当前位置:网站首页>MySQL知识总结 (三) 索引
MySQL知识总结 (三) 索引
2022-08-02 14:05:00 【weixin_45773632】
文章目录
数据结构
1. 什么是索引?
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。
索引是一种数据结构。数据库索引,是数据库管理系统中一个有序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
更通俗的说,索引就相当于目录。为了方便查找书中的内容,通过对内容建立索引形成目录。索引是一个文件,它是要占据物理空间的。
2. 索引有哪些优缺点?
索引的优点
- 可以大大加快数据的检索速度(大大减少检索的数据量),这也是创建索引的最主要的原因。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
索引的缺点
- 时间方面:创建索引和维护索引要耗费时间,具体地,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,会降低增/改/删的执行效率;
- 空间方面:索引需要占物理空间。
但是,使用索引一定能提高查询性能吗?
大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
3. 索引有哪几种?
主键索引: 数据列不允许重复,不允许为NULL,一个表只能有一个主键。
唯一索引: 数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。
- 可以通过
ALTER TABLE table_name ADD UNIQUE (column);创建唯一索引 - 可以通过
ALTER TABLE table_name ADD UNIQUE (column1,column2);创建唯一联合索引
普通索引: 基本的索引类型,没有唯一性的限制,允许为NULL值。
- 可以通过
ALTER TABLE table_name ADD INDEX index_name (column);创建普通索引 - 可以通过
ALTER TABLE table_name ADD INDEX index_name(column1, column2, column3);创建联合索引
全文索引: 是目前搜索引擎使用的一种关键技术。
- 可以通过
ALTER TABLE table_name ADD FULLTEXT (column);创建全文索引
4. 创建索引、删除索引、查看索引
4.1 创建索引:
(1) 方式一:使用 alter语句
ALTER TABLE用来创建所有类型索引:
1.添加主键索引
ALTER TABLE `table_name` ADD PRIMARY KEY (`column`)
2.添加唯一索引
ALTER TABLE `table_name` ADD UNIQUE (`column`)
3.添加全文索引
ALTER TABLE `table_name` ADD FULLTEXT (`column`)
4.添加普通索引
ALTER TABLE `table_name` ADD INDEX index_name (`column` )
5.添加联合索引
ALTER TABLE `table_name` ADD INDEX index_name (`column1`, `column2`, `column3`)
(2)方式二:使用 CREATE INDEX 语句
CREATE INDEX可对表增加普通索引或UNIQUE索引:
语法格式:
CREATE INDEX index_name ON table_name (column_list);
CREATE UNIQUE INDEX index_name ON table_name (column_list);
4.2 查看索引
语法:
show index from <table_name> [from <database_name>]
例子:
SHOW INDEX FROM student FROM test; 语句表示查看 test 数据库中 student 数据表的索引。
4.3 删除索引
1) 使用 DROP INDEX 语句
语法格式:
DROP INDEX <索引名> ON <表名> (只能用于删除普通索引)
2) 使用 ALTER TABLE 语句
根据索引名删除普通索引、唯一索引、全文索引:alter table 表名 drop KEY 索引名
alter table user_index drop KEY name;
alter table user_index drop KEY id_card;
alter table user_index drop KEY information;
删除主键索引:alter table 表名 drop primary key(因为主键只有一个)。这里值得注意的是,如果主键自增长,那么不能直接执行此操作(自增长依赖于主键索引):
5. 图解Mysql索引的数据结构
图解Mysql索引的数据结构!
MySQL索引底层数据结构及原理深入分析
5.1 关于索引
索引是帮助Mysql更加高效获取数据的一种数据结构,索引的使用很简单,但是如果不能理解索引底层的数据结构的话,就谈不上去优化索引了。
5.2 B+树
Mysql的索引用的是B+树,它具有这样的几个特点:
- 数据都存储在叶子节点中、非叶子节点只存储索引
- 叶子节点中包含所有的索引
- 每个小节点的范围都在大节点之间
- 叶子节点用指针相连,提高访问性能,比如条件是
>或者<的查询就可以直接按指针找(Mysql中的B+树叶子节点中的指针是双向指针)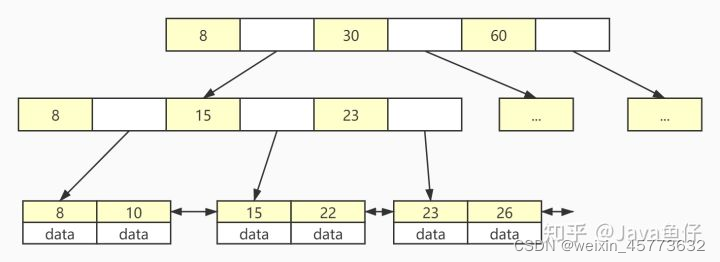
B+树的数据结构如图所示,首先非叶子节点只存储索引,且每个指针所指向的节点最左边的索引都是该指针对应的索引值,比如头节点的第一个索引值8,指向的非叶子节点的第一个索引值也是8。
5.3 为什么索引这么快?
索引可以支撑千万级表的快速查找,为什么呢?下面就来解释一下:
show GLOBAL STATUS like 'Innodb_page_size'
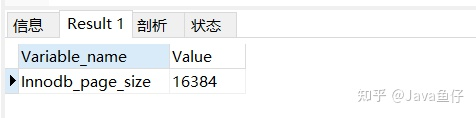
在Innodb中,默认的innodb_page_size大小为16kb,这就相当于上面每一个节点的大小默认情况下是16kb。一个索引值的大小为8B,索引后的指针所占大小为4B,因此可以解算出一个节点中大约可以存储1170个索引。
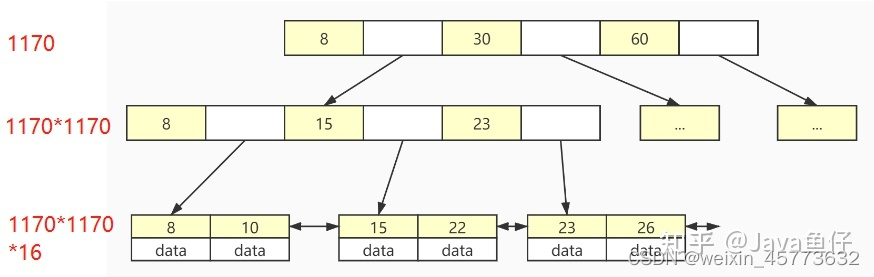
对于叶子节点,由于存储了数据,我们可以大方地估计每个数据的大小为1kb,相当于在叶子节点中每个节点可以存储16个数据。
这样就可以计算出一个三层的B+树结构的索引一共可以存储1170*1170*16=2190万**条数据,这就意味着只需要三次磁盘IO,就可以检索两千万条数据,由此可见索引可以支撑千万级表的快速查找。
5.4 Innodb索引的实现
Mysql中的存储引擎有Innodb和Myisam两种,两种索引的实现底层虽然都是B+树,但是实现形式还是略有不同。
Innodb属于聚簇索引,即叶子节点包含了完整的数据记录。下面这张图是innodb的主键索引,所有的数据都放在叶子节点中。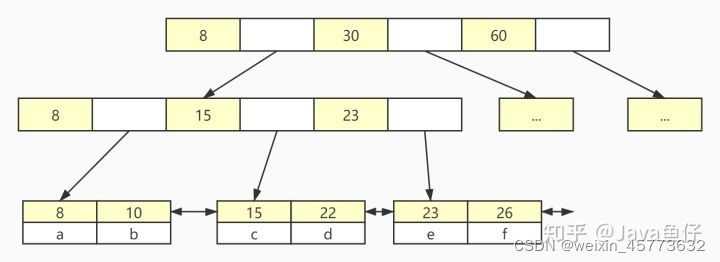
Innodb要求表必须有主键,并且推荐使用整型的自增主键,这也和他索引的实现有关,使用整型可以更好的进行B+树的排序,同时采用自增的方式可以在插入数据时将数据插入到最后一个节点的后一个,而不用对已产生的索引拆分。
非主键索引和主键索引略有不通,非主键索引的叶子节点存储的是主键的key值: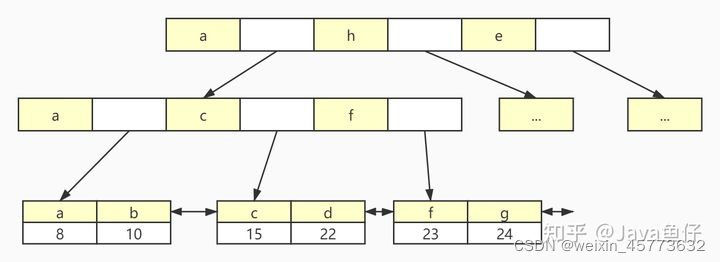
采用这种方式保持了数据的一致性,当新增一条数据时,只需要在主键索引处修改数据即可,而不会出现每个索引各自维护的情况。第二个优势是节省了存储的空间,数据只需要保存一份即可。
5.5 MyIsam索引的实现
Myisam索引文件和数据文件是分离的,在MyIsam存储引擎中,新建一张表后会在磁盘中增加三个文件:
.frm 文件存储的是表结构,.MYI文件存储的是B+树的索引表,MYD存储的是数据,我通过下面这张表展示MyIsam索引: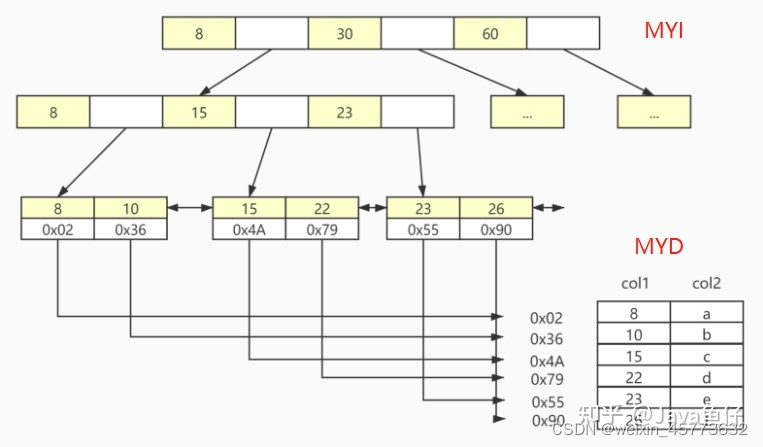
6. 为什么InnoDB表必须有主键?
Mysql索引设计如此…,mysql设计的就是innoDB把你的数据和主键索引用B+Tree来组织的,没有主键他的数据就没有一个结构来存储。
7. 创建索引的原则 (重中之重)
索引虽好,但也不是无限制的使用,最好符合一下几个原则
1) 最左前缀匹配原则
2)较频繁作为查询条件的字段才去创建索引
3)更新频繁字段不适合创建索引
4)若是不能有效区分数据的列不适合做索引列(如性别,男、女、未知、最多也就三种,区分度实在太低)
5)尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
6)定义有外键的数据列一定要建立索引。
7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
8)对于定义为text、image和bit的数据类型的列不要建立索引。
8. 创建索引时需要注意什么?
- 非空字段:应该指定列为NOT NULL,除非你想存储NULL。在mysql中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值;
- 取值离散大的字段:(变量各个取值之间的差异程度)的列放到联合索引的前面,可以通过count()函数查看字段的差异值,返回值越大说明字段的唯一值越多字段的离散程度高;
- 索引字段越小越好:数据库的数据存储以页为单位一页存储的数据越多一次IO操作获取的数据越大效率越高。
9. 使用索引查询一定能提高查询的性能吗?为什么
通常,通过索引查询数据比全表扫描要快。但是我们也必须注意到它的代价。
- 索引需要空间来存储,也需要定期维护, 每当有记录在表中增减或索引列被修改时,索引本身也会被修改。 这意味着每条记录的INSERT,DELETE,UPDATE将为此多付出4,5 次的磁盘I/O。 因为索引需要额外的存储空间和处理,那些不必要的索引反而会使查询反应时间变慢。使用索引查询不一定能提高查询性能,索引范围查询(INDEX RANGE SCAN)适用于两种情况:
- 基于一个范围的检索,一般查询返回结果集小于表中记录数的30%
- 基于非唯一性索引的检索
- 索引就是为了提高查询性能而存在的,如果在查询中索引没有提高性能,只能说是用错了索引,或者讲是场合不同
10. 百万级别或以上的数据如何删除(优先删除索引)
关于索引:由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所以当我们对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。所以,在我们删除数据库百万级别数据的时候,查询MySQL官方手册得知删除数据的速度和创建的索引数量是成反的。
- 所以我们想要删除百万数据的时候可以先删除索引(此时大概耗时三分多钟)
- 然后删除其中无用数据(此过程需要不到两分钟)
- 删除完成后重新创建索引(此时数据较少了)创建索引也非常快,约十分钟左右。
- 与之前的直接删除绝对是要快速很多,更别说万一删除中断,一切删除会回滚。那更是坑了。
11. 前缀索引
语法:index(field(10)),使用字段值的前10个字符建立索引,默认是使用字段的全部内容建立索引。
前提:前缀的标识度高。比如密码就适合建立前缀索引,因为密码几乎各不相同。
实操的难度:在于前缀截取的长度。
我们可以利用select count(*)/count(distinct left(password,prefixLen));,通过从调整prefixLen的值(从1自增)查看不同前缀长度的一个平均匹配度,接近1时就可以了(表示一个密码的前prefixLen个字符几乎能确定唯一一条记录)
12. 什么是最左前缀原则?什么是最左匹配原则
顾名思义,就是最左优先,在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
13. 什么是聚簇索引?何时使用聚簇索引与非聚簇索引
- 聚簇索引(INNODB):将数据与索引放到了一起,找到索引也就找到了数据
- 非聚簇索引(MyIsam):索引的存储和数据的存储是分离的,也就是说找到了索引但没找到数据,需要根据索引上的值(主键)再次回表查询,非聚簇索引也叫做辅助索引。
下面我们创建了一个学生表,做三种查询,来说明什么情况下是聚簇索引,什么情况下不是。
create table student (
id bigint,
no varchar(20) ,
name varchar(20) ,
address varchar(20) ,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `idx_no` (`no`) USING BTREE
)ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
第一种,直接根据主键查询获取所有字段数据,此时主键是聚簇索引,因为主键对应的索引叶子节点存储了id=1的所有字段的值。
select * from student where id = 1
第二种,根据编号查询编号和名称,编号本身是一个唯一索引,但查询的列包含了学生编号和学生名称,当命中编号索引时,该索引的节点的数据存储的是主键ID,需要根据主键ID重新查询一次,所以这种查询下no不是聚簇索引
select no,name from student where no = 'test'
第三种,我们根据编号查询编号(有人会问知道编号了还要查询?要,你可能需要验证该编号在数据库中是否存在),这种查询命中编号索引时,直接返回编号,因为所需要的数据就是该索引,不需要回表查询,这种场景下no是聚簇索引
select no from student where no = 'test'
总结:
主键一定是聚簇索引,MySQL的InnoDB中一定有主键。MyisAM引擎没有聚簇索引。
14.非聚簇索引一定会回表查询吗?
不一定,这涉及到查询语句所要求的列是否全部命中了索引,如果全部命中了索引,那么就不必再进行回表查询。
举个简单的例子,假设我们在员工表的年龄上建立了索引,那么当进行select age from employee where age < 20的查询时,在索引的叶子节点上,已经包含了age信息,不会再次进行回表查询。
15. 唯一索引比普通索引快吗?
唯一索引不一定比普通索引快, 还可能慢.
- 查询时, 在未使用 limit 1 的情况下, 在匹配到一条数据后, 唯一索引即返回, 普通索引会继续匹配下一条数据, 发现不匹配后返回. 如此看来唯一索引少了一次匹配, 但实际上这个消耗微乎其微.
- 更新时, 这个情况就比较复杂了. 普通索引将记录放到
change buffer中语句就执行完毕了. 而对唯一索引而言, 它必须要校验唯一性, 因此, 必须将数据页读入内存确定没有冲突, 然后才能继续操作. 对于写多读少的情况, 普通索引利用change buffer有效减少了对磁盘的访问次数, 因此普通索引性能要高于唯一索。
16. 联合索引是什么?为什么需要注意联合索引中的顺序?
MySQL可以使用多个字段同时建立一个索引,叫做联合索引。在联合索引中,如果想要命中索引,需要按照建立索引时的字段顺序挨个使用,否则无法命中索引。
具体原因为:
MySQL使用索引时需要索引有序,假设现在建立了"name,age,school"的联合索引,那么索引的排序为: 先按照name排序,如果name相同,则按照age排序,如果age的值也相等,则按照school进行排序。
当进行查询时,此时索引仅仅按照name严格有序,因此必须首先使用name字段进行等值查询,之后对于匹配到的列而言,其按照age字段严格有序,此时可以使用age字段用做索引查找,以此类推。因此在建立联合索引的时候应该注意索引列的顺序,一般情况下,将查询需求频繁或者字段选择性高的列放在前面。此外可以根据特例的查询或者表结构进行单独的调整。
17. 索引失效场景
边栏推荐
- Unit 6 meet ORM
- mysql
- YOLOv7使用云GPU训练自己的数据集
- OpenCart迁移到其他服务器
- Caused by: org.gradle.api.internal.plugins.PluginApplicationException: Failed to apply plugin [id ‘c
- C语言待解决
- Verilog学习 系列
- The 2nd China Rust Developers Conference (RustChinaConf 2021~2022) Online Conference Officially Opens Registration
- Visual Studio配置OpenCV之后,提示:#include<opencv2/opencv.hpp>无法打开源文件
- getUserProfile接口不显示用户性别和地区
猜你喜欢
![[ROS] (01) Create ROS workspace](/img/2a/11e5023ef6d052d98b4090d2eea017.png)
[ROS] (01) Create ROS workspace
C语言一维数组练习——将一个字符串中的某个字符替换成其它字符

Deep learning framework pytorch rapid development and actual combat chapter4
【c】小游戏---五子棋之井字棋雏形

run yolov5
YOLOv7 uses cloud GPU to train its own dataset
Deep learning framework pytorch rapid development and actual combat chapter3

St. Regis Takeaway Notes - Lecture 05 Getting Started with Redis
存储系统Cache(知识点+例题)
8580 Merge linked list
随机推荐
浏览器报错数字代表的大概意思
paddleocr window10 first experience
Flask request application context source code analysis
Flask framework in-depth two
鼠标右键菜单栏太长如何减少
线性代数期末复习存档
Network pruning (1)
无人驾驶综述:摘要
宝塔面板搭建小说CMS管理系统源码实测 - ThinkPHP6.0
Flask contexts, blueprints and Flask-RESTful
uniapp小程序禁止遮罩弹窗下的页面滚动的完美解决办法
8581 Linear linked list inversion
[ROS] (02) Create & compile ROS package Package
jwt (json web token)
verilog学习|《Verilog数字系统设计教程》夏宇闻 第三版思考题答案(第十二章)
ng-style:动态控制样式
[ROS] (01) Create ROS workspace
芝诺悖论的理解
Deep learning framework pytorch rapid development and actual combat chapter4
mysql