当前位置:网站首页>一次SQL优化,数据库查询速度提升 60 倍
一次SQL优化,数据库查询速度提升 60 倍
2022-07-01 18:41:00 【澎湖Java架构师】
导语
sql的性能优化能够帮助我们优化数据查询时间,本篇主要向大家介绍了10000w的数据在sql优化后查询速度提升60倍的优化过程。
正文
有一张财务流水表,未分库分表,目前的数据量为9555695,分页查询使用到了limit,优化之前的查询耗时16 s 938 ms (execution: 16 s 831 ms, fetching: 107 ms),按照下文的方式调整SQL后,耗时347 ms (execution: 163 ms, fetching: 184 ms);
操作:
查询条件放到子查询中,子查询只查主键ID,然后使用子查询中确定的主键关联查询其他的属性字段;
原理:
1、减少回表操作;
2、可参考《阿里巴巴Java开发手册(泰山版)》第五章-MySQL数据库、(二)索引规约、第7条:
【推荐】利用延迟关联或者子查询优化超多分页场景。
说明:
MySQL并不是挑过offeset行,而是取offset+N行,然后返回放弃前offset行,返回N行,那当offset特别大的时候,效率就非常的底下,要么控制返回的总页数,要么对超过特定阈值的页数进行SQL改写。
正例:
先快速定位需要获取的id段,然后再关联:
SELECT a.* FROM 表1 a,(select id from 表1 where 条件 LIMIT 100000,20) b where a.id = b.id;
-- 优化前SQLSELECT 各种字段FROM `table_name`WHERE 各种条件LIMIT 0,10;
- 优化后SQLSELECT 各种字段FROM `table_name` main_taleRIGHT JOIN (SELECT 子查询只查主键FROM `table_name`WHERE 各种条件LIMIT 0,10;) temp_table ON temp_table.主键 = main_table.主键
一、前言
首先说明一下MySQL的版本:
mysql> select version();+-----------+| version() |+-----------+| 5.7.17 |+-----------+1 row in set (0.00 sec)
表结构:
mysql> desc test;+--------+---------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+--------+---------------------+------+-----+---------+----------------+| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment || val | int(10) unsigned | NO | MUL | 0 | || source | int(10) unsigned | NO | | 0 | |+--------+---------------------+------+-----+---------+----------------+3 rows in set (0.00 sec)
id为自增主键,val为非唯一索引。
灌入大量数据,共500万:
mysql> select count(*) from test;+----------+| count(*) |+----------+| 5242882 |+----------+1 row in set (4.25 sec)
我们知道,当limit offset rows中的offset很大时,会出现效率问题:
mysql> select * from test where val=4 limit 300000,5;+---------+-----+--------+| id | val | source |+---------+-----+--------+| 3327622 | 4 | 4 || 3327632 | 4 | 4 || 3327642 | 4 | 4 || 3327652 | 4 | 4 || 3327662 | 4 | 4 |+---------+-----+--------+5 rows in set (15.98 sec)
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;+---------+-----+--------+---------+| id | val | source | id |+---------+-----+--------+---------+| 3327622 | 4 | 4 | 3327622 || 3327632 | 4 | 4 | 3327632 || 3327642 | 4 | 4 | 3327642 || 3327652 | 4 | 4 | 3327652 || 3327662 | 4 | 4 | 3327662 |+---------+-----+--------+---------+5 rows in set (0.38 sec)
为了达到相同的目的,我们一般会改写成如下语句:
时间相差很明显。
为什么会出现上面的结果?我们看一下select * from test where val=4 limit 300000,5;的查询过程:
- 查询到索引叶子节点数据。
- 根据叶子节点上的主键值去聚簇索引上查询需要的全部字段值。
类似于下面这张图:
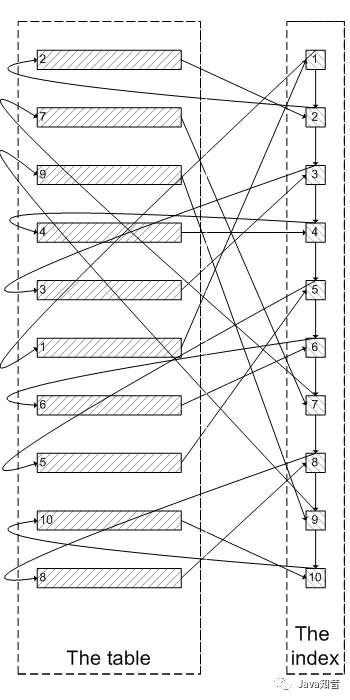
像上面这样,需要查询300005次索引节点,查询300005次聚簇索引的数据,最后再将结果过滤掉前300000条,取出最后5条。MySQL耗费了大量随机I/O在查询聚簇索引的数据上,而有300000次随机I/O查询到的数据是不会出现在结果集当中的。
肯定会有人问:既然一开始是利用索引的,为什么不先沿着索引叶子节点查询到最后需要的5个节点,然后再去聚簇索引中查询实际数据。这样只需要5次随机I/O,类似于下面图片的过程:
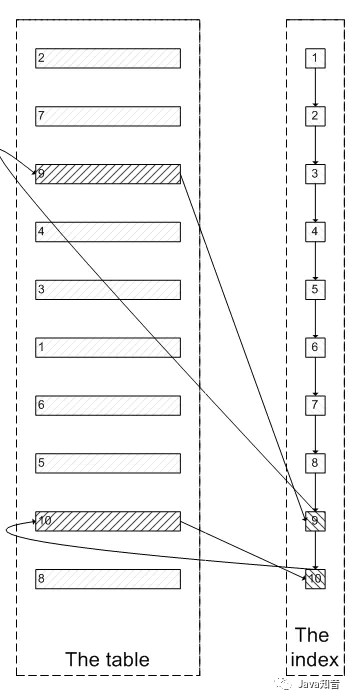
其实我也想问这个问题。
证实
下面我们实际操作一下来证实上述的推论:
为了证实select * from test where val=4 limit 300000,5是扫描300005个索引节点和300005个聚簇索引上的数据节点,我们需要知道MySQL有没有办法统计在一个sql中通过索引节点查询数据节点的次数。我先试了Handler_read_*系列,很遗憾没有一个变量能满足条件。
我只能通过间接的方式来证实:
InnoDB中有buffer pool。里面存有最近访问过的数据页,包括数据页和索引页。所以我们需要运行两个sql,来比较buffer pool中的数据页的数量。预测结果是运行select * from test a inner join (select id from test where val=4 limit 300000,5); 之后,buffer pool中的数据页的数量远远少于select * from test where val=4 limit 300000,5;对应的数量,因为前一个sql只访问5次数据页,而后一个sql访问300005次数据页。
select * from test where val=4 limit 300000,5
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;Empty set (0.04 sec)
可以看出,目前buffer pool中没有关于test表的数据页。
mysql> select * from test where val=4 limit 300000,5;+---------+-----+--------+| id | val | source |+---------+-----+--------+| 3327622 | 4 | 4 || 3327632 | 4 | 4 || 3327642 | 4 | 4 || 3327652 | 4 | 4 || 3327662 | 4 | 4 |+---------+-----+--------+5 rows in set (26.19 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;+------------+----------+| index_name | count(*) |+------------+----------+| PRIMARY | 4098 || val | 208 |+------------+----------+2 rows in set (0.04 sec)
可以看出,此时buffer pool中关于test表有4098个数据页,208个索引页。
select * from test a inner join (select id from test where val=4 limit 300000,5) ;为了防止上次试验的影响,我们需要清空buffer pool,重启mysql。
mysqladmin shutdown/usr/local/bin/mysqld_safe &
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;Empty set (0.03 sec)
运行sql:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;+---------+-----+--------+---------+| id | val | source | id |+---------+-----+--------+---------+| 3327622 | 4 | 4 | 3327622 || 3327632 | 4 | 4 | 3327632 || 3327642 | 4 | 4 | 3327642 || 3327652 | 4 | 4 | 3327652 || 3327662 | 4 | 4 | 3327662 |+---------+-----+--------+---------+5 rows in set (0.09 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;+------------+----------+| index_name | count(*) |+------------+----------+| PRIMARY | 5 || val | 390 |+------------+----------+2 rows in set (0.03 sec)
我们可以看明显的看出两者的差别:第一个sql加载了4098个数据页到buffer pool,而第二个sql只加载了5个数据页到buffer pool。符合我们的预测。也证实了为什么第一个sql会慢:读取大量的无用数据行(300000),最后却抛弃掉。
而且这会造成一个问题:加载了很多热点不是很高的数据页到buffer pool,会造成buffer pool的污染,占用buffer pool的空间。
遇到的问题
为了在每次重启时确保清空buffer pool,我们需要关闭innodb_buffer_pool_dump_at_shutdown和innodb_buffer_pool_load_at_startup,这两个选项能够控制数据库关闭时dump出buffer pool中的数据和在数据库开启时载入在磁盘上备份buffer pool的数据。、
边栏推荐
- code
- Games202 operation 0 - environment building process & solving problems encountered
- 用WPF写一款开源方便、快捷的数据库文档查询、生成工具
- 研究了11种实时聊天软件,我发现都具备这些功能…
- lefse分析
- Altair HyperWorks 2022 software installation package and installation tutorial
- Huawei game failed to initialize init with error code 907135000
- 解决方案:可以ping别人,但是别人不能ping我
- After studying 11 kinds of real-time chat software, I found that they all have these functions
- 【快应用】Win7系统使用华为IDE无法运行和调试项目
猜你喜欢

Huawei game failed to initialize init with error code 907135000

The best landing practice of cave state in an Internet ⽹⾦ financial technology enterprise

Memo - about C # generating barcode for goods
Memo - about C # generating barcode

磁盘的基本知识和基本命令

Leetcode-160 intersecting linked list

透过华为军团看科技之变(六):智慧公路
Games202 operation 0 - environment building process & solving problems encountered

Lumiprobe 生物分子定量丨QuDye 蛋白定量试剂盒

Leetcode203 remove linked list elements
随机推荐
组队学习! 14天鸿蒙设备开发“学练考”实战营限时免费加入!
Improve yolov5 with gsconv+slim neck to maximize performance!
Privacy sandbox is finally coming
LiveData postValue会“丢”数据
Appgallery connect scenario development practice - image storage and sharing
Three simple methods of ES6 array de duplication
linux下清理系统缓存并释放内存
docker 部署mysql8.0
Lumiprobe 自由基分析丨H2DCFDA说明书
[quick application] there are many words in the text component. How to solve the problem that the div style next to it will be stretched
华为联机对战服务玩家掉线重连案例总结
lefse分析
Qfile read / write file operation in QT
Summary of cases of players' disconnection and reconnection in Huawei online battle service
Lumiprobe 双功能交联剂丨Sulfo-Cyanine5 双-NHS 酯
Leetcode-160 intersecting linked list
What designs are needed in the architecture to build a general monitoring and alarm platform
Facebook聊单,SaleSmartly有妙招!
Clean up system cache and free memory under Linux
Image acquisition and playback of coaxpress high speed camera based on pxie interface