当前位置:网站首页>Pointnext: review pointnet through improved model training and scaling strategies++
Pointnext: review pointnet through improved model training and scaling strategies++
2022-07-04 19:56:00 【Master Ma】
PointNet++ It is one of the most influential neural architectures for point cloud understanding . Even though PointNet++ The accuracy of has been PointMLP and Point Transformer Wait until the recent network has largely surpassed , But we found that a large part of the performance improvement is due to the improvement of training strategies , That is, data enhancement and optimization technology , And increased model size rather than architectural innovation . therefore ,PointNet++ Its full potential remains to be explored .
In this work , We reexamine the classical model by systematically studying the model training and scaling strategies PointNet++, And provides two main contributions .
First , We propose a set of improved training strategies , Significantly improved PointNet++ Performance of . for example , We show that , Without changing the architecture ,PointNet++ stay ScanObjectNN The overall accuracy of object classification (OA) It can be downloaded from 77.9% Up to 86.1%, Even better than the most advanced PointMLP.
secondly , We will invert residual bottleneck design and separability MLP introduce PointNet++, To achieve efficient and effective model scaling , And to put forward PointNeXt, That is, the next version of PointNets.
PointNeXt It can be flexibly expanded , stay 3D Both classification and segmentation tasks are superior to the most advanced methods .
Thesis title :PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies
Detailed interpretation :
https://www.aminer.cn/research_report/62afdfb27cb68b460fd6c4fa?download=false
icon-default.png?t=M5H6https://www.aminer.cn/research_report/62afdfb27cb68b460fd6c4fa?download=false
AMiner link :https://www.aminer.cn/?f=cs
https://zhuanlan.zhihu.com/p/526818590
This paper re examines the classic PointNet++, And provides two main contributions , And then put forward PointNeXt, performance SOTA! Better performance than the PointMLP、Point Transformer Wait for the Internet , The code is open source (5 God 90+ star)!

PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies
Company :KAUST, Microsoft
Code :https://github.com/guochengqian/pointnext
The paper :https://www.aminer.cn/pub/62a2b6955aee126c0f4d8e79
PointNet++ It is one of the most influential neural architectures for point cloud understanding . Even though PointNet++ The accuracy of has been PointMLP and Point Transformer Wait until the recent network has largely surpassed , But we found that a large part of the performance improvement is due to the improvement of training strategies , That is, data enhancement and optimization technology , And increased model size rather than architectural innovation . therefore ,PointNet++ Its full potential remains to be explored .
In this work , We reexamine the classical model by systematically studying the model training and scaling strategies PointNet++, And provides two main contributions .
First , We propose a group Improved training strategies , Significantly improved PointNet++ Performance of . for example , We show that , Without changing the architecture ,PointNet++ stay ScanObjectNN The overall accuracy of object classification (OA) It can be downloaded from 77.9% Up to 86.1%, Even better than the most advanced PointMLP.
secondly , We will Inverted residual bottleneck design and separability MLP introduce PointNet++, To achieve efficient and effective model scaling , And to put forward PointNeXt, That is, the next version of PointNets.
PointNeXt It can be flexibly expanded , stay 3D Both classification and segmentation tasks are superior to the most advanced methods .
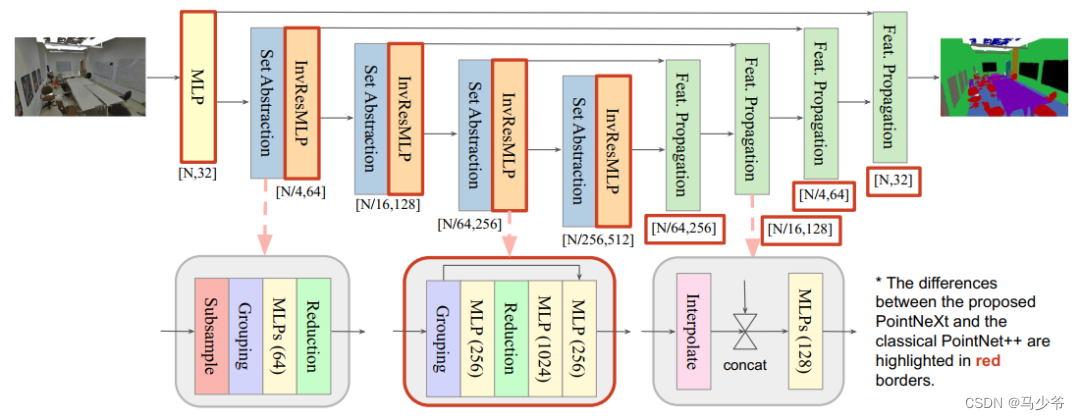
In this section , We showed how to improve through more advanced training strategies and model scaling strategies PointNet++ Performance of . We will introduce them in two sections :
(1) Modernization of training strategies ;
(2) Modernization of network architecture .
Modernization of training strategies
In this chapter , We briefly describe our research methods , Specific training strategies can be seen in the subsequent Ablation Experiment chapter .
Data to enhance
Data enhancement is one of the most important methods to improve the performance of neural networks , and PointNet++ Simple data enhancement combinations such as random rotation are used , The zoom , translation , shake (jitter) And applied to different data sets . Some of the latest methods use stronger data enhancement methods . for example , KPConv Random deactivation during training (drop) Some color information . In this work , We collected common data enhancement methods used in recent methods , The effect of each data enhancement method on each data set is quantitatively studied by superposition experiment . For each data set , We propose a set of improved data enhancement methods , It can be greatly improved PointNet++ Performance of .
Optimization strategy
Optimization techniques mainly include loss functions (loss function), Optimizer (optimizer), Learning rate Planner (learning rate schedulers), And super parameters (hyperparmeters). With the development of machine learning theory , Modern neural networks can be theoretically better ** Optimizer ( Such as AdamW) And a better loss function (CrossEntropy with label smoothing)** Training .Cosine learning rate decay It has also been widely used in recent years , Because compare step decay, It is simpler to adjust parameters and the effect is not bad . In this work , We quantify the effects of each optimization strategy on PointNet++ Influence . alike , For each data set , We propose a set of improved optimization techniques that can further improve network performance .
Modernization of model architecture : Minor modifications → Great improvement
Receptive field scaling
In point cloud network , Use different ball query radius ( Query radius ) Will affect the receptive field of the model , Which in turn affects performance . We find that the initial radius has a great influence on the network performance , And the optimal query radius is different on different datasets . Besides , We find relative coordinates Make network optimization more difficult , Performance degradation . therefore , We propose to use the relative coordinates to query the radius to achieve the normalization :
If there is no normalization , The value of relative coordinates will be very small ( Less than the radius ). This requires that the network can learn to apply greater weight to . This makes optimization difficult , In particular, the regularization method considering the weight attenuation limits the size of the network weight .
Model scaling
PointNet++ The scale of models used for classification and segmentation is smaller than 2M. Now the network parameters are generally 10M above [3,4]. Interestingly , We found that no matter using more SA The module is still larger channel size Will not significantly improve accuracy , But it leads to thoughput A marked decline . This is mainly caused by gradient vanishing and over fitting . In this section , We proposed Inverted Residual MLP (InvResMLP) Module to achieve efficient and practical model scaling . The module is based on SA On module , As shown in the middle of Figure 1 .InvResMLP and SA There are three differences between modules :
- A residual connection is added between the input and output of the module , To alleviate the gradient disappearance problem
- Separable MLP To reduce the amount of calculation , And enhance point by point feature extraction
- introduce invertedbottleneck The design of the , To improve the ability of feature extraction
stay PointNet++ On the basis of InvResMLP And the macro structure changes shown in Figure 1 , We proposed PointNeXt. We will stem MLP Of channel The size is expressed as C, take InvResMLP The number of modules is expressed as B. We PointNeXt The configuration of the series is summarized as follows :
- PointNeXt-S: C = 32, B = 0
- PointNeXt-B: C = 32, B = (1, 2, 1, 1)
PointNeXt-L: C = 32, B = (2, 4, 2, 2)
PointNeXt-XL: C = 64, B = (3, 6, 3, 3)
experiment
stay S3DIS Semantic segmentation ,PointNeXt-XL With mIoU/OA/mACC=74.9%/90.3%/83.0% Beyond Point Transformer obtain SOTA Performance and faster reasoning . stay ScanObjectNN Classification ,PointNeXt-S Beyond the current SOTA Method PointMLP, And the reasoning speed is ten times faster . stay ShapeNetPart Partial segmentation , Widened model PointNeXt-S(C=160) achieve 87.2 Instance mIoU, transcend SOTA CurNet.


Ablation Experiment 

边栏推荐
- SSRS筛选器的IN运算(即包含于)用法
- Swagger suddenly went crazy
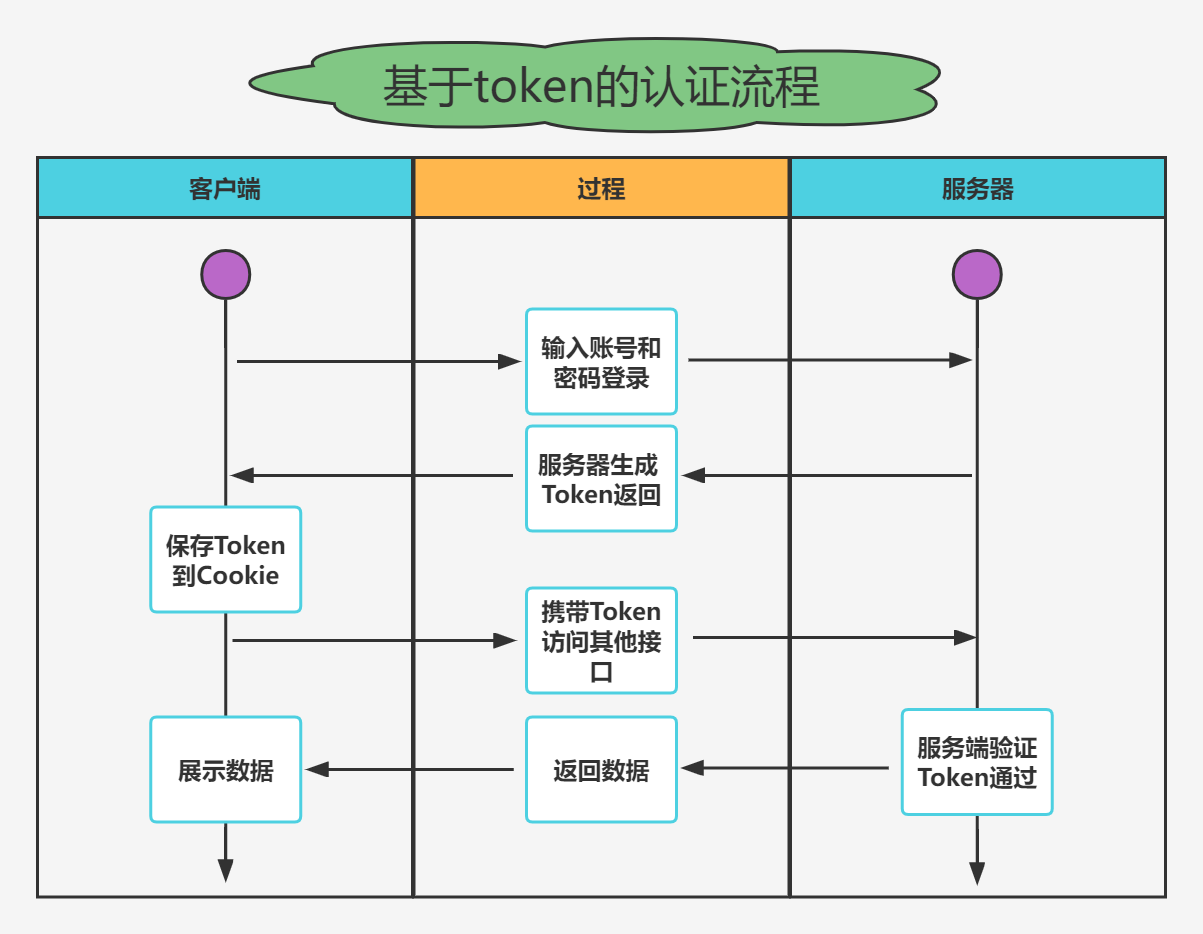
- Actual combat simulation │ JWT login authentication
- 1005 Spell It Right(20 分)(PAT甲级)
- Euler function
- 公司要上监控,Zabbix 和 Prometheus 怎么选?这么选准没错!
- 如何使用Async-Awati异步任务处理代替BackgroundWorker?
- mysql中explain语句查询sql是否走索引,extra中的几种类型整理汇总
- Utilisation de la barre de progression cbcggprogressdlgctrl utilisée par BCG
- Educational Codeforces Round 22 E. Army Creation
猜你喜欢

Master the use of auto analyze in data warehouse
Swagger suddenly went crazy
Actual combat simulation │ JWT login authentication

FPGA timing constraint sharing 01_ Brief description of the four steps

Detailed explanation of the binary processing function threshold() of opencv

Stream stream
c# . Net MVC uses Baidu ueditor rich text box to upload files (pictures, videos, etc.)

Creation of JVM family objects
BCG 使用之CBCGPTabWnd控件(相当于MFC TabControl)

English语法_名词 - 使用
随机推荐
Some thoughts on whether the judgment point is located in the contour
c# . Net MVC uses Baidu ueditor rich text box to upload files (pictures, videos, etc.)
FTP, SFTP file transfer
[QNX Hypervisor 2.2用户手册]6.3.1 工厂页和控制页
1009 Product of Polynomials(25 分)(PAT甲级)
Kotlin condition control
HDU 1372 & POJ 2243 Knight Moves(广度优先搜索)
西门子HMI下载时提示缺少面板映像解决方案
Several methods of online database migration
Actual combat simulation │ JWT login authentication
Data set division
【毕业季】绿蚁新醅酒,红泥小火炉。晚来天欲雪,能饮一杯无?
有关架构设计的个人思考(本文后续不断修改更新)
"Only one trip", active recommendation and exploration of community installation and maintenance tasks
Socket programming demo II
1002. A+b for Polynomials (25) (PAT class a)
Abc229 summary (connected component count of the longest continuous character graph in the interval)
Oracle with as ora-00903: invalid table name multi report error
Kotlin cycle control
1011 World Cup betting (20 points) (pat a)