当前位置:网站首页>深度学习之 卷积网络(textCNN)
深度学习之 卷积网络(textCNN)
2022-08-02 14:07:00 【lq_fly_pig】
近期利用零散的时间,系统的学习下 nlp经典的模型,主要是看了韩国一个小哥哥的github开源代码,写的很好,大家有时间 可以去看看,美中不足的是没有注释和说明,这里我主要是参考他的代码,自己学习学习,并顺便把nlp的零散的基础知识补充一下
基础知识回顾:
一. 认识CNN网络
在此温习下卷积神经网络(CNN),下面出现的图片,是在网络中找的,如有冒犯,请勿见怪
1. 引入一个例子,边界检测
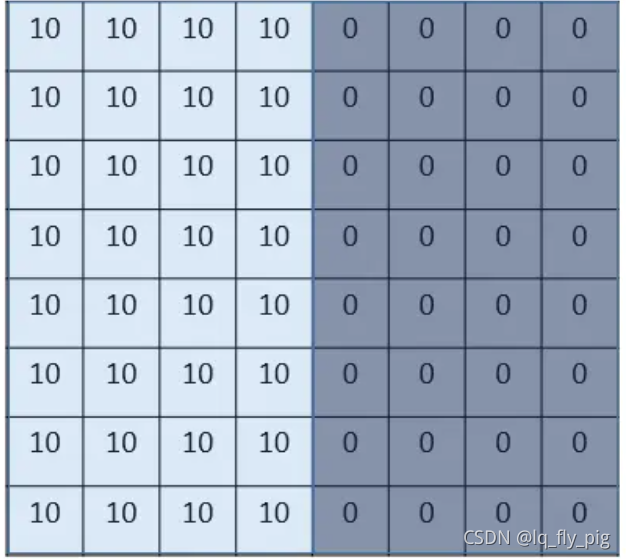
假如 上图大小是 8x8,数字代表的是像素值,明显看到10比0的位置要亮一些,像素值越大越亮,中间的边界 就是需要我们检测的边界
2. 怎么检测? 用什么方法
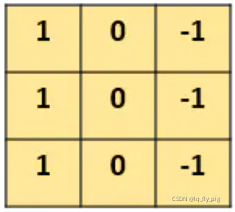
对,用的就是右边的一个小矩阵(3x3),也叫滤波器 filter、kernel
使用右边的滤波器,从原始图片(8x8) 坐标(0,0)起始的位置进行覆盖,也就是对应的元素相乘再求和。依次按照步子大小 ,向右边和向下边开始移动,直到把原始图片每一个角落都覆盖到,最终生成一个新的矩阵。
假设步长为1,就是每一次移动一个步,则生成的新的矩阵的大小为 (6 x 6) 6 = 8-3 + 1,最终的过程如下所示:
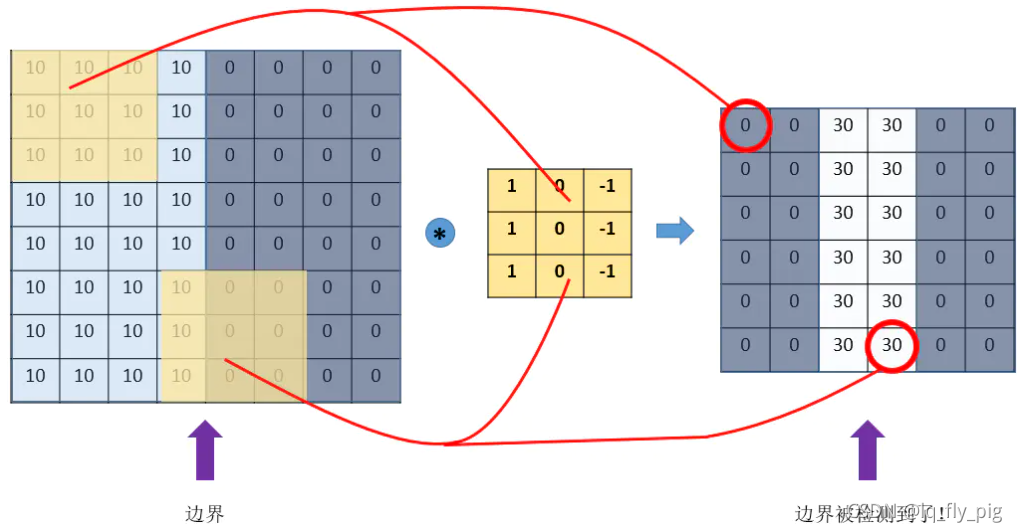
边界检测过程
3.结论
(1). 我们可以通过设计特定的filter,让它去跟图片做卷积,就可以识别出图片中的某些特征,比如边界
(2). CNN(convolutional neural network),主要就是通过一个个的filter(滤波器),不断地提取特征,从局部的特征到总体的特征,从而进行图像识别等等功能
4.思考
filter 怎么设计? 多大? 怎么提取特征? 特征的数量? 。。。学过神经网络之后,我们就知道,这些filter,根本就不用我们去设计,每个filter中的各个数字,不就是参数吗,我们可以通过大量的数据,来 让机器自己去“学习”这些参数,有现成的框架,如 TensorFlow 、Pytorch
二. CNN网络基本概念
1. padding参数
从上面的例子我们看出来了,每次卷积后,都是减少矩阵的大小,经过几次卷积,生成新的矩阵越来越小,最终没了。还有另外一个问题,大家可以想想,就是每次卷积边缘数值参与计算很少,这样的话,容易丢失边缘特征信息。为此,可以在每次卷积结束,边缘部分通过padding 一个数值来 保持矩阵的大小,同时也保证了边缘的数值参与计算的次数不减少
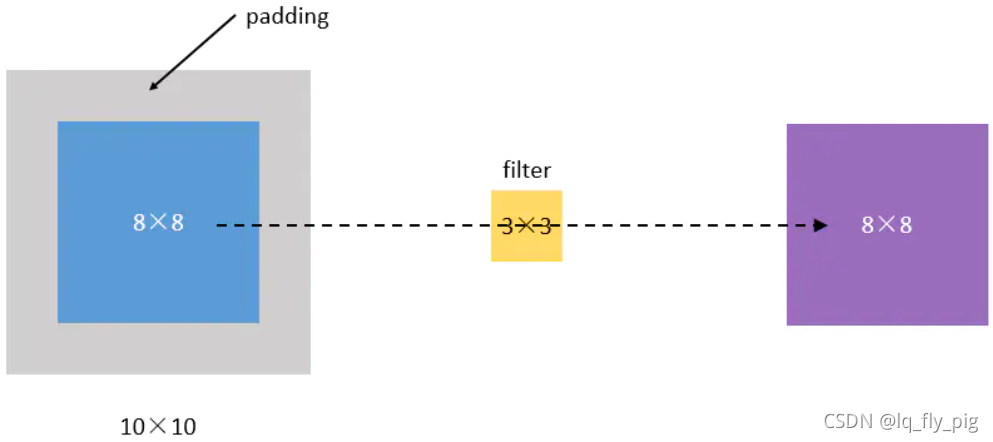
如上图所示,我们把(8,8)的图片给补成(10,10),那么经过(3,3)的filter之后,就是(8,8),没有变
padding的情况有两种方式:
(1).卷积之后大小不变的方式 称之为"Same" 方式
(2). 卷积过程中,不做任何操作,不做padding ,称之为 "Valid"方式
2. stride步长
stride步长指的是 上面卷积过程中的,向左或向下移动filter的 步子大小,一般默认步长都是1,example,原始图片输入(8 x 8)的大小,filter的大小是(3 x 3)
stride = 1, 则输出(6 x 6), 6 =(8 - 3)/1 + 1
stride = 2, 则输出(3 x 3), 3 = (8-3)/2 + 1 ,向下取整数
3.pooling 池化
pooling池化主要是对卷积后的矩阵进行特征提取操作,特征提取的方式,有max 或者 avage ,看下面:
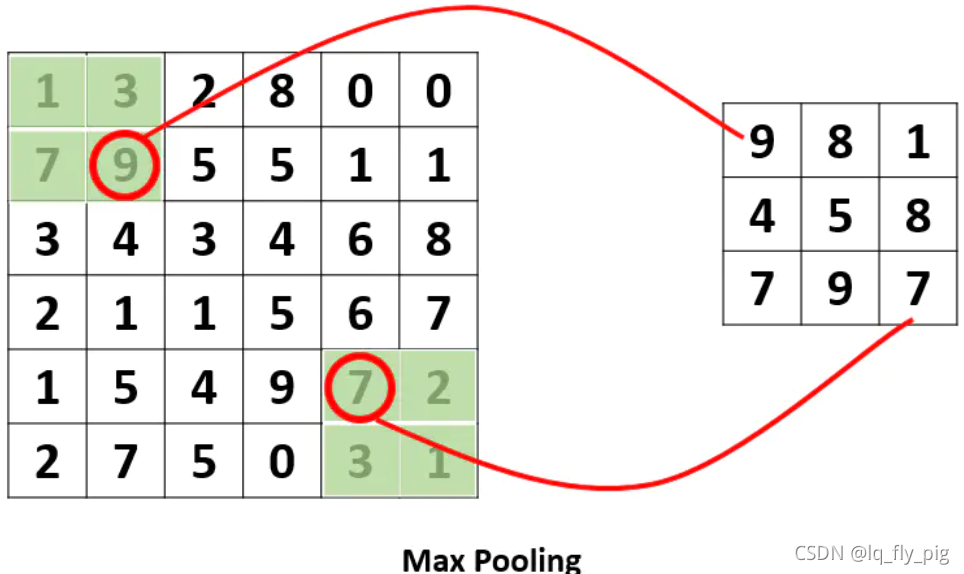
上图是max Pooling 主要是提取特征范围内的 最大值,采用了一个2×2的窗口,并取stride=2,生成的大小为(3X3), (6-2)/stride + 1 = 3
针对于 AveragePooling(取采样窗口中的平均值) ,左上角的采样窗口得到的大小是 5,而不是 9
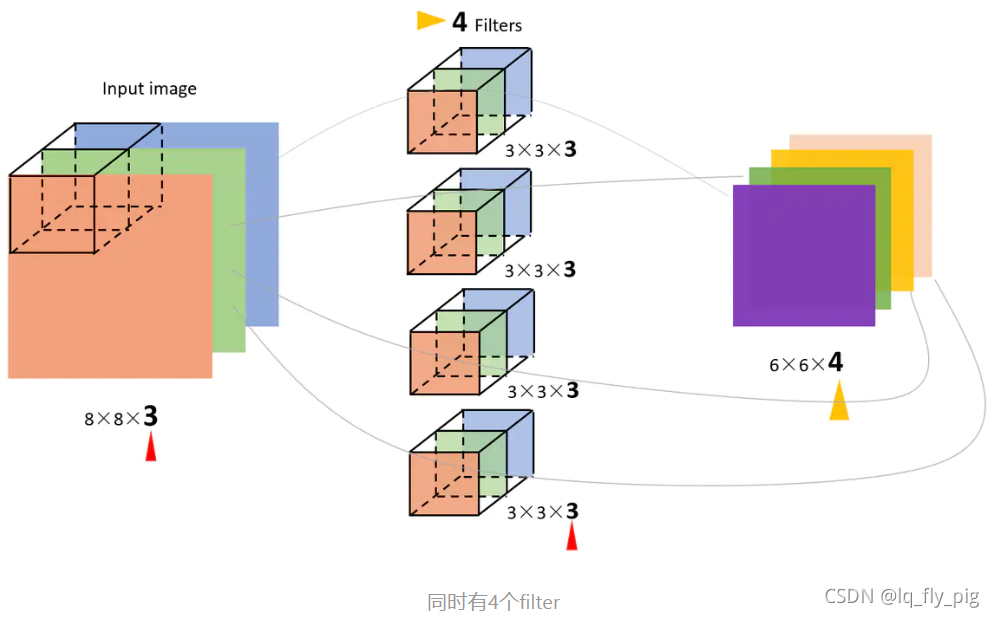
4.多通道(channel)的卷积
彩色图像,一般都是RGB三个通道(channel)的,因此输入数据的维度一般有三个:(长,宽,通道)28 x 28 大小的 RGB图片,维度大小就是(28,28,3)
针对上面的 (8x8)-> (3x3) filter -> (6x6) ,此时就变成下面的方式:
(8x8x3) -> (3x3x3) filter ->(6x6)
filter的维度变成三维的,最后一维度和channel的大小一样,是三个channel的所有元素对应相乘后求和,也就是之前是9个乘积的和,现在是27个乘积的和。因此,输出的维度并不会变化。还是(6,6)。一般情况都是使用多个filter 进行卷积,如 使用4个 filter进行卷积,输出的维度为(6x6x4);
5.总结
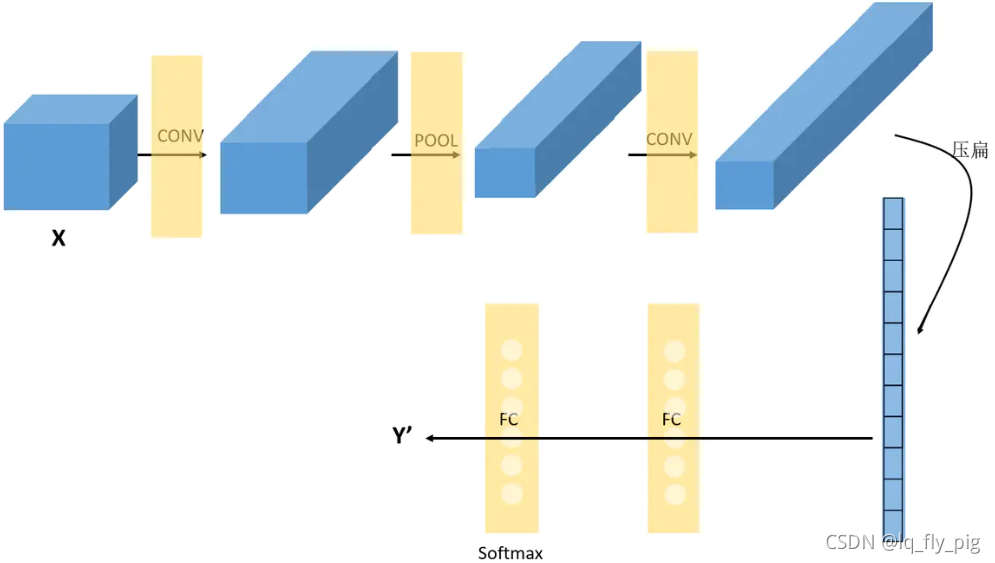
从上文得到,卷积(convolution)、池化(pooling)以及填白(padding)是怎么进行处理的,他一共包括三个部分:
(1).卷积层 Convolutional
卷积层是 由 滤波器filters和激活函数构成,通常需要设置的超参数包括filters的数量、大小、步长,以及padding是“valid”还是“same”,以及选择激活函数的种类
(2).池化层 Convolutional
一般有两种情况,一种是Maxpooling 或者 是Averagepooling。通常需要指定的超参数,包括是Max还是average,窗口大小以及步长。
(3).全连接层 FC
每一个单元都和前一层的每一个单元相连接,所以称之为“全连接”。这里要指定的超参数,无非就是神经元的数量,以及激活函数。
三. textCNN网络
从上文中我们已经学习了CNN网络的三大要素,如 卷积核(滤波器 filter), 再到池化层,再到输出的 FC层。TextCNN是Yoon Kim小哥在2014年提出的模型,借鉴于CNN网络,大致的逻辑如下:
1. 输入是 [batch_size,seq_len,embed_dim],batch 大小,token 长度,embed的大小
2.使用N个卷积核 得到的维度为 [batch_size,N,feature_map.size,feature_map.size]
3.使用maxPooling, 使用max_pool1d(size) , 1x size 的采样窗口,步长默认是1,取max数值
4. 上文得到的向量 拍平,进行 softmax分类
注意事项:(参考李 rumor)
- Filter尺寸:这个参数决定了抽取n-gram特征的长度,这个参数主要跟数据有关,平均长度在50以内的话,用10以下就可以了,否则可以长一些。在调参时可以先用一个尺寸grid search,找到一个最优尺寸,然后尝试最优尺寸和附近尺寸的组合
- Filter个数:这个参数会影响最终特征的维度,维度太大的话训练速度就会变慢。这里在100-600之间调参即可
- CNN的激活函数:可以尝试Identity、ReLU、tanh
- 正则化:指对CNN参数的正则化,可以使用dropout或L2,但能起的作用很小,可以试下小的dropout率(<0.5),L2限制大一点
- Pooling方法:根据情况选择mean、max、k-max pooling,大部分时候max表现就很好,因为分类任务对细粒度语义的要求不高,只抓住最大特征就好了
- Embedding表:中文可以选择char或word级别的输入,也可以两种都用,会提升些效果。如果训练数据充足(10w+),也可以从头训练
- 蒸馏BERT的logits,利用领域内无监督数据
- 加深全连接:原论文只使用了一层全连接,而加到3、4层左右效果会更好
四.代码展示:
import torch
import torch.nn as nn
import torch.optim as optim
import pdb
import torch.nn.functional as F
import numpy as np
### textCNN 文本分类
num_class = 2 ## 二分类
embedding_size = 3 ## embed 的维度大小
class TextCNN(nn.Module):
def __init__(self,num_channels = 1) -> None: ## input [6,1,3,3]
super(TextCNN,self).__init__()
self.embed = nn.Embedding(voc_size, embedding_size)
self.conv1 = nn.Conv2d(num_channels,5,1,1) # num_channel = 1 表示通道数, 5 表示 filter kernel 的数量,滤波器的数量
### 1 -> filter的大小 1*1 的大小, 1 -> stride 步子的大小
self.conv2 = nn.Conv2d(5,5,1,1) ## input = [6,5,3,3] batch = 6, channel_num = 5,filter_size =1, stride = 1
self.fc = nn.Linear(5*3*3,num_class)
def forward(self,X):
embedded = self.embed(X) ## X [6,3],embedded = [6,3,3]
X = embedded.unsqueeze(1) ## X = [6,1,3,3] ,针对第一个维度进行扩充,由之前的三维变成现在的四维
out1 = self.conv1(X) ## X -> [6,1,3,3] out1 -> [6,5,3,3] 3 = (3-1)/stride + 1
y1 = F.relu(out1) ## y -> [6,5,3,3]
y1 = F.max_pool2d(y1,1,1)
out2 = self.conv2(y1) ## out2 = [6,5,3,3]
y2 = F.relu(out2) ## y -> [6,5,3,3]
y2 = F.max_pool2d(y2,1,1)
y2 = y2.view(-1,5*3*3)
out = self.fc(y2)
return out
if __name__ == '__main__':
###主要是用于情感分类
sentences = ["i love you", "he loves me", "she likes baseball", "i hate you", "sorry for that", "this is awful"]
labels = [1, 1, 1, 0, 0, 0]
word_list = ' '.join(sentences).split()
word_list = list(set(word_list))
word_dict = {w:i for i,w in enumerate(word_list)}
voc_size = len(word_list)
model = TextCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
inputs = torch.LongTensor([np.asarray([word_dict[n] for n in sen.split()]) for sen in sentences])
targets = torch.LongTensor([out for out in labels]) # To using Torch Softmax Loss function
# pdb.set_trace()
# Training
for epoch in range(5000):
optimizer.zero_grad()
output = model(inputs)
# output : [batch_size, num_classes], target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, targets)
if (epoch + 1) % 200 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward() ## Loss 方向传播
optimizer.step() ## 每一次参数迭代更新
# Test
test_text = 'sorry hate you'
tests = [np.asarray([word_dict[n] for n in test_text.split()])]
test_batch = torch.LongTensor(tests)
# Predict
predict = model(test_batch).data.max(1, keepdim=True)[1]
if predict[0][0] == 0:
print(test_text,"is Bad Mean...")
else:
print(test_text,"is Good Mean!!")
边栏推荐
- 宝塔面板搭建小说CMS管理系统源码实测 - ThinkPHP6.0
- What?It's 2020, you still can't adapt the screen?
- LLVM系列第十七章:控制流语句for
- 牛客刷题汇总(持续更新中)
- VS Code无法安装插件之Unable to install because, the extension '' compatible with current version
- 宝塔搭建PHP自适应懒人网址导航源码实测
- LLVM系列第五章:全局变量Global Variable
- uniCloud 未能获取当前用户信息:30205 | 当前用户为匿名身份
- 华为路由交换
- It is not allowed to subscribe with a(n) xxx multiple times.Please create a fresh instance of xxx
猜你喜欢
宝塔搭建PESCMS-Ticket开源客服工单系统源码实测

Spark_Core

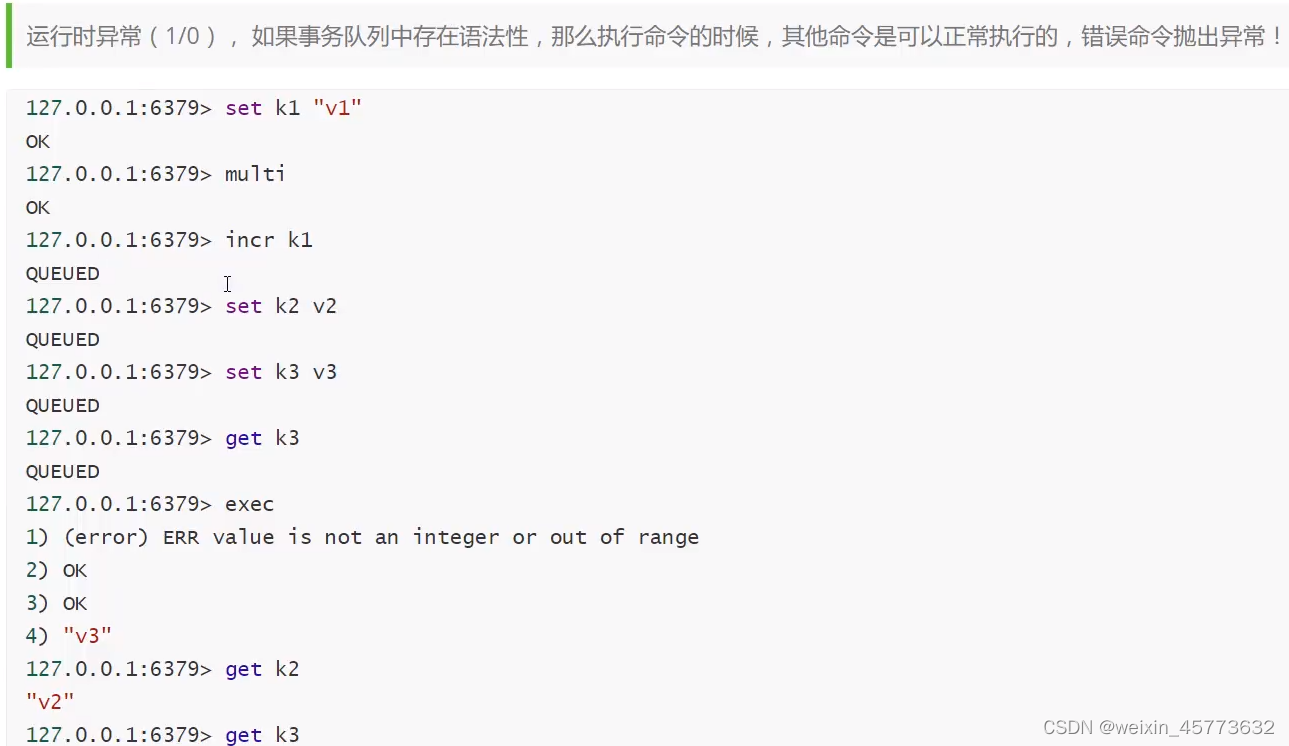
St. Regis Takeaway Notes - Lecture 05 Getting Started with Redis

Using the cloud GPU + pycharm training model to realize automatic background run programs, save training results, the server automatically power off
redis基础
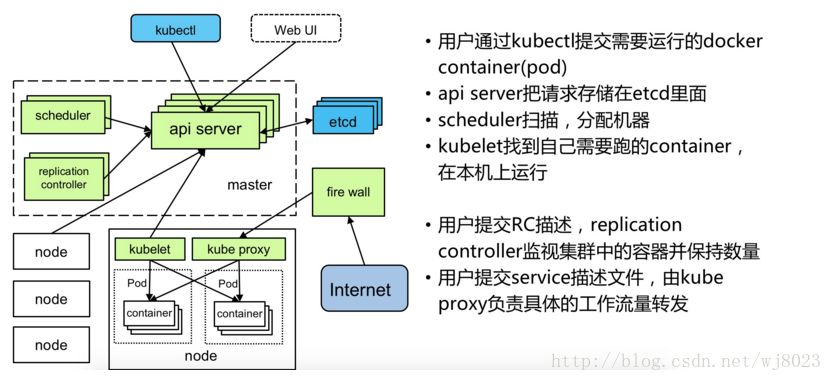
Kubernetes架构和组件
LLVM系列第二十四章:用Xcode编译调试LLVM源码
NDK报错问题分析方案(一)

MongoDB Compass 安装与使用
MySQL知识总结 (十) 一条 SQL 的执行过程详解
随机推荐
C语言日记 3 常量
两个surfaceview的重叠效果类似直播效果中的视频和讲义实践
LLVM系列第六章:函数返回值Return
想做好分布式架构?这个知识点一定要理解透彻
VS Code无法安装插件之Unable to install because, the extension '' compatible with current version
主存储器(一)
Kubernetes架构和组件
MySQL知识总结 (六) MySQL调优
PHP版本切换:5.x到7.3
NDK报错问题分析方案(一)
【目标检测】YOLO v5 安全帽检测识别项目模型
拥抱Jetpack之印象篇
LLVM系列第二十章:写一个简单的Function Pass
Flink-独立集群/Yarn
getUserProfile接口不显示用户性别和地区
Cannot figure out how to save this field into database. You can consider adding a type converter for
【目标检测】YOLO v5 吸烟行为识别检测
关于spark
LLVM系列第十九章:写一个简单的Module Pass
Kubernetes核心概念