当前位置:网站首页>Flink前期代码结构
Flink前期代码结构
2022-08-02 14:05:00 【大学生爱编程】
1. 小知识
1.可以做离线和实时但是侧重于实时,flink绝对的一条条处理
2.流处理:数据具体大小未知,进行简单操作,及时响应不会结束
批处理:数据大小固定,可以进行复杂操作,需要离线处理
3.为了统一API,flink中数据都视为流,同一套代码可以进行流批处理统一
无界流:有开始没有定义结束,持续处理无界流,在摄取事件后立即处理事件,需要按照事件发生的顺序处理事件
有界流:有定义开始和结束,在执行计算之前摄取所有数据来处理有界流,处理有界流不需要有序摄取,因为可以始终对有界数据集进行排序,有界流的处理也成为批处理
将hdfs的数据也视为有界流
4.MQ:消息队列 kafka
5.离线计算与实时计算:
离线:数据量大周期长,数据是固定的,可进行复杂操作,方便查询计算结果,可以进行多次操作
实时:数据实时到达,数据到达次序独立,无法预估数据容量,再次提取数据的代价大(因为流处理程序时不停止的,可能已经处理一年的数据了再重写代码成本太高)
6.Flink面临的难点:
任务失败到重启之间的时间内数据如何不丢失?启动之前的数据如何保证只处理一次?
7.什么是Flink?
分布式计算引擎,侧重于实时计算,对无界和有界流进行有状态计算(进行累加)
8.事件(数据)驱动,有数据来了就计算{事件时间,状态计算,唯一一次计算,快速计算,基于内存}
9.运行方式:local,cluster,cloud
10.学习重点:DataStreamAPI SQL Stateful Stream Processing
11.在Flink中SQL比DSL好用
12.读取数据(source),处理数据(transformation),保存数据(sink)
2. idea中的操作
2.1前期的依赖
新建模块,独立依赖,独立配置
版本的控制:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.15.0</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<scala.version>2.12.7</scala.version>
<log4j.version>2.17.1</log4j.version>
</properties>
前期的三个依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-walkthrough-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version} </artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
2.2 加个插件将Java和Scala分开写代码
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- Scala Compiler -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<args>
<arg>-nobootcp</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<version>1.7</version>
<executions>
<!-- Add src/main/scala to eclipse build path -->
<execution>
<id>add-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>src/main/scala</source>
</sources>
</configuration>
</execution>
<!-- Add src/test/scala to eclipse build path -->
<execution>
<id>add-test-source</id>
<phase>generate-test-sources</phase>
<goals>
<goal>add-test-source</goal>
</goals>
<configuration>
<sources>
<source>src/test/scala</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.3 写代码的基本操作
import org.apache.flink.streaming.api.scala._
object Demo1WordCount {
def main(args: Array[String]): Unit = {
/**
* 创建flink环境
*/
val env: StreamExecutionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1) //设置并行度
/**
* 读取数据
*/
val linesDS: DataStream[String] =env.socketTextStream("master",8888)
/**
* 统计单词数量
*/
val wordDS: DataStream[String] =linesDS.flatMap((line:String)=>line.split(","))
val kvDS: DataStream[(String, Int)] =wordDS.map(word=>(word,1))
val groupDS: KeyedStream[(String, Int), String] =kvDS.keyBy(kv=>kv._1) //按照单词进行分组
val countDS: DataStream[(String, Int)] =groupDS.sum(1)
/**
* 查看结果
*/
countDS.print()
/**
* 启动flink
*/
env.execute()
}
}
结果:
1> (java,1)
1> (java,2)
1> (java,3)
1> (java,4)
4> (hadoop,1)
1> (java,5)
4> (flink,1)
3. Spark和Flink的区别
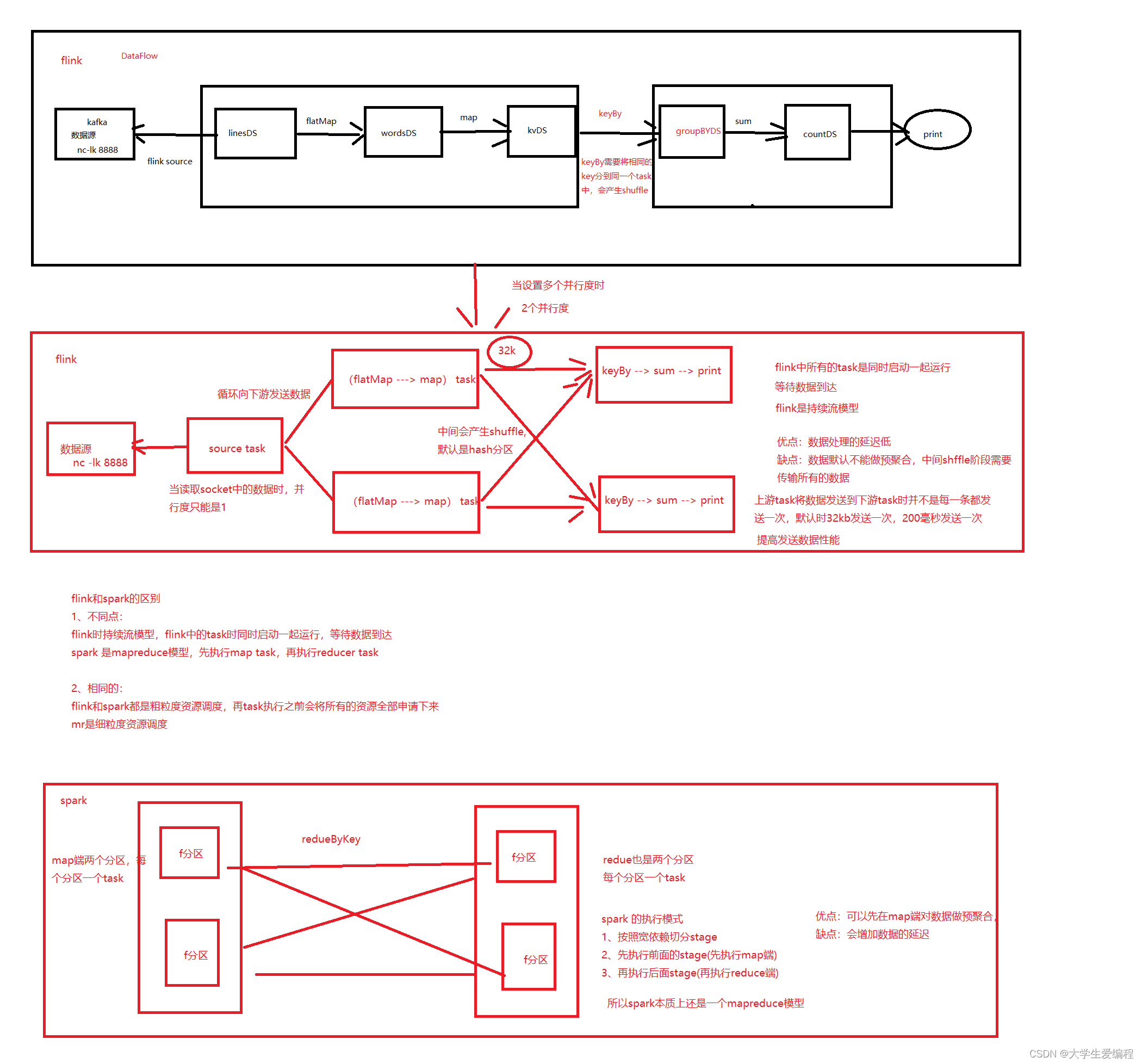
1.因为spark侧重批处理,所以传来一批数据可以在map端进行预聚合,减少shuffle阶段的数据量,先执行map端的task再执行reduce端的task,底层是MR模型
2.而侧重于流处理的flink是同时开启所有的task等待数据的到达,是持续流模型,数据处理的延迟低但是数据默认不能做预聚合,中间shuffle阶段要传输所有数据并且数据不会落地到磁盘
3.flink中上游的task将数据发送到下游task时并不是每一条发送一次,默认时32kb或者200毫秒发送一次数据,提高发送数据的性能
4.spark和flink是粗粒度资源调度,mr是细粒度的
在创建环境时可以设置:
env.setParallelism(1) 并行度
env.setBufferTimeout(5000) 延迟时间默认是200
4. Source(官网1.9.1版更全)
4.1基于本地集合
1.是有界流,执行完毕后会结束任务
2.默认仍然当作流处理的,每一条都会处理
设置执行模式:(新版本才有)
批处理:env.setRuntimeMode(RuntimeExecutionMode.BATCH) 仅可处理有界流
流处理:env.setRuntimeMode(RuntimeExecutionMode.STREAM) 有界流或无界流都可以处理
两者的展示结果不同:一个是汇总的,一个是一条条的
import org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala._
object Demo1ListSource {
def main(args: Array[String]): Unit = {
//创建flink环境
val env: StreamExecutionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment
env.setRuntimeMode(RuntimeExecutionMode.BATCH) //设置批处理模式
//基于本地的集合 有界流
val linesDS: DataStream[String] =env.fromCollection(List("java,hadoop","java,flink","java,flink"))
linesDS
.flatMap(_.split(","))
.map(word=>(word,1))
.keyBy(kv=>kv._1)
.sum(1)
.print()
env.execute()
4.2 基于文件
import org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.streaming.api.scala._
object Demo2FileSource {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment
env.setRuntimeMode(RuntimeExecutionMode.BATCH)
/**
* 基于集合构建有界流
*/
val studentDS: DataStream[String] =env.readTextFile("data/students.txt")
//切分成数组,取出班级直接构建kv二元组
val clazzDS: DataStream[(String, Int)] =studentDS.map(stu=>(stu.split(",")(4),1))
val clazzNumDS: DataStream[(String, Int)] =clazzDS
.keyBy(kv=>kv._1)
.sum(1)
clazzNumDS.print()
env.execute()
}
}
4.3 基于网络套接字
无界流只能使用流处理模式,默认都是无界流
4.4 使用自定义source读MySQL中的数据(java代码能连接的数据源都能读)
数据库中的数据根据解析数据时是否结束循环来判断有界无界流 ,但都采用流处理模式
object Demo4TextStream {
def main(args: Array[String]): Unit = {
//创建flink环境
val env: StreamExecutionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment
val mysqlDS: DataStream[String] =env.addSource(new MysqlSource) //传接口的子类,接收上游的数据
mysqlDS //处理上游传来的数据
.map(stu=>(stu.split("\t")(4),1))
.keyBy(ky=>ky._1)
.sum(1)
.print()
env.execute() //执行flink
}
//继承SourceFunction[String]接口,指定返回类型,实现方法
class MysqlSource extends SourceFunction[String]{
/**
* 读取外部数据的方法
* @param sourceContext 上下文对象 将读取到的数据发送到下游
* 仅执行一次
*/
override def run(sourceContext: SourceFunction.SourceContext[String]): Unit = {
//使用jdbc读取MySQL数据,将读取到的数据发送到下游
Class.forName("com.mysql.jdbc.Driver")
val con: Connection =DriverManager.getConnection("jdbc:mysql://master:3306/bigdata","root","123456")
//编写sql
val stat: PreparedStatement =con.prepareStatement("select * from students")
val resultSet: ResultSet =stat.executeQuery() //执行查询
//解析数据
while(resultSet.next()){
val id: Long =resultSet.getLong("id")
val name: String =resultSet.getString("name")
val age: Long =resultSet.getLong("age")
val gender: String =resultSet.getString("gender")
val clazz: String =resultSet.getString("clazz")
//通过sourceContext将数据发送给下游
sourceContext.collect(s"$id\t$name\t$age\t$gender\t$clazz")
}
stat.close() //释放
con.close()
}
//任务取消时用于回收资源
override def cancel(): Unit = {
}
5. Transformation(注意导包,有一个特殊包)
5.1 Map
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.scala._
val env: StreamExecutionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment
val studentDS: DataStream[String] = env.readTextFile("data/students.txt")
//取出性别人数 ,匿名内部类实现方法
val kvDS: DataStream[(String, Int)] =studentDS.map(new MapFunction[String,(String,Int)]{
override def map(t: String): (String, Int) = {
val gender: String =t.split(",")(3)
(gender,1)
}
})
kvDS.print()
env.execute()
5.2 flatMap
import org.apache.flink.api.common.functions.FlatMapFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
传入一条数据返回多条数据,一行转多行
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val linesDS: DataStream[String] = env.readTextFile("data/words.txt")
val wordsDS: DataStream[String] =linesDS.flatMap((new FlatMapFunction[String,String]{
override def flatMap(t: String, collector: Collector[String]): Unit = {
val split: Array[String] =t.split(",")
for(word <- split){
collector.collect(word)
}
}
}))
wordsDS.print()
env.execute()
5.3 filter
import org.apache.flink.api.common.functions.FilterFunction
import org.apache.flink.streaming.api.scala._
//读取文件
val linesDS: DataStream[String] =env.readTextFile("data/students.txt")
/**
* 传入一条数据返回一个布尔值,true的保留
*/
val filterDS: DataStream[String] =linesDS.filter(new FilterFunction[String]{
override def filter(t: String): Boolean = {
val gender: String =t.split(",")(3)
"女".equals(gender)
}
})
filterDS.print()
env.execute()
5.4 keyBy
import org.apache.flink.api.java.functions.KeySelector
import org.apache.flink.streaming.api.scala._
//创建flink环境 读取socket套接字
val env: StreamExecutionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment
val linesDS: DataStream[String] =env.socketTextStream("master",8888)
val wordsDS: DataStream[String] =linesDS.flatMap(word=>word.split(","))
val kvDS: DataStream[(String, Int)] =wordsDS.map(word=>(word,1))
// 读取文件中的单词,然后进行统计
// 先进行keyBy,在进行聚合
val keyedStream: KeyedStream[(String, Int), String] =kvDS.keyBy(new KeySelector[(String,Int),String]{
override def getKey(in: (String, Int)): String = {
in._1
}
})
val sumDS: DataStream[(String, Int)] =keyedStream.sum(1)
sumDS.print()
env.execute()
5.5 window
导包把整个包都导进来
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
object Window {
def main(args: Array[String]): Unit = {
//创建flink环境,读取socket内容,统计
val env: StreamExecutionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment
val linesDS: DataStream[String] =env.socketTextStream("master",8888)
val wordsDS: DataStream[String] =linesDS.flatMap(_.split(","))
val kvDS: DataStream[(String, Int)] =wordsDS.map(word=>(word,1))
/**
* 统计最近10秒的单词数量,每5秒统计一次
* 分组之后再根据时间窗口进行一次分组然后再聚合
*/
val keyByDS: KeyedStream[(String, Int), String] =kvDS.keyBy(kv=>kv._1)
val windowDS: WindowedStream[(String, Int), String, TimeWindow] = keyByDS.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
val countDS: DataStream[(String, Int)] = windowDS.sum(1)
countDS.print()
env.execute()
}
}
5.6 union
导包把整个包都导进来
import org.apache.flink.streaming.api.scala._
object Union {
def main(args: Array[String]): Unit = {
//创建flink环境
val env: StreamExecutionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment
val ds1: DataStream[Int] =env.fromCollection(List(1,2,3,4,5))
val ds2: DataStream[Int] =env.fromCollection(List(2,3,4,5,6))
//进行union的类型要一致
val unionDS: DataStream[Int] =ds1.union(ds2)
unionDS.print()
env.execute()
}
}
6. 保存数据–sink
结果写到文件中:
老版本:
countDS.writeAsText("data/flink/clazz_num")
新版本:(犯了个错误,主类名和包中的类名冲突)
至少包含多少时间的数据
多少时间没有新的数据
数据量达到多少
import org.apache.flink.api.common.RuntimeExecutionMode
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.configuration.MemorySize
import org.apache.flink.connector.file.sink.FileSink
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy
import org.apache.flink.streaming.api.scala._
import java.time.Duration
object Demo1FileSink {
def main(args: Array[String]): Unit = {
//创建flink环境
val env: StreamExecutionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment
//设置处理模式 批处理
env.setRuntimeMode(RuntimeExecutionMode.BATCH)
//读取数据 统计班级人数 保存结果
val kvDS: DataStream[(String, Int)] =env.readTextFile("data/students.txt").map(stu=>(stu.split(",")(4),1))
val countDS: DataStream[(String, Int)] =kvDS.keyBy(kv=>kv._1).sum(1)
// countDS.writeAsText("data/flink/clazz_num")
/**
* 新版本指定路径编码格式指定滚动生成的策略
*/
val sink: FileSink[(String, Int)] = FileSink
.forRowFormat(new Path("data/flink/clazz_num"), new SimpleStringEncoder[(String, Int)]("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
//至少包含多少时间的数据
.withRolloverInterval(Duration.ofSeconds(10))
//多少时间没有新的数据
.withInactivityInterval(Duration.ofSeconds(10))
//数据达到多大
.withMaxPartSize(MemorySize.ofMebiBytes(1))
.build())
.build()
//使用sink
countDS.sinkTo(sink)
env.execute()
}
}
6.2自定义sink
//使用自定义sink
linesDS.addSink(new SinkFunction[String]{
override def invoke(value: String, context: SinkFunction.Context): Unit = {
println(value)
}
})
env.execute()
6.3自定义sink2
socket中的数据保存到MySQL中
SinkFunction
object MysqlSink1 {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
val countDS: DataStream[(String, Int)] =linesDS.flatMap(line=>line.split(","))
.map(word=>(word,1)).keyBy(_._1).sum(1)
countDS.addSink(new MysqlSink())
env.execute()
}
class MysqlSink extends SinkFunction[(String, Int)]{
override def invoke(value: (String, Int), context: SinkFunction.Context): Unit = {
/**
* invoke 每一条数据都会执行一次
* value 一行数据
* context 上下文对象
*/
Class.forName("com.mysql.jdbc.Driver")
val con: Connection =DriverManager.getConnection("jdbc:mysql://master:3306/bigdata?","root","123456")
val stat: PreparedStatement =con.prepareStatement("replace into word_count(word,c) values(?,?)")
stat.setString(1,value._1)
stat.setInt(2,value._2)
stat.execute()
stat.close()
con.close()
}
}
}
RichSinkFunction
socket中数据保存至MySQL中:实现RichSinkFunction,是sinkFunction的子类
object Demo4MysqlSink {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val linesDS: DataStream[String] = env.socketTextStream("master", 8888)
//统计单词数量
val countDS: DataStream[(String, Int)] =linesDS.flatMap(line=>line.split(","))
.map(word=>(word,1)).keyBy(_._1).sum(1)
countDS.addSink(new MysqlSink())
env.execute()
}
class MysqlSink extends RichSinkFunction[(String, Int)]{
var con: Connection=_ //注意val于var的变化
var stat: PreparedStatement=_
override def open(parameters: Configuration): Unit = {
Class.forName("com.mysql.jdbc.Driver")
con= DriverManager.getConnection("jdbc:mysql://master:3306/bigdata", "root", "123456")
stat = con.prepareStatement("replace into word_count(word,c) values(?,?)")
}
override def close(): Unit = {
stat.close()
con.close()
}
override def invoke(kv: (String, Int)): Unit = {
stat.setString(1, kv._1)
stat.setInt(2, kv._2)
stat.execute()
}
}
}
open:在invoke之前执行,每一个task中只执行一次,一般用于初始化数据库连接
close:任务关闭时用于回收资源
invoke:每一条数据执行一次,两个参数,前者表示一行数据,后者表示上下文对象
replace into:替换插入,不存在则插入,存在则更新,需要设计主键
边栏推荐
猜你喜欢





随机推荐
我理解的学习金字塔
Unit 12 associated serialization
【Camera2】由Camera2 特性想到的有关MED(多场景设备互动)的场景Idea
verilog学习|《Verilog数字系统设计教程》夏宇闻 第三版思考题答案(第十二章)
verilog学习|《Verilog数字系统设计教程》夏宇闻 第三版思考题答案(第十章)
Flask request application context source code analysis
什么是闭包?闭包的作用?闭包的应用?有什么缺点?
二进制乘法运算
宝塔搭建PESCMS-Ticket开源客服工单系统源码实测
window10 lower semi-automatic labeling
verilog学习|《Verilog数字系统设计教程》夏宇闻 第三版思考题答案(第七章)
St. Regis Takeaway Notes - Lecture 10 Swagger
Caused by: org.gradle.api.internal.plugins.PluginApplicationException: Failed to apply plugin [id ‘c
Deep learning framework pytorch rapid development and actual combat chapter4
Steps to connect the virtual machine with xshell_establish a network connection between the host and the vm virtual machine
paddleocr window10 first experience
MySQL知识总结 (八) InnoDB的MVCC实现机制
ThinkPHP5.0内置分页函数Paginate无法获取POST页数问题的解决办法
【c】小游戏---五子棋之井字棋雏形
C语言——一级指针初识