当前位置:网站首页>深度學習 卷積神經網絡(CNN)基礎
深度學習 卷積神經網絡(CNN)基礎
2022-07-05 19:42:00 【落花雨時】
文章目錄
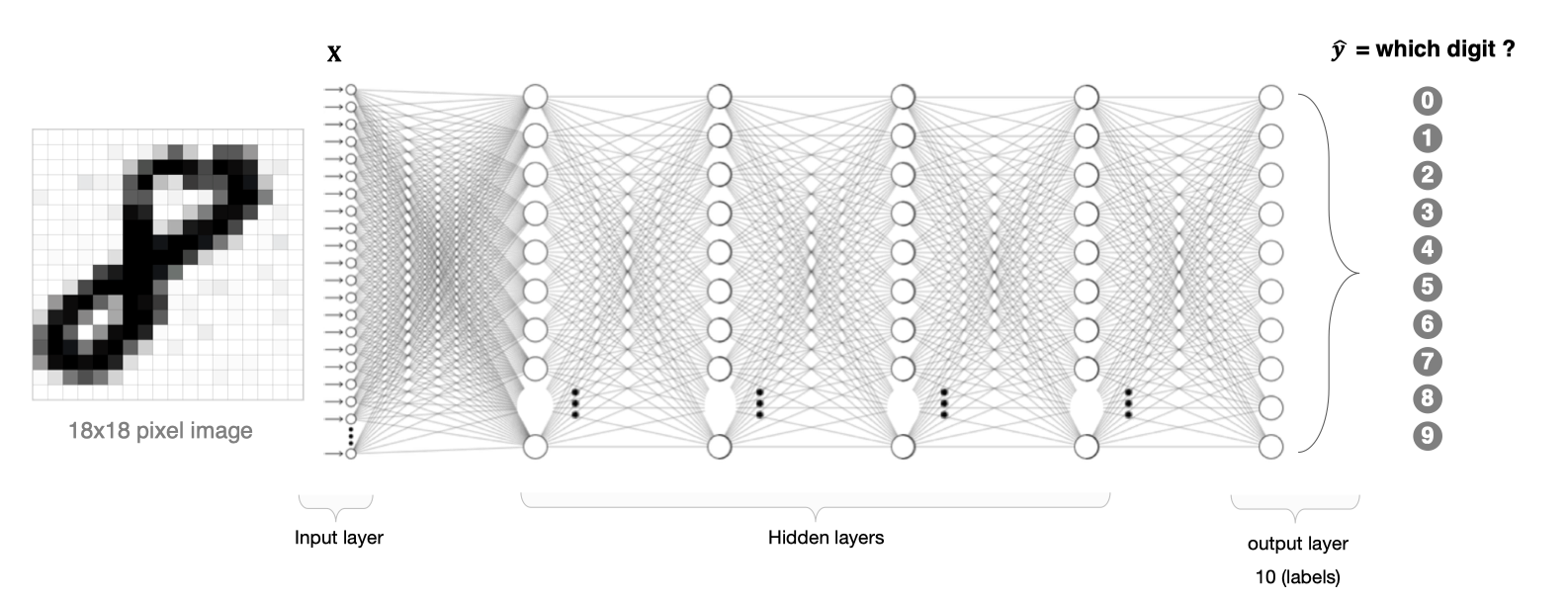
利用全連接神經網絡對圖像進行處理存在以下兩個問題:
- 需要處理的數據量大,效率低
假如我們處理一張 1000×1000 像素的圖片,參數量如下:
1000×1000×3=3,000,000
這麼大量的數據處理起來是非常消耗資源的
- 圖像在維度調整的過程中很難保留原有的特征,導致圖像處理的准確率不高
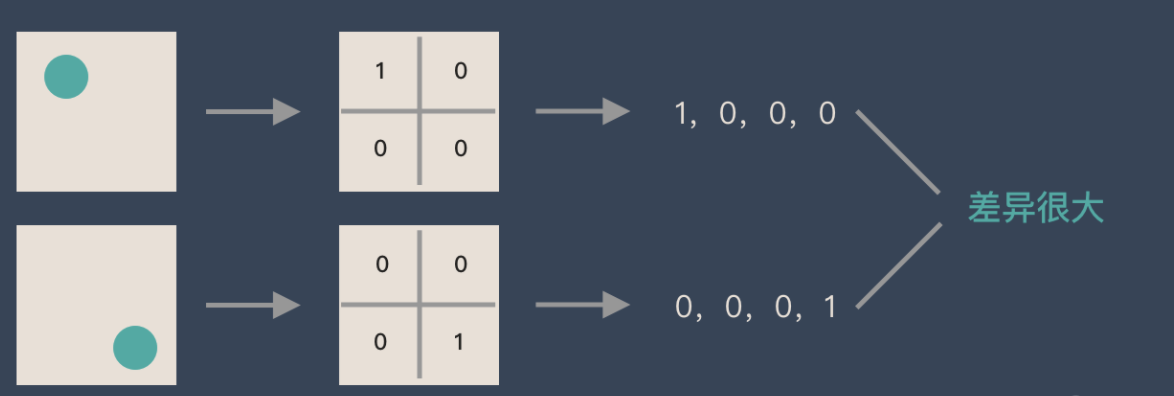
假如有圓形是1,沒有圓形是0,那麼圓形的比特置不同就會產生完全不同的數據錶達。但是從圖像的角度來看,圖像的內容(本質)並沒有發生變化,只是比特置發生了變化。所以當我們移動圖像中的物體,用全連接昇降得到的結果會差异很大,這是不符合圖像處理的要求的。
1. CNN網絡的構成
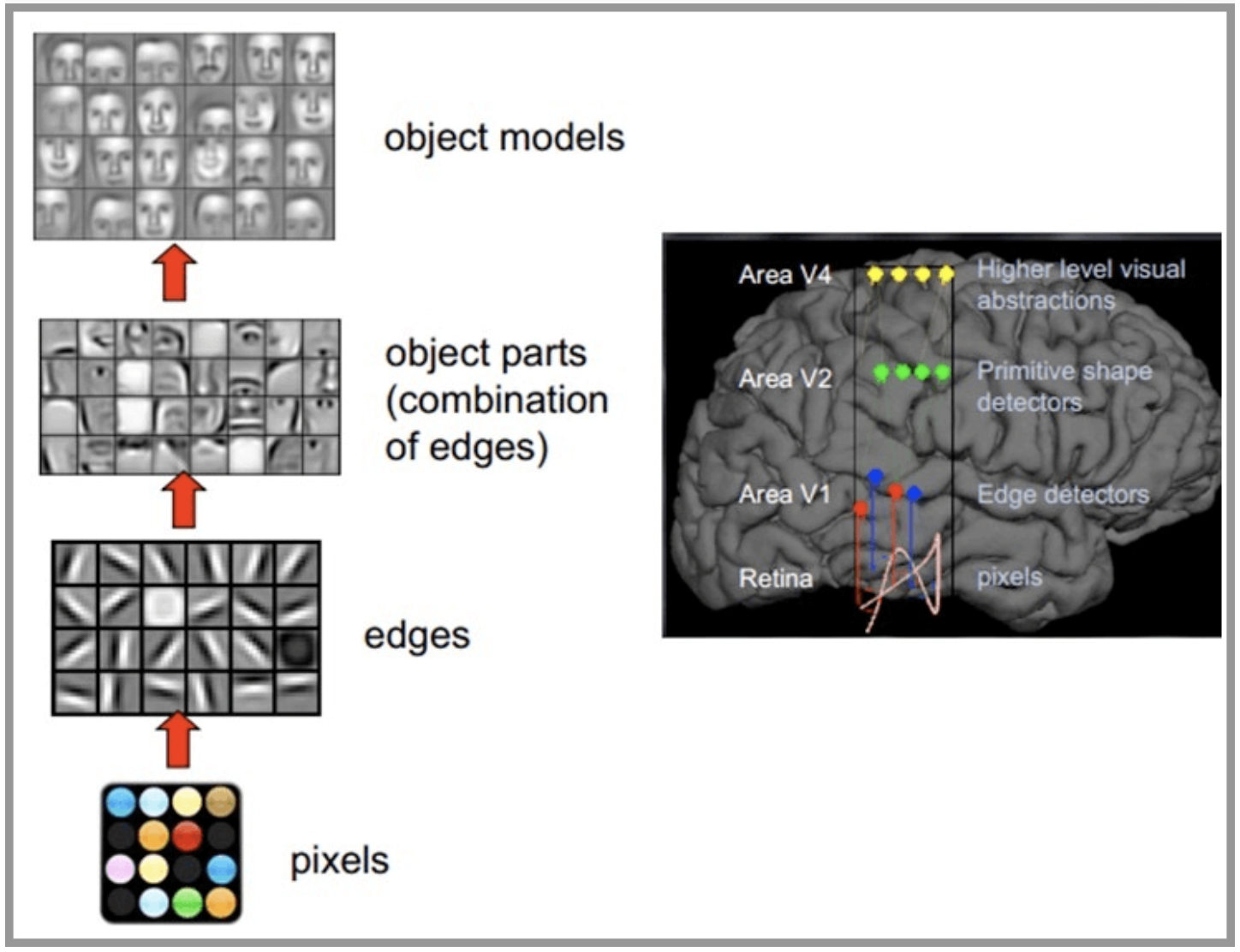
CNN網絡受人類視覺神經系統的啟發,人類的視覺原理:從原始信號攝入開始(瞳孔攝入像素 Pixels),接著做初步處理(大腦皮層某些細胞發現邊緣和方向),然後抽象(大腦判定,眼前的物體的形狀,是圓形的),然後進一步抽象(大腦進一步判定該物體是只人臉)。下面是人腦進行人臉識別的一個示例:
CNN網絡主要有三部分構成:卷積層、池化層和全連接層構成,其中卷積層負責提取圖像中的局部特征;池化層用來大幅降低參數量級(降維);全連接層類似人工神經網絡的部分,用來輸出想要的結果。

整個CNN網絡結構如下圖所示:

2. 卷積層
卷積層是卷積神經網絡中的核心模塊,卷積層的目的是提取輸入特征圖的特征,如下圖所示,卷積核可以提取圖像中的邊緣信息。

2.1 卷積的計算方法
那卷積是怎麼進行計算的呢?
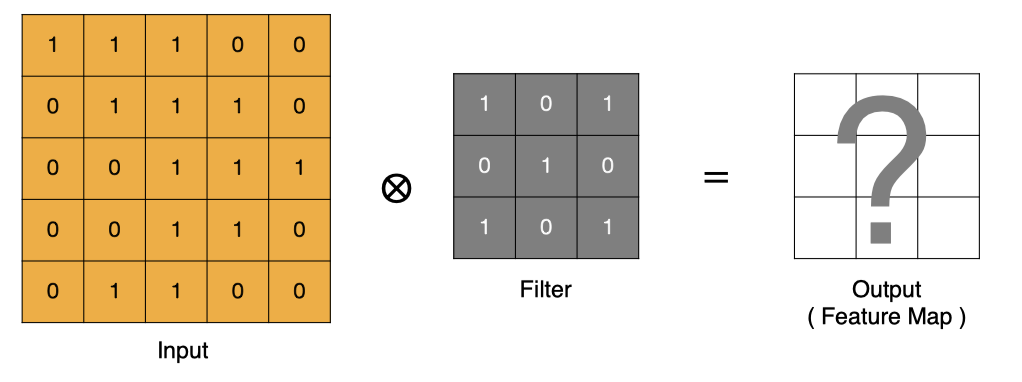
卷積運算本質上就是在濾波器和輸入數據的局部區域間做點積。
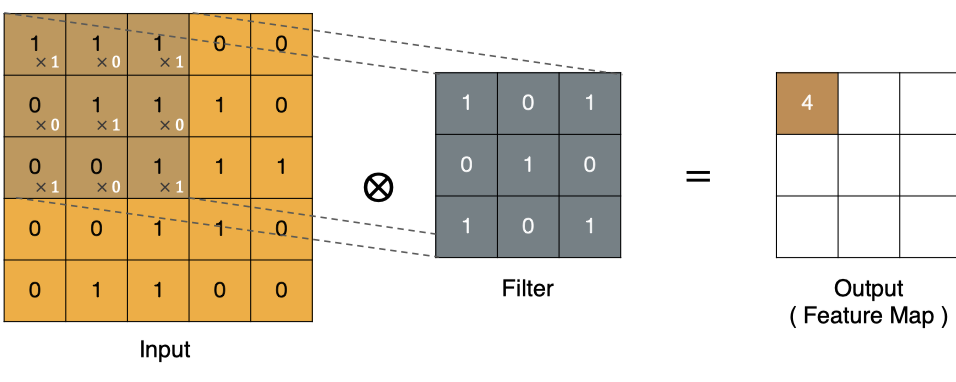
左上角的點計算方法:
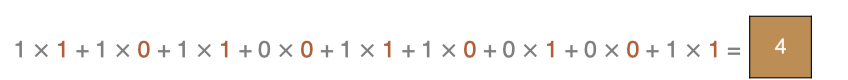
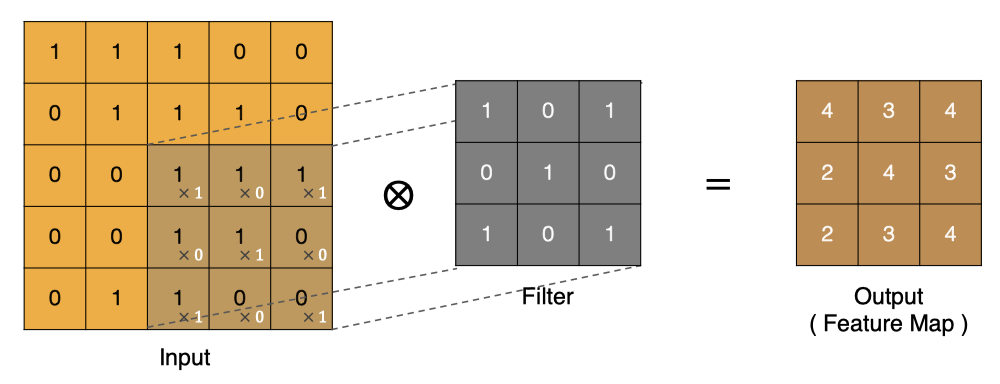
同理可以計算其他各點,得到最終的卷積結果,
最後一點的計算方法是:
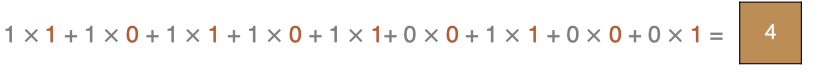
2.2 padding
在上述卷積過程中,特征圖比原始圖减小了很多,我們可以在原圖像的周圍進行padding,來保證在卷積過程中特征圖大小不變。
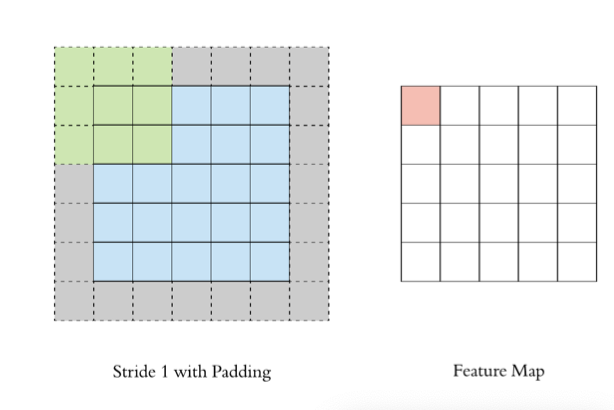
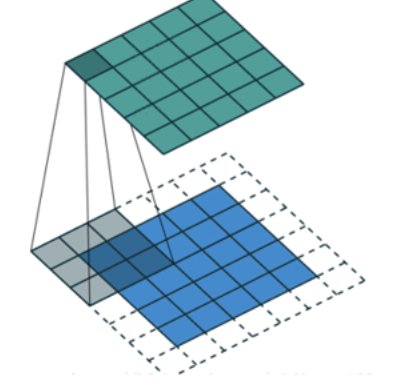
2.3 stride
按照步長為1來移動卷積核,計算特征圖如下所示:

如果我們把stride增大,比如設為2,也是可以提取特征圖的,如下圖所示:

2.4 多通道卷積
實際中的圖像都是多個通道組成的,我們怎麼計算卷積呢?
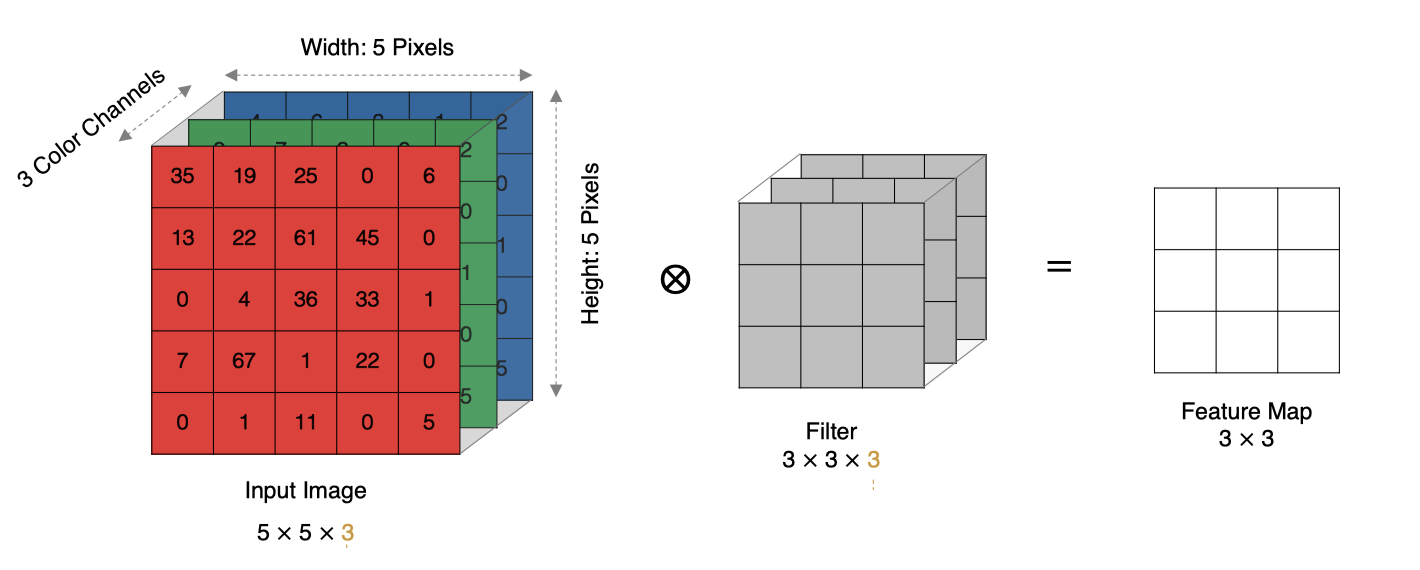
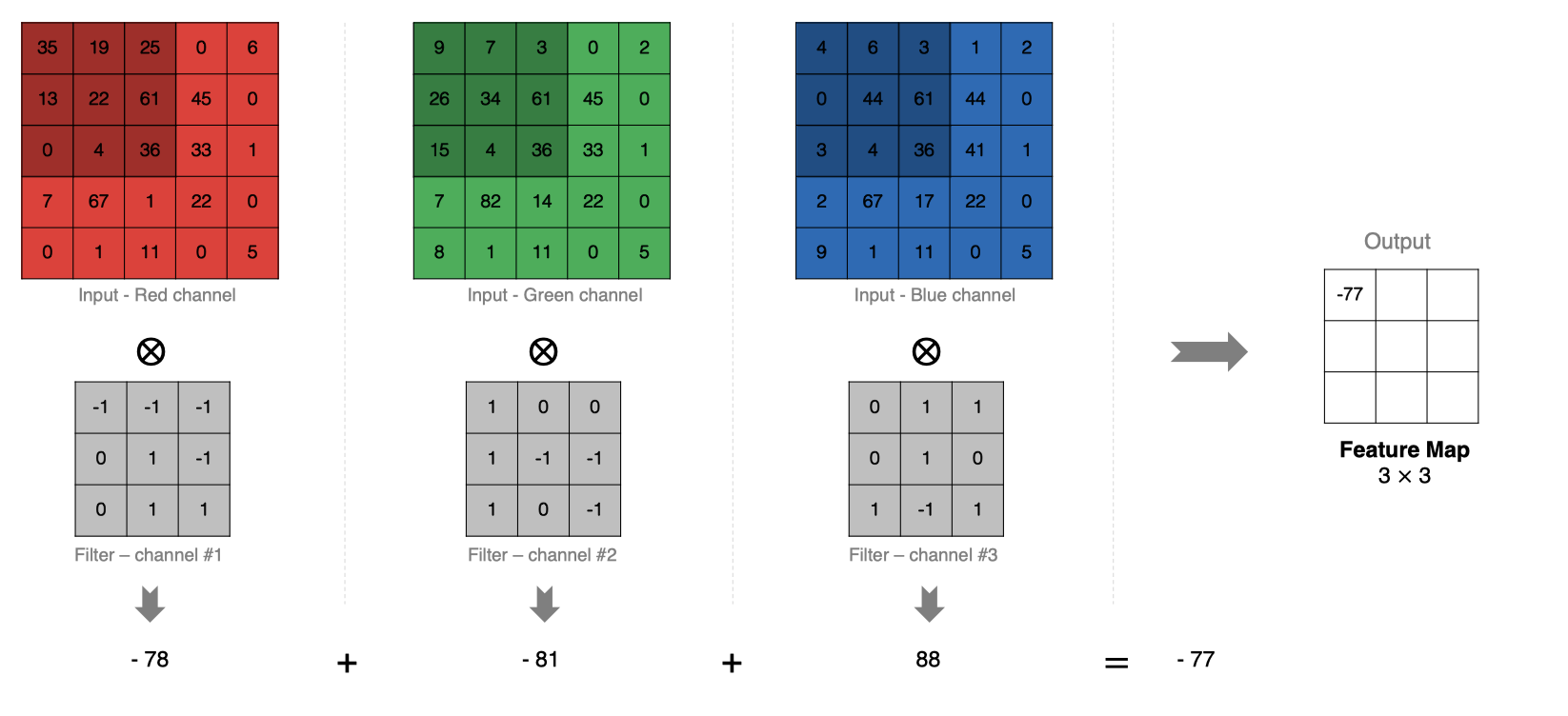
計算方法如下:當輸入有多個通道(channel)時(例如圖片可以有 RGB 三個通道),卷積核需要擁有相同的channel數,每個卷積核 channel 與輸入層的對應 channel 進行卷積,將每個 channel 的卷積結果按比特相加得到最終的 Feature Map
2.5 多卷積核卷積
如果有多個卷積核時怎麼計算呢?當有多個卷積核時,每個卷積核學習到不同的特征,對應產生包含多個 channel 的 Feature Map, 例如下圖有兩個 filter,所以 output 有兩個 channel。
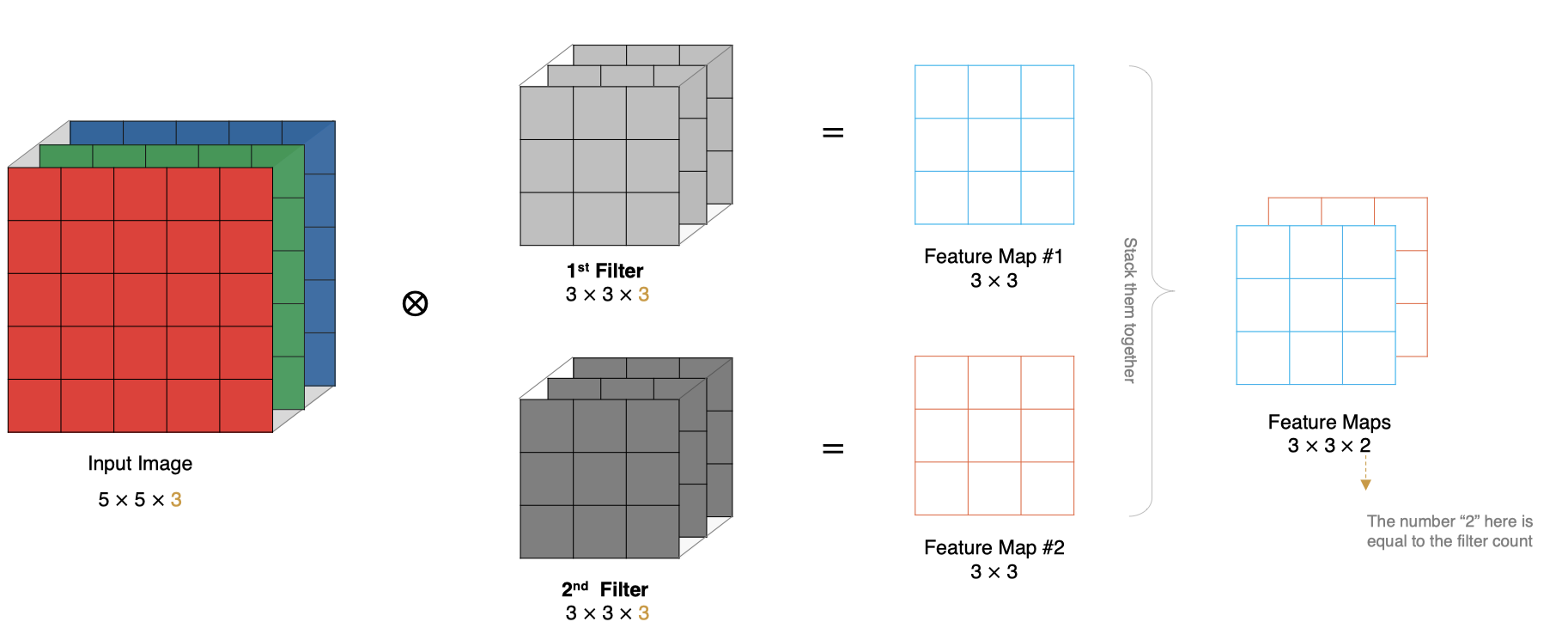
2.6 特征圖大小
輸出特征圖的大小與以下參數息息相關: * size:卷積核/過濾器大小,一般會選擇為奇數,比如有1 * 1, 3 * 3, 5 * 5 * padding:零填充的方式 * stride:步長
那計算方法如下圖所示:

輸入特征圖為5x5,卷積核為3x3,外加padding 為1,則其輸出尺寸為:
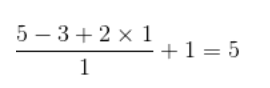
如下圖所示:
在tf.keras中卷積核的實現使用
tf.keras.layers.Conv2D(
filters, kernel_size, strides=(1, 1), padding='valid',
activation=None
)
主要參數說明如下:

3. 池化層(Pooling)
池化層迎來降低了後續網絡層的輸入維度,縮减模型大小,提高計算速度,並提高了Feature Map 的魯棒性,防止過擬合,
它主要對卷積層學習到的特征圖進行下采樣(subsampling)處理,主要由兩種
3.1 最大池化
Max Pooling,取窗口內的最大值作為輸出,這種方式使用較廣泛。

在tf.keras中實現的方法是:
tf.keras.layers.MaxPool2D(
pool_size=(2, 2), strides=None, padding='valid'
)
參數:
pool_size: 池化窗口的大小
strides: 窗口移動的步長,默認為1
padding: 是否進行填充,默認是不進行填充的
3.2 平均池化
Avg Pooling,取窗口內的所有值的均值作為輸出
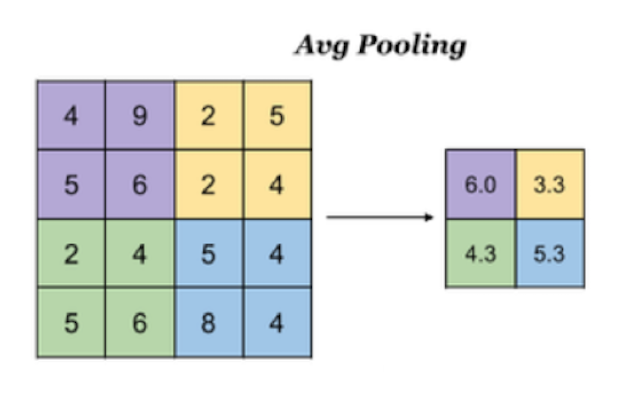
在tf.keras中實現池化的方法是:
tf.keras.layers.AveragePooling2D(
pool_size=(2, 2), strides=None, padding='valid'
)
4. 全連接層
全連接層比特於CNN網絡的末端,經過卷積層的特征提取與池化層的降維後,將特征圖轉換成一維向量送入到全連接層中進行分類或回歸的操作。
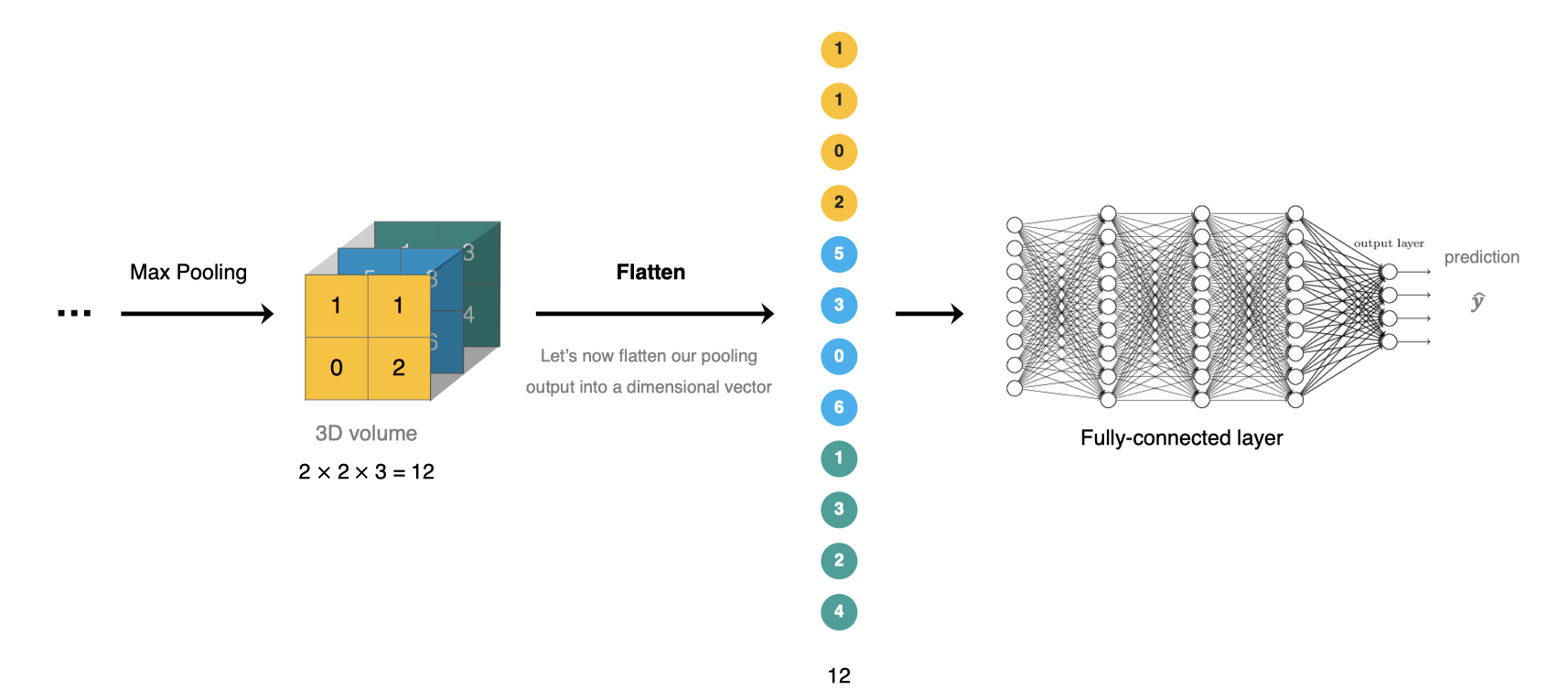
在tf.keras中全連接層使用tf.keras.dense實現。
5.卷積神經網絡的構建
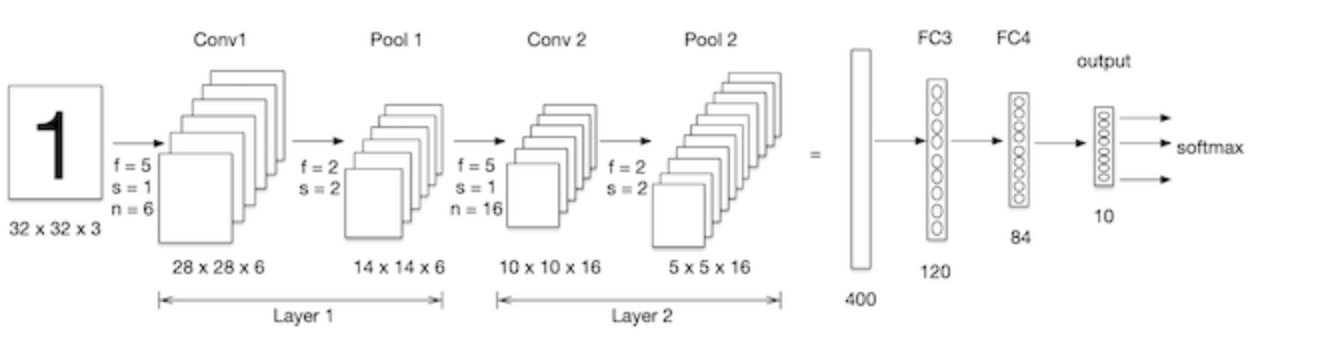
我們構建卷積神經網絡在mnist數據集上進行處理,如下圖所示:LeNet-5是一個較簡單的卷積神經網絡, 輸入的二維圖像,先經過兩次卷積層,池化層,再經過全連接層,最後使用softmax分類作為輸出層。
導入工具包:
import tensorflow as tf
# 數據集
from tensorflow.keras.datasets import mnist
5.1 數據加載
與神經網絡的案例一致,首先加載數據集:
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
5.2 數據處理
卷積神經網絡的輸入要求是:NHWC ,分別是圖片數量,圖片高度,圖片寬度和圖片的通道,因為是灰度圖,通道為1.
# 數據處理:num,h,w,c
# 訓練集數據
train_images = tf.reshape(train_images, (train_images.shape[0],train_images.shape[1],train_images.shape[2], 1))
print(train_images.shape)
# 測試集數據
test_images = tf.reshape(test_images, (test_images.shape[0],test_images.shape[1],test_images.shape[2], 1))
結果為:
(60000, 28, 28, 1)
5.3 模型搭建
Lenet-5模型輸入的二維圖像,先經過兩次卷積層,池化層,再經過全連接層,最後使用softmax分類作為輸出層,模型構建如下:
# 模型構建
net = tf.keras.models.Sequential([
# 卷積層:6個5*5的卷積核,激活是sigmoid
tf.keras.layers.Conv2D(filters=6,kernel_size=5,activation='sigmoid',input_shape= (28,28,1)),
# 最大池化
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
# 卷積層:16個5*5的卷積核,激活是sigmoid
tf.keras.layers.Conv2D(filters=16,kernel_size=5,activation='sigmoid'),
# 最大池化
tf.keras.layers.MaxPool2D(pool_size=2, strides=2),
# 維度調整為1維數據
tf.keras.layers.Flatten(),
# 全卷積層,激活sigmoid
tf.keras.layers.Dense(120,activation='sigmoid'),
# 全卷積層,激活sigmoid
tf.keras.layers.Dense(84,activation='sigmoid'),
# 全卷積層,激活softmax
tf.keras.layers.Dense(10,activation='softmax')
])
我們通過net.summary()查看網絡結構:
Model: "sequential_11"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 24, 24, 6) 156
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 12, 12, 6) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 16) 2416
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 4, 4, 16) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 256) 0
_________________________________________________________________
dense_25 (Dense) (None, 120) 30840
_________________________________________________________________
dense_26 (Dense) (None, 84) 10164
dense_27 (Dense) (None, 10) 850
=================================================================
Total params: 44,426
Trainable params: 44,426
Non-trainable params: 0
______________________________________________________________
手寫數字輸入圖像的大小為28x28x1,如下圖,我們來看下卷積層的參數量:
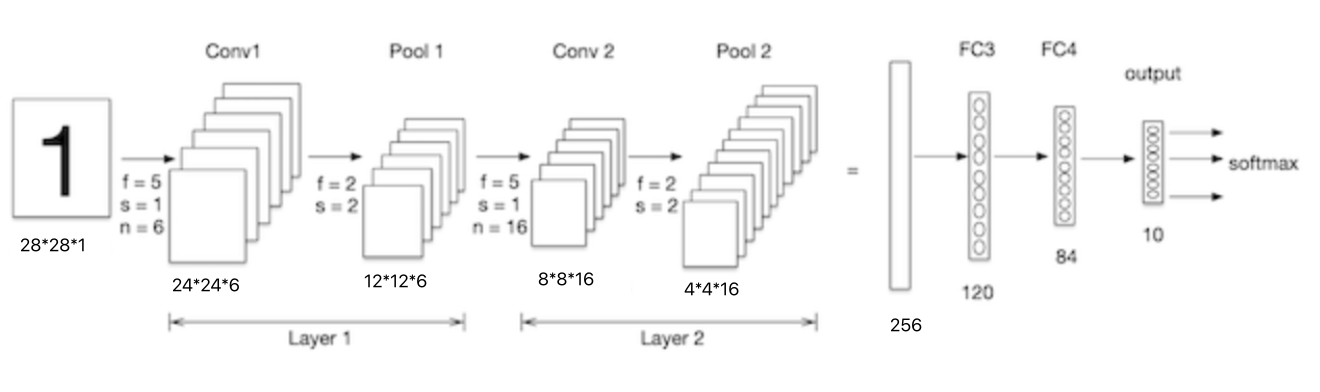
conv1中的卷積核為5x5x1,卷積核個數為6,每個卷積核有一個bias,所以參數量為:5x5x1x6+6=156。
conv2中的卷積核為5x5x6,卷積核個數為16,每個卷積核有一個bias,所以參數量為:5x5x6x16+16 = 2416。
5.4 模型編譯
設置優化器和損失函數:
# 優化器
optimizer = tf.keras.optimizers.SGD(learning_rate=0.9)
# 模型編譯:損失函數,優化器和評價指標
net.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
5.5 模型訓練
模型訓練:
# 模型訓練
net.fit(train_images, train_labels, epochs=5, validation_split=0.1)
訓練流程:
Epoch 1/5
1688/1688 [==============================] - 10s 6ms/step - loss: 0.8255 - accuracy: 0.6990 - val_loss: 0.1458 - val_accuracy: 0.9543
Epoch 2/5
1688/1688 [==============================] - 10s 6ms/step - loss: 0.1268 - accuracy: 0.9606 - val_loss: 0.0878 - val_accuracy: 0.9717
Epoch 3/5
1688/1688 [==============================] - 10s 6ms/step - loss: 0.1054 - accuracy: 0.9664 - val_loss: 0.1025 - val_accuracy: 0.9688
Epoch 4/5
1688/1688 [==============================] - 11s 6ms/step - loss: 0.0810 - accuracy: 0.9742 - val_loss: 0.0656 - val_accuracy: 0.9807
Epoch 5/5
1688/1688 [==============================] - 11s 6ms/step - loss: 0.0732 - accuracy: 0.9765 - val_loss: 0.0702 - val_accuracy: 0.9807
5.6 模型評估
# 模型評估
score = net.evaluate(test_images, test_labels, verbose=1)
print('Test accuracy:', score[1])
輸出為:
313/313 [==============================] - 1s 2ms/step - loss: 0.0689 - accuracy: 0.9780
Test accuracy: 0.9779999852180481
與使用全連接網絡相比,准確度提高了很多。
边栏推荐
- third-party dynamic library (libcudnn.so) that Paddle depends on is not configured correctl
- How to safely and quickly migrate from CentOS to openeuler
- Xaas trap: all things serve (possible) is not what it really needs
- 【硬核干货】数据分析哪家强?选Pandas还是选SQL
- 不愧是大佬,字节大牛耗时八个月又一力作
- 大厂面试必备技能,2022Android不死我不倒
- 中国银河证券开户安全吗 证券开户
- 手机开户选择哪家券商公司比较好哪家平台更安全
- 从零实现深度学习框架——LSTM从理论到实战【实战】
- Is it safe for Anxin securities to open an account online?
猜你喜欢
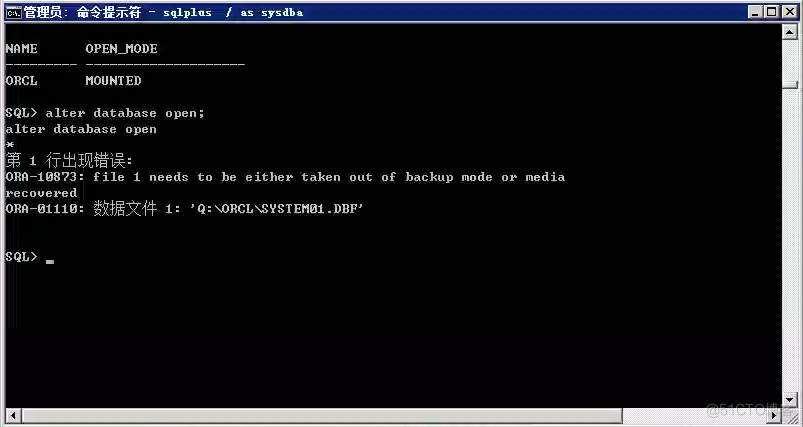
Oracle故障处理:Ora-10873:file * needs to be either taken out of backup or media recovered
![[OBS] qstring's UTF-8 Chinese conversion to blog printing UTF-8 char*](/img/cc/172684664a9115943d45b0646ef110.png)
[OBS] qstring's UTF-8 Chinese conversion to blog printing UTF-8 char*
使用 RepositoryProvider简化父子组件的传值
aggregate

UWB超宽带定位技术,实时厘米级高精度定位应用,超宽带传输技术
【硬核干货】数据分析哪家强?选Pandas还是选SQL
[hard core dry goods] which company is better in data analysis? Choose pandas or SQL
XaaS 陷阱:万物皆服务(可能)并不是IT真正需要的东西
How to convert word into PDF? Word to PDF simple way to share!
Django使用mysqlclient服务连接并写入数据库的操作过程

随机推荐
Fuzor 2020軟件安裝包下載及安裝教程
PHP uses ueditor to upload pictures and add watermarks
third-party dynamic library (libcudnn.so) that Paddle depends on is not configured correctl
【obs】libobs-winrt :CreateDispatcherQueueController
HiEngine:可媲美本地的云原生内存数据库引擎
The relationship between temperature measurement and imaging accuracy of ifd-x micro infrared imager (module)
Bitcoinwin (BCW) was invited to attend Hanoi traders fair 2022
【C语言】字符串函数及模拟实现strlen&&strcpy&&strcat&&strcmp
IBM大面积辞退40岁+的员工,掌握这十个搜索技巧让你的工作效率至上提高十倍
不愧是大佬,字节大牛耗时八个月又一力作
Android面试,android音视频开发
What does software testing do? What are the requirements for learning?
再忙不能忘安全
强化学习-学习笔记4 | Actor-Critic
Information / data
Apprentissage du projet MMO I: préchauffage
信息/数据
多分支结构
Django uses mysqlclient service to connect and write to the database
MySQL中字段类型为longtext的值导出后显示二进制串方式