当前位置:网站首页>spark优化
spark优化
2022-08-02 14:05:00 【boyzwz】
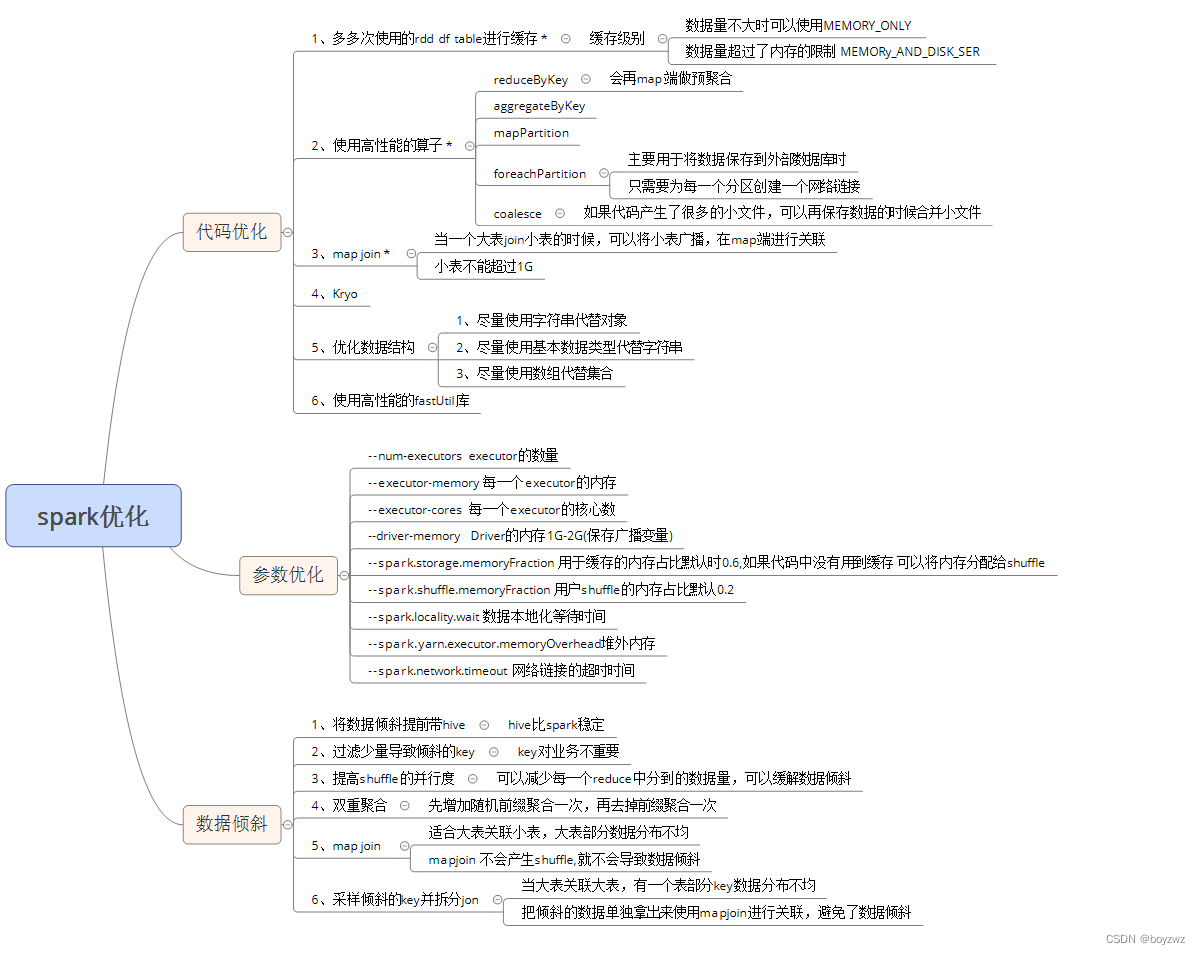
一、代码优化
1、避免创建重复的RDD
2、尽可能复用同一个RDD
3、对多次使用的RDD进行持久化
//缓存在内存中,因为不进行序列化与反序列化操作,性能最高,要求内存足够大
studentRDD.cache()
studentRDD.persist(StorageLevel.MEMORY_ONLY)
//若内存溢出,可将RDD数据序列化后再保存在内存中
studentRDD.persist(StorageLevel.MEMORY_ONLY_SER)
//将数据序列化后缓存在内存中,内存缓存不下才会写入磁盘
studentRDD.persist(StorageLevel.MEMORY_AND_DISK_SER)4、尽量避免使用shuffle类算子
5、使用map-side预聚合的shuffle操作
当一个小表join大表时,可将小表广播出去,在map端进行关联(小表不超过1G)
6、使用高性能的算子
reduceByKey/aggregateByKey
mapPartitions
foreachPartitions
coalesce
/**
* repartition: 对rdd重分区,返回一个新的rdd, 会产生shuffle
* repartition可以用于增加分区和减少分区,
* 增加分区可以增加并行度,在资源充足的情况下, 效率更高
* 减少分区可以减少产生的小文件的数量
*
*/
val rePartRDD: RDD[String] = studentsRDD.repartition(10)
println(s"rePartRDD分区数据:${rePartRDD.getNumPartitions}")
/**
* coalesceL 重分区,,可以设置是否产生shuffle
* 如果指定shuffle为true,可以用于增加分区和减少分区
* 如果指定shuffle为false,只能用于减少分区
*
*/
val coalesceRDD: RDD[String] = rePartRDD.coalesce(100, shuffle = true)
println(s"coalesceRDD分区数据:${coalesceRDD.getNumPartitions}")
/**
* 当处理好的数据需要保存到磁盘的时候,如果产生了很多的小文件,可以使用coalesce合并小文件
* 合并的标准:保证合并之后的每一个文件的大小在128M左右
*
* 比如数据保存的数据是10G, 最好的情况是合并为80个
*
* shuffle = false: 不产生shuffle,效率更好
*
*/
coalesceRDD
.coalesce(1, shuffle = false) //合并小文件
.saveAsTextFile("data/coalesce")7、广播大变量
如果使用的外部变量比较大,建议使用Spark的广播功能,对该变量进行广播。广播 后的变量,会保证每个Executor的内存中,只驻留一份变量副本,而Executor中的 task执行时共享该Executor中的那份变量副本。这样的话,可以大大减少变量副本的数量,从而减少网络传输的性能开销,并减少对Executor内存的占用开销,降低 GC的频率
8、使用Kryo优化序列化性能
使用Kryo序列化器,优化序列化性能
9、优化数据结构
尽量使用字符串替代对象,
使用原始类型(比如 Int、Long)替代字符串,
使用数组替代集合类型,
这样尽可能地减少内存占用 ,从而降低GC频率,提升性能。
10、使用高性能的库fastutil
二、参数优化
spark-submit
--master yarn-cluster
--num-executors = 50 //设定executor的数量
--executor-memory = 4G //设置每个executor的内存大小
--executor-cores = 2 //设置每个executor的核数
--driver-memory = 2G //设置Driver的内存1G-2G
--conf spark.storage.memoryFraction=0.4 //用于缓存的内存占比默认时0.6,如果代码中没有用到缓存 可以将内存分配给shuffle
--conf spark.shuffle.memoryFraction=0.4 //用户shuffle的内存占比默认0.2
--conf spark.locality.wait=10s //再executor中执行前的等待时间 默认3秒
--conf spark.yarn.executor.memoryOverhead=1024 //堆外内存 默认等于堆内存的10%
--conf spark.network.timeout=200s //网络连接的超时时间 默认120s总的内存=num-executors*executor-memory
总的核数=num-executors*executor-cores
spark on yarn 资源设置标准yarn的资源一般占总的资源的80%
1、单个任务总的内存和总的核数一般做多在yarn总资源的1/3到1/2之间2、在上线内再按照需要处理的数据量来合理指定资源 -- 最理想的情况是一个task对应一个core
三、数据倾斜优化
1、使用Hive ETL预处理数据
如果导致数据倾斜的是Hive表。如果该Hive表中的数据本身很不均匀,可以通过Hive来进行数据预处理(即通过Hive ETL预先对 数据按照key进行聚合,或者是预先和其他表进行join)
2、过滤少数导致倾斜的key
将导致数据倾斜的key(对作业的执行和计算结果不是特别重要的话)过滤除去
3、提高shuffle操作的并行度
增加shuffle后的reduce task的数量,减少每一个reduce中分到的数据量,可以缓解数据倾斜
4、双重聚合
第一次是局部聚合,先给每个key 都打上一个随机数,接着对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合;
然后将各个key的前缀给去掉,再次进行全局聚合操作,就可以得到最终结果了
5、将reduce join转为map join
不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过 collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD 执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每 一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来。
6、采样倾斜key并分拆join操作
提高数据本地级别
边栏推荐
猜你喜欢



随机推荐
Redis-01-Nosql概述
我理解的学习金字塔
Visual Studio配置OpenCV之后,提示:#include<opencv2/opencv.hpp>无法打开源文件
spark写sql的方式
binlog与iptables防nmap扫描
8580 Merge linked list
C语言日记 1“Hello world“
Error Correction Design Principle of Hamming Check Code
MongoDB安装流程心得:
Raj delivery notes - separation 第08 speak, speaking, reading and writing
Kubernetes介绍
MySQL知识总结 (一) 数据类型
使用云GPU+pycharm训练模型实现后台跑程序、自动保存训练结果、服务器自动关机
每周招聘|PostgreSQL专家,年薪60+,高能力高薪资
YOLOv7 uses cloud GPU to train its own dataset
什么是 Web 3.0:面向未来的去中心化互联网
liunx下mysql遇到的简单问题
verilog学习|《Verilog数字系统设计教程》夏宇闻 第三版思考题答案(第七章)
C语言日记 5 运算符和表达式
verilog学习|《Verilog数字系统设计教程》夏宇闻 第三版思考题答案(第十四章)