当前位置:网站首页>MapReduce流程
MapReduce流程
2022-08-02 14:05:00 【boyzwz】
mapreduce 必须构建在hdfs之上的一种大数据离线分布式计算框架
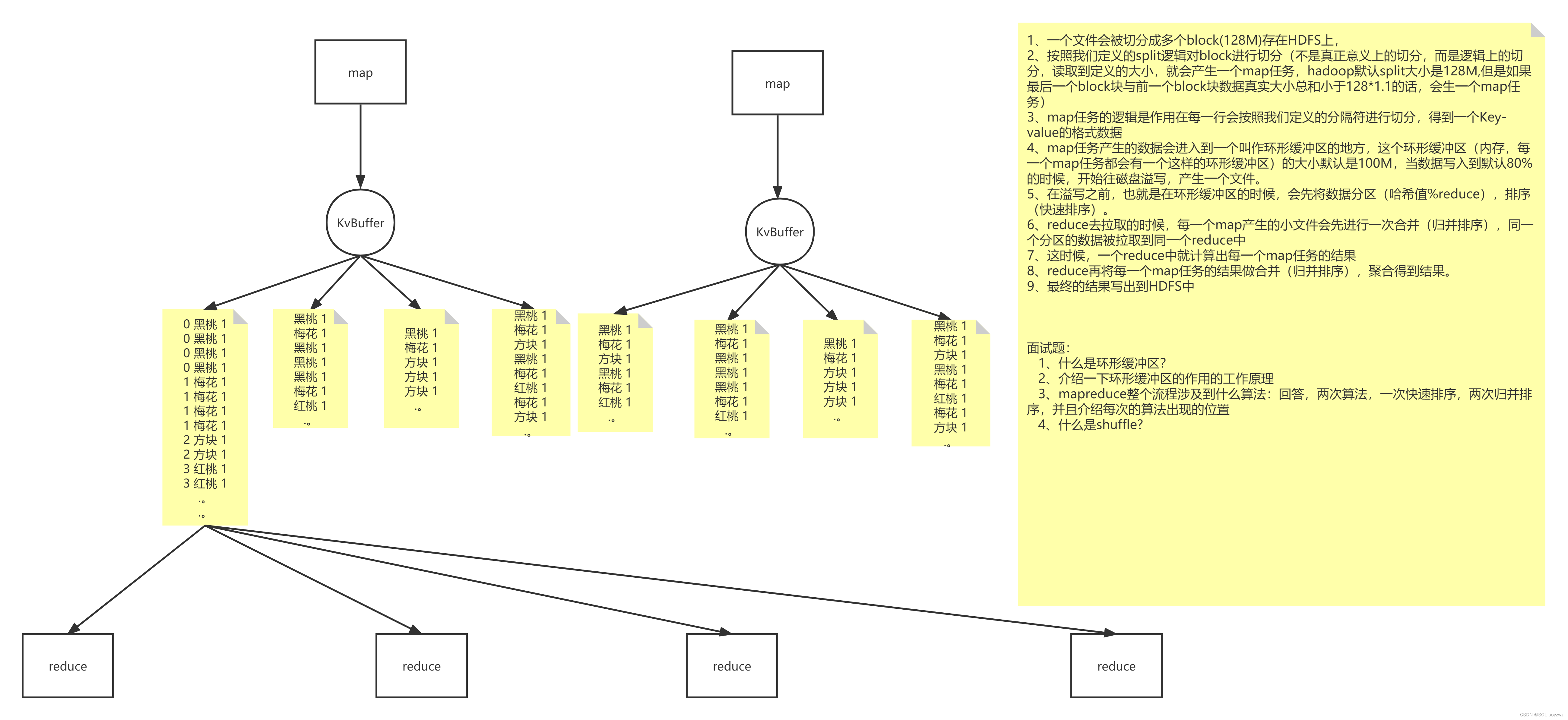
切片 split:
在 MapReduce 中,执行 Map 之前,首先将输入文件按指定大小 split 切分成小片(是逻辑上的切片,而不是真正意义上的切分) 默认为 128M,每切分一小片生成一个 Map 任务(即每读取文件 128M 产生一个 Map 任务),当最后一片与上一个切片大小加起来小于128*1.1时,则会这两片生成一个 Map 任务。
split 和 block 大小默认一致,为了减少由于 split 和 block 之间大小不一致,导致的多余的网络之间的传输。
执行 MapTask:
map 默认从所属切片读取数据,每次读取一行(默认读取器)到内存中(map 种的逻辑作用在每一行上)。
每一个 Map 任务都有一个环形缓冲区(默认100M),Map 任务产生的数据会写入环形缓冲区(内存中),当写入的数据达到缓冲区的阈值时(默认80%即80M),则会开始将缓冲区中的数据向磁盘中溢写(每次溢写都会产生一个新的溢写文件),而Map中的数据则可以继续写入缓冲区。
在溢写到磁盘之前,会对数据进行分区,排序(快速排序)
在 reduce 拉取溢写文件之前,每个 Map 任务产生的溢写文件会进行一次合并(归并排序),生成一个大的溢写文件。
执行 ReduceTask:
当 Map 任务完成后,Reduce 从每一个 Map 拉取数据(同一个分区的数据被拉取到同一个 Reduce中),那么每个 map 都会产生一个小文件 。
Reduce 在对每一个 map 任务的结果进行合并(归并排序),聚合得到结果。
MapReduce 工作过程中, Map 阶段处理的数据如何传递给 Reduce 阶段,这是 MapReduce 框架中关键的一个过程,这个过程叫作 Shuffle 。
MapReduce的资源调度:
MapReduce 1.x:
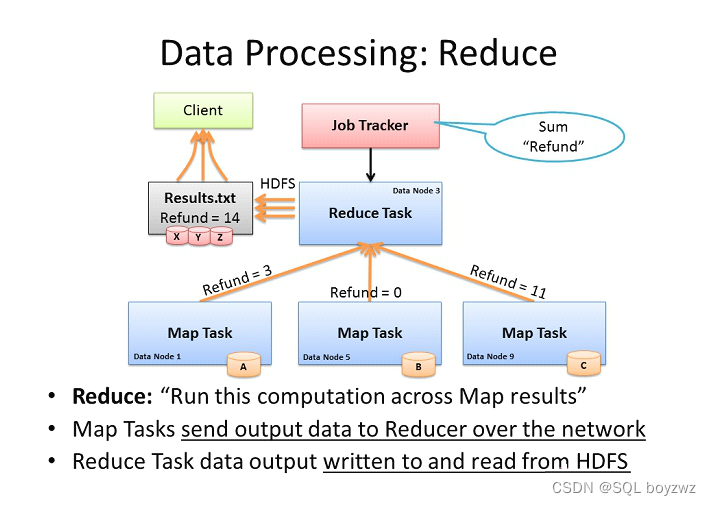
JobTracker:
主节点,单点,负责调度所有的作用和监控整个集群的资源负载。
MapReduce 2.x:
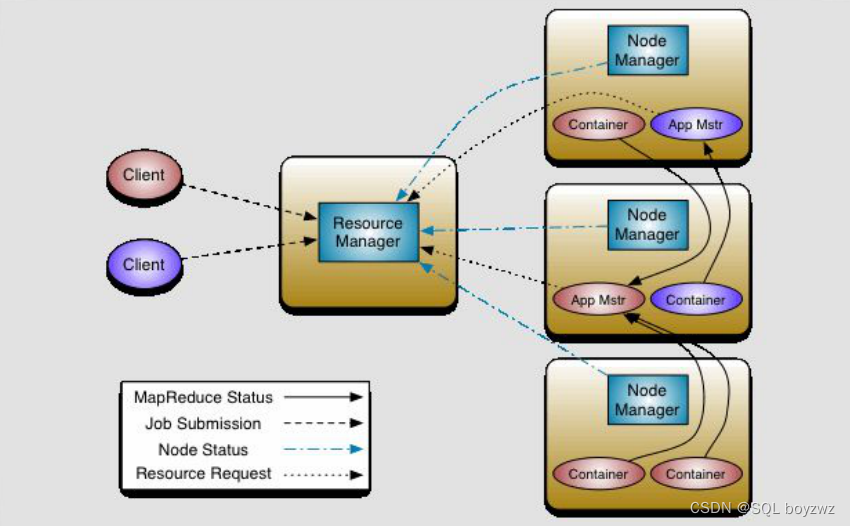
核心思想:将 MRv1 中 JobTracker 的资源管理和任务调度两个功能分开,分别由ResourceManager 和 ApplicationMaster 进程实现
ResourceManager:
主节点,负责整个集群的资源管理和调度。
ApplicationMaster:
负责与 ResourceManager 协商资源,并和 NodeManager 协同来执行和监控 Container。
边栏推荐
猜你喜欢



随机推荐
jwt (json web token)
无人驾驶综述:等级划分
主存储器(一)
MySQL知识总结 (五) 锁
数据乱码问题—更改mysql字符编码
C语言日记 5 运算符和表达式
C语言日记 7 输入/输出格式控制
What's wrong with running yolov5 (1) p, r, map are all 0
猜数字游戏,猜错10次关机(srand、rand、time)随机数生成三板斧(详细讲解!不懂问我!)
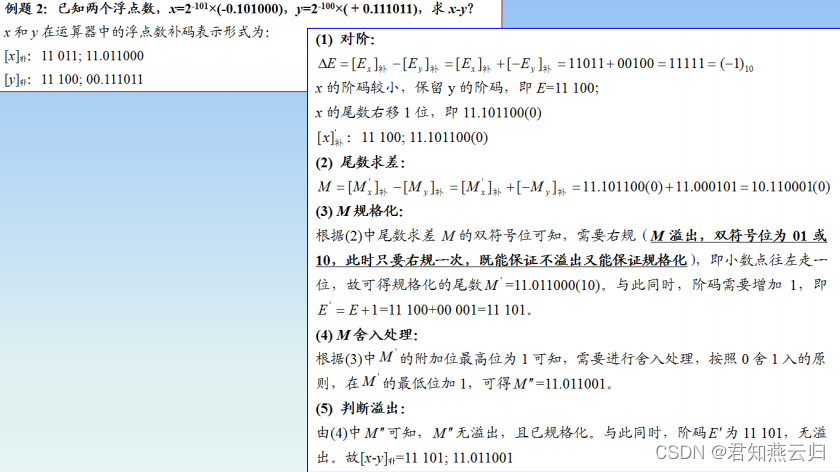
存储系统Cache(知识点+例题)
static关键字3种作用,简单粗暴对比,好理解
HBuilderX 核心插件安装提示:“插件XXX下载失败,请检查网络”问题的解决办法
Network pruning (1)
宏定义问题记录day2
MySQL知识总结 (十一) MySql 日志,数据备份,数据恢复
MySQL知识总结 (三) 索引
[ROS] (02) Create & compile ROS package Package
OpenCart迁移到其他服务器
Scala学习总结
[VCU] Detailed S19 file (S-record)