当前位置:网站首页>Pytorch(16)---搭建一个完整的模型
Pytorch(16)---搭建一个完整的模型
2022-08-02 14:07:00 【伏月三十】
一个完整的模型
训练阶段
第一步:
准备数据集。并将其分为训练集和数据集。
第二步:
利用dataloader加载数据集。dataloader将数据成批送入神经网络。
第三步:
创建网络模型,可以直接写,也可以在另一个文件model.py写好,然后引用。
第四步:
创建损失函数。
第五步:
优化器:选择梯度下降法,使损失函数减少。
第六步:
送入网络进行训练。将训练的模型保存下来。
第七步:
用训练集进行测试。
model.py写网络模型
'''搭建神经网络:CIFAR10网络结构'''
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
class CIFAR10(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model=Sequential(
Conv2d(3,32,5,1,2,1),
MaxPool2d(2,),
Conv2d(32,32,5,1,2),
MaxPool2d(2,),
Conv2d(32,64,5,1,2,),
MaxPool2d(2,),
Flatten(),
Linear(64*4*4,64),
Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
if __name__ == '__main__':
cifar10=CIFAR10()
'''验证模型是否正确 给一个输入,看输出的结果 '''
input = torch.ones((64, 3, 32, 32))
output = cifar10(input)
print(output.shape)
train_gpu1.py进行训练,该文件直接把网络模型写进去了,推荐写外面,因为加载模型的时候,需要导入模型结构。
'''在该文件下增加循环次数,看准确率能不能提高'''
import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
from b_nn.model import *
'''1准备数据集'''
train_data = torchvision.datasets.CIFAR10("dataset_CIFAR10", train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("dataset_CIFAR10", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
'''查看数据集的长度'''
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
'''2利用dataloader加载数据集'''
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
'''3创建网络模型'''
class CIFAR10(nn.Module):
def __init__(self) -> None:
super().__init__()
self.model=Sequential(
Conv2d(3,32,5,1,2,1),
MaxPool2d(2,),
Conv2d(32,32,5,1,2),
MaxPool2d(2,),
Conv2d(32,64,5,1,2,),
MaxPool2d(2,),
Flatten(),
Linear(64*4*4,64),
Linear(64,10)
)
def forward(self,x):
x=self.model(x)
return x
cifar10 = CIFAR10()
cifar10=cifar10.cuda()
'''4创建损失函数'''
loss_fn = nn.CrossEntropyLoss()
loss_fn=loss_fn.cuda()
'''5优化器'''
learning_rate = 1e-2 # 学习率
optimizer = torch.optim.SGD(cifar10.parameters(), learning_rate, )
'''6设置训练啊网络的一些参数'''
total_train_step = 0 # 记录训练的次数
total_test_step = 0 # 记录测试的次数
epoch = 50 # 记录训练的轮数 设置训练50轮 发现训练41轮是最高的
'''添加tensorboard'''
writer = SummaryWriter("../train_logs_gpu1")
start_time=time.time()
for i in range(epoch):
print("-----------------第{}轮训练开始:------------------".format(i + 1))
'''训练步骤开始'''
cifar10.train()
for data in train_dataloader:
imgs, targets = data # 取数据
imgs=imgs.cuda()
targets=targets.cuda()
outputs = cifar10(imgs) # 送入神经网络模型
loss = loss_fn(outputs, targets) # 计算误差
'''训练一次:优化器优化模型'''
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 对参数进行优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time=time.time()
print(end_time-start_time)
print("在训练集上的训练次数:{},loss:{}".format(total_train_step, loss.item())) # 例如.item()可以把一个tensor数据类型转换成真实的数字
writer.add_scalar("训练集train_loss", loss.item(), total_train_step)
'''训练完一轮后,在测试数据集上进行测试,看是否需要终止训练'''
'''测试步骤'''
cifar10.eval()
total_test_loss = 0
total_accuracy = 0 # 整体正确的个数
with torch.no_grad(): # 没有梯度
for data in test_dataloader:
imgs, targets = data
imgs=imgs.cuda()
targets=targets.cuda()
outputs = cifar10(imgs)
loss = loss_fn(outputs, targets) # loss是一部分loss
total_test_loss = loss.item() + total_test_loss # 整体loss
# 指标
accuracy = (outputs.argmax(1) == targets).sum() # outputs.argmax(1)==targets 预测结果和标签值相同的求和
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy / test_data_size))
writer.add_scalar("整体测试集总test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_acc", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
'''保存模型'''
#第一种保存方式
torch.save(cifar10, "cifar_{}.pth".format(i)) # 将每一轮训练的结果都保存一下
#第二种保存方式(官方推荐)
torch.save(cifar10.state_dict(),"cifar2_{}.pth".format(i))
print("模型已经保存")
writer.close()
在训练了50轮后,发现第40轮准确率最高,大约是67%。model_cifar40.py文件里加载cifar_40.pth模型,并在该文件里用该模型进行测试。
from model import *
import torch
import torchvision
from torch.utils.data import DataLoader
'''1准备数据集'''
train_data = torchvision.datasets.CIFAR10("dataset_CIFAR10", train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("dataset_CIFAR10", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
'''查看数据集的长度'''
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
'''2利用dataloader加载数据集'''
train_dataloader = DataLoader(train_data, batch_size=100)
test_dataloader = DataLoader(test_data, batch_size=100)
'''3创建网络模型'''
'''直接加载训练好的模型'''
model_cifar40=torch.load("cifar_40.pth")
model_cifar40=model_cifar40.cuda()
'''在训练集上试一下'''
for data in train_dataloader:
imgs, targets = data # 取数据
imgs=imgs.cuda()
targets=targets.cuda()
outputs = model_cifar40(imgs) # 送入神经网络模型
accuracy = (outputs.argmax(1) == targets).sum()
print("整体训练集上的正确率:{}".format(accuracy / 100))
print("--------------------------------------------------------------------------------")
'''在测试集上试一下'''
for data in test_dataloader:
imgs, targets = data # 取数据
imgs=imgs.cuda()
targets=targets.cuda()
outputs = model_cifar40(imgs) # 送入神经网络模型
accuracy = (outputs.argmax(1) == targets).sum()
print("整体测试集集上的正确率:{}".format(accuracy / 100))
结果: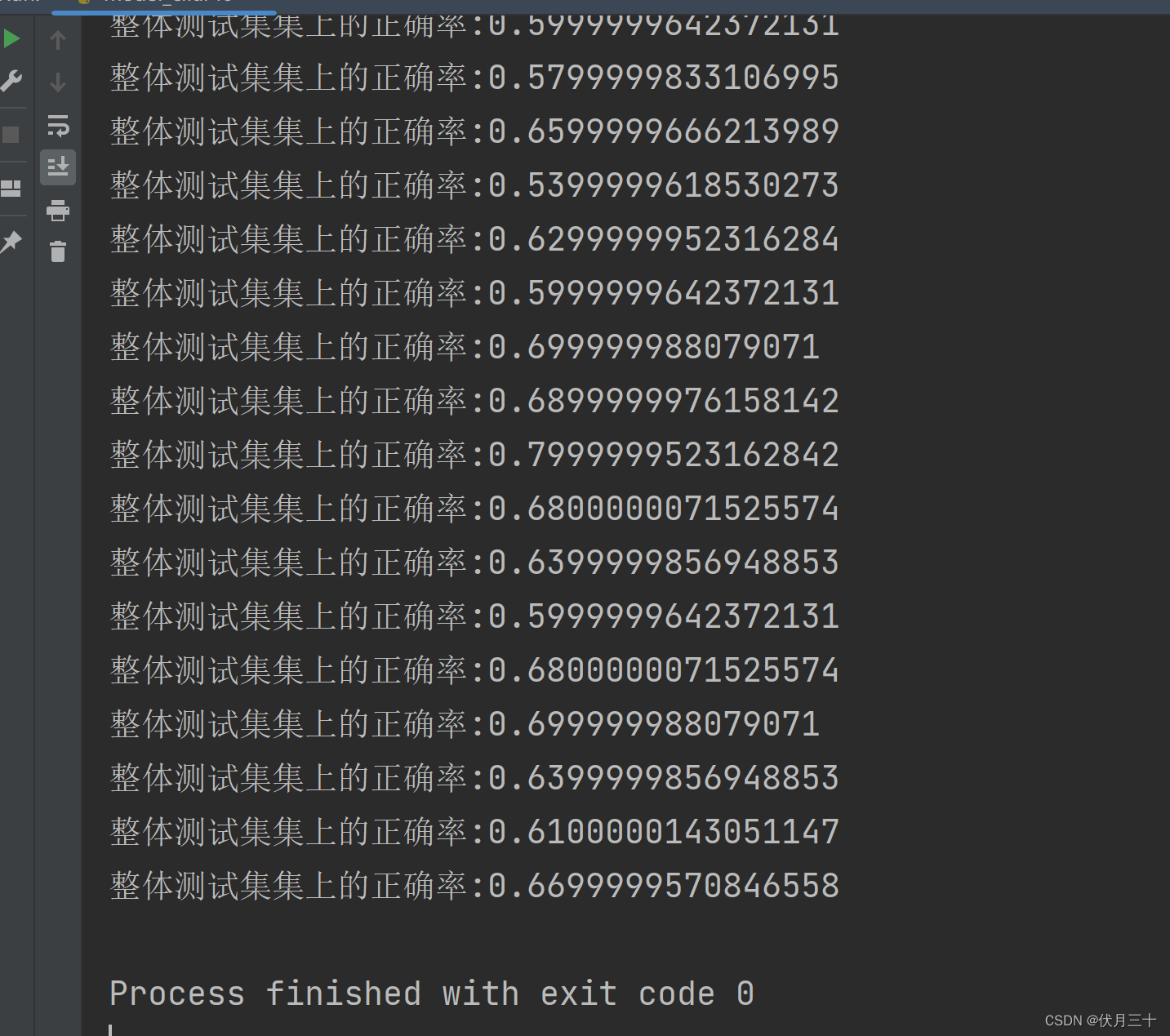
使用VGG16网络进行训练
套路一样,改一下模型即可。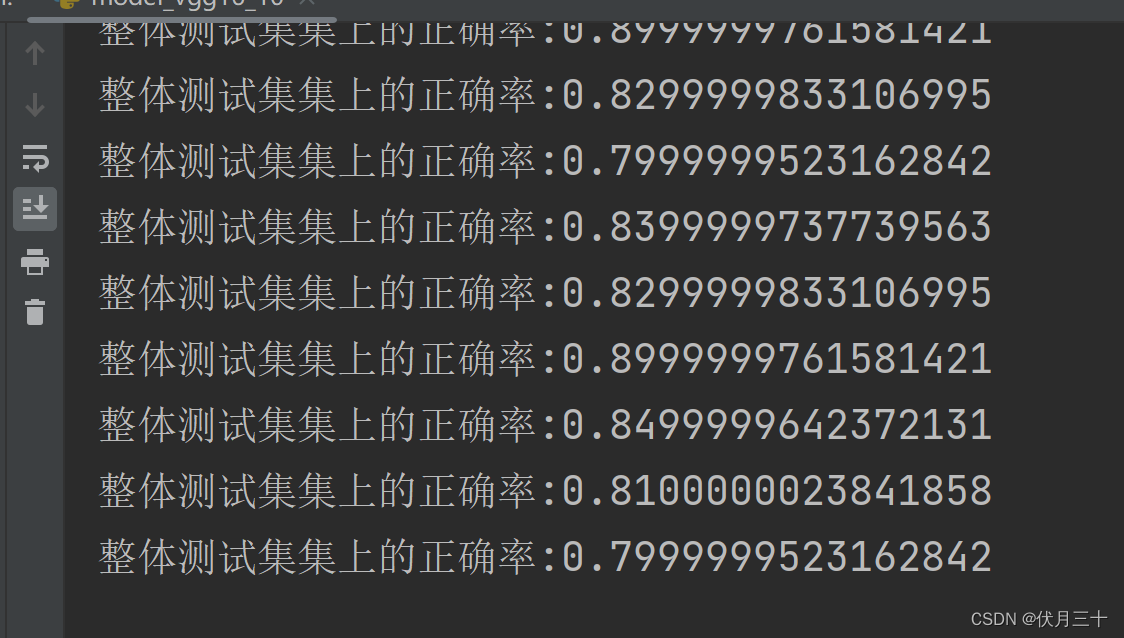
边栏推荐
猜你喜欢



随机推荐
Visual studio代码中有红色波浪线解决办法
LLVM系列第九章:控制流语句if-else
每周招聘|PostgreSQL专家,年薪60+,高能力高薪资
LLVM系列第四章:逻辑代码块Block
6. How to use the CardView production card layout effect
[VCU] Detailed S19 file (S-record)
spark on yarn
MySQL知识总结 (五) 锁
Flink时间和窗口
华为防火墙
浮点数的运算方法
拥抱Jetpack之印象篇
UIWindow的makeKeyAndVisible不调用rootviewController 的viewDidLoad的问题
Spark_DSL
Redis-01-Nosql概述
使用flutter小记
利用红外-可见光图像数据集OTCBVS打通图像融合、目标检测和目标跟踪
我理解的学习金字塔
标签加id 和 加号 两个文本框 和一个var 赋值
什么是 Web 3.0:面向未来的去中心化互联网