , Local inner classes .
- Except for static inner classes , Other inner classes cannot have static variables or static methods , Because the inner class belongs to a member variable of the outer class , First load the outer class and then the inner class .
reason :- Static variables need to replace symbolic reference with direct reference when class loading, but there is no inner class object at this time .
- Inner classes cannot be used directly without an instance of an outer class .
2.1、 Why static inner classes can have static constants
Because static constants are values that are determined at compile time , It will be stored in the constant pool of the class , While accessing constants in the constant pool does not require loading classes .
2.2、 Internal class usage scenarios
- To achieve a multiple inheritance effect
- Access control , Can only be called through an external class
3、 Automatic unpacking and packing
- Conversion between base type and reference type .
- Collection classes only accept objects .
- Pay attention to the cache value of the wrapper class ,Float and Double Value has no cached value ,Integer and Long The cache value is -128~127 After that, it will be automatically converted to an object . When comparing two packaging types, you need to use equals.
4、String Why final,StringBuilder And StringBuffer The difference between
- String Defined as final Type representation cannot be inherited , Make sure you don't change semantics in subclasses .
Every time the string Object changes are equivalent to regenerating a new string object . Frequently changed strings are not recommended String. - StringBuffer It's thread safe , StringBuilder It's not thread safe .
5、transient
- The marked member variable does not participate in the serialization process .
- Can only modify member variables , Cannot modify classes and methods .
6、 How to serialize
- Realization Serializable Interface .
- Serialization uses the output stream writeObject.
- Deserialization uses the input stream readObject.
7、 How to realize object cloning
- Realization Cloneable Interface , And rewrite clone Method .
- Deep copy can also be done by serialization
- In general, in actual use, we only need to copy the properties of the object , Usually use BeanUtils.copy()
These are shallow copies - Performance of several copy objects
cglib>Spring>apache, It is generally not recommended to use apache Because the object conversion will be wrong ,Spring Of date Type conversion can also be wrong .
8、 abnormal
8.1、Error
System level errors , The program doesn't have to deal with . You can only exit after an error .
8.2、Exception
- Exceptions that need to be caught or programmed .
- Exception It is divided into runtime exception and inspected exception
RuntimeException Include : Null pointer exception , Array subscript out of bounds ,classNotFound, Type conversion exception and so on .
Abnormal test means : The compiler requires a method to declare that it throws possible checked exceptions .
9、Object Medium finalize Method
If the class has overridden finalize Method , When this class of objects is recycled ,finalize Methods can be triggered .
8、 ... and 、dubbo Arrangement of knowledge points
1、dubbo The composition of
- provider service provider .
- consumer Service consumer .
- registry Registry Center Service discovery and registration .
- container Service run container .
- monitor The monitoring center , Count the number of service calls and call time .
2、dubbo The process of service registration and discovery
The service provider registers the service address to the registry at startup . The consumer subscribes to the service address at startup , The registry is based on the service information requested by the consumer , Match the corresponding list of providers and send them to consumers for caching , When the consumer initiates a remote call , Select one of the providers to call based on the cached list of providers .
Service provider status changes are notified to the registry in real time , Registration centers also push them to consumers in real time .
3、 The registry is down , Whether the client server can communicate
Be able to communicate , Because the client caches the information of the server .
4、dubbo Which protocols are supported
- dubbo agreement
- rmi agreement
- http agreement
- webservice agreement
By default dubbo agreement .
5、dubbo The serialization protocol of
Recommended hessian serialize , also dubbo,fastjson java Self serialization .
6、dubbo Communication framework of
netty.
7、dubbo Load balancing of
- random Random , Set the random probability according to the weight .
- roundrobin polling
- Minimum number of active calls
- Uniformity hash, Requests for the same parameters are always sent to the same provider .
8、dubbo timeout handler
dubbo When the call to the service is unsuccessful , By default, try again twice .
9、dubbo The cluster fault tolerance scheme of
The default is to automatically switch other services when failure occurs , It is recommended to read only Failover Fail auto switch , By default, try the other server twice . It is recommended to use Failfast Fast failure , If a call fails, an error will be reported immediately .
10、 What is the principle of service failure kick out
zookeeper Temporary node function of .
11、 How to handle when an interface has multiple implementations
have access to group Attribute to group , Both the service provider and the consumer specify the same group.
12、 How to make the service online compatible with the old version
You can use the version number to register , There is no reference between services with different version numbers , Similar to service grouping .
13、dubbo How to solve the problem of security mechanism
dubbo adopt token The token prevents users from bypassing the registry and connecting directly to , Then manage the authorization on the registry .dubbo It also offers a black and white list of services , To control the callers allowed by the service .
Nine 、mq Arrangement of knowledge points
1、kafka
kafka By multiple broker Server composition , Each type of message is defined as topic, same topic Internal information is based on key And algorithms are distributed to different partition On , Stored in different broker On .
1.1、kafka How to achieve high throughput
- The order IO,kafka Messages are constantly appended to the file , Reduce the seek time of hard disk head , It takes very little sector rotation time . Use os Of pageCache function .
- Zero copy , Skip copy of user buffer , Establish a direct mapping of disk space and memory , The data is no longer copied to the user buffer . Take data from the kernel Buffer in Copy To network card Buffer On , This completes a send .
- File segmentation ,partition It is divided into several segments segment, Each operation is only a small part of the operation , Increased the ability to operate in parallel .
- data compression , adopt gzip or snappy The format compresses the message . Reduce the amount of data transferred , Reduce the pressure of network transmission
- Bulk delivery ,producer When sending a message , Messages can be cached locally , Wait until the fixed conditions are sent to kafka, Reduced server side IO The number of times .
1.2、kafka How to keep the information reliable
kafka The reliability of messages is mainly realized by replica mechanism , By configuring the parameters , send kafka Can make a trade-off between reliability and performance .
1.3、kafka How to achieve high availability
kafka By multiple broker form , Every broker It's a node . One topic It can be divided into many partition, Every partition Can exist in different broker On , Every partition Only a part of the data .
kafka 0.8 After that HA Mechanism , Namely replica Replica mechanism , Every partition The data will be synchronized to other broker above , Make your own copy , be-all replica One will be elected leader( adopt zookeeper Realization ) To deal with producers and consumers , Other replica Namely follower. If a broker Hang up , It has partition Of leader, Will follow follower And re elected one of them leader.
When writing data , Producers write leader,leader Put the data on the disk ,follower Take the initiative pull data ,follower It will be sent after synchronization ACK to leader,leader Received all the follower Of ack The success will be returned to the producer .
Reading data from leader read , Only when a message is all follower They will be consumed by consumers only after they are synchronized successfully .
Producers through zookeeper find partition Of leader.leader The election of is essentially a distributed lock .
2、 How to ensure high availability of message queue
kafka Reference resources 1.3 section ;
RabbitMQ: Using mirror cluster to achieve high availability of queues , Synchronous messages between multiple instances .
shortcoming :
- High performance overhead , All messages should be synchronized to all nodes .
- No scalability , Based on the master-slave structure, there is no linear scalability .
3、 How to keep the information reliable 、 Data is not lost
RabbitMQ
rabbitMq Provide services and confirm Mode to ensure that the producer's data is not lost . Transaction mode refers to starting a transaction before committing data , If an exception occurs during the sending process, the transaction is rolled back . In this way, throughput will be reduced . Turn on confirm Pattern , After the producer submits the message ,rabbitmq Returns the ack Explain to the producer that the queue is successful , If you return nack, Producers can try again .Kafka
Set up request.require.acks=all,
producer.type=sync
min.insnrc.replicas=2, At least two copies are required to be written successfully , Will return a response to producer.4、 How to ensure the order of the message
kafka
write in partition When you specify a key, So consumers start with partition The data is ordered , If it's multi-threaded consumption , Then you need a memory queue , Will be the same hash The results are stored in a memory queue , Then a thread corresponds to a memory queue . It can ensure that the order of writing to the database is consistent .rabbitmq
If there are multiple consumers , So let each consumer have one queue, Then put all the data to be sent into one queue in , This ensures that all data reaches only one consumer , So as to ensure that the order of data arriving at the database is certain .
5、 Comparison of several message queues
- activeMq Use java Language development , The throughput reaches 10000 level , No large-scale throughput validation , The community is not active .
- rabbitMq Use erlang Language development , Good performance , Throughput up to 10000 level , The community is active , But it's hard to customize development .
- rocketMq Use java Development , The interface is simple and easy to use , Throughput reaches 100000 levels , It has been verified by the large-scale throughput of Alibaba .
- kafka Use scala Development , High throughput , Throughput up to 100000 levels , It is mainly used for log collection and real-time calculation of big data .
6、 Why use message queuing
- system decoupling
- Asynchronous processing
- Traffic peak clipping
7、 What are the disadvantages of introducing message queuing
- Reduced system availability .
- The complexity of the system increases , Consider the issue of consistency , Message re consumption , The reliability of the message .
8、 If MQ How to deal with millions of data
- Fix it first consumer The problem of , bring consumer Work well .
- Emergency expansion , increase consumer And the number of message queues , And allocate the backlog messages to the new message queue .
- If the backlog is overdue , It can only be compensated from the log .
Ten 、mybatis Arrangement of knowledge points
1、 What is? Mybatis
MyBatis It's one and a half ORM frame , It's encapsulated inside JDBC, Just focus on SQL Statement itself , It doesn't take a lot of effort to process the load driver 、 Create connection 、 establish Statement And so on , Programmers write native SQL, Can be controlled SQL Executive performance , High flexibility .
Mybatis Execution steps :
- establish SqlSessionFactory
- adopt SqlSessionFactory obtain SqlSession
- adopt SqlSession Perform database operations
- Commit transaction
- Close session
2、MyBatis Of xml How to correspond to the interface
xml Can configure nameSpace Limit the full name of the interface , The method name in the interface is mapped to... In the tag ID value , Method parameters in the interface are passed to SQL Parameter list for .
The principle of interface operation is to use JDK Dynamic proxy for , according to mapper Configured xml To generate DAO The implementation of the .
3、 There are several ways to bind interfaces
- Annotation binding @Select @Update
- adopt xml Write in SQL binding
4、$ And # The difference between
# It's precompiling ,$ It's the original replacement ,$ Two more ’ Before and after the replacement data .# Can prevent SQL Inject .
5、mapper How to pass multiple parameters
Use @Param Annotation to name parameters , Encapsulated into Map.
6、MyBatis How to paginate , How to implement paging plug-ins
MyBatis utilize RowBounds Object to paginate , in the light of resultset Paging memory , You can also directly write parameters with physical paging for physical paging .
Pagination plug-in is to use MyBatis Provided plug-in interface , Implement custom plug-ins , Block pending execution in the plug-in SQL, Then rewrite SQL Add the corresponding physical paging statements and parameters .
7、MyBatis How to compare the returned result with Java Mapping objects
- Use resultMap Define the mapping between database column names and object properties .
- Use resultType Use aliases to map object property names .
MyBatis Create objects by reflection , Then assign values to the attributes one by one .
8、 semi-automatic ORM And fully automatic ORM The difference between
semi-automatic ORM: When querying associated objects or associated collection objects , It needs to be written manually SQL To complete .
9、MyBatis There are several actuators
- SimpleExecutor Every SQL All generate new Statement object .
- ReuseExecutor With SQL As key cache Statement,Statement object reuse .
- BatchExecutor wait for addBatch After execution executebatch
Use... In the configuration file executorType To configure the use of executor.
11、 ... and 、mysql Arrangement of knowledge points
1、 Business
1.1、 characteristic
ACID( Atomicity 、 Uniformity 、 Isolation, 、 persistence )
1.2、 Isolation level
- read uncommit: Uncommitted read 、 There are dirty reading problems .
- read committed: Read committed 、 Solve the dirty reading problem , But there is a problem of non repeatable reading .
- repeateble read: Repeatable , Solve the problem of non repeatable reading , There is the problem of unreal reading .
- serializable: Solve all the problems , Transactions are executed serially .
- Dirty reading : Read uncommitted dirty data .
- It can't be read repeatedly : In the same transaction , For a single piece of data , The results of the two readings are inconsistent , Because other transactions modify the data .
- Fantasy reading : For reading multiple pieces of data , The results of two reads in the same transaction are inconsistent , Because of the new data .
1.3、 Transaction implementation principle
Use the lock mechanism and mvcc Achieve transaction isolation :
- Lock mechanism is used between two write operations to ensure isolation .
- Between a write operation and a read operation , Use mvcc To ensure isolation .
undolog and redolog:
- redolog Redo logs are used to recover data , Ensure the persistence of committed transactions .
- undolog The rollback log is used to roll back data , Ensure the atomicity of uncommitted transactions .
1.4、 Why do you have MVCC And you need a lock
Use mvcc Can reduce the use of locks , Most read operations don't need to be locked , Good performance . Read without lock , Read write conflict .
2、 lock
2.1、 Classification of locks
- Shared lock : Read the lock , Other business can be read , But it can't be written .
- Exclusive lock : Write lock , Other things can't be read , You can't write .
- Intention sharing lock :InnoDB Provide , No user intervention is required , Before adding shared locks , The transaction must acquire the intent share lock .
- Intention exclusive lock : Before adding an exclusive lock, the transaction must obtain the intended exclusive lock .
- Clearance lock : Lock the gap between index records , Make sure that the gap between index records remains unchanged .
- Row lock : By index .
2.2、 How to open the lock
insert、update、delete By default, it locks .
select The statement that needs to be displayed will be locked :
Add shared lock :lock in share mode
Add and exclude the lock :for update
2.3、 When to lock the watch
When modifying data using an index as a search condition , Will use row lock , Otherwise, watch lock is used .
2.4、 What kind of problem does intention lock solve
It mainly solves the problem of coexistence of table lock and row lock , Intent lock resolves the conflict between table lock and previous row lock , Avoid scanning the system consumption of the whole table in order to determine whether the table has row lock . The row lock should be added with intention lock before locking . Intention lock is a kind of table lock .
3、MVCC
stay MVCC Concurrency control , There are two types of read operations : Read the snapshot (snapshot read) And current reading (current read). Read the snapshot , Read the visible version of the record ( It could be a historical version ), Don't lock it . The current reading , The latest version of the record is read , also , The record returned by the current read , It's locked , Ensure that other transactions do not modify this record concurrently .
4、 engine
4.1、InnoDB And myisam The difference between
- InnoDB Support row lock , Business , Foreign keys .
- InnoDB Do not save the specific number of lines , perform select count(*) from table Scan the whole table when .
- InnoDB Support mvcc myisan I won't support it .
4.2、InnoDB By what means is the row lock of
InnoDB Row locking is achieved by locking the index entries on the index ,InnoDB This row lock implementation feature means : Data is retrieved only through index conditions ,InnoDB To use row level locks , otherwise ,InnoDB Table locks will be used .
4.3、InnoDB What is the way to solve unreal reading
Use Next-key lock Solve unreal reading .
next-key lock It's a line lock +gap lock Clearance lock to achieve . Row locks are exclusive locks on a single index record , Clearance lock is to lock a range , But not the record itself . Prevent multiple transactions from inserting records into the same scope .
5、 Copy table
- create table a like b
Copy only structures, not data . - create table a as (select * from b)
Replication structures also copy data .
6、 Master slave replication process and principle
- Any changes will be written to the primary server binlog in , Start one from the server I/O thread Connect to the master server to read binlog, Write to local from the server relaylog( relay logs ) in , Open a from the server sql thread Regular inspection relaylog, If you find any changes, immediately execute the updated content on this machine .
- Three modes of master-slave replication
- sql Sentence copying : All operations of the database sql It's all written in binlog in .
- Row copy : Every change of data will be written to binlog in .
- Mixed mode :sql sentence + Row copy ,mysql Automatic selection .
- Global transaction ID Realize the principle of replication
When the master node updates the data, it will generate GTID It was recorded that binlog in , From the node I/O Thread gets changed binlog Record your own relaylog in , From node's sql The thread from relaylog In order to get GTID, And then from my own binlog Search for , If you find it, it means GTID Has been executed , Then ignore , If there is no record , From relaylog Execute the GTID And record to binlog in .
7、 Dual main architecture
Two sets of mysql Service is master-slave ,masterA Responsible for data writing ,masterB spare , Two masters and slaves pass through keepAlived High availability , All slave servers and masterB Master slave synchronization .
8、 Semi synchronous replication and parallel replication
- Semi synchronous replication solves the problem of data loss .
- Parallel replication solves the delay problem of master-slave replication .
Semi synchronous replication ensures that transactions are written in the primary database binlog After that, you need to return a ack To the client . Make sure that after the transaction is committed binlog Transfer to at least one slave Library , There is no guarantee that this transaction will be used up from the library binlog, Performance degradation , Response time is getting longer .
Parallel replication refers to opening multiple sql Thread parallel application binlog.
9、mysql in char And varchar The difference between ;varchar(20) and int(20) difference
- varchar It's getting longer ;char The length is fixed .
- varchar(50) Represents the maximum amount that can be stored 50 Characters ;int(20) Is the length of the displayed character , Does not affect internal storage .
10、truncate\delete\drop difference
Different scenarios :
- truncate: Clear table data .
- delete: Delete table data , One or more lines .
- drop: Delete table .
11、 Why use indexes
Index is used to improve search efficiency , Create a unique index to ensure the uniqueness of the data .
- hash Indexes : It's a hash Table storage data structure , according to key You can directly find value, It can only be full =、in、 != Query for , Scope search hash The index is useless .hash Index cannot sort with index . In the union index hash An index cannot be queried with partial index building . Because it's a union index and it's calculated together hash value , Not separately hash value .
- B+ Tree index : The leaf node keeps a complete data record ,B+ Tree disk is cheaper to read and write , More stable query efficiency . The low cost of reading and writing is because non leaf nodes do not store data , Query efficiency is stable because every query has to go from the root node to the leaf node .
The more indexes, the better , Because the index is up select But it's less efficient insert And update The efficiency of , because insert and update Maintain the index dynamically , Indexes also take up a certain amount of physical space , Too many index columns are not a good choice either .
12、 What is a clustered index
There is only one cluster index in a table , Data and index are stored in one place , Find the index and find the data .
13、 What is an overlay index
select The data columns of can be obtained only from the index , You don't have to read rows of data , In other words, the query column can be covered by the created index .
14、 The data structure of the index
Use B+ Trees , stay InnoDB Each index in is a B+ Trees , The primary key index is called a cluster index , Other non primary key indexes are called secondary indexes . The leaf node of the primary key index keeps a record of the entire data row , The leaf node of the secondary index stores the primary key value .
Query the primary key value of the result according to the secondary index , Then according to the primary key value, find the record in the primary key index .
15、 The leftmost prefix of the index
- If you don't start with the leftmost column of the index , Index cannot be used .
- The union index is sequential , Some columns of a federated index cannot be skipped .
- If there is a range query for a column in the query column , Then all the columns on the right cannot be optimized by index , Because all the columns on the right are out of order .
16、 When the index is not applicable 、SQL Optimize
- There is... In the condition or.
- Does not conform to the leftmost prefix principle .
- like Condition to % Start .
- There is a type cast .
- There is something in the condition that is not equal to .
- Function operations in conditions , Expression operation .
- In the condition of null Value judgement .
- in and not in.
- mysql It is estimated that full table scanning is faster than indexing , No index .
17、 What are the three paradigms of database
- First normal form : Primary key required , And each field is required to be atomic and non separable .
- Second normal form : Require all non primary key fields to be fully dependent on primary keys , Can't generate partial dependence .
- Third normal form : There is no transitive dependency between all non primary key fields and primary key fields
18、in and exist The difference between
in It's about making the exterior and the interior hash Connect , and exist It's external watch loop loop , Every time loop Loop and then query the inner table .
19、 Implementation plan
- id: Express selec Statement operation table order ,id The bigger the priority is , The first to be executed .
- select type Represent each select The type of clause
- simple The query does not contain subqueries or union
- primary Outermost query
- subquery select or where Subquery
- derived stay from Subqueries in the list
- union the second select Appear in the union And then it's marked as union
- union result from union Table to get the result select
- type Connection type
- system The query table has only one row
- const sql The query is based on the index and finds
- eq_ref Use primary key or unique index , And there's only one result
- ref Use a non unique index to find , Can scan multiple records
- range Index range lookup , The index searches according to the specified range . Common in between > < etc.
- index Traverse index , Just scan the index tree , Instead of a database table .
- ALL Scan the full table data
sql The statement must at least reach range Level
- table The query table
- possible key The index contained on the query column
- key Index name used , If you don't use an index, it's NULL
- ref
- rows Number of scanning lines Estimated value
- extra Detailed instructions using index Indicates that an overlay index is used ,using where Said the use of where Clause to filter the result set using tempory Using a temporary table using filesort Using file sorting ( Cannot sort with index )
20、 Sub database and sub table
- Split Vertically
Vertical sub table : Will not be commonly used fields , Split the larger data fields into the extended table , Avoid problems caused by too much data during query .
Vertical sub database : For a system, it is divided according to the business module . - Horizontal split A table is divided into multiple tables , A library is divided into multiple libraries .
Vertical segmentation solved IO bottleneck , Horizontal slicing reduces the reading and writing pressure of a single table .
The method of sub database and sub table :
- Query segmentation , take ID And Ku's mapping Separate records in a library , Advantage is :Id And Ku's mapping The algorithm can be modified at will . The disadvantage is the introduction of additional single points ,
- Range segmentation , For example, according to the time area or scope of segmentation , advantage : The size of a single table can be controlled , Natural horizontal expansion , Can't solve several write bottlenecks .
- Adopt consistency hash Segmentation .
20.1、 Transaction consistency issues
Distributed transactions :2PC\TCC\ Business compensation .
Final consistency : Systems that don't require real-time consistency , The final consistency can be achieved by transaction compensation .
For example, check the reconciliation of data in one day , Compare based on logs , Regularly synchronize with standard data sources .
20.2、 Paging across nodes 、 Sort 、 function
First, paginate the data in the partition nodes of different nodes 、 Sort 、 Functions, etc , Then summarize the result sets returned by different partitions , And deal with it again , Finally, it is returned to the user .
20.3、 Cross Library join Several schemes of
- Use the dictionary table , Keep a copy of this type of table in each library , It's usually data that doesn't change .
- Field redundancy , Redundant fields that need to be associated .
- Assemble in business code .
Copy table , Redundant fields need to solve the problem of consistency , It can be updated regularly .
20.4、 Uniformity hash
Uniformity hash Can only better avoid the data migration problem in the process of capacity expansion , But it can't completely avoid the problem of data migration .
Suppose by 2^32 Points make up a point hash Ring , First, the server will be hash, Distribution in hash On the ring , Put the data key Use the same hash Algorithm , To calculate the hash Value and distribute it to hash On the ring , The first machine encountered clockwise is the server where the data is stored . Virtual nodes can be introduced to solve the problem of consistency hash Data skew problem of . Uniformity hash Make data migration to a minimum , And the data distribution is relatively uniform .
20.5、 Smooth expansion 、 Migration free expansion
Adopt double expansion strategy , Avoid data migration , Data of each node before expansion , Half of them will be migrated to a new node . First set it into a master-slave structure , Then delete the master-slave structure after data replication , Modify routing rules , And then delete the redundant data .
20.6、 Commonly used database and table middleware
- cobar
- mycat
- sharding-jdbc
21、 only ID
- uuid: Locally generated , Efficient , But the length is longer , And out of order .
- Snowflake algorithm : Time stamp + machine id+ Serial number Increasing trend does not rely on third-party systems , Both stability and efficiency are relatively high , It's time dependence .
- database Auto increment Multiple machines set different step sizes ,N Set the step size to N, The initial value is from 0-N-1, It can guarantee multiple machines Id Different .
- redis Generate Id: Provided by itself incr increby Auto increment atomic command of , Can guarantee id Generating order .
- US mission leaf-snowflake Need to use zookeeper.
Twelve 、netty Arrangement of knowledge points
1、netty What is it?
netty Is based on nio An asynchronous event driven network communication framework is developed , contrast BIO Increased high concurrency .
2、netty Characteristics
- High concurrency : be based on nio.
- Fast transmission :netty The transmission depends on zero copy technology , Reduces unnecessary memory copies , Improve transmission efficiency .
- Package it : It's packaged a lot of nio Operation details of , Provides an easy to use interface .
3、 What is? netty Zero copy of
stay OS On the level of Zero-copy To avoid in User mode (User-space) And Kernel mode (Kernel-space) Copy data back and forth between .Netty Of Zero-copy It's completely in user mode (Java level ) Of , More inclined to optimize data operations .
- buffer buffer In out of heap direct memory socket To read and write , There is no need to make a second copy of the byte buffer .
- Netty File transfer using transferTo Method , It can send the data of the file buffer directly to the target Channel, Avoid the traditional through the loop write Memory copy problem caused by mode .
4、netty Application scenarios of
- rpc frame -dubbo.
- rocketmq.
5、 Non blocking IO Application scenarios of
rpc frame dubbo thirft
redis
6、netty What is the performance of high performance
- Use nio
- Zero copy
- High performance serialization protocol protobuff
7、netty The components of
- channel
- channelfeature
- eventloop
- channelhandler
- channelpipline
8、netty Thread model of
Netty adopt Reactor The model is based on the multiplexer receiving and processing user requests , Two thread pools are implemented internally ,boss Thread pool and work Thread pool , among boss The thread in the thread pool is responsible for processing the request accept event , When receiving accept Event request , Put the corresponding socket Package into a NioSocketChannel in , And to work Thread pool , among work The thread pool is responsible for the request read and write event , By the corresponding Handler Handle .
9、BIO\NIO\AIO The difference between
- bio One connection, one thread , When the client has a connection request, the server needs to start a thread for processing . High thread overhead .
- nio One request, one thread , But the connection requests sent by the client are registered on the multiplexer , The multiplexer polls the connection to have I/O Start a thread to process when requested .
- aio A valid request, a thread , Client's I/O All requests were made by OS First complete and then inform the server application to start the thread for processing .
10、BIO And NIO The difference between
- BIO It's stream oriented NIO It's buffer oriented
- BIO It's blocked NIO It's non blocking
- BIO No, selector NIO Yes selector
- BIO The flow is unidirectional NIO channel It's two-way
11、 What is the problem of sticking and unpacking
The size of bytes written by the application is larger than the size of the socket send buffer , There will be unpacking , The application writes less data than the socket buffer size , The network card sends the data written by the application many times to the network , This will cause sticking ;
12、netty How to solve the problem of sticking and unpacking
- Message fixed-length
- Add special character segmentation at the end of the package
- Messages are divided into header and body
13、 ... and 、redis Arrangement of knowledge points
1、Redis How to synchronize data between master nodes
Double main structure , Two redis They are masters and followers of each other , Then the master-slave synchronization is used to realize the data synchronization between the two master nodes .
2、Redis Master slave data synchronization
- Establishing a connection
Use from node slaveof Set up... With the master node socket Connect , The slave node will send ping Command to make the first request , If you return pong It's not , To break off socket Reconnection , If the master node returns pong explain socket The connection is normal . - Data synchronization
Send from node to master node psync command , Start syncing . It can be divided into full replication and partial replication .
Full replication is the master node fork Sub thread , Generate in the background RDB file , And use a copy buffer to record all write commands from now on . When bgsave After the execution is complete , take RDB The file is sent to the slave node , From the node first clear their old data , Reload the RDB file . The master node sends all commands in the copy buffer to the slave node , Execute these commands from the node , Update your status .
Partial replication means that both the master and slave nodes record a copy offset , It is mainly used to judge whether the master-slave database state is consistent , The slave node requests full replication if it has never replicated data , Otherwise send psync Command will send the master node runid and offset Request partial copy , The master node is based on runid and offset To determine whether to make partial or full replication . If the master node runid And sent from the node runid Same and sent from node offset It's still in the copy buffer , This part of the copy buffer will be sent to the slave node . The slave node will update its own state and offset. - Command propagation ( Between master and slave nodes there is ping replconf ack Order mutual heartbeat detection )
After data synchronization is complete , The master-slave node enters the command propagation stage . In this stage, the master node sends its own write command to the slave node , Accept commands from the node and execute , So as to ensure the data consistency of master-slave nodes .
3、Redis High availability solution
3.1、 Sentinel mode
Sentinel mechanism is to use one or more sentinel instances to form a system to manage redis The master-slave server of , Realize fault detection 、 Auto fail over 、 Configuration center 、 Client notification .
- Fault finding : monitor redis master and slave Whether the work is normal .
- Auto fail over :master After downtime ,slave Upgrade to master.
- Configuration center : If a fail over occurs , notice client Client new master Address .
- Client notification : Monitored redis After the node has a problem , The sentry passed API Notify the administrator or application .
The role of a sentry :
master Abnormal detection of , Fail over after discovery of anomalies , Put one of them slave As master, Put the previous master As slave. Modify the information in the configuration file .How the sentry works :
Every time 10 Second, each sentinel will get the master-slave node's info, The function is to discover from nodes , Confirm the master-slave relationship .
Pass every two seconds master Of pub sub Mechanisms exchange information , Including its own node information and the information of each node . If you find out that master The version is lower than the others master Version of , Update the current master Version of . It's also used for Sentinels' mutual discovery .
Every time 1 Seconds for other sentinels and redis Nodes do ping operation . Mainly for heart rate detection .
If the primary node is found to be down , Think subjective downtime , Send a message to the other sentinels , If most people think the node is down , We think that the objective downtime .
The sentinel will vote after the objective outage , Choose a sentinel to do failover.failover Will elect one slave Nodes as new master node , And update the configuration file , send out slaveof Command to complete the failover .
slave Election committee judgment : And master Number of disconnection times of ,slave The priority of the , Subscript for data replication offset, process id.
There are three parts to fail over :
- Select a slave from all slaves of the offline master service , Make it the main service .
- Change all slave services of the offline master service to copy the new master service .
- Set the offline master service as the slave service of the new master service .
3.2、Redis Master-slave
It mainly uses the principle of master-slave synchronization Redis High availability .
3.3、Redis Partition cluster mode
Introduced hash The concept of slot , It is divided into 16384 individual hash Slot . Use crc16 hash Algorithm , Will a key Mapping to 16 Digit number . Map physical nodes to hash Above the trough .
Each node in the cluster communicates with other nodes . Each node maintains the information of all nodes . Nodes pass through gossip Protocol to exchange status information , By voting slave To master Handoff . Only master The switch can only be performed after the objective offline .
The slave node is only used as a standby node , Don't offer requests , Just fail over operations .
The client can use jediscluser, Local cache node Node information .
4、 What is subjective downtime 、 Objective downtime
- Subjective downtime SDOWN Refers to a single sentinel instance making offline judgment on the server .
- Objective downtime ODOWN Refers to multiple sentinel instances ( More than half ) Make offline judgment on the server .
5、Redis Persistence scheme
- RDB Persistence take redis Data periodic dump Persistence to disk .
- AOF Persistence take redis The operation log is written to the file by appending .
RDB Persistence will fork A child thread , First write the data to a temporary file , Replace the final file when all are written successfully .
AOF Record the server's write in the form of log 、 Delete operation , Save as text . High data security .
redis There are three ways to synchronize : A second synchronous everysec、 Every change is synchronized always and Out of sync no.
6、Redis Data obsolescence program
When redis Data culling is performed when memory reaches its maximum
- volatile-lru From the set expiration time of key To eliminate the least recently used key.
- volatile-ttl From the set expiration time of key The first to expire key.
- volatile-random From the set expiration time of key in To be eliminated at random .
- allkeys-lru From all key Choose the least recently used key Eliminate .
- allkeys-random From all key In random elimination .
- no-envication Ban data obsolescence .
redis The maximum use of memory and data elimination strategy can be based on maxmemory and maxmemory-policy To configure .
7、Redis Data expiration policy
- Delete periodically Get some at random on a regular basis key Judge whether it is overdue
- Lazy deletion visit key Temporal judgment key Is it overdue
8、 Why? Redis fast
- Pure memory operation .
- Single thread reduces thread context switching .
- Use non blocking IO, multiple IO Reuse .
9、Redis Multiplexing principle
utilize select、poll、epoll You can monitor multiple IO The power of events , The current thread will be blocked when idle , When one or more streams have IO When an event is , Wake up from blocking , So the program will poll all the streams ,epoll Only polling the stream that actually emitted the event , And only process the ready streams sequentially , This avoids a lot of useless operations .
Multichannel refers to multiple network connections , Reuse refers to reusing the same thread .
IO Multiplexing is event driven .
10、Redis Data structure of
10.1、string
Internal storage :
- Digital usage int.
- Other uses SDS.
10.2、list
Internal storage :
- ziplist All strings are less than 64 byte , Quantity less than 512.
- linkedlist Double linked list .
10.3、hash
Internal storage :
- ziplist Quantity less than 512, All elements are less than 64 byte .
- dict.
10.4、set
Internal storage :
- intset All elements are integers , The number of elements is less than 512.
- dict.
10.5、sort set
Internal storage :
- ziplist The number of elements is less than 128 And the length is less than 64.
- skiplist.
11、Redis hash Underlying principle
dict Dictionaries ,hash The algorithm uses murmurhash, Conflict resolution uses chain addressing ,rehash Use two hash surface ,hd[0] and hd[1]. Progressive type rehash, For the first ht[1] Allocate space for dict Hold two hash Table references , Maintain an index counter ,rehashidx, Set its value to 0 Express rehash Start , stay rehash period , Every time the dictionary crud operation , Will be ht[0] Data in rehash To ht[1] in , And will rehashidx increase 1, When all ht[0] Transfer all data in to ht[1] In the middle of the day , take rehashidx Set to -1, take ht[1] The pointer to the ht[0],ht[1] Set as null.
ziplist It was developed to save memory , A sequential data structure consisting of a block of contiguous memory , Each compression node can hold an array of bytes or an integer value .
Each of them entry The node head saves the node length information before and after , Realize the function of bidirectional linked list .
Use when there is little data ziplist Data is often used dict
All elements are less than 512, And the size of each element is less than 64 Byte usage ziplist Otherwise use dict.
12、skiplist
A skip table is an ordered data structure , By maintaining pointers to multiple nodes on each node , In order to achieve the purpose of fast access . The jump table consists of many layers , Each layer is an ordered list , The bottom list contains all the elements . Randomly generate layers .
13、ziplist
ziplist It was developed to save memory , A sequential data structure consisting of a block of contiguous memory , Each compression node can hold an array of bytes or an integer value . Each of them entry The node head saves the node length information before and after , Realize the function of bidirectional linked list .
14、 How to use it Redis Implement distributed locks
Use SETNX Get the lock , And use expire Command to add a timeout to the lock , After the timeout period, the lock will be released automatically , Avoid deadlocks . The lock value It's randomly generated uuid, Used to judge when releasing a lock . Release the lock by uuid To determine if it's time to lock , If so, use delete Operation to release .
But there is a problem , If the thread execution time is too long, more than the lock expiration time will cause more than one thread to own the lock , Causes distributed locks to fail .
15、 How to use it Redis Cluster implements distributed locks
redlock Algorithm :
Get the current timestamp , And in this way N Nodes acquire locks , It's the same as a stand-alone lock acquisition . Calculate the entire lock acquisition time , If more than half of the nodes get locks , And it doesn't exceed the lock timeout , The lock is obtained successfully . If the acquisition fails, release the lock to all nodes .
If the master node goes down in the middle , Asynchronous replication is not synchronized yet , At this time, multiple clients may lock successfully at the same time .
16、Redis How transactions are implemented
adopt multi、discard、exec、watch Four commands to achieve redis The business of . Use multi Open transaction , Yes exec Trigger commit transaction ,discard Used to cancel a transaction .
watch To monitor any number of keys before a transaction is opened , If any monitored key is modified by the client , Then the whole transaction is not executed . When the client ends the transaction , Whether the transaction succeeds or fails ,watch Key and client related information will be deleted .
17、Redis Of pub\sub How the mechanism works
adopt publish and subcribe Command to implement subscription Publishing .
redis One was maintained pubsub_channels Dictionary , Dictionaries are used to hold information about subscription channels , The key to the dictionary is the channel name , The value of a dictionary is a linked list , The linked list stores the clients who subscribe to this channel . Client calls suncribe On command ,redis Put the client and the channel you want to subscribe to in pubsub_channels Connect .
subcribe channel1 channel2
publish channel1 message
Use unsubcribe channel1 Unsubscribe from the channel . from pubsub_channels Delete the corresponding client information in the channel .
A subscription to a pattern is a regular expression .publish Of message Not only to a certain channel , If there's a pattern that matches the channel , Then the client who subscribes to this pattern will also receive a message . Bottom use pubsub_patterns The linked list is saved , Every node has saved patterns And subscription clients , Just walk through the whole list to find out which clients to send .
psubcribe patterns For subscription mode
punsubcribe patterns For unsubscribe mode
18、Redis and Memcache What's the difference?
- redis Support multiple data types ,memcache Only strings are supported .
- redis Support persistence ,memcache I won't support it .
- redis Support distributed ,memcache I won't support it .
19、 Cache avalanche
Large area cache failure occurs at the same time , Lead to DB overpressure .
terms of settlement :
- Consider the synchronous way to read and write the database .
- Second level cache ,A For the original cache ,B Cache for copy , When A Access to when disabled B
- adopt hystrix Limit and degrade the request .
- Add a random value to the original expiration time .
- Set an expiration flag for the cache key, This key Is half the cache expiration time , Judge this first key Is it overdue , If it expires, refresh the cache asynchronously .
20、 Cache penetration
If the mass request query does not exist key, These requests will fall on DB On , Lead to DB High pressure
- cache null value , It doesn't solve the problem at all , If you use a different key Concurrent access , It's not working
- The bloon filter .
The realization principle of Bloom filter : One bit Add a group of hash Function composition , To a key Conduct K Time hash, Mapping to bit Array of K A little bit , Will this K Points are stored as 1, Next time you come in , Do the same thing , Check this out K Whether all the bits are 1, One of them is 0 Return null value .
21、 Cache breakdown
Hot data set failure
- Never expired data settings .
- Add mutex lock , Ensure that the first request after cache invalidation hits the database , Other requests access the cache after the first request writes data to the cache .
22、 Hot data
The frequency of data access in a timing period .
23、 How to solve the consistency of distributed cache
Cache-Aside-pattern:
- invalid
The application starts with cache Take data from , Didn't get ( Data band expiration time ), Then take the data from the database , After success , Put into cache . - hit
Applications from cache Take data from , Get the data and return . - to update
First update the data to the database , After success , Then clear the cache data .
24、 Caching algorithm
LRU Recently at least use Using linked list +hashmap Realization , Every time you check hashmap Whether there is , To be is to return , And add the node to the head node of the linked list . If it doesn't exist, add the end node of the list , Each elimination is carried out from the end node of the linked list .
LFU The least used Use two map To implement , One map Record key value the other one map Record key Visit frequency and time of visit . Eliminate the least used key.
FIFO fifo , Use linked list to implement , Elimination from the head , Tail add .
fourteen 、Spring Interview knowledge points arrangement
1、 Transaction propagation behavior
- require If there is a transaction, add , Otherwise, create a new transaction .
- supports If there is a transaction, add , Otherwise, no transactions are used .
- mandatory If there is a transaction, add , Otherwise, throw it out of order .
- require_new Create transaction , If there is a current transaction, the current transaction will be suspended .
- not_support Run in a non transactional manner , If a transaction currently exists, suspend .
- never Run in a non transactional manner , If there is currently a transaction, an exception is thrown .
- nested If there are currently transactions , The transaction is created as a nested transaction , If there is no current transaction , Create a new transaction .
2、 Transaction isolation
- default Use the isolation level set by the database
- ReadUncommitted Dirty reading 、 It can't be read repeatedly 、 Fantasy reading .
- ReadCommitted Non repeatable reading appears 、 Fantasy reading .
- RepeatableRead Phantom reading .
- serializable Serial execution .
3、Spring How transactions are implemented
adopt AOP To implement declarative transactions ,Spring At startup, it parses and generates relevant bean, At this time, you will see the classes and methods of the relevant annotations , And generate proxies for these classes and methods , And according to @Transactional The relevant parameters of configuration injection .
Be careful :
- @Transactional It can only be modified public Method .
- Self calling method transactions do not take effect , If you want a transaction to work , What must be displayed is called through the proxy object .
- The database engine must support transactions .
- Rollback when an exception is caught .
4、 A dynamic proxy
JDK The dynamic proxy requires that the class must implement the interface ,cglib Need to introduce cglib Class library of .
4.1、JDK A dynamic proxy
JDK The core of dynamic proxy is invocationHandler Interface and Proxy class . The proxy class must implement the interface . Then implement invocationHandler, Get proxy objects by reflection , When the proxy object method is called , Do related operations before and after the method .
4.2、cglib Dynamic proxy for
By implementing MethodInterceptor Interface , rewrite interceptor Method , Similar to the callback method , When you call a method of a proxy object, you call interceptor Method , stay interceptor Methods to do the relevant operations .
5、SpringAOP
AOP It is based on dynamic proxy . If the proxy object implements the interface , So use JDK Dynamic proxy generates proxy objects , Otherwise use cglib Generate proxy objects .
6、SpringIOC
SpringIOC Inversion of control , Objects are all created by spring Container to manage , Decouple objects , The bottom layer is realized by reflection acquisition ,SpringIOC Responsible for creating objects , Management object , Integrating object and object configuration .
7、Bean Scope of action
- singleton Default scope , Single case .
- prototype Every time you inject or pass through Spring The context fetch instance is recreated once .
- request Every time http Requests are created once .
- session Every session Will be created once .
8、Bean Life cycle of
- establish Bean example .
- Setting property values .
- If it's done BeanNameAware Interface , call setBeanName Methods .
- If it's done BeanFactoryAware Interface , call setBeanFactory Method .
- If it's done ApplicationContextAware Interface , call setApplicationContext Method .
- If it's done BeanPostProcessor Interface , Call postProcessBeforeInitialization Method .
- If it's done InitailizeBean Interface , Call afterPropertiesSet Method .
- stay bean In the configuration file of init-method, Call the specified method .
- If it's done BeanPostProcessor Interface , Call postProcessAfterInitialization Method .
The destruction Bean When , If it's done DisposableBean, execute destroy Method .
9、SpringMVC working principle
- Client requests to DispatcherServlet.
- DispatcherServlet Call according to the request information handlerMapper, Find the corresponding handler.
- take handler Leave it to handlerAdapter Handle .
- handlerAdapter according to handler Find specific controller To deal with , And back to ModelAndView object .
- DispatcherServlet take ModelAndView Object is sent to ViewResolver To analyze .
- ViewResover It will return the corresponding view to DispatcherServlet, And then back to the user .
10、SpringMVC Start process
Web Container initialization : Initialize first Listener, Then initialize Filter, Finally initialize Servlet.
initialization Listener When , You usually use ContextLoaderListener class ,Spring Will create a WebApplicationContext Object as IOC Containers , Global read wen.xml Configured in ContextConfigLocation In the parameter xml To create the corresponding Bean.
Listener After initialization, it will be initialized Filter, Finally initialize Servlet.Servlet Will create a current Servlet Of IOC Sub containers of , And will just generate WebApplicationContext As a parent container , Read Servlet initParam Configured xml, And initialize loading related Bean.
11、BeanFactory and AppliacationContext What's the difference?
ApplicationContext yes BeanFactory Sub interface of , Yes BeanFactory It has been extended . On the basis of it, we add AOP、 Event communication 、MessageResource( internationalization ).
BeanFactory yes IOC The core interface of the container , Used to package and manage all kinds of Bean.
BeanFactory It's delayed loading , Only from the container Bean When , To instantiate .
12、SpringMVC And SpringBoot The difference between
SpringMVC Provides a slightly coupled way to develop web application .SpringBoot Automatic configuration is realized , Reduce the complexity of project construction .
13、Hystrix
Service failure and degradation , Every request is Hystrix One of the Command, Every Command Will report the status to the fuse , Fuse will maintain and count these data , And according to these data to judge whether the fuse is open , If the fuse is on , Request a quick return , Try to half open the fuse at intervals , Put in a part of the request , Take a health check , If the check is successful , Fuse off , Otherwise keep opening .
14、 How to solve circular reference
- Constructor loop dependency
Put the currently created Bean Record in cache , If you create Bean You find yourself in the cache , False report BeanCurrentlyInCreationException, Denotes cyclic dependency . For created bean Will be removed from the cache . - setter Cyclic dependence ( Only singleton mode works ,prototype It won't do caching ) Use level 3 caching :singletonFactories( Singleton objects entering the instantiation phase )、earlySingletonObjects( Objects that are instantiated but not initialized )、singletonObjects( The singleton object that completes initialization ).
Spring The solution to circular dependency _lkforce-CSDN Blog
15、@Autowired And @Resource The difference between
- @Autowired The default is byType For injection ,@Resource yes byName For injection .
- @Autowired It can be set to require attribute , If true You have to inject , If it is false You can not inject .
- If it is @Autowired, It can be used name And @Qualifier In combination with .
- @Resource You can specify the injection method .
16、@Component And @Bean The difference between
@Component Annotation based on class ,@Bean Method based .
17、 Declare a class as Spring Of bean What are the annotations for
@Componet: General notes , Any class can be marked as Spring bean.
@Repository: Persistence layer ,DAO layer
@Service: Service layer .
@Controller: Controller layer
These four notes are in org.springframework.stereotype It's a bag .
18、Spring The implementation principle of singleton
Using the singleton registry to achieve , The registration form is ConcurrentHashMap.
19、SpringIOC Injection mode of
- Constructor Injection
- setter Inject
- Annotation injection
20、Spring Container and SpringMVC Containers and Web The relationship between containers
Spring The container is SpringMVC Parent container of , The child container can directly use the parent container's bean, Such as :Controller In the injection Service.Web The container includes Servlet、Filter、Listener etc. , and Spring And SpringMVC Container independent , When Web You want to use Spring Medium Bean when , Need to pass through ServletContextEvent obtain WebApplicationContext perhaps ApplicationContext, And then you can get Bean 了 .
A detailed reference :spring Container and springmvc Containers , as well as web The relationship between containers - Hai Xiaoxin - Blog Garden
21、SpringBoot @Condition Conditions for assembly
Suppose an interface has multiple implementations , All by Spring To manage , however Spring It's not clear which class to load into the container ,@Conditional The function of , It's under different conditions , Guide loader , What to build bean Add to ioc Containers .
A detailed reference :springboot Conditions for assembly - Simple books
22、Spring For the same name perhaps id Of bean To deal with
When there are too many developers for a feature , It will happen that the same name or... Is configured in the configuration file or annotation ID Of Bean, Of course, their internal properties may be different , When Spring When loading , The latter will cover up the former , If you will DefaultListableBeanFactory Attributes of a class allowBeanDefinitionOverriding Set to false, Error will be reported when starting , Easy to locate the problem .
A detailed reference : solve spring In different configuration files in name perhaps id same bean Possible problems _zgmzyr The column -CSDN Blog
23、Controller In the injection Request object
Controller You can inject HttpServletRequest Objects? ? The answer is : Yes , This leads to a problem ,Controller Is in SpringMVC Initializes... Loaded into the container , and HttpServletRequest Every request is different ,Spring How to deal with it , And how to ensure thread safety ? The answer is : Using dynamic proxies +ThreadLocal technology . When the proxy object is called , Will eventually get RequestContextHolder Medium ThreadLocal In the member variable Request object . So this Request The object is Spring When was it put in ? The answer is : stay SpringMVC Of DispatcherServlet Parent class of FrameworkServlet Of processRequest Method .
A detailed reference : stay SpringMVC Controller In the injection Request Member domain - abcwt112 - Blog Garden
spring bean In the injection HttpServletRequest Thinking about member variables - Simple books
24、Web Medium filter obtain Spring Medium Bean
Need to get WebApplicationContext , And then you can get bean 了 .
A detailed reference :filter In order to get spring bean - Chenxi - Blog Garden
25、Dubbo How to inject Spring Medium Bean
Dubbo On initialization , How to get Spring In container Bean Well ?
Use dubbo-spring when ,ReferenceBean and ServiceBean All of them are implemented ApplicationContextAware, In the callback method ApplicationContent Pass it on to the extended factory SpringExtensionFactory. such bean You can go to Dubbo In the . The injection method and principle refer to the following article : How to be in filter etc. dubbo Inject from the management component spring Of bean - Simple books
dubbo How to use it spring bean - Simple books
15、 ... and 、zookeeper Arrangement of knowledge points
1、zookeeper What is it?
Open source distributed application coordination service .
2、zookeeper What is offered
- file system
- A notification mechanism
3、zookeeper What did you do
- Naming service utilize zk Create a global path , The global path is unique , As a name, point to the service provider address, etc .
- Configuration Management , Put the configuration information of the program in znode below ,znode To transform by watcher The mechanism notifies the client .
- Cluster management .
- Distributed lock .
4、zookeeper How to implement distributed locks
The distributed lock is acquired in locker Create a temporary order node in the directory , Delete the temporary node when the lock is released .
Client connection zookeeper, And create a temporary node in the directory , Judge whether the temporary node created by yourself is the smallest among the nodes , If so, the lock is considered to have been obtained , Otherwise, listen to the change message of the child node just in front of itself , After getting the change message , Repeat the steps above , Until you get the lock . After the execution of the business code , Delete temporary from node .
Third party tools curator Distributed locks can be used directly .
5、zookeeper Notification mechanism of
client End to end znode Build a watcher event , When it's time to znode When something changes , these client Will receive zk The notice of , then client According to znode Change to make business changes, etc .
register watcher getData、exists、getChildren
Trigger watcher create、delete、setData
The notification mechanism is not permanent , It's disposable , Need to use third-party tools to achieve duplicate registration .
6、zookeeper There are several node types
Persistent node 、 Persistent order nodes 、 Temporary node 、 Temporary order node .

版权声明
本文为[Clamhub's blog]所创,转载请带上原文链接,感谢
边栏推荐
- 快快使用ModelArts,零基礎小白也能玩轉AI!
- 阿里云Q2营收破纪录背后,云的打开方式正在重塑
- Programmer introspection checklist
- Character string and memory operation function in C language
- High availability cluster deployment of jumpserver: (6) deployment of SSH agent module Koko and implementation of system service management
- Synchronous configuration from git to consult with git 2consul
- Wiremock: a powerful tool for API testing
- 技術總監,送給剛畢業的程式設計師們一句話——做好小事,才能成就大事
- 基於MVC的RESTFul風格API實戰
- Filecoin最新动态 完成重大升级 已实现四大项目进展!
猜你喜欢


随机推荐
Vue 3 responsive Foundation
Don't go! Here is a note: picture and text to explain AQS, let's have a look at the source code of AQS (long text)
Troubleshooting and summary of JVM Metaspace memory overflow
Character string and memory operation function in C language
Serilog原始碼解析——使用方法
How to select the evaluation index of classification model
中小微企业选择共享办公室怎么样?
合约交易系统开发|智能合约交易平台搭建
在大规模 Kubernetes 集群上实现高 SLO 的方法
(2)ASP.NET Core3.1 Ocelot路由
多机器人行情共享解决方案
hadoop 命令总结
EOS创始人BM: UE,UBI,URI有什么区别?
“颜值经济”的野望:华熙生物净利率六连降,收购案遭上交所问询
[performance optimization] Nani? Memory overflow again?! It's time to sum up the wave!!
事半功倍:在没有机柜的情况下实现自动化
有关PDF417条码码制的结构介绍
Query意图识别分析
数据产品不就是报表吗?大错特错!这分类里有大学问
How long does it take you to work out an object-oriented programming interview question from Ali school?