当前位置:网站首页>3D Semantic Segmentation - 2DPASS
3D Semantic Segmentation - 2DPASS
2022-08-03 23:06:00 【Lemon_Yam】
2DPASS(
ECCV2022)主要贡献:
- 提出了2D Prior Aided Semantic Segmentation 2DPASS,This method uses the two-dimensional prior information of the camera toAuxiliary three-dimensional semantic segmentation.To the best of the author's team,2DPASS is the first to distill multimodal information and apply it to a single point cloud(模态)的语义分割方法
- Single-knowledge distillation using the multi-scale fusion proposed in the paper(MSFSKD)策略,2DPASS 在 SemanticKITTI 和 NuScenes achieved on these two large-scale benchmarks显著的性能提升且达到了
SOTA
前言
️在自动驾驶领域中,Camera can get the dense color information and granular textureInability to get accurate depth information and unreliable in low light conditions,Lidar can provide accurate depth information butCan only capture sparse and textureless data.因此,Cameras and lidar capture complementary information,This makes semantic segmentation through multimodal data fusion a research hotspot.

Although the use of multimodal data can effectively improve model performance,but based on fusion(fusion-based)The method requires paired data(paired data)and has the following limitations:
- Due to the difference between the camera and the lidar视野(FOVs)不同,Cannot establish point-to-pixel mapping for points outside the image plane.通常情况下,激光雷达和相机的 FOVs overlap only on a small part(如上图所示,The red part is in the right image FOVs 重叠部分),This greatly limits the application of fusion-based methods
- Fusion-based methods at runtimeProcess images and point clouds simultaneously(By multitasking or cascading),从而消耗了更多的计算资源,This puts a lot of burden on real-time applications
因此,论文提出了一种2D Prior Aided Semantic Segmentation(2DPASS)general training program,to improve representation learning on point clouds(representation learning)能力.论文提出的 2DPASS 在训练过程中Make full use of the 2-d image with rich semantic information,然后在Semantic segmentation without strict pairwise data constraints.在实际应用中,2DPASS Fusion via Auxiliary Modalities(auxiliary modal fusion)and multi-scale fusion to single knowledge distillation(MSFSKD),From multiple modal dataGet richer semantic and structural information,然后The information extraction to pure 3D 网络.compared to fusion-based methods,The paper's solution has the following better properties:
- 通用性:可以在Only a small amount of network structure is modifieddown easily with any other 3D The segmentation models are integrated together
- 灵活性:The fusion module is only during training用于增强 3D 网络,训练后,Enhanced 3D modelCan be deployed without image input
- 有效性:Even if only a small part of the overlap of multimodal data,The method proposed in the paper also可以显著提高性能
实验结果显示,在装备了 2DPASS 之后,Baseline model used in the paper(baseline model)Significant performance boost with only point cloud input.具体来说,它在 SemanticKITTI 和 NuScenes achieved on these two large-scale accepted benchmarks SOTA.
网络结构
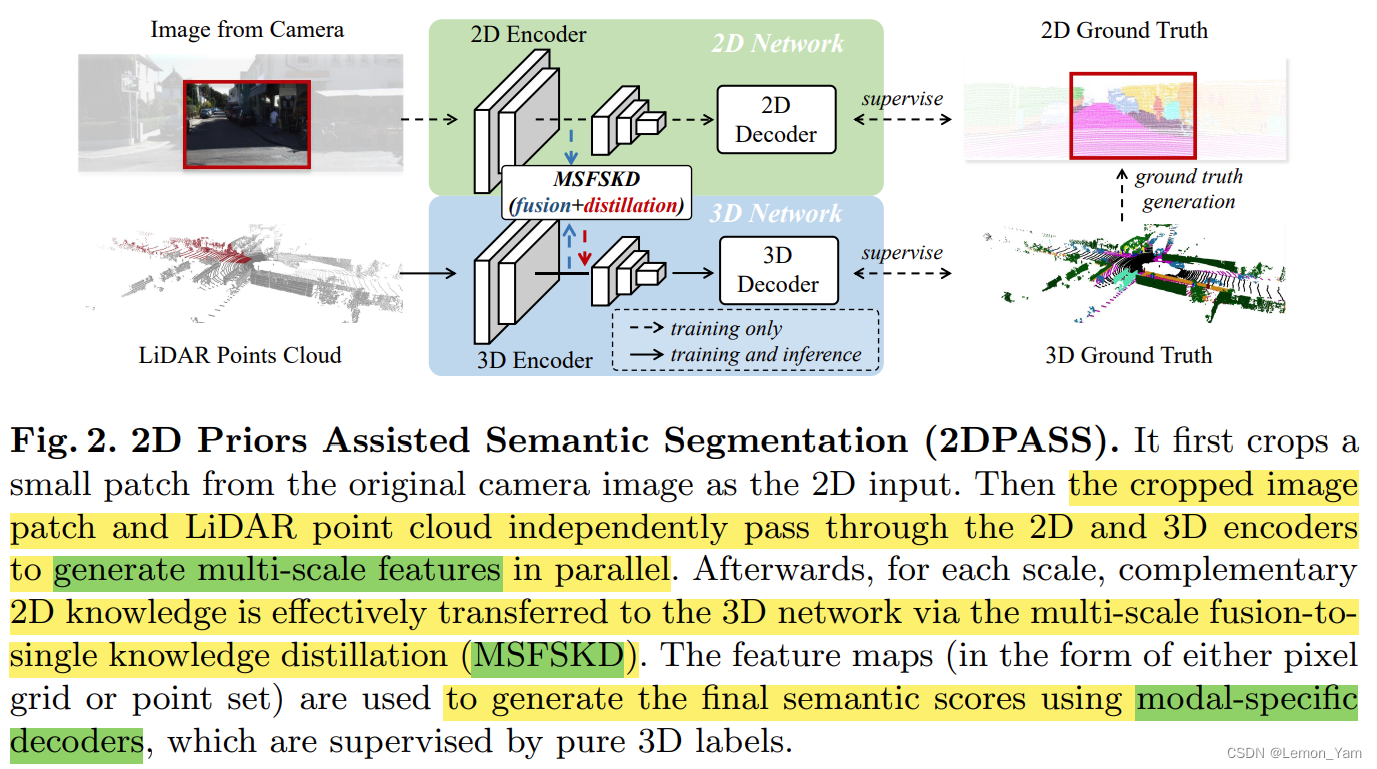
- from the original imageCrop out a small piece of the image(
480x320)作为 2D 输入(Since the camera image is very large,Multimodality leading to sending raw images to the paper pipeline is difficult to deal with),这个步骤Speeds up the training process without unnecessary performance degradation - The cropped image and lidar point cloud are passed through 2D 和 3D 编码器,并行Generate multiscale features
- 对于每个尺度,Complementary two-dimensional knowledge through
MSFSKD从而有效地Transfer to a 3D network(Make full use of texture and color perception of two-dimensional prior knowledge,and retain the original 3D specific knowledge) - on every scale 2D 和 3D features are used to generate semantic segmentation predictions,These predictions are纯 3D Label supervision
️在推理过程中,可以丢弃与 2D 相关的分支,compared to fusion-based methods,这有效地To avoid the additional computational burden in actual application.
编码器
The thesis using two-dimensional convolution ResNet34 编码器作为 2D 网络,而Use sparse convolution to build 3D 网络.具体来说,论文设计了一个Layered encoderSPVCNN,And is used on each scale ResNet 瓶颈设计,同时用 LeakyReLU 激活函数代替 ReLU 激活函数.在这两个网络中,We extract from different scales L 个特征图,get 2D features { F l 2 D } l = 1 L \{F_l^{2D}\}_{l=1}^L { Fl2D}l=1L and 3D features { F l 3 D } l = 1 L \{F_l^{3D}\}_{l=1}^L { Fl3D}l=1L.
️其中,Sparse convolution of one advantage is that it is thin,卷积运算Only consider non-empty voxels
解码器
- 对于 2D 网络,论文采用
FCNAs a decoder for each coding layer on the characteristics of sampling.具体来说,Can through to the first ( L − l + 1 ) (L−l + 1) (L−l+1) The feature map of the coding layer is upsampled to obtain the first l l l Decoding feature maps D l 2 D D_l^{2D} Dl2D,where all upsampled feature maps will beMerge by element-wise addition.最后,The fused feature mapthrough a linear classifier(linear classifier)进行 2D 语义分割. - 对于 3D 网络,论文采用
U-Net作为解码器.其中,The characteristics of the different scalesupsample to original size,并将它们连接在一起,then feed them into the classifier.论文发现,This structure canBetter learn hierarchical information,Get forecast results more efficiently at the same time.
Point-to-Pixel Correspondence
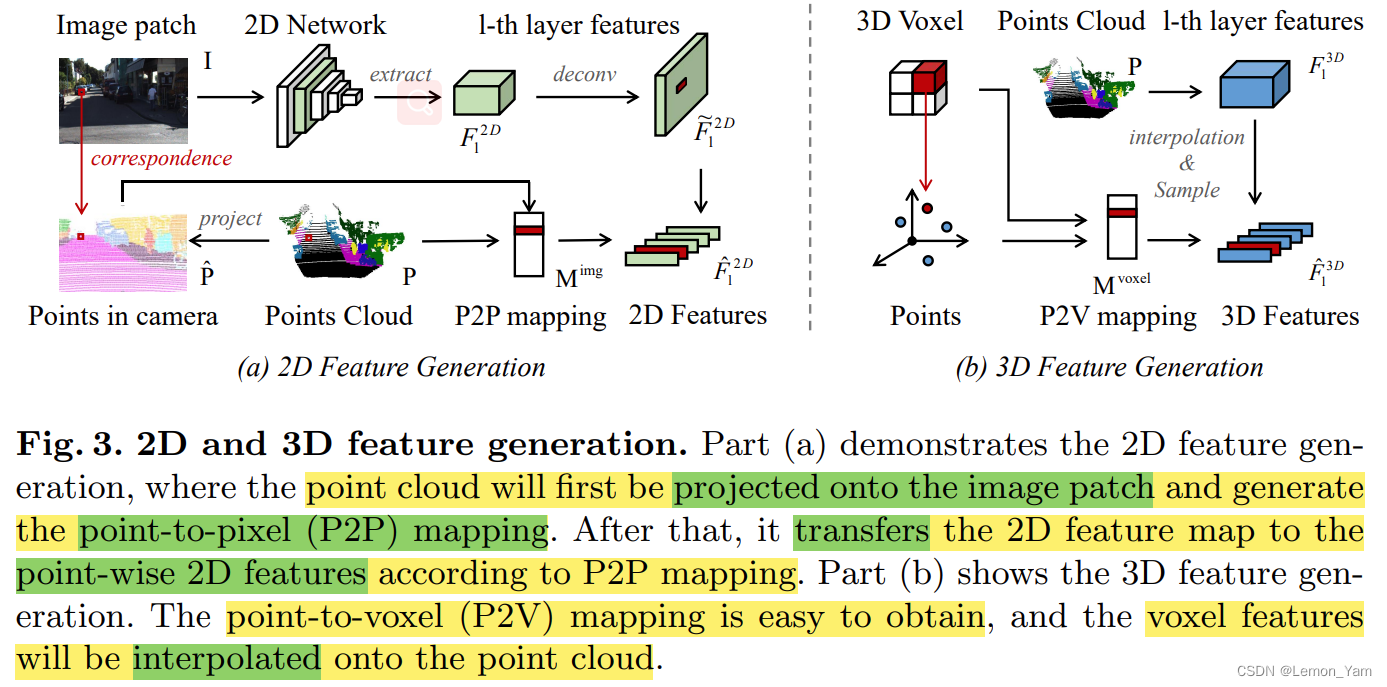
- 2D The feature is generated as shown above
(a)所示(以第 l l l Layer features as an example),其首先使用反卷积2D features F l 2 D ∈ R H l × W l × D l F_l^{2D} \in R^{H_l \times W_l \times D_l} Fl2D∈RHl×Wl×DlSampling to consistent with the original image resolution得到特征图 F ~ l 2 D \tilde{F}_l^{2D} F~l2D,然后再Project a point cloud to an image patch(image patch)上并Generate points to pixels(P2P)的映射,最后根据P2PMapping the 2D feature map F ~ l 2 D \tilde{F}_l^{2D} F~l2D Convert to Pointwise 2D Features F ^ l 2 D \hat{F}_l^{2D} F^l2D.其中,The mapping relationship between points and pixels is as follows:
[ u i , v i , 1 ] T = 1 z i × K × T × [ x i , y i , z i , 1 ] T M i m g = { ( ⌊ v i ⌋ , ⌊ u i ⌋ ) } i = 1 N ∈ R N × 2 \begin{aligned} \ [u_i, v_i, 1]^T &= \frac{1}{z_i} \times K \times T \times [x_i, y_i, z_i, 1]^T \\ M^{img} &= \{ (\lfloor v_i \rfloor , \lfloor u_i \rfloor) \}_{i=1}^N \in R^{N \times 2} \end{aligned} [ui,vi,1]TMimg=zi1×K×T×[xi,yi,zi,1]T={(⌊vi⌋,⌊ui⌋)}i=1N∈RN×2
️其中, p i = ( x i , y i , z i ) ∈ R 3 p_i=(x_i, y_i, z_i)\in R^3 pi=(xi,yi,zi)∈R3 is a point in the point cloud data, p ^ i = ( u i , v i ) ∈ R 2 \hat{p}_i=(u_i, v_i)\in R^2 p^i=(ui,vi)∈R2 is the projected pixel data, K ∈ R 3 × 4 K\in R^{3\times 4} K∈R3×4 为相机内参, T ∈ R 4 × 4 T \in R^{4 \times 4} T∈R4×4 为相机外参, ⌊ ⋅ ⌋ \lfloor \cdot \rfloor ⌊⋅⌋ 为下取整.
️由于 NuScenes Medium lidar and camera工作频率不同,需要通过全局坐标系将时间戳 t l t_l tl of lidar frames转换为时间戳 t c t_c tc camera frame.NuScenes Extrinsic parameter matrix in the dataset T T T 为:
T = T c a m e r a ← e g o t c × T e g o t c ← g l o b a l × T g l o b a l ← e g o t l × T e g o t l ← l i d a r T = T_{camera} \leftarrow ego_{t_c} \times T_{ego_{t_c}} \leftarrow global \times T_{global} \leftarrow ego_{t_l} \times T_{ego_{t_l}} \leftarrow lidar T=Tcamera←egotc×Tegotc←global×Tglobal←egotl×Tegotl←lidar
- 3D The feature is generated as shown above
(b)所示(以第 l l l Layer features as an example),which first obtainsPoint to voxel mapping M l v o x e l M_l^{voxel} Mlvoxel,然后给定3D features of sparse convolutional layers F l 3 D ∈ R N l ′ × D l F_l^{3D} \in R^{N^{'}_l \times D_l} Fl3D∈RNl′×Dl,根据 M l v o x e l M_l^{voxel} Mlvoxel in the original feature map F l 3 D F_l^{3D} Fl3D 上进行closest interpolation(nearest interpolation)得到Point-by-point 3D features F ~ l 3 D ∈ R N × D \tilde{F}_l^{3D}\in R^{N \times D} F~l3D∈RN×D,Finally, by discarding the image field of view(FOVs)outside points to filter related points.Its related formula is as follows:
M l v o x e l = { ( ⌊ x i r l ⌋ , ⌊ y i r l ⌋ , ⌊ z i r l ⌋ ) } i = 1 N ∈ R N × 3 F ^ l 3 D = { f i ∣ f i ∈ F ~ l 3 D , M i , 1 i m g ≤ H , M i , 2 i m g ≤ W } i = 1 N ∈ R N i m g × D l \begin{aligned} M_l^{voxel} &= \{ (\lfloor \frac{x_i}{r_l} \rfloor, \lfloor \frac{y_i}{r_l} \rfloor, \lfloor \frac{z_i}{r_l} \rfloor) \}_{i=1}^N \in R^{N \times 3} \\ \hat{F}_l^{3D} &= \{ f_i | f_i \in \tilde{F}_l^{3D}, M_{i, 1}^{img} \le H, M_{i, 2}^{img} \le W \}_{i=1}^N \in R^{N^{img} \times D_l} \end{aligned} MlvoxelF^l3D={(⌊rlxi⌋,⌊rlyi⌋,⌊rlzi⌋)}i=1N∈RN×3={ fi∣fi∈F~l3D,Mi,1img≤H,Mi,2img≤W}i=1N∈RNimg×Dl
️其中, P = { ( x i , y i , z i ) } i = 1 N P=\{(x_i, y_i, z_i)\}_{i=1}^N P={(xi,yi,zi)}i=1N 是点云数据, r l r_l rl 为第 l l l layer voxel resolution, H H H is the height of the image field of view, W W W is the width of the image field of view
MSFSKD
如下图所示,MSFSKD The internal structure includesModal Fusion and Modality Preserving Knowledge Distillation.其中 2D 特征和 3D 特征通过 2D Learner 进行融合,并使用两个 MLP As well as the nonlinear mapping characteristics逐点相加,Then the output features和原 2D 特征进行融合,再结合 classifier(全连接层)To obtain the fusion feature points S l 2 D 3 D S_l^{2D3D} Sl2D3D.而 3D Parts are enhanced by features,并结合 classifier(全连接层)获取 3D 预测分数 S l 3 D S_l^{3D} Sl3D,and do distillation at the result level.
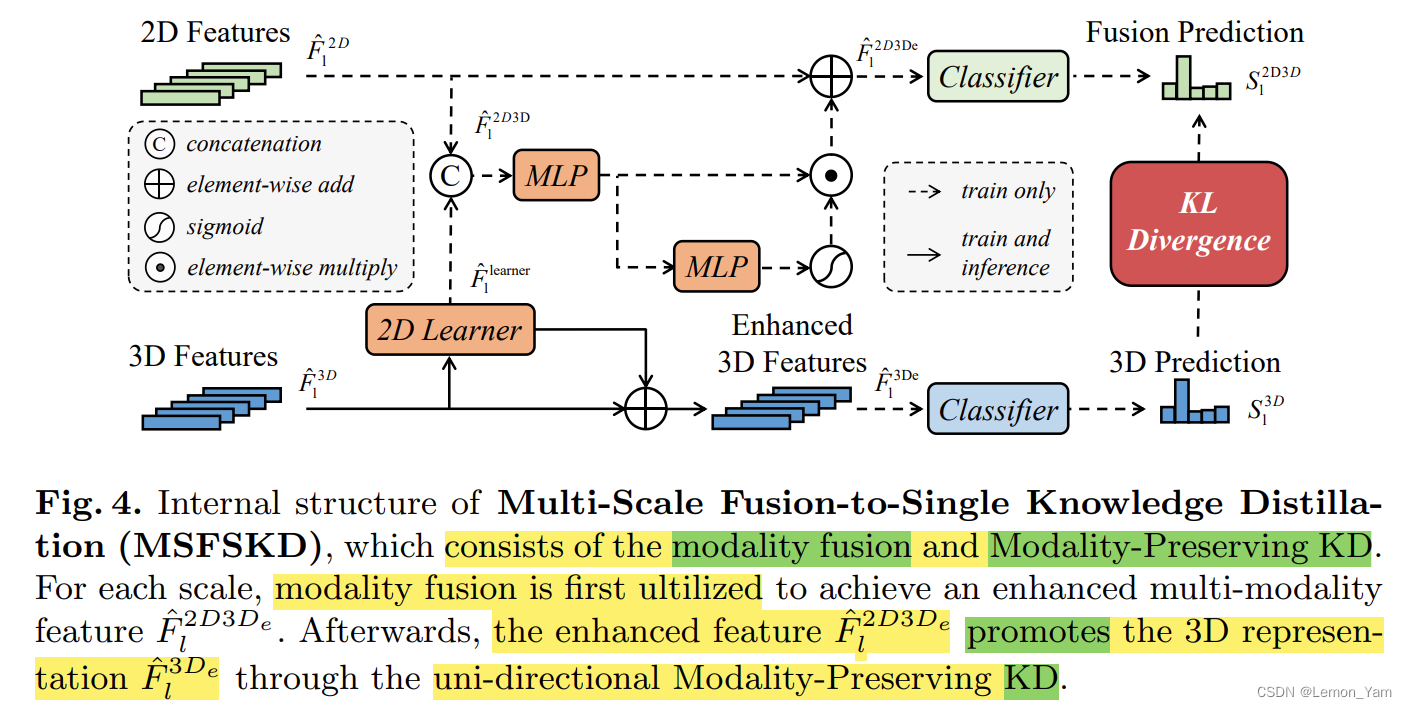
- 2D 和 3D Expression of fusion results are as follows:
F ^ l 2 D 3 D e = F ^ l 2 D + σ ( M L P ( F ^ l 2 D 3 D ) ) ⨀ F ^ l 2 D 3 D \hat{F}_l^{2D3D_e} = \hat{F}_l^{2D} + \sigma(MLP(\hat{F}_l^{2D3D})) \bigodot \hat{F}_l^{2D3D} F^l2D3De=F^l2D+σ(MLP(F^l2D3D))⨀F^l2D3D
️其中, σ \sigma σ 为 sigmoid 激活函数.此外,上图获取 F ^ l 2 D 3 D e \hat{F}_l^{2D3D_e} F^l2D3De 经过 2 个 MLP,And why is there only one expression MLP?
- Knowledge of distillation expression as follows:
L x M = D K L ( S l 2 D 3 D ∥ S l 3 D ) L_{xM} = D_{KL}(S_l^{2D3D}\parallel S_l^{3D}) LxM=DKL(Sl2D3D∥Sl3D)
️论文使用 KL 散度As the knowledge the distillation loss function
论文:https://arxiv.org/pdf/2207.04397.pdf
代码:https://github.com/yanx27/2DPASS
补充:ECCV2022 | 2DPASS:2DA priori auxiliary lidar point clouds of the semantic segmentation!
边栏推荐
- CAS: 178744-28-0, mPEG-DSPE, DSPE-mPEG, methoxy-polyethylene glycol-phosphatidylethanolamine supply
- 云平台建设解决方案
- [N1CTF 2018] eating_cms
- log4j-slf4j-impl cannot be present with log4j-to-slf4j
- Code Casual Recording Notes_Dynamic Programming_416 Segmentation and Subsetting
- 物联网新零售模式,引领购物新潮流
- 电商秒杀系统
- win10系统下yolov5-V6.1版本的tensorrt部署细节教程及bug修改
- 图论-虚拟节点分层建图
- 禾匠编译错误记录
猜你喜欢

直播预告 | 构建业务智联,快速拥抱财务数字化转型
设置工作模式与环境(下):探查和收集信息
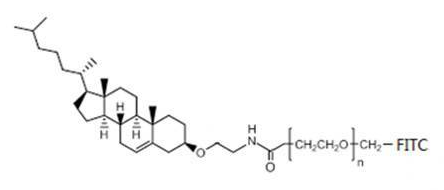
Fluorescein-PEG-CLS, cholesterol-polyethylene glycol-fluorescein scientific research reagent
On the Qixi Festival of 2022, I will offer 7 exquisite confession codes, and at the same time teach you to quickly change the source code for your own use

代码随想录笔记_动态规划_416分割等和子集
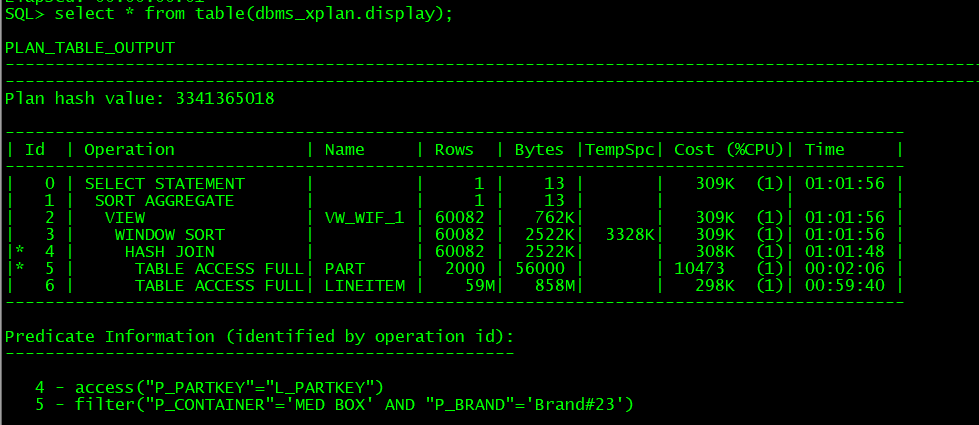
2022-08-03 Oracle executes slow SQL-Q17 comparison
电商秒杀系统
complete binary tree problem

override learning (parent and child)
3D 语义分割——2DPASS
随机推荐
RPA助力商超订单自动化!
Kotlin - 扩展函数和运算符重载
Software testing is seriously involution, how to improve your competitiveness?
1067 Sort with Swap(0, i)
SPOJ 2774 Longest Common Substring(两串求公共子串 SAM)
设置工作模式与环境(下):探查和收集信息
使用tf.image.resize() 和tf.image.resize_with_pad()调整图像大小
七夕活动浪漫上线,别让网络拖慢和小姐姐的开黑时间
V8中的快慢数组(附源码、图文更易理解)
"Digital Economy Panorama White Paper" Financial Digital User Chapter released!
override learning (parent and child)
The sword refers to the offer question 22 - the Kth node from the bottom in the linked list
Interpretation of ML: A case of global interpretation/local interpretation of EBC model interpretability based on titanic titanic rescued binary prediction data set using interpret
Creo 9.0二维草图的诊断:重叠几何
[2022强网杯] polydiv和gamemaster
override学习(父类和子类)
UVa 1025 - A Spy in the Metro (White Book)
如何创建一个Web项目
禾匠编译错误记录
Another MySQL masterpiece published by Glacier (send the book at the end of the article)!!