当前位置:网站首页>将SSE指令转换为ARM NEON指令
将SSE指令转换为ARM NEON指令
2022-08-02 14:09:00 【虹夭】
相关资料
● sse指令集:sse指令解释
● sse2neon仓库:可以在sse2neon.h中寻找对应的neon指令转换方法
注意事项
● 将sse指令转换为arm neon指令往往很难起到优化作用,甚至可能产生负优化,因此该部分优化仅供参考。
__mm_shuffle_ps转换
__mm_shuffle_ps的作用是将m1中取出两个元素放到m3的低位,根据的是_MM_SHUFFLE(i3,i2,i1,i0)的后两个数组,从m2中取出两个元素放到m3的高位,根据的是_MM_SHUFFLE(i3,i2,i1,i0)的前两个数字。
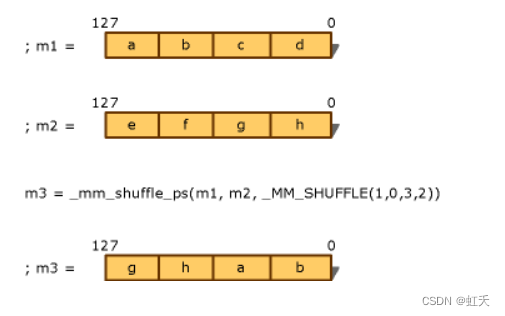
针对__mm_shuffle_ps的转换,sse2neon中大多使用load and store指令和type conversion操作进行组合,比如下面这个代码,对应__mm_shuffle_ps(a,b,__MM_SHUFFLE(2,2,0,0))。
FORCE_INLINE __m128 _mm_shuffle_ps_2200(__m128 a, __m128 b)
{
float32x2_t a00 = vdup_lane_f32(vget_low_f32(vreinterpretq_f32_m128(a)), 0);
float32x2_t b22 =
vdup_lane_f32(vget_high_f32(vreinterpretq_f32_m128(b)), 0);
return vreinterpretq_m128_f32(vcombine_f32(a00, b22));
}
直接使用类似上面的转换一定会造成性能的不升反降,最好的方法是在neon中寻找类似的操作,这部分操作主要集中在permutation,比如vtrn,vrev,vzip,vuzp等
比如上面的例子中:如果需要同时获取__mm_shuffle_ps(a,a,__MM_SHUFFLE(2,2,0,0))和__mm_shuffle_ps(a,a,__MM_SHUFFLE(3,3,1,1))时,可以使用vtrnq_32f(a,a)来获取,结果为float32x4x2_t类型,val[0]对应2200,val[1]对应3311。
边栏推荐
猜你喜欢


随机推荐
小T成长记-网络篇-1-什么是网络?
FP5139电池与适配器供电DC-DC隔离升降压电路反激电路电荷泵电路原理图
镜像法求解接地导体空腔电势分布问题
【使用Pytorch实现ResNet网络模型:ResNet50、ResNet101和ResNet152】
GICv3/v4-软件概述
How to add a one-key shutdown option to the right-click menu in Windows 11
自定义圆形seekBar,超简单
刷卡芯片CI520可直接PIN对PIN替换CV520支持SPI通讯接口
LLVM系列第二十七章:理解IRBuilder
神经网络可以解决一切问题吗:一场知乎辩论的整理
STL容器自定义内存分配器
DP4301无线收发SUB-1G芯片兼容CC1101智能家居
还是别看学位论文
Impressions of Embrace Jetpack
profiler network乱码
Pytorch(16)---搭建一个完整的模型
Win10电脑需要安装杀毒软件吗?
DP1332E刷卡芯片支持NFC内置mcu智能楼宇/终端poss机/智能门锁
Win10电脑不能读取U盘怎么办?不识别U盘怎么解决?
流,向量场,和微分方程